Not sure if it's any consolation, but knowledge representation, semantic web, and similar tools have consumed many years of brilliant lives - usually with marginal results. (This is my perverse way of congratulating you for not adding yourself to the pile.)
Hey Harrison! This post evaded me until now. I am sorry to hear that you are not going to continue working on this. I hope that you will still follow progress of other projects, and that you will chime in with feedback when some of the people working on similar things post about it i the future!
Research + Reality Graphing to Support AI Policy (and more): Summary of a Frozen Project
Tl;dr: I’ve been working on a project to support AI policy research, but my request for funding was turned down. I (currently) don’t have it in me to continue working on this project, but I figured I should describe my efforts and thought process thus far. If you are skimming this, it might be best to start with the example screenshots to quickly get a sense of whether this post is worth further reading.
[UPDATE/EDIT: I have exported the ORA map to an interactive/viewable version here on Kumu—just note that I still have not optimized for aesthetics/presentation]
Intro and Summary
For the past 1–2 months I have been working on a meta-research project to create a tool to support research for AI policy—and ideally other topics as well (e.g., AI technical safety debates, biosecurity policy). As I explain in slightly more detail later (including via illustrations), the basic idea was to explore whether it would be valuable to have a platform where people could collaborate in graphing relevant “nodes” such as policy proposals, arguments/responses, variables, assumptions, and research questions, and the relationships between these nodes.
I applied for a LTFF grant a little over a month ago to request some funding for my work, but unfortunately, earlier this week I was informed that my grant application was rejected. Normally, I would probably continue working on a project like this despite the setback. However, after years of having spent many dozens of (if not a few hundred) hours working on a variety of projects which ultimately nobody cared about, I have largely lost faith in my ability to judge which projects are valuable and I find it difficult to continue motivating myself to work on them. For those and a few related reasons, I may be giving up on this project, despite my continued (perhaps delusional) belief that it seems worth exploring.
However, it seemed like it would be quite hypocritical for me to toss the project in the circular folder with no published summary, given that one of my motivations for the tool was to reduce problems from people not publishing their work (e.g., non-publication bias, duplication of effort). Thus, I will at least be providing this partial summary of my thought process and efforts. If there is anything I do not cover or explain well, feel free to ask: I might even have relevant half-baked notes somewhere I forgot to include or simply chose to leave out.
The What: Research and reality graphing in support of AI policy research
