
Lizka
Bio
I'm a researcher at Forethought; before that, I ran the non-engineering side of the EA Forum (this platform), ran the EA Newsletter, and worked on some other content-related tasks at CEA. [More about the Forum/CEA Online job.]
Selected posts
- Disentangling "Improving Institutional Decision-Making"
- [Book rec] The War with the Newts as “EA fiction”
- EA should taboo "EA should"
- Invisible impact loss (and why we can be too error-averse)
- Celebrating Benjamin Lay (died on this day 265 years ago)
- Remembering Joseph Rotblat (born on this day in 1908)
Background
I finished my undergraduate studies with a double major in mathematics and comparative literature in 2021. I was a research fellow at Rethink Priorities in the summer of 2021 and was then hired by the Events Team at CEA. I later switched to the Online Team. In the past, I've also done some (math) research and worked at Canada/USA Mathcamp.
Posts 173
Comments580
Topic contributions267
[I don't want to spam the Quick Takes section, so I'll use this thread as a place to jot down some meta-ish notes on research and writing. (I might find a better place for this stuff later.)]
...
Some reasons I poke at words (i.e. when I ask "what do you mean by...?"[1])
- I’m just caught up in pedantry / unnecessary nuance-finding
- (I'm noticing a distinction that could be made, or some vagueness at the corners of this term, or a pathological example that doesn't fit neatly into the category they're trying to use ---- but it's not actually that relevant or important)
- I would personally value clarification / feel blocked by my uncertainty
- I am just not following things / can't picture what you mean / don't know if you're using this as some kind of jargon; I'm having trouble engaging with the rest without clarification here.
- -> A variant of this makes it hard for me to engage with IMO-half-operationalized exercises or questions
- like "what are your timelines" (to what?) or "rate this 1-10 on impact" (what do you mean by impact exactly?) or "how much influence do you think altruists/idealists have?" (...)
- I'm trying to flag that a particular group of people will probably interpret the term in problematic ways
- (i.e. not how you're trying to use it)
- I’m quickly reporting a bit of unprocessed "user feedback" about a reaction I notice in myself
- Even if I can work through this myself, the doc can probably be improved here
- I’ve noticed I feel confused and suspect that might be tracking a real issue with the terminology or with your argument
- (or maybe I’m misinterpreting)
- I can’t picture what this is meant to point to and don’t know if the (provisional?) use of the term is fake or not;
- you may want to consider tabooing it, and I would probably personally appreciate it
- [Probably others, may add later]
Tbc often the background generator of a comment like this (especially before I've written it out-- when I'm at the point of considering saying or writing something) is not an explicit thought, and certainly not something that cleanly maps into one of the above. Often it's just a fuzzy intuition that something is off; things aren't matching up/ they're of the wrong type, or I'm struggling to keep a picture in mind (I'm just lost and can't even start putting it together or I'm failing to make one that doesn't look absurd, ...), or I'm feeling something like triggered by the word (maybe because I've seen people talk past each other with it in frustrating ways, or because I have sometimes felt like it's circular in the bad way), ... This list was a quick attempt at noticing the differences later; I think I should train myself to notice more easily what's going on, and in some cases I should process things more before posting or saying anything (and what to do will depend on the case I'm in).
==
(For "practical advice on threading the needle between pedantry and just vibing", I remember liking this post btw, but I don't remember exactly how relevant it was. Also stuff on inferential distances, maybe)
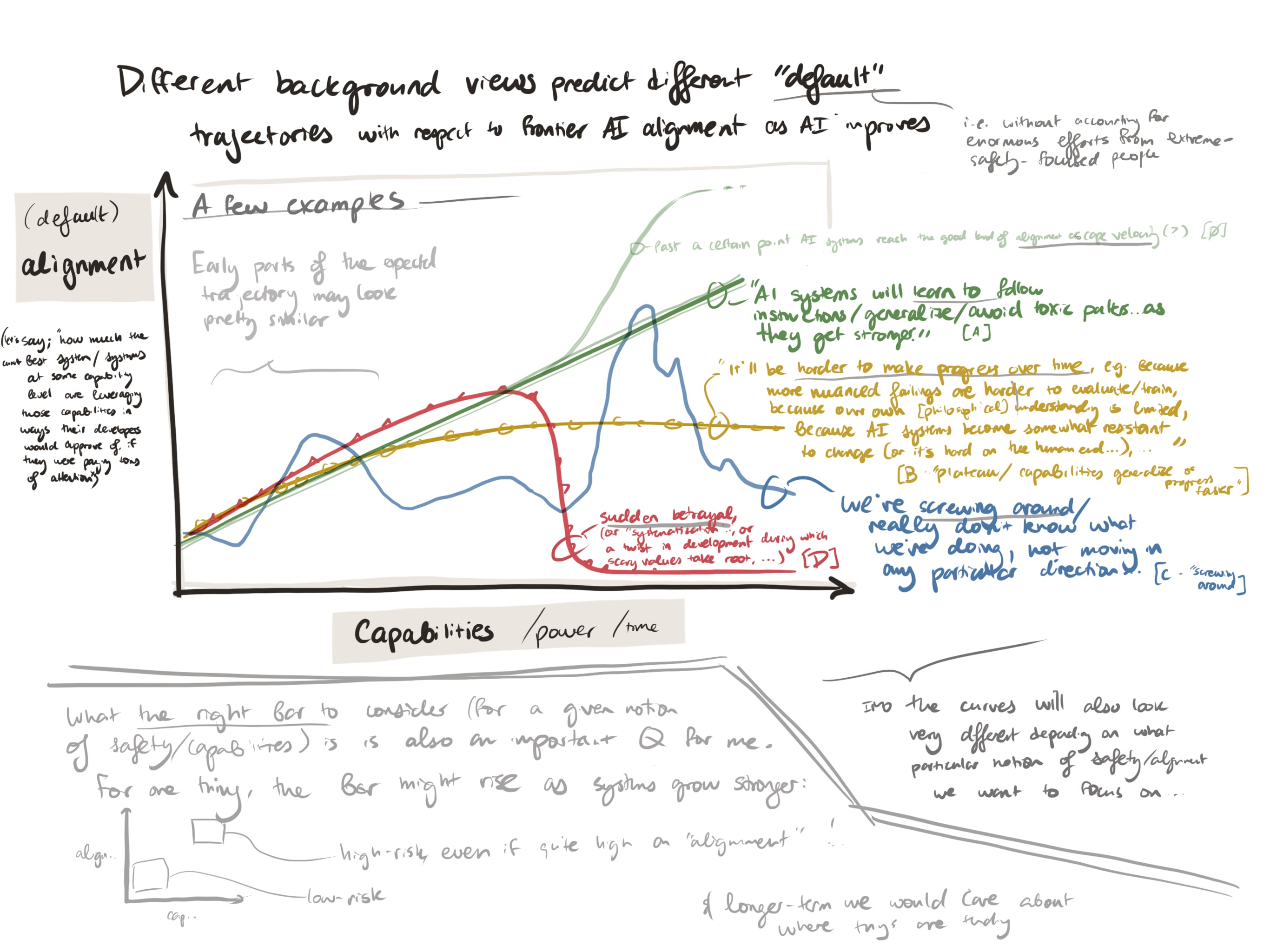
People have pretty different background expectations about what the most relevant or worrying kind of AI misalignment /takeover/... scenario would look like. This also corresponds to different views on when they expect signs of it to be visible (such that not seeing those signs or seeing something else would update them). Among other issues, I think this confuses discussion around whether (e.g.) "alignment is easy" or how we should be updating.[1]
My brain likes pictures, so I've found it useful to tag different views and discussions via the following diagrams (these are pretty "raw"/not-distilled):
