Comments

Summary: This post documents research by SatisfIA, an ongoing project on non-maximizing, "aspiration-based" designs for AI agents that fulfill goals specified by constraints ("aspirations") rather than maximizing an objective function. We aim to contribute to AI safety by exploring design approaches and their software implementations that we believe might be promising, but neglected or novel. Our approach is roughly related to, but largely complementary to, concepts like Decision Transformers, Active Inference, Quantilization and Satisficing (or soft optimization in general).
It's divided into two parts, the informal introduction and the formal introduction.
First, the informal introduction describes the motivation for the research, our working hypotheses, and our theoretical framework. It does not contain results and can safely be skipped if you want to get directly into the actual research.
Second, the formal introduction presents the simplest form of the type of aspiration-based algorithms we study. We do this for a simple form of aspiration-type goals: making the expectation of some variable equal to some given target value.[1]
At the end of the post we give an overview of the projects status (we're looking for collaborators!) and have a small glossary of terms.
This post is the summary for an emerging sequence on LessWrong and the Alignment Forum, authored by us and other members of the SatisfIA project team. If you wish to learn more about our approach you can read the full sequence there.
We share a general concern regarding the trajectory of Artificial General Intelligence (AGI) development, particularly the risks associated with creating AGI agents designed to maximize objective functions. We have two main concerns:
The development of AGI seems inevitable due to its immense potential economic, military, and scientific value. This inevitability is driven by:
The conventional view on A(G)I agents (see, e.g., Wikipedia) is that they should aim to maximize some function of the state or trajectory of the world, often called a "utility function", sometimes also called a "welfare function". It tacitly assumes that there is such an objective function that can adequately make the AGI behave in a moral way. However, this assumption faces several significant challenges:
Given these concerns, the implication is clear: AI safety research should spend considerably more effort on identifying and developing AGI designs that do not rely on the maximization of an objective function. Given our impression that currently not enough researchers pursue this, we chose to work on it, complementing existing work on what some people call "mild" or "soft optimization", such as Quantilization or Bayesian utility meta-modeling. In contrast to the latter approaches, which are still based on the notion of a "(proxy) utility function", we explore the apparently mostly neglected design alternative that avoids the very concept of a utility function altogether.[2] The closest existing aspiration-based design we know of is Decision Transformer, which is inherently a learning approach. To complement this, we focus on a planning approach.
We use the following working hypotheses during the project, which we ask the reader to adopt as hypothetical premises while reading our text (you don't need to believe them, just assume them to see what might follow from them).
Following the motivation described above, our primary hypothesis posits that it must not be allowed that an AGI aims to maximize any form of objective function that evaluates the state or trajectory of the world. (This does not necessarily rule out that the agent employs any type of optimization of any objective function as part of its decision making, as long as that function is not only a function of the state or trajectory of the world. For example, we might allow some form of constrained maximization of entropy or minimization of free energy or the like, which are functions of a probabilistic policy rather than of the state of the world.)
The 2nd hypothesis is that to keep an AGI from aiming to maximize some utility function, the AGI agent must use a decision algorithm to pick actions or plans on the basis of the available information, and that decision algorithm must be hard-coded and cannot be allowed to emerge as a byproduct of some form of learning or training process. This premise seeks to ensure that the foundational principles guiding the agent's decision making are known in advance and have verifiable (ideally even provable) properties. This is similar to the "safe by design" paradigm and implies a modular design where decision making and knowledge representation are kept separate. In particular, it rules out monolithic architectures (like using only a single transformer or other large neural network that represents a policy, and a corresponding learning algorithm).
Although in reality, an AGI agent will never have a perfect model of the world and hence also needs some learning algorithm(s) to improve its imperfect understanding of the world on the basis of incoming data, our 3rd hypothesis is that for the design of the decision algorithm, it is helpful to hypothetically assume in the beginning that the agent already possesses a fixed, sufficiently good probabilistic world model that can predict the consequences of possible courses of action, so that the decision algorithm can choose actions or plans on the basis of these predictions. The rationale is that this "model-based planning" framework is simpler and mathematically more convenient to work with and allows us to address the fundamental design issues that arise even without learning, before addressing additional issues related to learning. (see also Project history)
We hypothesize the existence of generic and abstract safety criteria that can enhance AGI safety in a broad range of scenarios. These criteria focus on structural and behavioral aspects of the agent's interaction with the world, largely independent of the specific semantics or contextual details of actions and states and mostly unrelated to concrete human values. Examples include the level of randomization in decision-making, the degree of change introduced into the environment, the novelty of behaviors, and the agent's capacity to drastically alter world states. Such criteria are envisaged as broadly enhancing safety, very roughly analogous to guidelines such as caution, modesty, patience, neutrality, awareness, and humility, without assuming a one-to-one correspondence to the latter.
We assume it is possible to offer concrete guarantees concerning certain aspects of the AGI's performance and behavior. By adhering to the outlined hypotheses and safety criteria, our aim is to develop AGI systems that exhibit behaviour that is in some essential respects predictable and controlled, reducing risk while fulfilling their intended functions within safety constraints.
Because the number of possible policies grows exponentially fast with the number of possible states, any algorithm that requires scanning a considerable portion of the policy space (like, e.g., "naive" quantilization over full policies would) soon becomes intractable in complex environments. In optimal control theory, this problem is solved by exploiting certain mathematical features of expected values that allow to make decisions sequentially and compute the relevant quantities (V- and Q-values) in an efficient recursive way using the Hamilton–Jacobi–Bellman equation. Based on our preliminary results, we hypothesize that a very similar recursive approach is possible in our aspiration-based framework in order to keep our algorithms tractable in complex environments.
Agent-environment interface. Our theoretical framework and methodological tools draw inspiration from established paradigms in artificial intelligence (AI), aiming to construct a robust understanding of how agents interact with their environment and make decisions. At the core of our approach is the standard agent–environment interface, a concept that we later elaborate through standard models like (Partially Observed) Markov Decision Processes. For now, we consider agents as entirely separate from the environment — an abstraction that simplifies early discussions, though we acknowledge that the study of agents which are a part of their environment is an essential extension for future exploration.