After years of thinking about this and related concepts, I still don’t exactly know what to call this tool. Still, the basic idea is to “graph” (in the node-and-link sense) reality and research, hence my current preference for the name “research and reality graphing.” In this case, the goal is to specifically use it in support of AI policy research, to inform whether the AI safety community should support or oppose (or ignore) policy proposals like “impose interpretability regulations in the US,” “restrict US-China AI collaboration,” and “create a National AI Research Resource/Cloud in the US.”
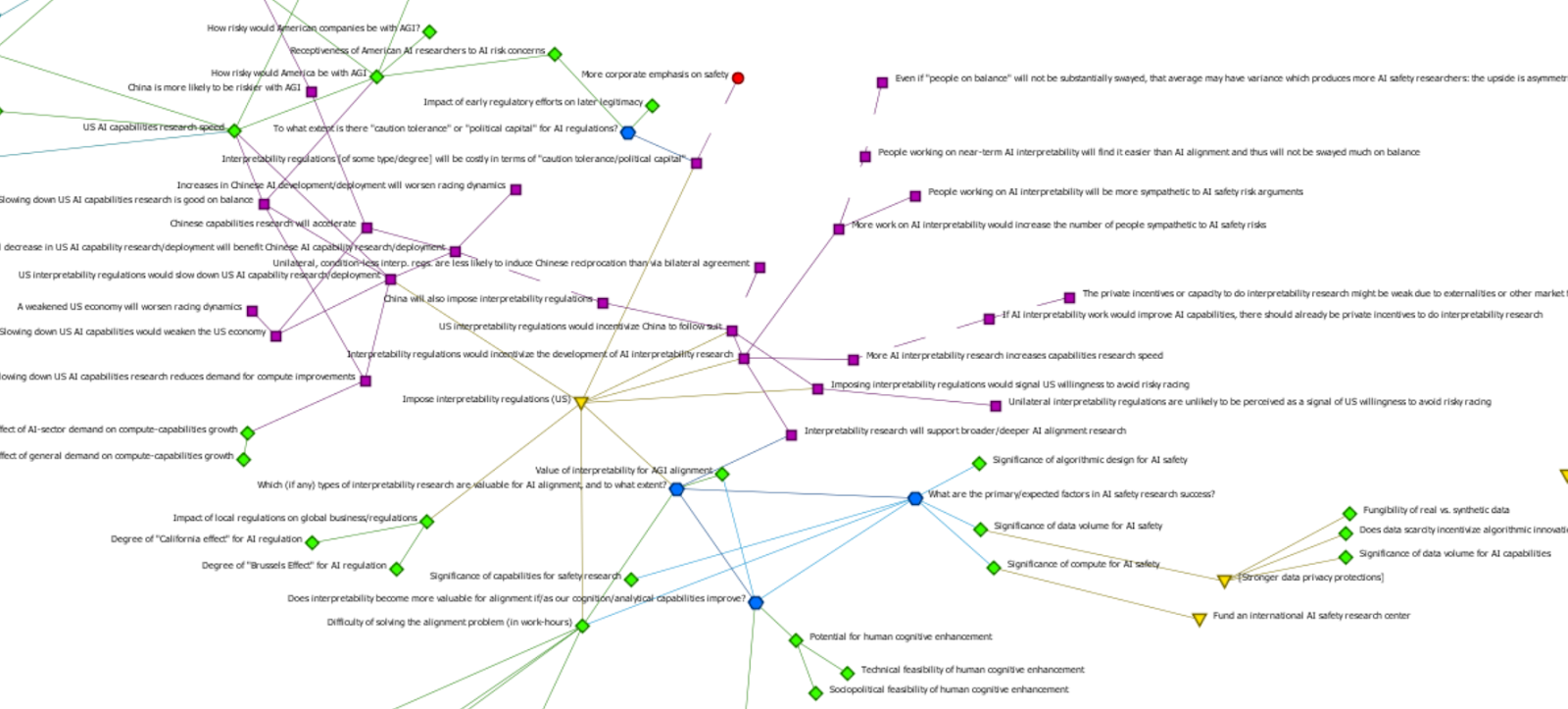
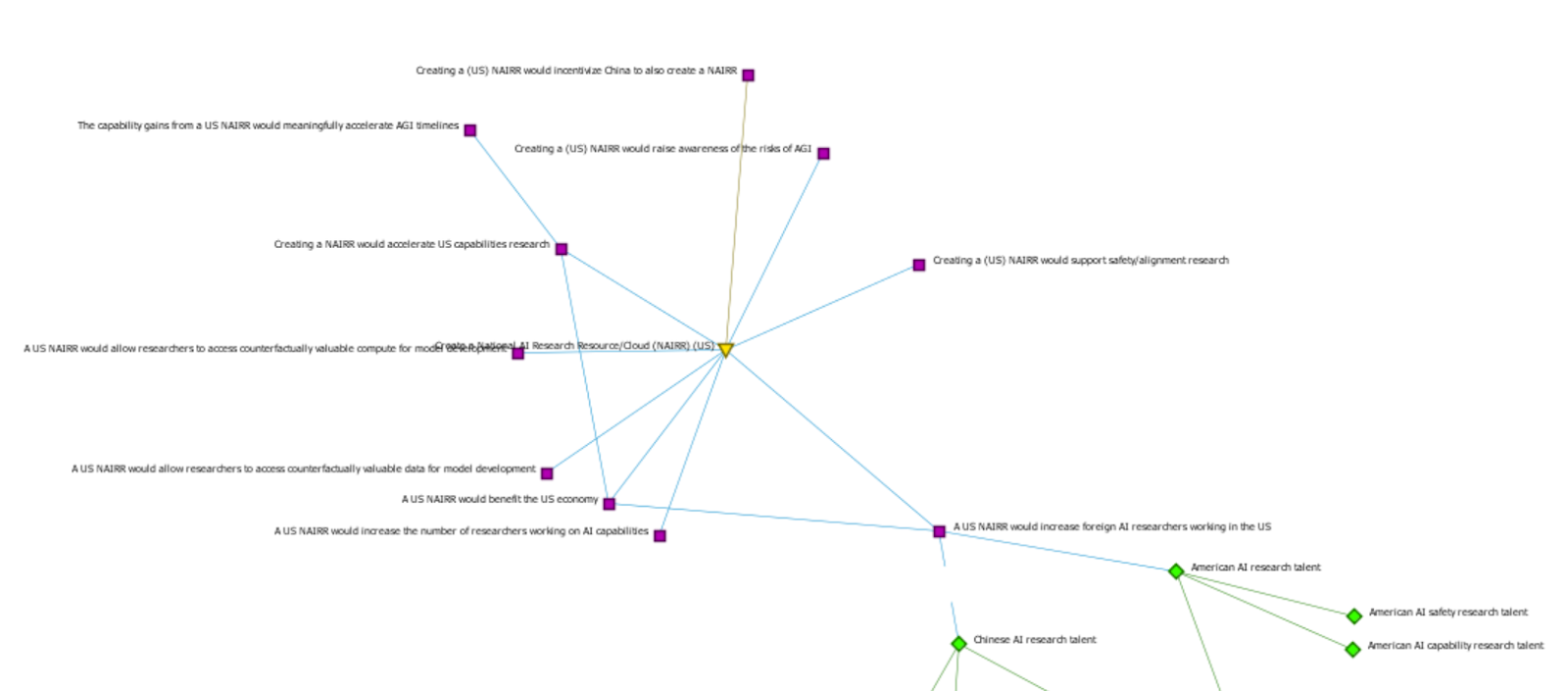
But before I attempt any more verbal explanation, I’ll simply provide the following screenshots, which I think efficiently do a large chunk of the explanatory legwork. (Note: Because I was still testing out which approaches/structures seemed to work best, the networks in the following screenshots are unpolished and still have issues, such as some inconsistencies in terms of node types, little attention paid to aesthetics, many undefined placeholder relationships, inconsistencies in terms of granularity, etc. That being said, the purple squares are generally "claims/assertions/arguments", yellow triangles are policy proposals, blue hexagons are research questions, and green diamonds are generally "reality variables")
(Screenshots are of ORA-Lite; if you would like the full file, free to message me)
Some additional explanatory/detail notes:
The graph views shown above would presumably NOT be the only way for audiences to browse the research: I envisioned that some audiences such as certain policymakers (as opposed to pure policy researchers) would prefer to navigate the existing research in something like a hierarchical format that starts with a peak node/question (e.g., “should I support AI interpretability regulations in the US?”) and only includes information/nodes that have relations to nodes which have been selected/expanded. (Think of a pyramid structure and/or “bullet points with dropdown/expansion options.”)
This is closely related to some of my past proposals/ideas, including structured discussion platforms like Kialo (which has a much simpler structure) and epistemic mapping (which is very conceptually similar to this proposal, with the debatable exception that it was not as tailored/intended for policy topics and audiences)
Having talked with people who are working on similar projects (e.g., Paal Kvarberg, Aryeh Englander with Modeling Transformative AI Risks (MTAIR)), I really think that the architecture/approach I envisioned differed by putting less initial emphasis on quantitative elicitation and modeling (e.g., eliciting estimates on variables/claims, using estimates to calculate probabilities) and instead initially emphasizing “share concepts/ideas to save audiences’ time on literature reviews and brainstorming” while still creating an architecture that can later be used for quantitative elicitation and modeling.
Why do this?