1)
2) And a second one, roughly:
how much systems at a given capability level appear safe vs where they actually are on the path or spectrum to the kind of safety we care about[2].
(This also has some more notes on how people might relate differently to the same results / evidence.)

These are very messy sketches! I'm sharing because I made a hacky commitment to post short things and in case it's useful for someone (or in case a comment helps clarify things for me, which I'd definitely appreciate). There's some chance that I'll clean these up and update them later.
- ^
Related: "conflationary alliances" (see also a post with a version of this dynamic about "charity" on the Forum)
- ^
Again, a huge part of the problem/confusion seems to be that this is a very underdetermined term; see footnote above. Also feels sort of related to things I wrote about here
(altohugh I'm guessing it's also partly due to the fact that this is a basically unedited sketch and I first drew this because a similar image had come to mind in a variety of contexts, and I wanted a version I could adapt as needed - i.e. it was meant to be flexible. If I were making a v2 I'd probably want to commit more, though.)
Also relevant (sort of[1]) — this cool post from Chris Olah & Adam Jermyn (from a while back): Reflections on Qualitative Research
I’m not sure if it’d be remotely compelling to people who have a very different perspective overall (I'm already fairly sympathetic; see e.g. my "y-axis" post).
Still, pulling out a few parts I appreciated:
[…] For Want of Constrained Hypothesis Space
One of the reasons mature fields can rely so much on summary statistics is that they have a constrained hypothesis space. […] in pre-paradigmatic fields we don’t know what hypotheses to consider! A physicist in the 1800s coming up with explanations for energy production in the Sun would have entirely missed nuclear physics.
So the goal of science in pre-paradigmatic fields is to first figure out what hypotheses we should be considering! And this means working in a rather different way…
[…] Why are summary statistics so popular? One reason involves the ecosystem of interfaces for scientific research. We don’t often think of things this way, but scientific research implicitly involves interfaces for thinking about data. For example equations, line plots, and terminology are all interfaces.
[…]
Rigor and The Signal of Structure
How do we know if qualitative results are “real”? What does rigorous qualitative research look like?
We don’t have tools like “statistical significance” to fall back on, and so it’s easy for this research to seem non-rigorous. […] We suspect that one of the most reliable ways to know that a qualitative result is trustworthy is what we’ll call the signal of structure:
The signal of structure is any structure in one’s qualitative observations which cannot be an artifact of measurement or have come from another source, but instead must reflect some kind of structure in the object of inquiry, even if we don’t understand it.
You might think of this as the informal, “unsupervised” version of statistical significance. Whereas statistical significance tests a particular (hopefully pre-registered) hypothesis against a null hypothesis, the signal of structure observes an unpredicted high-dimensional pattern and rejects the hypothesis it was noise or an artifact, typically because the structure is so compelling and complex that it’s clearly orders of magnitude past the bar.
[…] It’s worth noting that it’s also exceedingly easy to fool oneself with qualitative research. (This is likely another reason why scientists are often skeptical of it!) …
Some signs of good qualitative work include:
- The Signal of Structure.
- A principled understanding of what you’re seeing and why it makes sense to look at. A magnifying glass makes things bigger; the weights of a neural network are the fundamental computational substrate of them.
Related: What's So Bad About Ad-Hoc Mathematical Definitions? (discussion here IIRC)
Sort of related: “Research as a Stochastic Decision Process” — my mental motto version of the post is something like “try to be greedy about the rate at which you’re gaining/producing information/clarity”
Also from Chris Olah (and Shan Carter), and IMO great: Distillation and research debt
I've found the following abstract frame/set of heuristics useful for thinking about how we can try to affect (or predict) the long-term future:
“How do we want to spend our precision/reach points? And can we spend them more wisely?”