Simple modular design. To be able to analyse decision-making more clearly, we assume a modular architecture that divides the agent into two main components: the world model and the decision algorithm. The world model represents the agent's understanding and representation of its environment. It encompasses everything the agent knows or predicts about the environment, including how it believes the environment responds to its actions. The decision algorithm, on the other hand, is the mechanism through which the agent selects actions and plans based on its world model and set goals. It evaluates potential actions and their predicted outcomes to choose courses of action that appear safe and aligned with its aspirations.
Studying a modular setup can also be justified by the fact that some leading figures in AI push for modular designs even though current LLM-based systems are not yet modular in this way.
Information theory. For formalizing generic safety criteria, we mostly employ an information theoretic approach, using the mathematically very convenient central concept of Shannon entropy (unconditional, conditional, mutual, directed, etc.) and derived concepts (e.g., channel capacity). This also allows us to compare and combine our findings with approaches based on the free energy principle and active inference. where goals are formulated as desired probability distributions of observations.
The decision algorithms we currently study have the following high-level structure:
Depending on the type of aspiration, the details can be designed so that the algorithm comes with certain guarantees about the fulfillment of the goal.
In line with the working hypotheses, we assume more specifically the following in this post:
The challenge in this post is to design a decision algorithm for tasks where the agent's goal is to make the expected (!) Total equal (!) a certain value which we call the aspiration value. This is a crucial difference from a "satisficing" approach that would aim to make expected Total at least as large as and would thus still be happy to maximize Total. Later we consider other types of tasks, both less restrictive ones (including those related to satisficing) and more specific ones that also care about other aspects of the resulting distribution of Total or states.
It turns out that we can guarantee the fulfillment of this type of goal under some weak conditions!
Notice that a special case of such expectation-type goals is making sure that the probability of reaching a certain set of acceptable terminal states equals a certain value, because we can simply assume that each such acceptable terminal state gives 1 Delta and all others give zero Delta. We will come back to that special case later when discussing aspiration intervals.
In later posts, we will generalize the above assumptions in the following ways:
We focus on a single episode for a specific task.
Environment. We assume the agent's interaction with the environment consists of an alternating sequence of discrete observations and actions. As usual, we formalize this by assuming that after each observation, the agent chooses an action and then "calls" a (potentially stochastic) function provided by the environment that returns the next observation.
World model. The episode's world model, , is a finite, acyclic MDP. The model's discrete time counter, , advances whenever the agent makes an observation. From the sequence of observations made until time , the world model constructs a representation of the state of the world, which we call the model state or simply the state and denote by , and which also contains information about the time index itself. The set of all possible (model) states is a finite set . A subset of states is considered terminal. If the state is terminal, the episode ends without further action or Delta, which represents the fact that the agent becomes inactive until given a new task. Otherwise, the agent chooses an action . The world model predicts the consequences of each possible action by providing a probability distribution for the successor state . It also predicts the expected Delta for the task-relevant evaluation metric as a function of the state, action, and successor state: .
The following two graphs depict all this. Entities occurring in the world model are blue, those in the real world red, green is what we want to design, and dotted things are unknown to the agent:
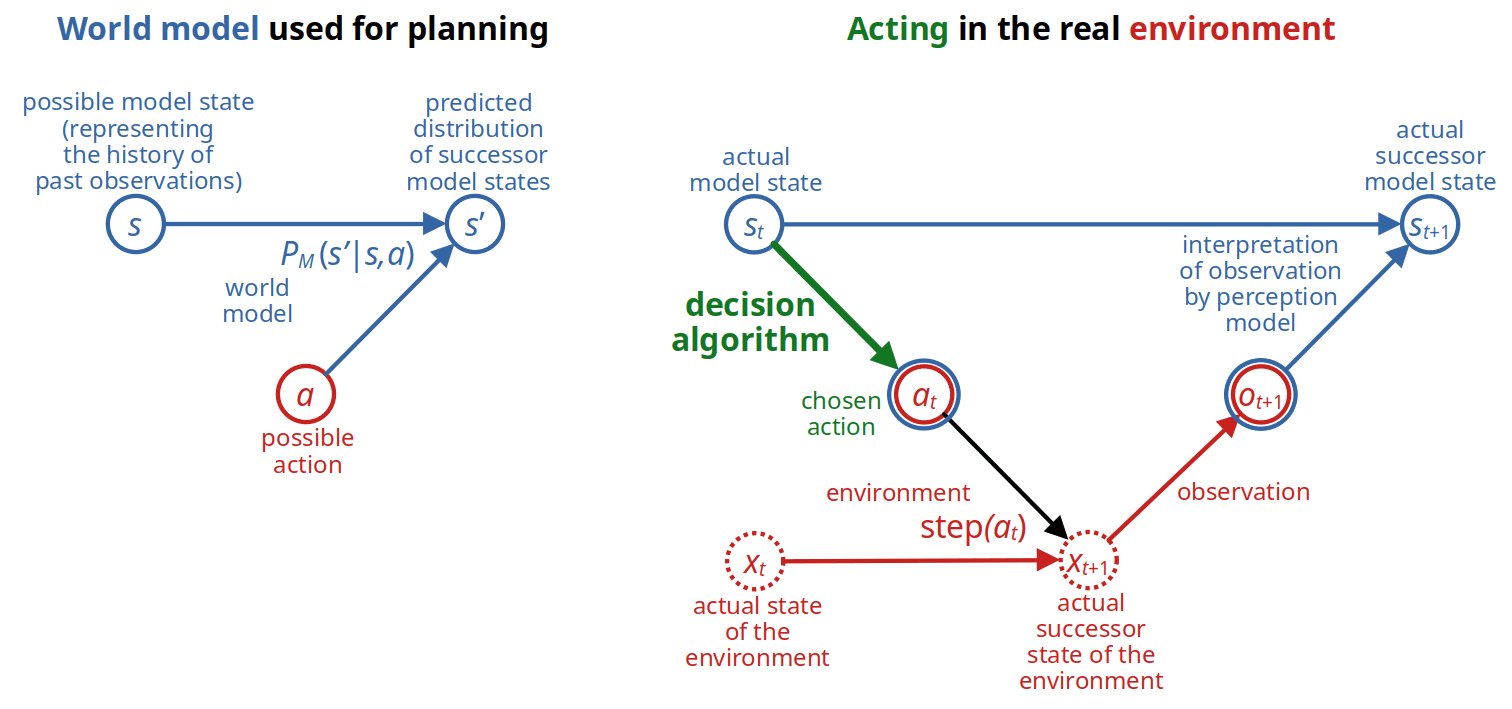
We hide the process of constructing the next state from the previous state, action, and next observation by simply assuming that the agent can call a version of the function that is given the current state and action and returns the successor state constructed from the next observation: .
