Agreed. It also doesn't seem to me that even a successful alignment of AGI to "human values"--the same values which gave us war, slavery, and even today still torture billions of sentient beings per year before killing them--is prima facie a good thing.
Does AI alignment imply that the AGI must care about blind spots in today's "human values", and seek to expand its circle to include moral patients who would otherwise have been ignored? Not necessarily.
There's been tons of discussion about this, and I think most of the field disagrees, and there are some complications you're missing.
In the introduction to a paper last year, Issa Rice and I tried to clarify some definitions, which explains why "control" isn't the same as "alignment":
The term AI-safety also encompasses technical approaches that attempt to ensure that humans retain the ability to control such systems or to restrict the capabilities of such systems (AI control), as well as approaches that aim to align systems with human values—that is, the technical problem of figuring out how to design, train, inspect, and test highly capable AI systems such that they produce all and only the outcomes their creators want (AI alignment).
"AGI existential safety" seems like the most popular relatively-unambiguous term for "making the AGI transition go well", so I'm fine with using it until we find a better term.
I think "AI alignment" is a good term for the technical side of differentially producing good outcomes from AI, though it's an imperfect term insofar as it collides with Stuart Russell's "value alignment" and Paul Christiano's "intent alignment". (The latter, at least, better subsumes a lot of the core challenges in making AI go well.)
I hate to be someone who walks into a heated debate and pretends to solve it in one short post, so I hope my post didn’t come off too authoritative (I just genuinely have never seen debate about the term). I’ll look more into these.
I think some of these problems apply to the term "AI safety" as well. Say we built an AGI that was 100% guaranteed not to conquer humanity as a whole, but still killed thousands of people every year. Would we call that AI "Safe"?
One possible way to resolve this is for:
"misalignment" refers to the AI not doing what it's meant to do
"AI safety" refers to ensuring that the consequences of misalignment are not majorly harmful
"AI X-risk safety" refers to ensuring that AI does not destroy or conquer humanity.
Each one being an easier subset of the problem above it.
"AI safety" refers to ensuring that the consequences of misalignment are not majorly harmful
That's saying that AI safety is about protective mechanisms and that alignment is about preventative mechanisms. I haven't heard the distinction drawn that way, and I think that's an unusual way to draw it.
So partially what I'm saying is that the definitions of " AI alignment" and "AI safety" are confusing, and people are using them to refer to different things in a way that can mislead. For example, if you declare that your AI is "safe" while it's killing people on the daily (because you were referring to extinction), people will rightly feel mislead and angry.
Similarly, for "misalignment", an image generator giving you an image of a hand with the wrong number of fingers is misaligned in the sense than you care about the correct number of fingers and it doesn't know this. But it doesn't cause any real harm the way that a malfunction in a healthcare diagnoser would.
Your point about safety wanting to prevent as well as protect is a good one. I think "AI safety" should refer to both.
Let me start by saying that I generally hate pedantic arguments, so I don't see this post as the most important thing in the world. More important than not calling it AI Alignment is actually ensuring AI Safety, obviously.
Still, the phrase "AI Alignment" has always bugged me. I'm not an AI researcher or anything, so my subject matter knowledge is not very deep, but from my understanding AI Alignment is a poor description of the issue actually at hand. AI Safety is more about control than alignment.
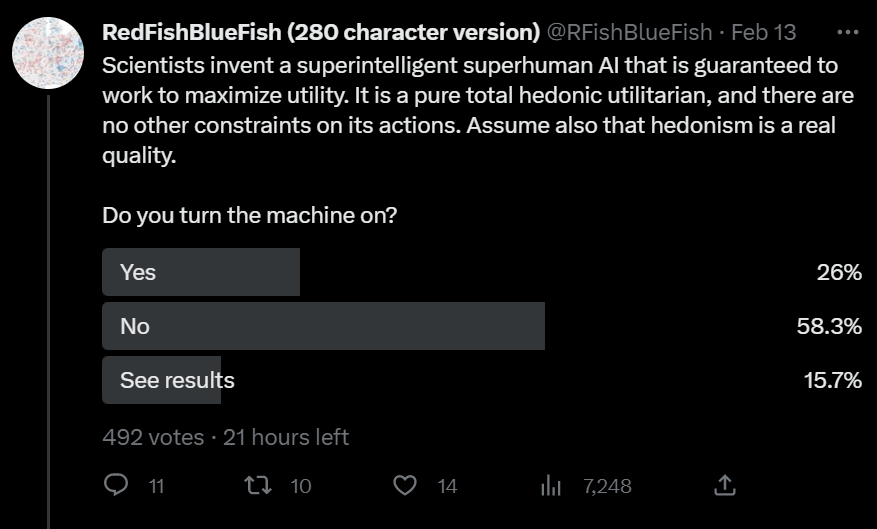
To illustrate, let me display a Twitter poll I recently ran:
Taking out the See Results, that's around 30% Yes, 70% No.
I would guess that respondents are >2/3 EA/rationality people or similar - my follower count is not very large and is a mix of EA and politics people, but it was retweeted by Peter Wildeford, Natalia Coelho, Ezra Newman and (at)PradyuPrasad. 70% of EAs identified as utilitarian in the 2019 EA survey; I'm not sure how these respondents compare to that but they are probably pretty similar. Either way I'd estimate that >25% of people who are mostly hedonic total utiliarians voted No on this question.
Even with what is in my view the most complete and plausible ethical theory we have, a substantial fraction of believers still don't want an AI exclusively aligned to this theory. Add in the large contentious disagreements that humans (or even just philosophers) have about ethics, and it is pretty clear that we can't just give AI an ethical theory to run with. This is not to mention the likely impossibility of making an AI that will optimize for utilitarianism or any other moral philosophy. Broadening it to human values rather than a specific moral philosophy, these values are similarly contentious, imprecise and not worth optimizing for in an explicit manner.
An alternative, from my experience less frequently used, definition of AI Alignment is aligning AI to the intent of the designer (this is what Wikipedia says). The problem is that AGI systems themselves, partly by definition, don't have one intent. AGI systems like ChatGPT (yes it is AGI, no it is not human-level AGI) are broad in capabilities and are then applied by developers to specific problems. AI Safety is more about putting constraints on AI models rather than aligning them to one specific task.
What we really want is an AI that won't kill us all. The goal of AI Safety is to ensure that humanity has control over its future, that AIs do not start to dominate humanity in the same way humanity dominates all other species. Aligning AI to human values or to any specific intent is relatively unimportant so long as we make sure their actions are within our control. I think calling AI Safety "AI Alignment" or referring to "The Alignment Problem" misleads people as to what the issue actually is and what we should do about it. Just call it AI Safety, and either call the technical problem "AI Control" or drop the (IMO also misleading) idea that there is "one" problem that we are trying to solve.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...


Agreed. It also doesn't seem to me that even a successful alignment of AGI to "human values"--the same values which gave us war, slavery, and even today still torture billions of sentient beings per year before killing them--is prima facie a good thing.
Does AI alignment imply that the AGI must care about blind spots in today's "human values", and seek to expand its circle to include moral patients who would otherwise have been ignored? Not necessarily.