[Meta: This is a rough, abstract, and pretty rambly note with assorted links; I’m just trying to pull some stuff out and synthesize it in a way I can more easily reference later (hoping to train habits along these lines). I don't think the ideas here are novel, and honestly I'm not sure who'd find this useful/interesting. (I might also keep editing it as I go.]
An underlying POV here is that (a) scope and (b) precision are in tension. (Alts: (a) "ambition / breadth / reach / ...” — vs — (b) “predictability / fidelity / robustness / ...”). You can aim at something specific and nearby [high precision, limited reach] or at something larger and farther away, fuzzier [low precision, broad reach]. And if you care about the kind of effect you’re having (you want to make X happen, not just looking for influence ~for influence’s sake), this matters a bunch.
Importantly, I think there are “architectural” features of the world/reality[1] that can ease this tension somewhat if they're used properly; if you channel your effort through them, you can transmit an intervention without it dissipating (or getting warped) as much as it otherwise would. Any channels like this will still be leaky (and they’re limited), but this sort of “structure” seems like the main thing to look for if you’re hoping to think about or improve the long-term future.
(See a related sketch diagram here. I also often picture something like: “what levers could reach across a paradigm shift?” (or: what features are invariant in relevant ways?))
Some examples / thinking this through a bit:
- Trying to organize or steer a social movement (/big group of people) might extend your reach, but you generally sacrifice precision/fidelity by doing that; the group might get derailed, the ideas might mutate (or just get blurrier / diluted), etc.[2]
- Sometimes people build unusually stable social structures (i.e. ones that don’t change that much).[3] Maybe some religious orders are like this. I think these often exploit a pattern like “encouraging strong+loud commitment to various kinds of norms is self-reinforcing”.
- (The broader pattern here might be about creating a thing that can maintain homeostasis, and the trick is finding healthy versions/.)
- (On that note, questions like “Where do (did?) stable, cooperative institutions come from?” seem really useful to explore.)
- Betting on long-lasting institutions could let you extend your reach by leveraging the likely persistent role(?)/relative stability of those institutions
- ...but you’re still paying a scope and/or precision/fidelity cost (there are only particular ways that you can shape an institution’s behavior, in some scenarios an institution that looks relevant won’t matter at all for what you care about, it might just get in the way, etc.)
- E.g. trying improve a government body’s decision-making with the hope that it’ll help with AI governance
- Relatedly, particular high-plasticity moments (or catalyzing/disruptive events) might matter a lot, and we might be able to predict some of them+what matters, and be better prepared for them.
- E.g. maybe a bunch of countries/actors will come together and write something like a new declaration of human rights. Or something may act as a “warning shot”, and for some (brief?) time high-inertia things like what the public cares about or the structure of a major institution might become very malleable.
- This is significant for how I think about AI. (See “the crucible” or “AI as a constitutional moment.”[4])
- The other side of high-plasticity moments is the possibility of crystallization/lock-ins/strong basins. (See dynamism, value lock-in, ...)
- Other high-level asymmetries can also function as “structure” in this way:
- E.g. perhaps truth or certain virtues are self-reinforcing and generally beneficial, or tend to good equilibria; we can use this kind of thing to ~bootstrap
- See “Good governance escape velocity”, “promoting x x-ingly”, aligning to virtues... (stuff like superrationality / meta cooperative principles?)
- Or a different pattern/feature: if we’re in some not-too-stable social equilibrium (e.g. many people afraid of expressing a view), then acting (as an individual) in a true-to-yourself way can break that equilibrium — see “being a fixed point”.
- (A more zoomed out “pattern” here might just be that “good things are good”)
- E.g. perhaps truth or certain virtues are self-reinforcing and generally beneficial, or tend to good equilibria; we can use this kind of thing to ~bootstrap
And so the point is that some projects find significantly “smarter” paths through this <reach (things have a small effect) vs precision (things don't have the effect you want)> space, piggybacking on features of reality that are more stable and predictably causally linked. I.e. it helps to orient to ~casual chokepoints that are close enough to predict/act on (we know stuff about them, we can use them as operational targets -- they’re on the right horizon/within reach), but causally upstream of enough important stuff for improvements to propagate down and make a big (positive!) difference.