Goal. The goal is given by an aspiration value . The task is to choose actions so that the expected Total,
equals .
Auxiliary notation for interval arithmetic. We will use the following abbreviations:
Our agent will achieve the goal by
For both aspiration propagation and decision making, the agent uses some auxiliary quantities that it computes upfront at the beginning of the episode from the world model as follows.
Similar to what is done in optimal control theory, the agent computes the - and -functions of the hypothetical policy that would maximize expected Total, here denoted and , by solving the respective Bellman equations
with for terminal states . It also computes the analogous quantities for the hypothetical policy that would minimize expected Total, denoted and :
with for terminal states . These define the state's and action's feasibility intervals,
The eventual use of these intervals will be to rescale aspirations from step to step. Before we come to that, however, we can already prove a first easy fact about goals of the type "make sure that expected Total equals a certain value":
If the world model predicts state transitions correctly, then there is a decision algorithm that fulfills the goal if and only if the episode's starting aspiration is in the initial state's feasibility interval .
Proof. The values and are, by definition, the expected Total of the maximizing resp. minimizing policy, and hence it is clear that there cannot be a policy which attains in expectation if is larger than or smaller than .
Conversely, assuming that lies inside the interval , the following procedure fulfills the goal:
This fulfills the goal, since the correctness of the model implies that, when using or , we actually get an expected Total of resp. .
Of course, using this "either maximize or minimize the evaluation metric" approach would be catastrophic for safety. For example, if we tasked an agent with restoring Earth's climate to a pre-industrial state, using as our evaluation metric the global mean temperature, this decision algorithm might randomize, with carefully chosen probability, between causing an ice age and inducing a runaway greenhouse effect! This is very different from what we want, which is something roughly similar to pre-industrial climate.
Another trivial idea is to randomize in each time step between the action with the largest and the one with the smallest , using a fixed probability resp. . Since expected Total is a continuous function of which varies between and , by the Intermediate Value Theorem there exists some value of for which this algorithm gives the correct expected Total; however, it is unclear how to compute the right in practice.
If the episode consists of many time steps, this method might not lead to extreme values of the Total, but it would still make the agent take an extreme action in each time step. Intuition also suggests that the agent's behavior would be less predictable and fluctuate more than in the first version, where it consistently maximizes or minimizes after the initial randomization, and that this is undesirable.
So let us study more intelligent ways to guarantee that .
In order to avoid extreme actions, our actual decision algorithm chooses "suitable" intermediate actions which it expects to allow it to fulfill the goal in expectation. When in state , it does so by
More precisely: First compute (or learn) the functions , and . Then, given state and a feasible state-aspiration ,
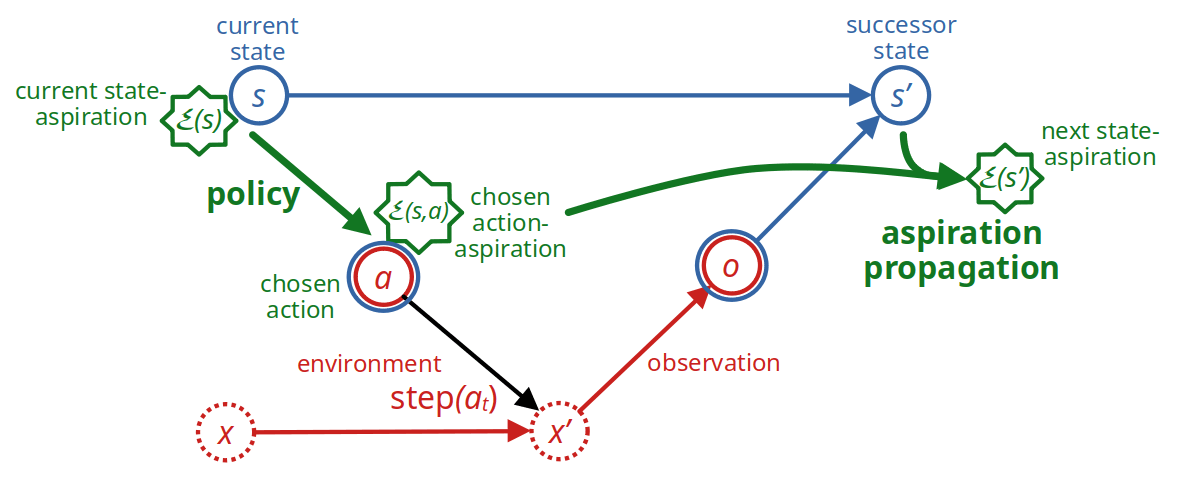
If we add the state- and action aspirations as entities to the diagram of Fig. 1, we get this:
We return to the apple-shopping scenario mentioned above, which we model by the following simple state-action diagram:
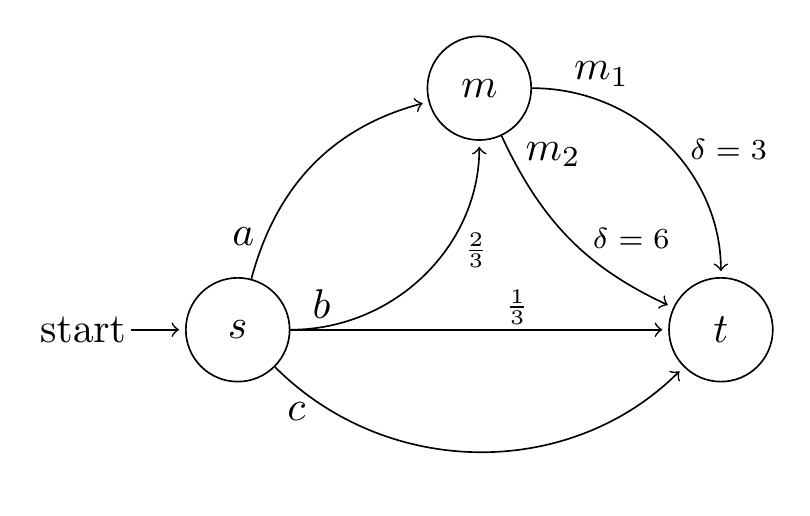
Our agent starts at home (state ) and wishes to obtain a certain number of apples, which are available at a market (state ). It can either walk to the market (action ), which will certainly succeed, or take public transportation (action ), which gives a 2/3 chance of arriving successfully at the market and a 1/3 chance of not reaching the market before it closes and returning home empty-handed. Of course, the agent can also decide to take the null action (action ) and simply stay home the entire day doing nothing.