I could talk about this at great length, but I’ll try to limit my soapboxing [1] (especially since I doubt it matters anymore):
Even slight net improvements in policy towards reducing existential risk should have massive expected value (although this admittedly does not guarantee that the benefits of this project exceed the opportunity costs).
I have long believed/argued that our current methods of research and collaboration are suboptimal. e.g.:
So much information/insight that is gathered in the research process is simply not included, whether due to space constraints or the difficulty of incorporating such knowledge.
In some situations, none of the research that people conduct ends up being shared, whether due to the research being too preliminary or narrow to constitute a publication or a number of other reasons.
The process of searching for specific information (e.g., “responses to X argument”) is less efficient than it could be, especially when such responses are not the primary focus of entire papers and/or the responses may be spread out across a variety of studies.
It can be difficult to validate that a given study is thoroughly and fairly representing the perspective of opposing views, and in many cases this simply does not happen.
Traditional linear text is not optimal for discussing—let alone actually modeling—the complexity of some questions in policy research and analysis. In STEM fields researchers have realized that you can’t effectively analyze and discuss complex systems in rocketry (for example) without using equations and dedicated modeling systems, but when it comes to many soft questions in social sciences and policy analysis this kind of modeling rarely occurs. (There are lots of caveats not explicated here: yes, I realize it may not be practical for soft questions; yes, I know people do cost-benefit analyses; etc. but I’m not going to respond to these objections unless someone wants to challenge me on this.)
Traditional academic back-and-forths (e.g., “A response to X article” followed by “A response to a response to X article”...) are inefficient, especially when the debate cannot proceed at the point-by-point level as opposed to “here’s my 6 paragraphs of commentary” followed by “here are my 7 paragraphs of response to your 6 paragraphs of commentary.” Some comment chains in forums are particularly illustrative of this.
A tool such as this seems like it could help improve policy research and subsequent policymaking. In part by mitigating some of the problems I listed above, two of the main desired outcomes of a tool like this would be to:
Make a given amount of research time more efficient (e.g., reducing the time that it takes researchers to conduct literature reviews), such as by making it easier to find claims and uncertainties related to any given node (e.g., “what are the main responses and justifications for the claim that interpretability research could be harmful because it could accelerate capabilities research?”);
Improve the quality/output of a given amount of research effort, such as by reducing the probability of overlooked arguments, helping to illustrate the importance of research questions/gaps, etc.