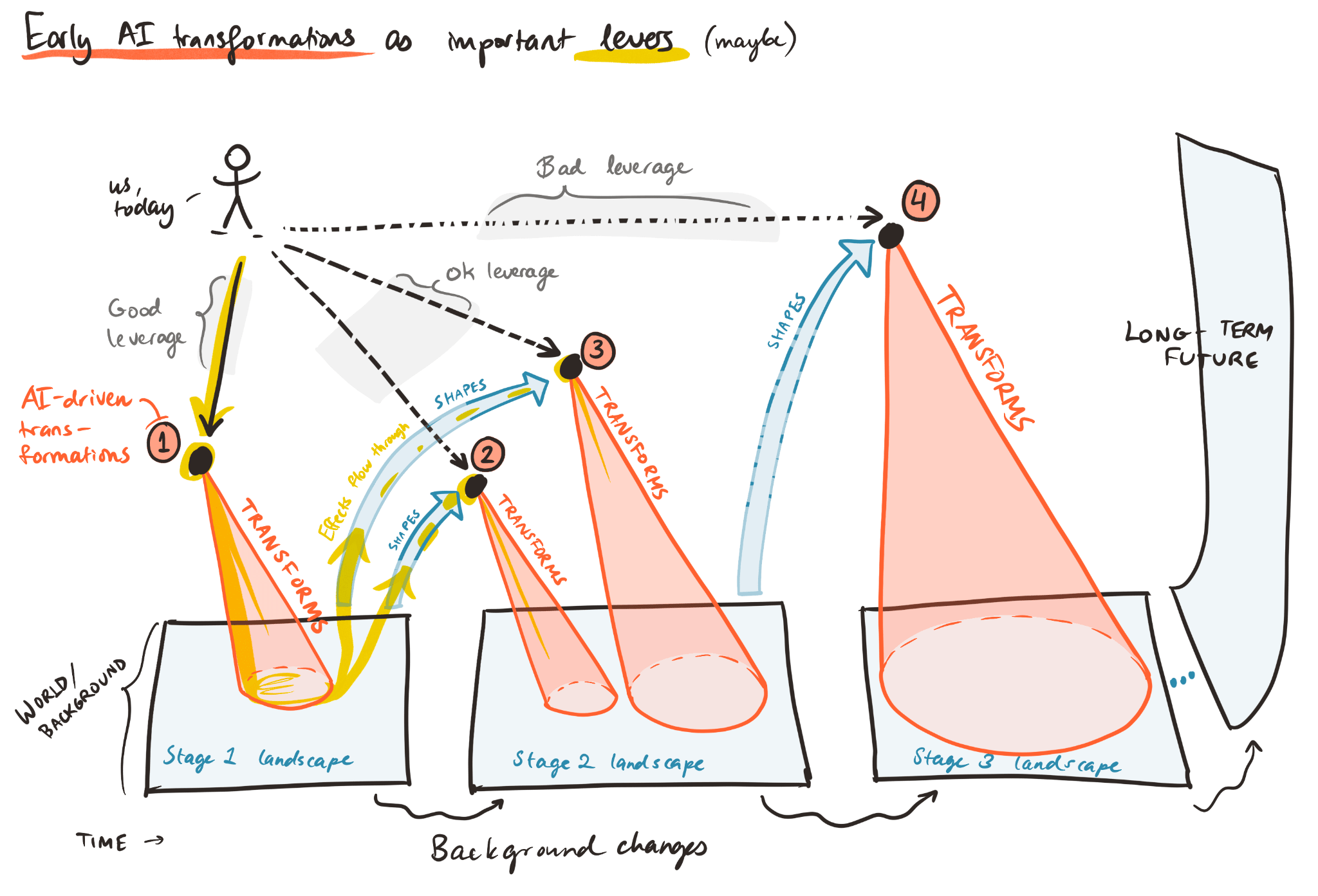
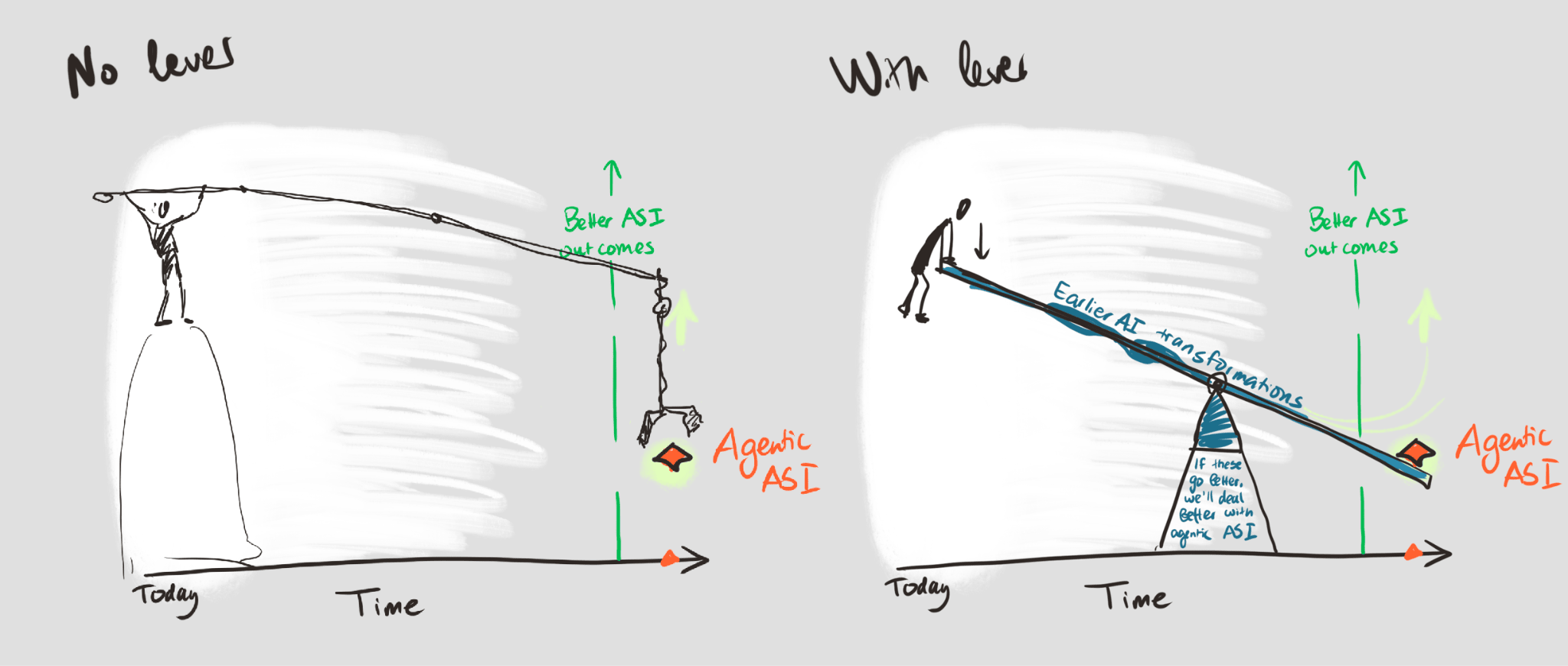
I wrote most of this when we were working on the “First type of transformative AI?” post (here's the Forum version); I’d found it very natural to translate some of that into the above frame.