Once it reaches the market , the agent can buy either one or two packs of three apples (actions and , respectively) before returning home at the end of the day (state ).
To apply Algorithm 1, we first compute the - and -functions for the maximizing and minimizing policies. Since there are no possible cycles in this environment, straightforwardly unrolling the recursive definitions from the back ("backward induction") yields:
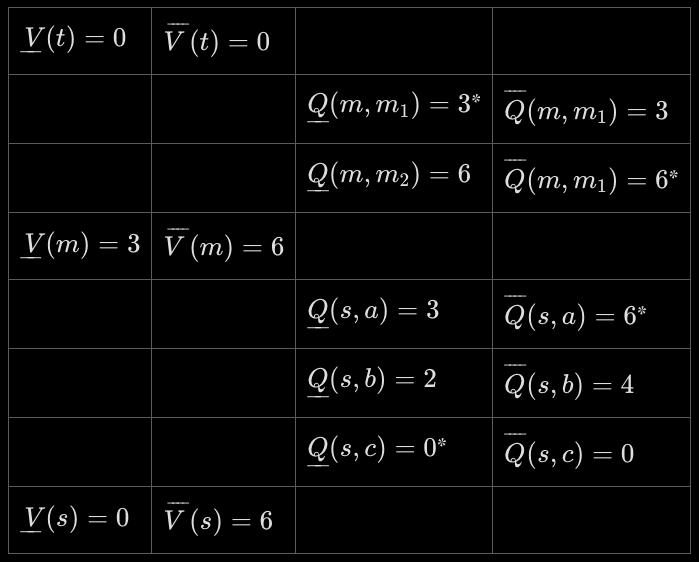
(The asterisks* mark which actions give the values)
Suppose that the agent is in the initial state and has the aspiration .
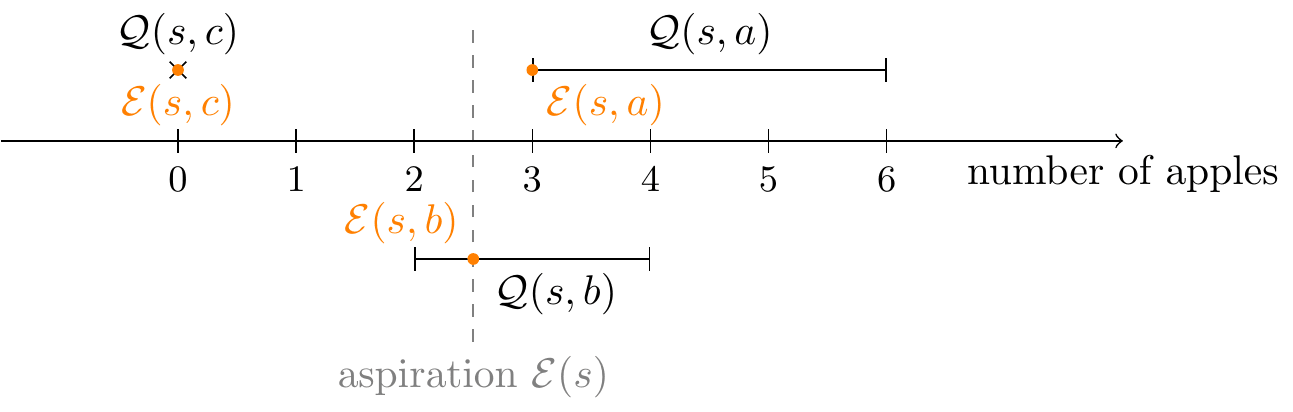
Suppose now that we started with the same initial aspiration , but instead chose action as our over-achieving action in step 2. In this case, algorithm execution would go as follows:
These examples demonstrate two cases:
There is one last case, where both feasibility intervals contain ; this is the case, for example, if we choose in the above environment. Execution then proceeds as follows:
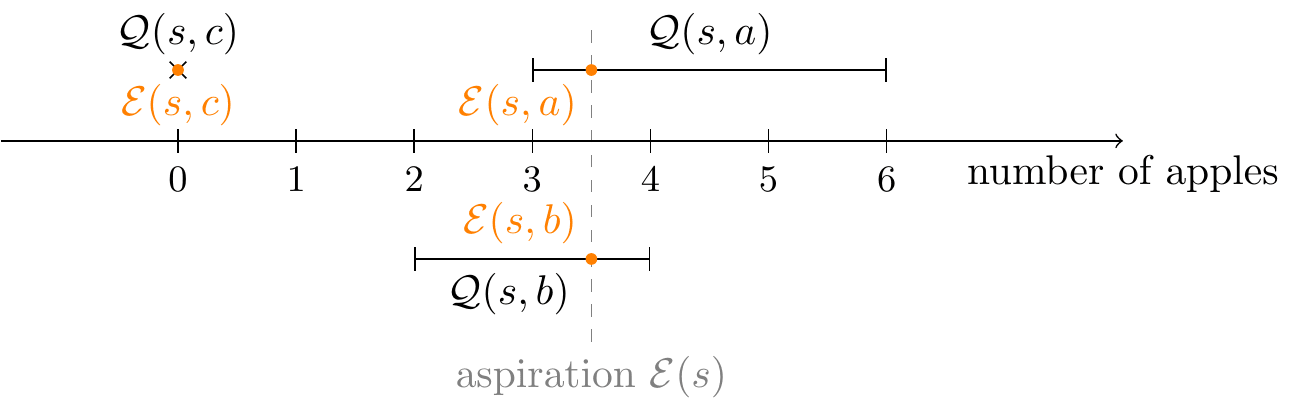
Now that we have an idea of how the decision algorithm works, it is time to prove its correctness.
