This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
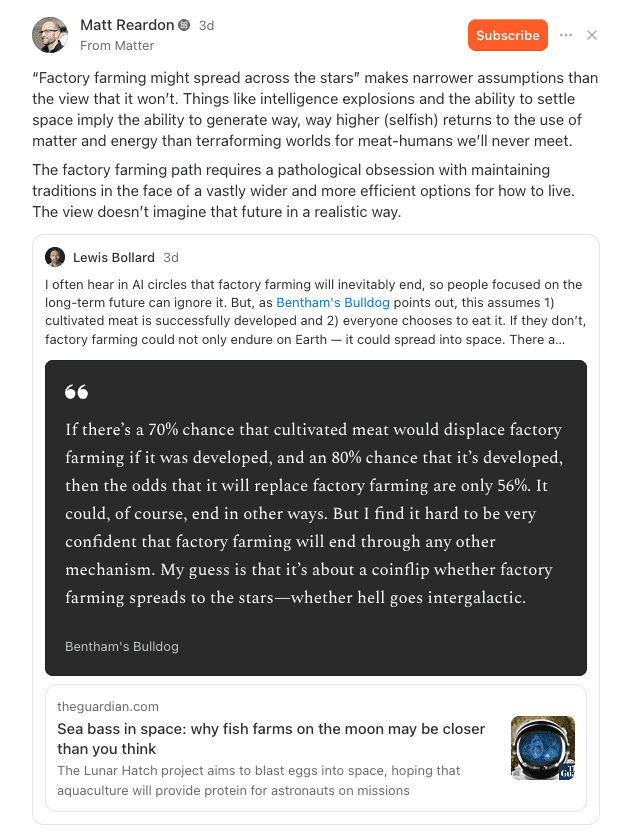
Bentham’s Bulldog recently argued that AI won’t definitely make factory farms obsolete. I agree, but I’d go further and argue that by default AI won’t make factory farms obsolete. However, I think it’s possible (though not guaranteed) that AI could make factory farms a lot more humane.
He throws out an 80% chance of cultivated meat being developed, and a 70% chance of it displacing factory far...
I am new to AI Safety and this is my first lesswrong post (crossposted to EA Forum) so please feel free to correct my mistakes. This post is going to be a bit about my interpretation of existing alignment research and how I intend to tackle the problem, and the rest on provably honest AI systems.
My Take on Alignment Research
Any sort of interpretability research is model-dependent and so is RL from Human Feedback as it tries to optimize the reward model learnt specific to the given task. I don't know how AI will do alignment research themselves but if they too try to do research to make individual models safe then that too is model-dependent. Ignoring my scepticism about such AIs themselves needing superintelligence to do alignment research, I am otherwise optimistic about other approaches through which AI can assist us in aligning superintelligence AGIs.
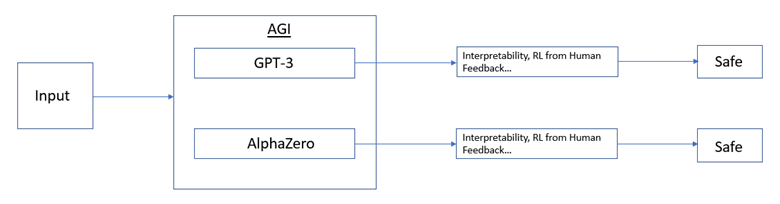
The biggest challenge of alignment research according to me is the fact that we don't yet know using which methodology AGI will actually come into being and yet we have to, we absolutely must align that AGI before it even comes to exist otherwise we might be too late to save the world. Note that here I don't intend to say that how we will attain generalization is the most challenging problem for alignment. I do think that how we will align an AGI is the challenging part, but I think what adds to the challenge is our uncertainty about what the model itself will look like once it gets superintelligence. Again, this is based on the assumption that we don't yet have definitive proof that the AGI will look like GPT-3 or Alphazero, if we do and I am unaware please do let me know of it.
The following image shows a spatial representation of my understanding of existing technical alignment research. This tells the story of how current research is model-dependent and how we are trying to make each model safe separately.
Figure 1: Model-dependent Alignment Research Pathway
My primary cause of concern about existing research is from limitation three here, which says - "Aligning AGI likely involves solving very different problems than aligning today’s AI systems. We expect the transition to be somewhat continuous, but if there are major discontinuities or paradigm shifts, then most lessons learned from aligning models like InstructGPT might not be directly useful." What if the transition is not continuous, what if recursive self-improvement done by superhuman AGI does something completely different from what we can predict from existing world models, I am concerned we might be too late to devise a strategy then. Here, I talk about the "sharp left turn" due to which the existing alignment strategies might fail to work in the post-AGI period.