Something like:
-> People often zero in on something like the "boss battle" AI challenge (e.g. ~ASI), but — even assuming that's the main threat — aiming directly for dealing with later-stage AI transformations seems like it's often an inefficient way of spending your precision/reach points (relative to channeling your effort through shaping earlier AI impacts).
I.e. (barring something like the "silent-IE" trajectory here) —
If AI will have transformed a bunch of other stuff by the time the issue shows up, the world you're preparing for will be radically different than the one you're used to (and harder to predict).
- If you try to do something specific/robust/..., there's a greater chance that your work will be irrelevant (or it'll only help with the small slice of things/scenarios you can predict more specifically); your scope is very narrow.
- If you do something much more ambitious, you really need to hope that the intervention is actually helpful instead of getting warped / distracted along the way (moves like trying to start a movement, which could end up harmful or pushing for things that aren't that useful, or e.g. trying to lock in a particular power structure or set of norms before knowing more about what's going on).
(This is basically just the usual pattern. You can maybe think of it as having "how much AI has changed the world" on the X-axis instead of "time into the future")
Meanwhile, earlier-in-the-queue AI impacts might provide us with really good “channels”/levers (for affecting the long-term):
- They're "within reach" — we know more about how AI is changing things now, have more access/ability to change things (plus this is getting less attention)
- In some cases I think shaping how this plays out could be a reasonably good way to faithfully “transmit” the effects of our effort
- E.g. because we have reason to believe that they’re causally connected to later shifts in particular ways (e.g. the good kind of positive feedback loop on epistemics/coordination; if this change goes better, we’ll be nontrivially better set up for dealing with AI takeover threats / power concentration issues, ...)
- (For epistemics/coordination effects I also think they'd help quite a bit with other potential challenges -- it's a bit like "general capacity for sense" in my mind. But I expect this "causal connection" step is really tricky more generally and maybe voids some of this frame? )
- I think we can point to some that matter a lot; orienting to them doesn't limit the scope too much (even if they’re not “the big one”);
- (Even if you only consider the effects on AI-disempowerment threats, I think shaping how e.g. AI gets deployed in information ecosystems could matter a lot.)
To be clear: “how earlier AI impacts go” definitely isn't the only kind of channel/ causal chokepoint we can use to try to improve “how AI goes” or to help with "boss battles" etc. E.g.
- The nature of advanced AI systems is obviously critical and seems (somewhat) predictably affectable; on some views shaping something like ASI is “within reach” (i.e. you should just directly work on something like prosaic superhuman-AI-alignment), or maybe you should work on bootstrapping to safely automated alignment (/virtuous cycles on this front), or maybe the internal processes of the major AI companies are the key thing, and so on.
- I also think the order of different AI capabilities could matter a lot, and we might have some “differential AI development” opportunities.
- ...
Still, I continue to think that people focus too much on something like the "silent-IE" path here, and too little on “in which ways could AI massively change things early — before disempowerment-threatening-ASI — and can we improve how that goes?”
(At the time I also wrote the following (still true): Having written that, I find myself wanting to look closer at the “architecture” of potential early transformations; what are important early transformations that give us some predictability channel? Etc.)
Anyway, I like this as a “find a route to impact/predictability that makes use of more robust/persistent features” prompt. In my mind it’s also quite related to how I would prefer people orient to speculative BOTECs; find “features” related to the question you care about that are more stable (including inputs that are more grounded and a way to put them together that you trust). (Related section of my “ITN 201” post. See also this note on using simpler models.)
I think similar dynamics apply in a bunch of other places, too.[5]
== Some only-very-marginally-relevant images ==