If the world model predicts state transitions correctly and the episode-aspiration is in the initial state's feasibility interval, , then decision algorithm 1 fulfills the goal .
Proof.
First, let us observe that algorithm 1 preserves feasibility: if we start from state with state-aspiration , then for all states and actions visited, we will have and .
This statement is easily seen to be true for action-aspirations, as they are required to be feasible by definition in step 1, and correctness for state-aspirations follows from the definition of in step 6.
Let us now denote by the expected Total obtained by algorithm 1 starting from state with state-aspiration , and likewise by the expected Total obtained by starting at step 5 in algorithm 1 with action-aspiration .
Since the environment is assumed to be acyclic and finite, we can straightforwardly prove the following claims by backwards induction:
We start with claim 1. The core reason why this is true is that, for non-terminal states , we chose the right in step 3 of the algorithm:
Claim 1 also serves as the base case for our induction: if is a terminal state, then is an interval made up of a single point, and in this case claim 1 is trivially true.
Claim 2 requires that the translation between action-aspirations, chosen before the world's reaction is observed, and subsequent state-aspirations, preserves expected Total. The core reason why this works is the linearity of the rescaling operations in step 6:
This concludes the correctness proof of algorithm 1.
We can extend the basic algorithm by adding criteria for choosing the two candidate actions the algorithm mixes, and by generalizing the goal from making the expected Total equal a particular value to making it fall into a particular interval.
The interesting question now is what criteria the agent should use to pick the two candidate actions in step 2. We might use this freedom to choose actions in a way that increases safety, e.g., by choosing randomly as a form a "soft optimization" or by incorporating safety criteria like limiting impact.
Let's look at some simple illustrative examples of performance and safety criteria (More useful criteria will be discussed in the full LW sequence).
After having introduced the basic structure of our decision algorithms we will focus on the core question: How shall we make use of the freedom gained from having aspiration-type goals rather than maximization goals?
After all, while there is typically only a single policy that maximize some objective function (or very few, more or less equivalent policies), there is typically a much larger set of policies that fulfill some constraints (such as the aspiration to make the expected Total equal some desired value).
More formally: Let us think of the space of all (probabilistic) policies, , as a compact convex subset of a high-dimensional vector space with dimension and Lebesgue measure . Let us call a policy successful iff it fulfills the specified goal, , and let be the set of successful policies. Then this set has typically zero measure, , and low dimension, , if the goal is a maximization goals, but it has large dimension, , for most aspiration-type goals.
E.g., if the goal is to make expected Total equal an aspiration value, , we typically have but still . At the end of this post, we discuss how the set of successful policies can be further enlarged by switching from aspiration values to aspiration intervals to encode goals, which makes the set have full dimension, , and positive measure, .
What does that mean? It means we have a lot of freedom to choose the actual policy that the agent should use to fulfill an aspiration-type goal. We can try to use this freedom to choose policies that promise to be rather safe than unsafe according to some generic safety metric, similar to the impact metrics used in reward function regularization for maximizers.
Depending on the type of goal, we might also want to use this freedom to choose policies that fulfill the goal in a rather desirable than undesirable way according to some goal-related performance metric.
In this post, we will illustrate this with only very few, "toy" safety metrics, and one rather simple goal-related performance metric, to exemplify how such metrics might be used in our framework. In the LW sequence we discuss more sophisticated and hopefully more useful safety metrics.
Let us begin with a simple goal-related performance metric since that is the most straightforward.
Recall that in step 2 of the basic algorithm, we could make the agent pick any action whose action-aspiration is at most as large as the current state-aspiration, , and it can also pick any other action, , whose action-aspiration is at least as large as the current state-aspiration, . This flexibility is because in steps 3 and 4 of the algorithm, the agent is still able to randomize between these two actions in a way that makes expected Total, , become exactly .
If one had an optimization mindset, one might immediately get the idea to not only match the desired expectation for the Total, but also to minimize the variability of the Total, as measured by some suitable statistic such as its variance. In a sequential decision making situation like an MDP, estimating the variance of the Total requires a recursive calculation that anticipates future actions, which can be done but is not trivial (see the LW sequence).
Let us instead look at a simpler metric to illustrate the basic approach: the (relative, one-step) squared deviation of aspiration, which is very easy to compute:
The rationale for this is that at any time, the action aspirations are the expected values of Total-to-go conditional on taking action , so keeping them close to will tend to lead to a smaller variance. Indeed, that variance is lower bounded by , where is the probability for choosing calculated in step 3 of Algorithm 1.