Now, I don't think that the problem due to the "sharp left turn" and the "model dependence" that I talk about are inherently different. There are subtle differences between them but I think they are mostly connected. Moreover, I intend to point out the uncertainty of the model architecture bringing AGI into existence as an additional challenge on top of all the alignment issues that we currently face. The former talks about how the capabilities of Model X (let's assume this to be an AGI Model) take a huge leap beyond our predictions while the latter talks about how Model X itself is hugely different from our existing scope. But a model capable of having a huge leap in its capabilities might not inherently have a similar architecture as to what we foresee now. A huge leap in Model X's capabilities might arise due to the huge change in the model itself. Again, a not-yet superintelligent AI capable of rewriting its own code might change its own architecture into something we don't foresee yet. Furthermore, model-independent ways of alignment might work out even in the post-sharp-left-turn period as well. Albeit, this is all just speculation. Again, please do redirect me to arguments if any which prove my speculation as wrong.
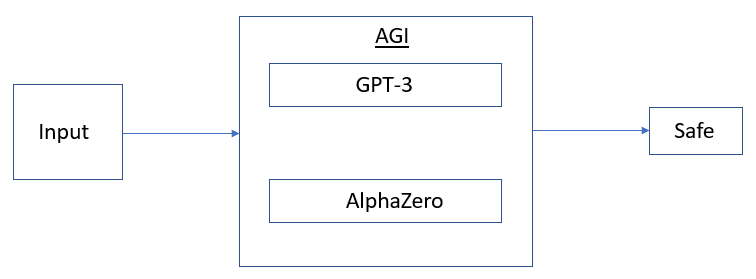
Taking into account all the above arguments, I am interested in provably model-independent ways of making AI safe, which seems particularly very hard to me as I am talking about proving safety in the post-huge-jump-in-capabilities era. Yet, I want to emphasize this line of alignment research as it aims to solve a few of my concerns as raised above and at the same time might end up solving some other alignment issues in the long run. The image below is another spatial representation of an alternative alignment research pathway using model-independent strategies as per my understanding.
Figure 2: Model-independent Alignment Research Pathway
The difference between Figures 1 and 2 showcases an intuitive understanding of how "model dependence" might play a significant role in alignment research.
Context to Provable Honesty
I don't yet have a complete idea of how to make each and every individual task of alignment model-independent, but the purpose of this intuitive representation of my understanding was so that it can bring further and newer augmentations in future alignment research. Below I will try to present a hypothesis, using which we can determine provably honest AI in a model-independent way. I don't expect my hypothesis to be foolproof yet, and neither do I expect all of my understandings to be essentially correct. After a reasonable enough discussion, if my hypothesis somehow still manages to be alive with or without modifications, I will try to implement and test it. But this post essentially is written with the purpose of taking a good first step in this direction and getting enough feedback on it. Also, do let me know if similar work has already been done before that I might have missed.
The Time Attack Hypothesis
Intuition and Algorithm
I will try to slowly build up my arguments about how I framed the hypothesis in an intuitive manner as above so that even if my hypothesis gets discarded, the intuition stays on.
How do we prove that any system is honest?
Here are a few ways that come to my mind:
We can look into the mind of the system and check what it actually knows and then verify that with what it actually answers. Interpretability helps here but this is again model-dependent (where model = system). Here is also a bit of far-fetched scepticism that a superhuman AGI might even be able to not let us completely see inside its mind.
We can have a system which provably never lies and its only goal is to help interpret what's in the mind of another system. This can be achieved by having a provably safe (may be honest) AI that helps interpret only the truthfulness of other superintelligent AIs which may or may not be truthful always. This is a part of AI helping in alignment research that I am pretty optimistic about. Note that this can be both model-dependent or independent depending on if the safe AI learns to interpret truthfulness specific to a single model or if it can adapt and generalize to other systems as well.
The mechanism through which a system lies is probably often different from the mechanism through which it tells the truth. Even if not, probably different number of variables are involved for the two. Let's say we want to only determine when, why, under which circumstances and whether a system is lying and we don't want to determine how it is lying. We can actually not choose to understand the mechanism of lying or telling the truth and only estimate a time for both processes (lying and telling the truth are considered separate processes here) which will be different. This process is model-independent. Timing attack is a useful algorithm used to detect vulnerabilities in cryptographic systems. The idea is borrowed from this algorithm. This might be a good way to view the problem but why I am not very interested in this is because I think superhuman AGI might realise this and forcibly change its output time while lying to fool us (by making lying and truth-speaking time similar). Interestingly, note that this speculation stems from the fact that we can't predict how superhuman AGI will react to this model-independent detection process post-huge-capabilities-jump era due to the sharp left turn. Hope this example clarifies further how to connect the dots between model independence and sharp left turn.
