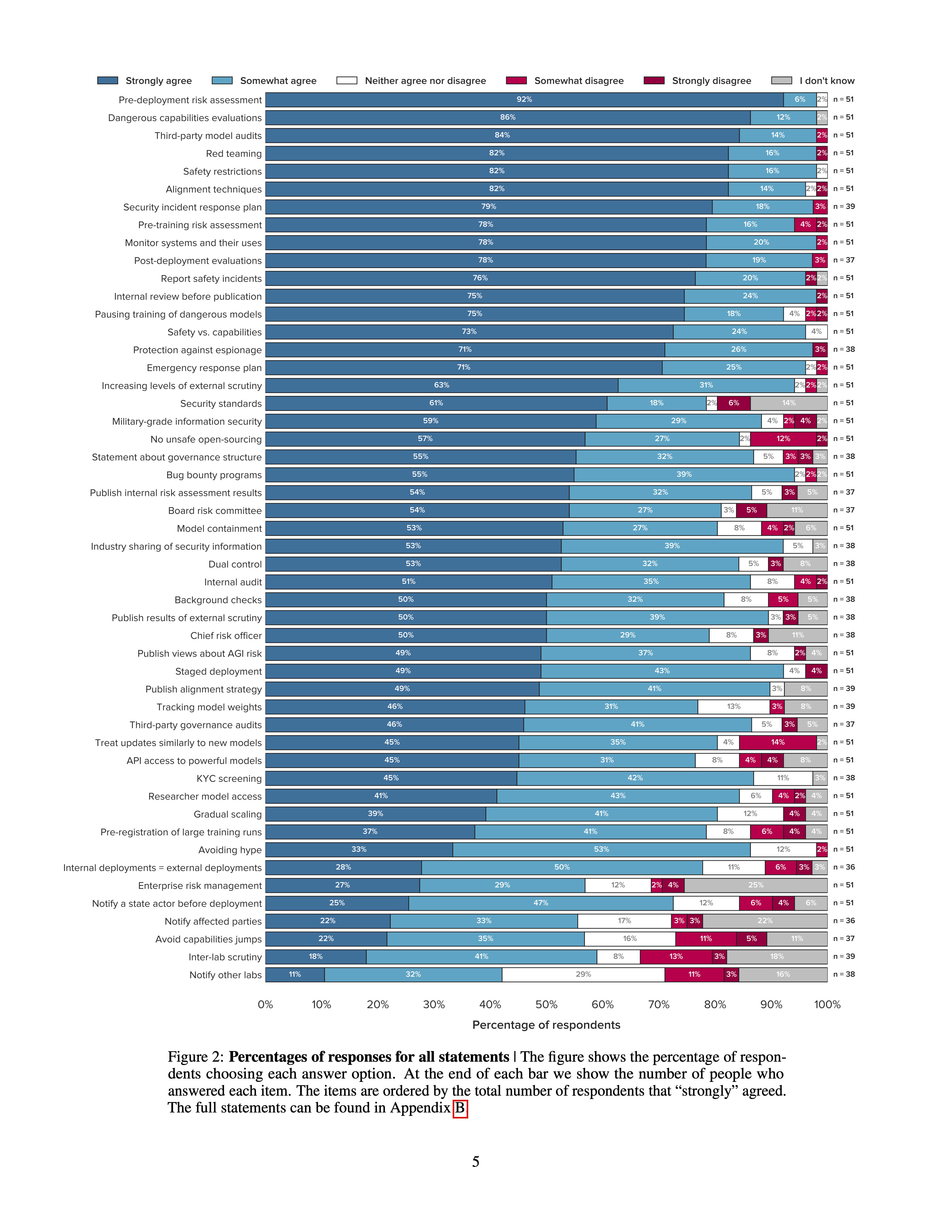
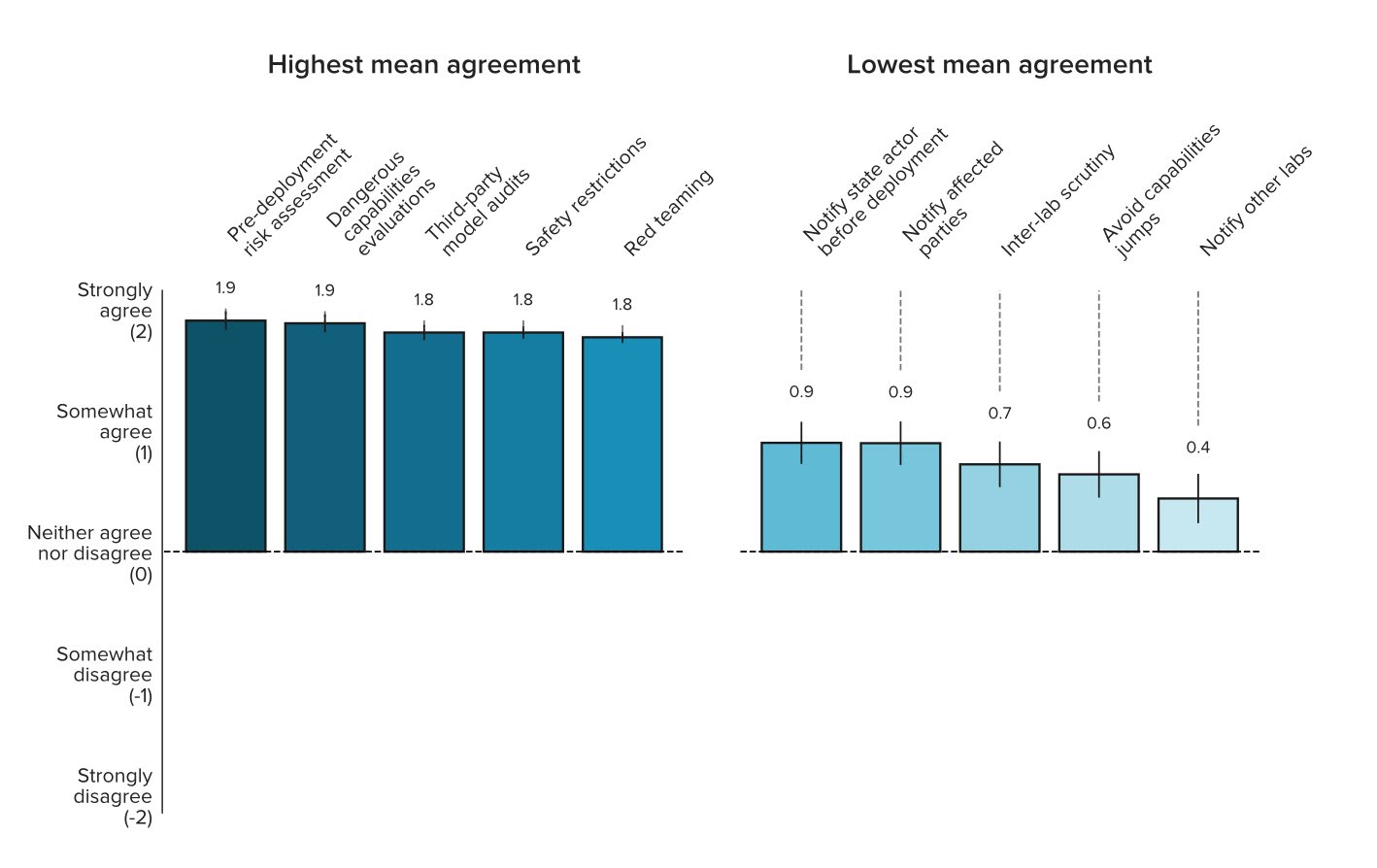
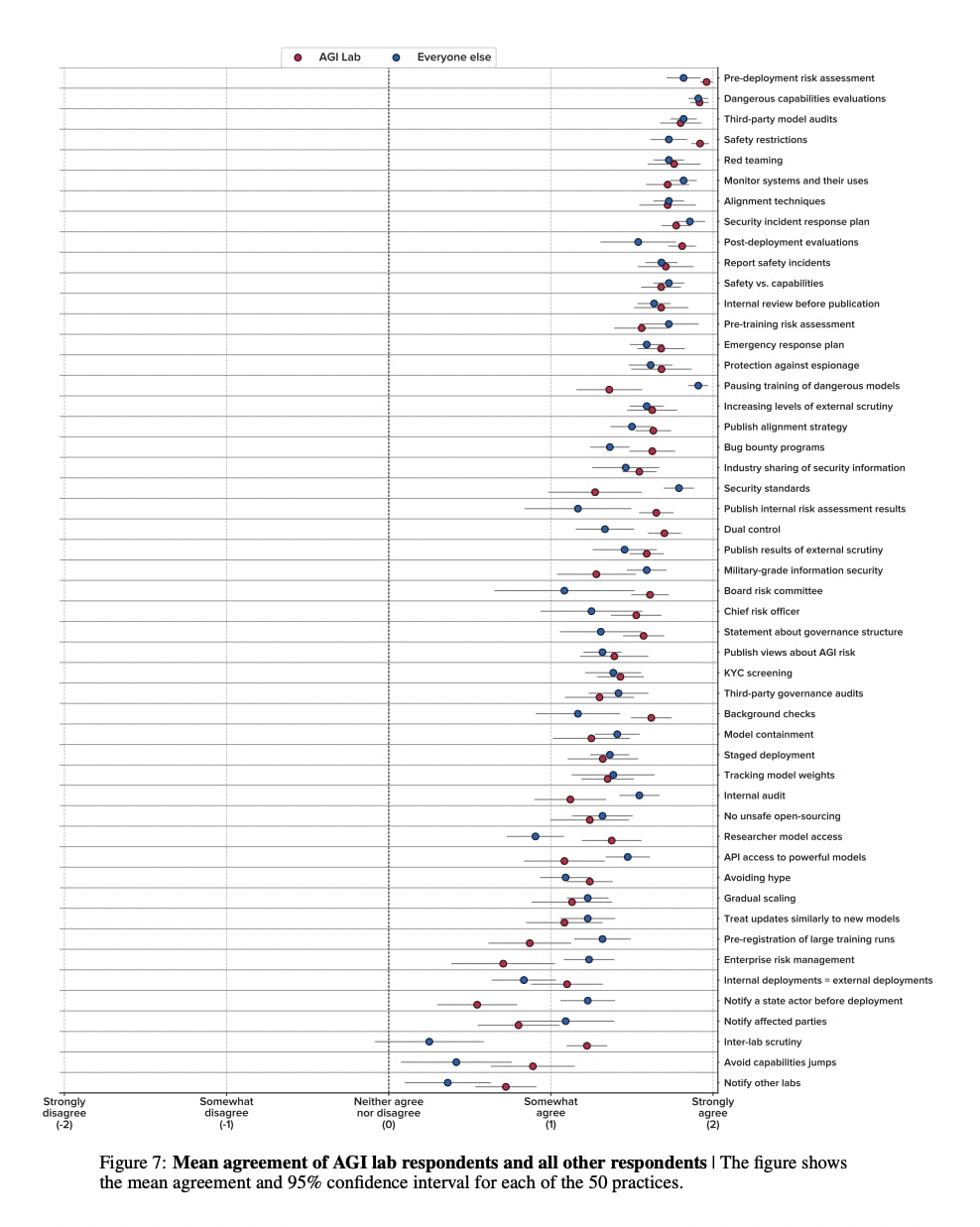
A number of leading AI companies, including OpenAI, Google DeepMind, and Anthropic, have the stated goal of building artificial general intelligence (AGI) - AI systems that achieve or exceed human performance across a wide range of cognitive tasks. In pursuing this goal, they may develop and deploy AI systems that pose particularly significant risks. While they have already taken some measures to mitigate these risks, best practices have not yet emerged. To support the identification of best practices, we sent a survey to 92 leading experts from AGI labs, academia, and civil society and received 51 responses. Participants were asked how much they agreed with 50 statements about what AGI labs should do. Our main finding is that participants, on average, agreed with all of them. Many statements received extremely high levels of agreement. For example, 98% of respondents somewhat or strongly agreed that AGI labs should conduct pre-deployment risk assessments, dangerous capabilities evaluations, third-party model audits, safety restrictions on model usage, and red teaming. Ultimately, our list of statements may serve as a helpful foundation for efforts to develop best practices, standards, and regulations for AGI labs.
I'm really excited about this paper. It seems to be great progress toward figuring out what labs should do and making that common knowledge.
(And apparently safety evals and pre-deployment auditing are really popular, hooray!)
Edit: see also the blogpost.



By the way, the paper "Towards best practices in AGI safety and governance", which seems relevant to this post, was evaluated by The Unjournal – see https://doi.org/10.21428/d28e8e57.ef6f66cd. Please let us know if you found our evaluation useful and how we can do better; we’re working to measure and boost our impact. You can email us at [email protected], and we can schedule a chat. (Semi-automated comment)