If the action space is rich enough, there will often be at least one action the action-aspiration of which equals the state-aspiration, , because the state-aspiration is contained in that action's feasibility interval, . There might even be a large number of such actions. This will in particular be the case in the early steps of an episode. This is because often one can distribute the amount of effort spent on a task more or less flexibly over time; as long as there is enough time left, one might start by exerting little effort and then make up for this in later steps, or begin with a lot of effort and then relax later.
If this is the case, then minimizing simply means choosing one of the actions for which and thus and thus , and then put . When there are many such candidate actions , that will still leave us with some remaining freedom for incorporating some other safety criteria to choose between them, maybe deterministically. One might thus think that this form of optimization is safe enough and should be performed because it gets rid of all variability and randomization in that step.
For example: Assume the goal is to get back home with fourteen apples within a week, and the agent can harvest or eat at most six apples on each day (apples are really scarce). Then each day the agent might choose to harvest or eat any number of apples, as long as its current stock of apples does not deviate from fourteen by more than six times the remaining number of days. Only in the last several days it might then have to harvest or eat exactly six apples per day, to make up for earlier deviations and to land at fourteen apples sharp eventually.
But there's at least two objections to minimizing SDA. First, generically, we can not be sure enough that there will indeed be many different actions for which , and so restricting our choice to the potentially only few actions that fulfill this might not allow us to incorporate safety criteria to a sufficient level. In particular, we should expect that the latter is often the case in the final steps of an episode, where there might at best be a single such action that perfectly makes up for the earlier under- or over-achievements, or even no such action at all. Second, getting rid of all randomization goes against the intuition of some many members of our project team that randomization is a desirable feature that tends to increase rather than decrease safety (this intuition also underlies the alternative approach of quantilization).
We think that one should thus not minimize performance metrics such as SDA or any other of the later discussed metrics, but at best use them as soft criteria. Arguably the most standard way to do this is to use a softmin (Boltzmann) policy for drawing both candidate actions and independently of each other, on the basis of their (or another metric's) scores:
restricted to those with , and for some sufficiently small inverse temperature to ensure sufficient randomization.
While the SDA criterion is about keeping the variance of the Total rather low and is thus about fulfilling the goal in a presumably more desirable way from the viewpoint of the goal-setting client, the more important type of action selection criterion is not goal- but safety-related. So let us now look at the latter type of criterion.
As the apple example above shows, the agent might easily get into a situation where it seems to be a good idea to take an extreme action. A very coarse but straightforward and cheap to compute heuristic for detecting at least some forms of extreme actions is when the corresponding aspiration is close to an extreme value of the feasibility interval: or .
This motivates the following generic safety criterion, the (relative, one-step) squared extremity of aspiration:
(The factor 4 is for normalization only)
The rationale is that using actions with rather low values of SEA would tend to make the agent's aspirations stay close to the center of the relevant feasibility intervals, and thus hopefully also make its actions remain moderate in terms of the achieved Total.
Let's see whether that hope is justified by studying what minimizing SEA would lead to in the above apple example:
The example shows that the consequence of minimizing SEA is not, as hoped, always an avoidance of extreme actions. Rather, the agent chooses the maximum action in the first two steps (which might or might not be what we eventually consider safe, but is certainly not what we hoped the criterion would prevent).
Maybe we should compare Deltas rather than aspirations if we want to avoid this? So what about (relative, one-step) squared extremity of Delta,
If the agent minimizes this instead of SEA in the apple example, it will procrastinate by choosing for the first several days, as long as . This happens on the first four days. On the fifth day (), it will still have aspiration 14. It will then again put with action-aspiration, but it will put with action-aspiration . Since the latter equals the state-aspiration, the calculated probability in step 3 of the algorithm turns out to be , meaning the agent will use action for sure after all, rather than randomizing it with . This leaves an aspiration of . On the remaining two days, the agent then has to use to fulfill the aspiration in expectation.
Huh? Even though both heuristics seem to be based on a similar idea, one of them leads to early extreme action and later relaxation, and the other to procrastination and later extreme action, just the opposite. Neither of them avoids extreme actions.
One might think that one could fix the problem by simply adding the two metrics up into a combined safety loss,
But in the apple example, the agent would still harvest six apples on the first day, since . Only on the second day, it would harvest just four instead of six apples, because is minimal. On the third day: two apples because is minimal. Then one apple, and then randomize between one or zero apples, until it has the 14 apples, or until the last day has come where it needs to harvest one last apple.
The main reason for all these heuristics failing in that example is their one-step nature which does not anticipate later actions. In the LW sequence we will talk about more complex, farsighted metrics that can still be computed efficiently in a recursive manner, such as disordering potential,
which measures the largest Shannon entropy in the state trajectory that the agent could cause if it aimed to, or terminal state distance,
which measures the expected distance between the terminal and initial state according to some metric on state space and depends on the actual policy and aspiration propagation scheme that the agent uses.
Let us finish this post by discussing other ways to combine several performance and/or safety metrics.
Defining a combined loss function like above by adding up components is clearly not the only way to combine several safety and/or performance metrics, and is maybe not the best way to do that because it allows unlimited trade-offs between the components.
It also requires them to be measured in the same units and to be of similar scale, or to make them so by multiplying them with suitable prefactors that would have to be justified. This at least can always be achieved by some form of normalization, like we did above to make SEA and SED dimensionless and bounded by .
Trade-offs between several normalized loss components can be limited in all kinds of ways, for example by using some form of economics-inspired "safety production function" such as the CES-type function
with suitable parameters and with . For , we just have a linear combination that allows for unlimited trade-offs. At the other extreme, in the limit of , we get , which does not allow for any trade-offs.
Such a combined loss function can then be used to determine the two actions , e.g., using a softmin policy as suggested above.
An alternative to this approach is to use some kind of filtering approach to prevent unwanted trade-offs. E.g., one could use one of the safety loss metrics, , to restrict the set of candidate actions to those with sufficiently small loss, say with, then use a second metric, , to filter further, and so on, and finally use the last metric, , in a softmin policy.