An old sketch illustrating a sort of related idea (trying to see further-out "beacons" is useful, but it's also useful to have a "nearer" target that you can actually visualize, even if it's flawed, which was a major motivation for the design sketches work):
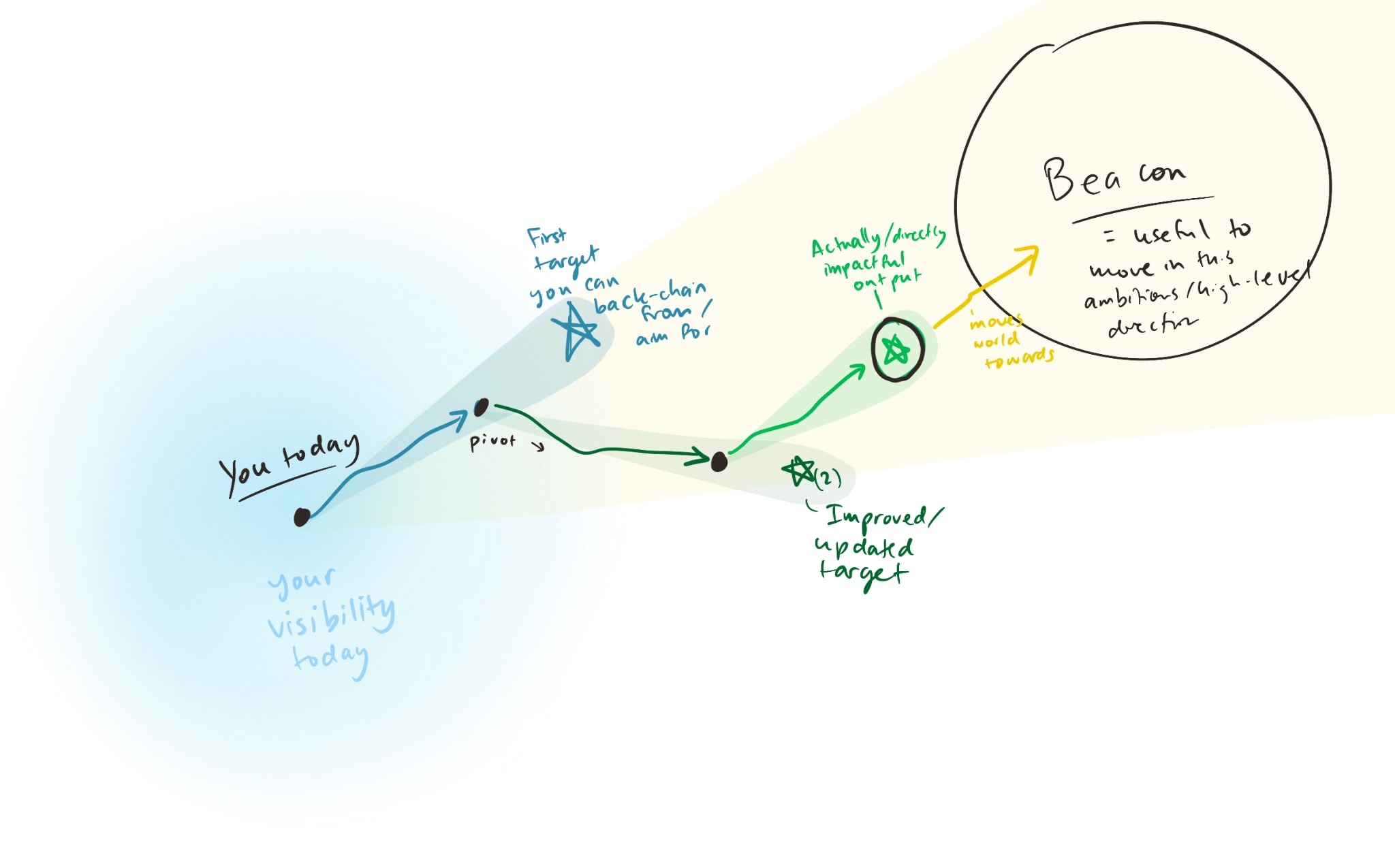
Another rough diagram (from over a year ago, now, I think):

And just for fun I'll add a couple other sketches in this footnote (people told me around when I made them that they were largely incomprehensible, IIRC).[6]
- ^
- ^
People often have quite a bit of choice in how to navigate the ~precision-breadth tradeoff, though, I think. See e.g. The fidelity model of spreading ideas
- ^
It's probably more accurate to say "...sometimes unusually stable social structures arise", actually.
My model is that they're often not really designed by anyone.
Similarly I think “leaders” of broad social structures (including e.g. revolutions) are often "selected in" or "leading the parade" rather than doing something like directing. (A check with Claude suggests that original main leaders/planners of successful revolutions usually did not hold power for at least 5 years [5-7/29 cases, apparently], and ~rarely achieved their stated political goals.)
Semi-related: (social) system dynamics are quite counterintuitive, “places to intervene in a system.”
- ^
I also remember appreciating Acemoglu’s Institutions, Technology and Prosperity
- ^
Related shortform by my brother (bold mine):
[...] This doesn't mean we need to give up, or only work on unambitious, practical applications. But it does mean that we have to admit that things can be useful to work on in expectation before we have a "complete story for how they save the world".
Note that what is being advocated here is not an "anything goes" mentality. I certainly think that AI safety research can be too abstract, too removed from any realistic application in any world. But there is a large spectrum of possibilities between "fully plan how you will solve a complex logic game before trying anything" and "make random jerky moves because they 'feel right'".
I'm writing this in response to Adam Jones' article on AI safety content.. I like a lot of the suggestions. But I think the section on alignment plans suffers from the "axe" fallacy that I claim is somewhat endemic here. Here's the relevant quote:
> For the last few weeks, I’ve been working on trying to find plans for AI safety. They should cover the whole problem, including the major hurdles after intent alignment. Unfortunately, this has not gone well - my rough conclusion is that there aren’t any very clear and well publicised plans (or even very plausible stories) for making this go well. (More context on some of this work can be found in BlueDot Impact’s AI safety strategist job posting). (emphasis mine).
I strongly disagree with this being a good thing to do!
We're not going to have a good, end-to-end plan about how to save the world from AGI. Even now, with ever more impressive and scary AIs becoming a comonplace, we have very little idea about what AGI will look like, what kinds of misalignment it will have, where the hard bits of checking it for intent and value alignment will be. Trying to make extensive end-to-end plans can be useful, but can also lead to a strong streetlight effect: we'll be overcommitting to current understanding, current frames of thought (in an alignment community that is growing and integrating new ideas with an exponential rate that can be factored in months, not years).
Don't get me wrong. I think it's valuable to try to plan things where our current understanding is likely to at least partially persist: how AI will interface with government, general questions of scaling and rough models of future development. But we should also understand that our map has lots of blanks, especially when we get down to thinking about what we will understand in the future. [...]
A few other links I'd dumped in a doc with this note:
John Wentworth’s writing on gears-level models (e.g. “...are capital investments”).
Eliezer:
- The Outside View's Domain ("...does not inspire in me any confidence that the Outside View can be applied across processes with greatly different internal causal structures, like life-and-death versus sleeping-and-waking. ..." ... "when you deal with attempted analogies across structually different processes, perhaps unique or poorly understood, then things which are similar in some surface respects are often different in other respects. And the sign of this domain is that when people try to reason by similarity, it is not at all clear what is similar to what, or which surface resemblances they should focus upon as opposed to others.")