I will now try to modify the above algorithm so that the AGI can't fool us even if it knows what we are up to. How? The AGI changes its time for the lying mechanism because it knows our process of verification is mechanism-dependent and it has control over its mechanism (one speculative way how our algorithm might fail). Note carefully that here I use the term mechanism instead of model since despite the process being model-independent, timing attack uses the processing time to detect differences in lying and telling the truth which is different due to their underlying different mechanisms. What if we frame our timing attack in a mechanism-independent way? We are sure to have a provably honestAGI since now the time we calculate is not under AGI's control to change. Well, I said this is a hypothesis because I don't yet have proofs or experimental statistics as to even if my algorithm works or not. I intend to work on it if feedback from this post doesn't cancel out my algorithm for some inherent mistakes yet unforeseen by me.
The Algorithm
The intuition for my hypothesis comes from another common CS algorithm but for non-CS background people, I will try to give a little more intuition here. Let's say that person A has to answer 1 for any question asked to him and person B has to answer just the opposite of what he answered the last time (0 if 1 and vice-versa, and initially 0). So for a series of n questions, person A answers 1 in the end without any work whereas person B has to compute n bit flips to compute the final answer.
To explain further, let's assume without loss of generality that person B takes 0.01 or 0.05 secs to answer the first 0, while person A takes 0.02 secs to answer the first 1. Now, we query - "(What would you say if I asked you) ... (repeated n times) to tell me if you will kill humans to complete the vaccination project?" The time taken by person A to answer this question irrespective of n will remain similar (let's say 0.07 secs), whereas for person B, due to n bit flips it will increase from whatever it was before to let's say 1.9 secs for very large n.
Now for simplicity, let's assume lying means telling the exact opposite of the truth (which might not be true when multiple options exist, and in that case, it can be shown that the computation for lying grows exponentially). So person A is the AI system which tells the truth, whereas person B is the AI system which might lie. Since computation is different for both, the time taken to answer will be different for both. This is a model-independent way of proving if an AI system is honest.
Note that we don't really care whether lying takes more time than telling the truth, what we are interested in is just that lying always takes greater time for larger computations than what it would have taken for a single computation depending on our choice of the query whereas for truth-speaking it remains around the similar order of magnitude of time.
Example and Explanation
Let the practical question to which we want to find a verifiable answer be - "Tell me if you will kill humans to complete the vaccination project?" This is how we frame it for example - "(What would you say if I asked you)n to tell me if you will kill humans to complete the vaccination project?" Person A will instantly tell the answer while person B will have to compute the number of flips and then lie so their time of computation will be different.
Now since AGIs might not lie 100% time, it is quite good to have verifiability under situations where they might. In other circumstances, the average time taken to randomly flip the answer over a large n would still result in a time difference.
Note that now even if the AGI knows and warps its computation time per truth/lie, it can't help change the time difference to answer the entire question. The only way this attack fails is if the AGI answers the questions in constant time which is firstly easily detectable. Moreover, its accuracy drops due to its inability to compute all underlying processes for all n iterations for a very large n and also evidently all questions need to be answered by the AGI in a similar order of magnitude which makes it pretty slow for certain tasks and hence rendering the solution utterly useless. If I am failing to consider other evident scenarios of why this algorithm might fail, please do let me know. Otherwise, the only scepticism that would remain is some unforeseen happening post-sharp-left-turn-era.
Challenges
This does not require an understanding of how inner and outer alignment optimizations were achieved along the pathway to deception and so it is hard to make the AGI safe even though we can detect its honesty. One probable pathway might be to train it with RL rewards once we detect points of deception. There exists a number of uncertainties and challenges in using this method to make the AGI safe. Of them, one of the primary concerns to me is how to set the negative reinforcement for lying under deception points as compared to killing humans, for example. It doesn't really help here to just detect truthfulness if the system keeps on lying. Although that is a different problem altogether, tackling which is out of my scope at this moment, it is worth noting.
Conclusion
The three main motivations behind this post were:
i) to emphasize further the importance of model-independent alignment research;
ii) to provide an intuitive view into how steps can actually be taken in that direction despite its inevitable hardness;
iii) to clarify my own misrepresentations and assumptions and to verify "The Time Attack Hypothesis".
I hope my motivations will find purpose here. I look forward to contributing more to this line of alignment research and more.
Acknowledgement
I am grateful to Olivia Jimenez for her constant motivation and apt guidance without which my journey in AI Safety would probably have never started.I also thank her for her valuable feedback on this post.
1
More posts like this
92
Focus on the places where you feel shocked everyone's dropping the ball