One can come up with many plausible generic safety criteria (see LW sequence), and one might be tempted to just combine them all in one of these ways, in the hope to thereby have found the ultimate safety loss function or filtering scheme. But it might also well be that one will have forgotten some safety aspects and end up with an imperfect combined safety metric. This would be just another example of a misspecified objective function. Hence we should again resist falling into the optimization trap of strictly minimizing that combined loss function, or the final loss function of the filtering scheme. Rather, the agent should probably still use a sufficient amount of randomization in the end, for example by using a softmin policy with sufficient temperature.
If it is unclear what a sufficient temperature is, one can set the temperature automatically so that the odds ratio between the least and most likely actions equals a specified value: for some fixed .
We saw earlier that if the goal is to make expected Total equal an aspiration value, , the set of successful policies has large but not full dimension and thus still has measure zero. In other words, making expected Total exactly equal to some value still requires policies that are very "precise" and in this regard very "special" and potentially dangerous. So we should probably allow some leeway, which should not make any difference in almost all real-world tasks but increase safety further by avoiding solutions that are too special.
Of course the simplest way to provide this leeway would be to just get rid of the hard constraint altogether and replace it by a soft incentive to make close to , for example by using a softmin policy based on the mean squared error. This might be acceptable for some tasks but less so for others. The situation appears to be somewhat similar to the question of choosing estimators in statistics (e.g., a suitable estimator of variance), where sometimes one only wants the estimator with the smallest standard error, not caring for bias (and thus not having any guarantee about the expected value), sometimes one wants an unbiased estimator (i.e., an estimator that comes with an exact guarantee about the expected value), and sometimes one wants at least a consistent estimator that is unbiased in the limit of large data and only approximately unbiased otherwise (i.e., have only an asymptotic rather than an exact guarantee about the expected value).
For tasks where one wants at least some guarantee about the expected Total, one can replace the aspiration value by an aspiration interval and require that .
The basic algorithm (algorithm 1) can easily be generalized to this case and only becomes a little bit more complicated due to the involved interval arithmetic:
Similar to algorithm 1, we...
More precisely: Let denote the midpoint of interval . Given state and state-aspiration interval ,
Note that the condition that no must be wider than in step 1 ensures that, independently of what the value of computed in step 3 will turn out to be, any convex combination of values is an element of . This is the crucial feature that ensures that aspirations will be met:
Theorem (Interval guarantee)
If the world model predicts state transition probabilities correctly and the episode-aspiration interval is a subset of the initial state's feasibility interval, , then algorithm 2 fulfills the goal .
The Proof is completely analogous to the last one, except that each occurrence of and is replaced by and , linear combination of sets is defined as , and we use the fact that implies .
Satisficing. The special case where the upper end of the aspiration interval coincides with the upper end of the feasibility interval leads to a form of satisficing guided by additional criteria.
Probability of ending in a desirable state. A subcase of satisficing is when all Deltas are 0 except for some terminal states where it is 1, indicating that a "desirable" terminal state has been reached. In that case, the lower bound of the aspiration interval is simply the minimum acceptable probability of ending in a desirable state.
This is how we use certain potentially ambiguous terms in this post:
Agent: We employ a very broad definition of "agent" here: The agent is a machine with perceptors that produce observations, and actuators that it can use to take actions, and that uses a decision algorithm to pick actions that it then takes. Think: a household's robot assistant, a firm's or government's strategic AI consultant. We do not assume that the agent has a goal of its own, let alone that it is a maximizer.
Aspiration: A goal formalized via a set of constraints on the state or trajectory or probability distribution of trajectories of the world. E.g., "The expected position of the spaceship in 1 week from now should be the L1 Lagrange point, its total standard deviation should be at most 100 km, and its velocity relative to the L1 point should be at most 1 km/h".
Decision algorithm: A (potentially stochastic) algorithm whose input is a sequence of observations (that the agent's perceptors have made) and whose output is an action (which the agent's actuators then take). A decision algorithm might use a fixed "policy" or a policy it adapts from time to time, e.g. via some form of learning, or some other way of deriving a decision.
Maximizer: An agent whose decision algorithm takes an objective function and uses an optimization algorithm to find the (typically unique) action at which the predicted expected value of the objective function (or some other summary statistic of the predicted probability distribution of the values of this function) is (at least approximately) maximal, and then outputs that action.
Optimization algorithm: An algorithm that takes some function (given as a formula or as another algorithm that can be used to compute values of that function), calculates or approximates the (typically unique) location of the global maximum (or minimum) of , and returns that location . In other words: an algorithm .
Utility function: A function (only defined up to positive affine transformations) of the (predicted) state of the world or trajectory of states of the world that represents the preferences of the holder of the utility function over all possible probability distributions of states or trajectories of the world in a way conforming to the axioms of expected utility theory or some form of non-expected utility theory such as cumulative prospect theory.
Loss function: A non-negative function of potential outputs of an algorithm (actions, action sequences, policies, parameter values, changes in parameters, etc.) that is meant to represent something the algorithm shall rather keep small.
Goal: Any type of additional input (additional to the observations) to the decision algorithm that guides the direction of the decision algorithm, such as:
Planning: The activity of considering several action sequences or policies ("plans") for a significant planning time horizon, predicting their consequences using some world model, evaluating those consequences, and deciding on one plan the basis of these evaluations.
Learning: Improving one's beliefs/knowledge over time on the basis of some stream of incoming data, using some form of learning algorithm, and potentially using some data acquisition strategy such as some form of exploration.
Satisficing: A decision-making strategy that entails selecting an option that meets a predefined level of acceptability or adequacy rather than optimizing for the best possible outcome. This approach emphasizes practicality and efficiency by prioritizing satisfactory solutions over the potentially exhaustive search for the optimal one. See also the satisficer tag.