To give just one of many hypothetical “value/impact successes” scenarios: consider a researcher who has been focusing on the value of US AI interpretability regulations, but needs to better understand certain aspects of US-China AI competition/cooperation that figure into their policy analysis regarding interpretability regulations. Traditionally, this requires diving into the literatures on great power relations, economic competition, differing regulatory regimes and business environments, and any other topics which seem potentially relevant. Doing this may take many hours for someone who is not familiar with the literature, given how they have unknown unknowns (e.g., "what haven't I considered which may be important?"), most information or arguments are not aggregated into one source, following specific debates or concept threads may require reviewing a range of different sources, etc. It may be possible to find someone who has already done this research and talk with them—especially if the person now doing the research has sufficient prestige or connections—but it might also not be practical to meet with them and discuss the findings. Now, suppose instead that a few different people who have already done some relevant research have already "graphed" many of the key concepts, research findings, and remaining uncertainties regarding this question of US-China AI competition/cooperation—including many questions or topics that are not mentioned or emphasized in most published literature reviews (due to word count or other reasons). After skimming perhaps one or two traditional literature reviews, the researcher can browse the research graph/hub where the concepts have been aggregated, summarized, and organized in a way that is easier to focus only on the nodes that seem most relevant to the question about interpretability regulations. I think it’s plausible that the graph could save the researcher >50% of the time they would have otherwise had to spend conducting a literature review of the overall field, in part by providing some immediate intuition pumps as to “what do I need to know (and perhaps 'whom do I need to talk to about what'),” making it easier to identify responses or supporting evidence for any given claim, etc.
Some of the plausible use cases seem to include:
Theories of change/victory and paradigm analysis for AI governance (e.g., Matthijs Maas’ work);
Informing grant funding, especially for prioritizing certain research topics or advocacy projects;
Traditional policy research/analysis and subsequent advocacy;
(And more)
One last justification I’ll briefly mention: I am very supportive of similar/related projects, including MTAIR and Paal Kvarberg’s epistemic crowdsourcing. However, I have been concerned about the projects’ ability to attract contributors and users while they focus heavily on quantitative elicitation and modeling. Long story short, I worry that for those projects to be successful you may need to reach a critical mass of participation/interest; it’s possible that the initially quantitative-light approach of this project may be a more effective path for building/snowballing initial interest in such epistemic collaboration platforms.
I admit that much of the above is left without deeper analysis/justification, and it still doesn’t convey all of my major thoughts, but unless someone actually requests a longer discussion I’ll just leave it at that.
How
I preliminarily used Carnegie Mellon’s ORA-Lite, which is free to download and use (unlike Analytica, which is the model used by MTAIR). Ultimately, I don’t think ORA would have been viable for the final product, but it was useful as an initial sandbox tool for experimentation.
ORA doesn’t seem to enable real-time collaboration.
ORA definitely isn’t awful in terms of user-friendliness, but it probably would need to be more user-friendly to be viable.
If you would like the full file I was working on, I would be happy to share it. (Just recognize that it is quite raw)
The graph/system could be implemented in a variety of ways, including one option of establishing a “librarian corp” of junior researchers/interns who are able to operate without needing much senior researcher oversight (e.g., 1 "senior" FTE or less for the entire team). For example, perhaps an organization like GovAI or Rethink Priorities could have a division of ~20 flex-work interns and junior researchers who work on teams covering different subject areas by default but respond to any specific requests for research (e.g., "tell me about the potential for 'value trade' between Western and Chinese AI researchers in the status quo or if our governments encouraged such collaboration"). However, I never spent very long thinking about this aspect of implementation.
(There are some other methodological and implementation details that I probably have some scattered notes on, but I’ll leave it at that for now. If there’s something you’d like for me to explain, feel free to comment/message.)
Final notes
If you are interested in learning more about this kind of project, feel free to get in touch. There is also a Slack channel (on the new EA Metascience workspace) that I recently created that is dedicated to these kinds of reality elicitation and graphing projects: DM me for details.
I had been working on a list of “key assumptions which, if wrong, might suggest this project is not that valuable” (e.g., “this could be done mainly by junior researchers and there is enough slack in demand for such researchers that it has sufficiently low opportunity costs”). However, I haven’t formalized the list for publication. If you are curious about exploring similar projects—or if for any other reason you’d like to see the list—I’d be happy to wrap up and write up some of these thoughts.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...

Really appreciate your work and your honesty.
Not sure if it's any consolation, but knowledge representation, semantic web, and similar tools have consumed many years of brilliant lives - usually with marginal results. (This is my perverse way of congratulating you for not adding yourself to the pile.)