- Underconstrained Abstractions ("...The further away you get from highly regular things like atoms, and the closer you get to surface phenomena that are the final products of many moving parts, the more history underconstrains the abstractions that you use. This is part of what makes futurism difficult. ")
- ^
From "First type of TAI?" again, a whacky schematic:
Whacky illustration:
This is a really useful post, thanks for writing it! (This kind of thing is precisely why I'm so interested in AI tools / work on AI for epistemics[1])
...
That said, I think strong findings like this are often largely due to differences in how things are measured or other incidental/background features of the dataset considered / the methods used to analyze the data. I haven't personally checked anything, but to give you a sense of what I mean, here are a couple explanations that might be worth considering:
- (a) For whatever reason (via some sort of entanglement/ hyperstitioning / info-cascade-type dynamic?), the classifier you're using might be paying significantly more attention to posts published on or around April 1
- I.e. it would find a similar number of misleading claims in posts published at other times if it looked more carefully, but it doesn't, so you see a spike
- (This would be extra concerning given what it says about the baseline rate of falsehoods!)
- (b) There's a (vestigial?) crossposting system or similar that activates on this date and publishes a backlog of posts from other websites/fora
- (This seems more likely given that people on the EA Forum seem so much less likely to make false claims)
- (c) Whenever they're actually published, many posts that make verifiably untrue claims may later be edited; back-dated so they seem as if they'd been posted around April 1
- (I can imagine this happening due to a system malfunction; e.g. if the Online Team has its own classifier running, maybe as part of some internal metric/OKR. That may have a bug that logs this information via the "date posted" field instead of whatever system they meant to set up. A more cynical POV might be that they are systematically manipulating the dates in an attempt to make the Forum seem more truth-seeking than it actually is, if e.g. it's audited annually on March 31 via a system that doesn't quite reach to a full year back!)
I'll say that I tend to default to mistake theory, not conflict theory, and describing the issue in words like "fake" seems to assume the latter. Under the former lens, you might want to consider hypotheses like (d): maybe the world is very strange/different around April 1, such that it's easier for people to be confused and accidentally say untrue things.
(Still, we should probably always consider whether (e) the Forum is being inundated with lies in a planned attack of some kind.)
I'm also worried about an "epistemics" transformation going poorly, and agree that how it goes isn't just a question of getting the right ~"application shape" — something like differential access/adoption[1] matters here, too.
@Owen Cotton-Barratt, @Oliver Sourbut, @rosehadshar and I have been thinking a bit about these kinds of questions, but not as much as I'd like (there's just not enough time). So I'd love to see more serious work on things like "what might it look for our society to end up with much better/worse epistemic infrastructure (and how might we get there)?" and "how can we make sure AI doesn't end up massively harming our collective ability to make sense of the world & coordinate (or empower bad actors in various ways, etc.).
- ^
This comment thread on an older post touched on some related topics, IIRC
I didn't end up writing a reflection in the comments as I'd meant to when I posted this, but I did end up making two small paintings inspired by Benjamin Lay & his work. I've now shared them here.
I think of today (February 8) as "Benjamin Lay Day", for what it's worth. (Funny timing :) .)
Another one I'd personally add might be November 4 for Joseph Rotblat. And just in case you haven't seen / just for reference, there are some related resources on the Forum, e.g. here https://forum.effectivealtruism.org/topics/events-on-the-ea-forum, and here https://forum.effectivealtruism.org/posts/QFfWmPPEKXrh6gZa3/the-ea-holiday-calendar .
In fact I think the Forum team may also still maintain a list/calendar of possible days to celebrate somewhere. ( @Dane Valerie might know?)
Benjamin Lay — "Quaker Comet", early (radical) abolitionist, general "moral weirdo" — died on this day 267 years ago.
I shared a post about him a little while back, and still think of February 8 as "Benjamin Lay Day".
...