Quantilization: A technique in decision theory, introduced in a 2015 paper by Jessica Taylor. Instead of selecting the action that maximizes expected utility, a quantilizing agent chooses randomly among the actions which rank higher than a predetermined quantile in some base distribution of actions. This method aims to balance between exploiting known strategies and exploring potentially better but riskier ones, thereby mitigating the impact of errors in the utility estimation. See also the quantilization tag.
Reward Function Regularization: A method in machine learning and AI design where the reward function is modified by adding penalty terms or constraints to discourage certain behaviors or encourage others, such as in Impact Regularization. This approach is often used to incorporate safety, ethical, or other secondary objectives into the optimization process. As such, it can make use of the same type of safety criteria as an aspiration-based algorithm might.
Safety Criterion: A (typically quantitative) formal criterion that assesses some potentially relevant safety aspect of a potential action or plan. E.g., how much change in the world trajectory could this plan maximally cause? Safety criteria can be used as the basis of loss functions or in reward function regularization to guide behavior.
Using Aspirations as a Means to Maximize Reward: An approach in adaptive reinforcement learning where aspiration levels (desired outcomes or benchmarks) are adjusted over time based on performance feedback. Here, aspirations serve as dynamic targets to guide learning and action selection towards ultimately maximizing cumulative rewards. This method contrasts with using aspirations as fixed goals, emphasizing their role as flexible benchmarks in the pursuit of long-term utility optimization. This is not what we assume in this project, where we assume no such underlying utility function.
The SatisfIA project is a collaborative effort by volunteers from different programs: AI Safety Camp, SPAR, and interns from different ENSs, led by Jobst Heitzig at PIK's Complexity Science Dept. and the FutureLab on Game Theory and Networks of Interacting Agents that has started to work on AI safety in 2023.
Motivated by the above thoughts, two of us (Jobst and Clément) began to investigate the possibility of avoiding the notion of utility function altogether and develop decision algorithms based on goals specified through constraints called "aspirations", to avoid risks from Goodhart's law and extreme actions. We originally worked in a reinforcement learning framework, modifying existing temporal difference learning algorithms, but soon ran into issues more related to the learning algorithms than to the aspiration-based policies we actually wanted to study (see Clément's earlier post).
Because of these issues, discussions at VAISU 2023 and FAR Labs, and comments from Stuart Russell, Jobst then switched from a learning framework to a model-based planning framework and adapted the optimal planning algorithms from agentmodels.org to work with aspirations instead, which worked much better and allowed us to focus on the decision making aspect.
As of spring 2024, the project is participating in AI Safety Camp and SPAR with about a dozen people investing a few hours a week. We are looking for additional collaborators. Currently, our efforts focus on theoretical design, prototypical software implementation, and simulations in simple test environments. We will continue documenting our progress in the LW sequence. We also plan to submit a first academic conference paper soon.
In addition to AISC, SPAR, VAISU, FAR Labs, and GaNe, we'd like to thank everyone who contributed or continues to contribute to the SatisfIA project.
The algorithm is based on the idea of propagating aspirations along time, and we prove that the algorithm gives a performance guarantee if the goal is feasible. Then we extend the basic algorithm by 1) adding criteria for choosing the two candidate actions the algorithm mixes, and 2) by generalizing the goal from making the expected Total equal a particular value to making it fall into a particular interval.
This might not be trivial of course if the agent might "outsource" or otherwise cause the maximization of some objective function by others, a question that is related to "reflective stability" in the sense of this post. An rule additional "do not maximize" would hence be something like "do not cause maximization by other agents", but this is beyond the scope of the project at the moment.
Information-theoretic, not thermodynamic.
This is also why Sutton and Barto's leading textbook on RL starts with model-based algorithms and turns to learning only in chapter 6.
When we extend our approach later to incorporate performance and safety criteria, we might also have to assume further functions, such as the expected squared Delta (to be able to estimate the variance of Total), or some transition-internal world trajectory entropy (to be able to estimate total world trajectory entropy), etc.
Note that this type of goal is also implicitly assumed in the alternative Decision Transformer approach, where a transformer network is asked to predict an action leading to a prompted expected Total.
If the agent is a part of a more complex system of collaborating agents (e.g., a hierarchy of subsystems), the "action" might consist in specifying a subtask for another agent, that other agent would be modeled as part of the "environment" here, and the observation returned by might be what that other agent reports back at the end of its performing that subtask.
It is important to note that might be an incomplete description of the true environment state, which we denote but rarely refer to here.
Note that we're in a model-based planning context, so it directly computes the values recursively using the world model, rather than trying to learn it from acting in the real or simulated environment using some form of reinforcement learning.
These assumptions may of course be generalized, at the cost of some hassle in verifying that expectations are well-defined, to allow cycles or infinite time horizons, but the general idea of the proof remains the same.
E.g., assume the agent can buy zero or one apple per day, has two days time, and the aspiration is one apple. On the first day, the state's feasibility interval is , the action of buying zero apples has feasibility interval and would thus get action-aspiration 0.5, and the action of buying one apple has feasibility interval and would thus get action-aspiration 1.5. To get 1 on average, the agent would thus toss a coin. So far, this is fine, but on the next day the aspiration would not be 0 or 1 in order to land at 1 apple exactly, but would be 0.5. So on the second day, the agent would again toss a coin. Altogether, it would get 0 or 1 or 2 apples, with probabilities 1/4, 1/2, and 1/4, rather than getting 1 apple for sure.
That the algorithm uses an optimization algorithm that it gives the function to maximize to is crucial in this definition. Without this condition, every agent would be a maximizer, since for whatever output the decision algorithm produces, one can always find ex post some function for which .
![Bob Jacobs [inactive]](https://res.cloudinary.com/cea/image/upload/c_crop,g_custom/c_fill,dpr_2,q_100,f_auto,g_auto:faces,w_36,h_36,b_white/Profile/w5vjftvndjb0tsxvugwg)

Executive summary: The SatisfIA project explores aspiration-based AI agent designs that avoid maximizing objective functions, aiming to increase safety by allowing more flexibility in decision-making while still providing performance guarantees.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.