Around the same time I also made two paintings inspired by his life/work, which I figured I'd share now. One is an icon-style-inspired image based on a portrait of him[1]:

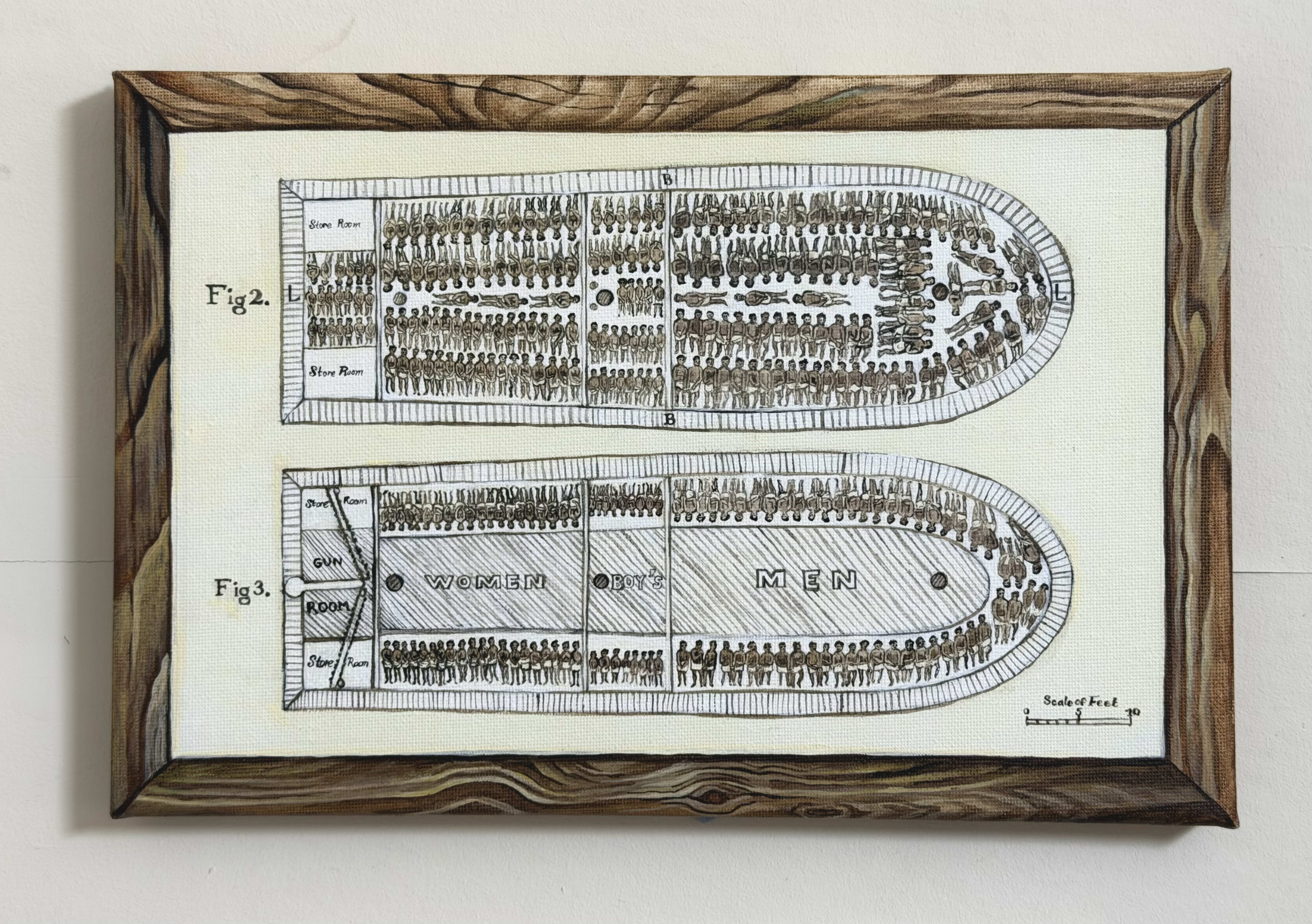
The second is based on a print depicting the floor plan of an infamous slave ship (Brooks). The print was used by abolitionists (mainly(?) the Society for Effecting the Abolition of the Slave Trade) to help communicate the horror of the trade.
I found it useful to paint it (and appreciate having it around today). But I imagine that not everyone might want to see it, so I'll skip a few lines here in case you expanded this quick take and decide you want to scroll past/collapse it instead.
.
.
.
[This is an unedited babble]
When I'm writing I sometimes get stuck trying to read what’s been written on the topic before.
I think often that's driven by an earnest interest/hope/curiosity (looking to learn or read something exciting), or wanting to scope down the thing I'm writing by linking to past stuff (or just driven by remembering a piece that I really appreciated and then getting nerd-sniped along the way). Sometimes it's more directed (noticing a crux, trying to see if I can look that up) (in general I want to do more of this one, relative to the rest). I still think e.g. that linking is often useful, but overall IMO I do the above too much. (I think actually maybe there's a form of planning fallacy at play, where I often feel like this will be a 5-minute task but actually it too frequently turns into a 2-hour detour...[1])
There are two patterns that seem more harmful, at least in my case:
(a) a defensive move; wanting to check if what is actually new or completely accurate or somehow silly.... , or (b) just following some sort of "path of least resistance" gradient when I"m trying to think about something complicated and it's easier to go and read about something vaguely related to the topic (or about what the hell is going on with diffusion models or whatever's on my mind).
I want to think more about (b) later. For now I just noticed myself wanting to post a quick note re the defensive stuff in (a) — the "is this really contributing something new?" point in particular. IMO:
(This view can be taken too far - "reverse all advice you hear" etc. But still, I think "novelty is often overrated, and maybe that overrating often happens in large part inside people's heads - unsure.)
Anyway, it’s funny- I’ve personally told people that they shouldn’t worry too much about novelty before, and I endorse what I've said there. I think people overrate it, I think writing the same thing multiple times is often useful, etc... But I still notice myself thinking "eh but surely someone has said this, IDK if this would be that useful" (and then spending more time trying to check a minor thing than I would have just writing it if I went at it with a no-apologies attitude)[3]
What gives? Imposter syndrome? (Or thinking too much about how things make me look instead of about what people will read, maybe? Something like low-status-behavior intuitions for women?) I don’t know. I suppose I’ll leave it at that for now, in part as a public reminder or commitment that I don’t have to do this. And I’ll try to resist linking more than I already have.[4] 🙃
(
A flip side of / complementary pattern to the above is making sure we sometimes get into a mindset (state?) where we can:
)
Plus just having a somewhat poor memory, and being distractible. And not being better at "form factors" / scoping.
This makes me remember a recent thread comparing different AI systems' cyber capabilities (finding vulnerabilities in a codebase, IIRC), where the open-source models had (unlike the others) been given the places with vulnerabilities and asked to figure out how to exploit them instead of having to locate things themselves. Someone compared this to something like giving someone a needle instead of a haystack-with-a-needle
ANyway, IMO noticing that X is relevant for your life / context is really useful, and underrated (vs "coming up with" X)
(and I'm pretty sure I apologize for lack of novelty when I post stuff , which probably worsens the norms here - in fact I might have done that in the previous comment I posted - I should do less of that!)
Althuogh I'm sort of using this as a low-setup-cost / MVP version of a personal wiki, and I had collected some links in an old slack message. So, in the interest of not actually following the links right now...
https://www.henrikkarlsson.xyz/archive?sort=new
https://maggieappleton.com/garden-history
https://michaelnotebook.com/qtr/index.html
https://scienceplusplus.org/cusc/index.html
https://www.lesswrong.com/posts/hjMy4ZxS5ogA9cTYK/how-i-think-about-my-research-process-explore-understand