Given that you have just published this on the forum, I have not yet finished watching the video, but it is playing in the background on 1.5x speed.
Your project is valuable to me since I am not up-to-date with my knowledge of the state of interpretability research and suspect that your project and manner of explanations will help slightly in this regard. Beyond the value, interpretability is simply interesting. I would very likely watch more video explanations of this nature on topics in AI Safety, interpretability, alignment, etc... which leads me to my question: Do you intend to continue to upload videos like the one you've uploaded today?
I really wish more EAs included video explanations / tutorials to supplement their work.
Thank you for posting this on the forum, and especially for creating the video.
Thanks for the comment and for watching! I don't currently have any future videos planned, but I'd definitely consider it if there's interest. I'm also a fan of learning via videos, and you're right that there aren't that many in the AI Safety space. (Robert Miles is the only AI Safety YouTuber, I'm aware of. Absolutely worth checking out if your interested in this kind of stuff.)
Derive by hand the optimal configurations (architecture and weights) of "vanilla" neural networks (multilayer perceptrons; ReLU activations) that implement basic mathematical functions (e.g. absolute value, minimum of two numbers, etc.)
Identify "features" and "circuits" of these networks that are reused repeatedly across networks modeling different mathematical functions
Verify these theoretical results empirically (in code)
What follows is a brief introduction to this work. For full details, please see:
The linked video (also embedded at the bottom of this post)
Or if you prefer to go at your own pace, the slides I walk through in that video
Motivation
Olah et al. make three claims about the fundamental interpretability of neural networks:
They demonstrate these claims in the context of image models:
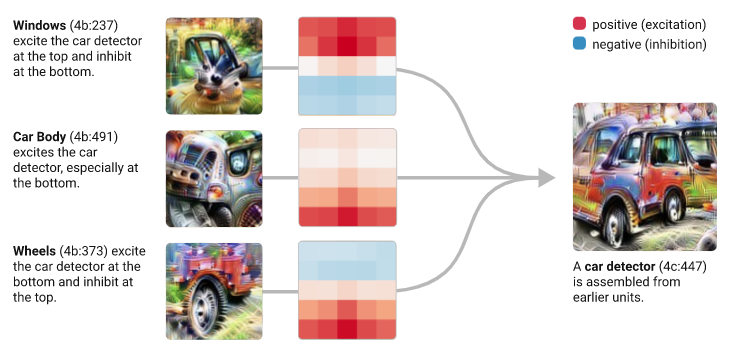
Features / Circuits:
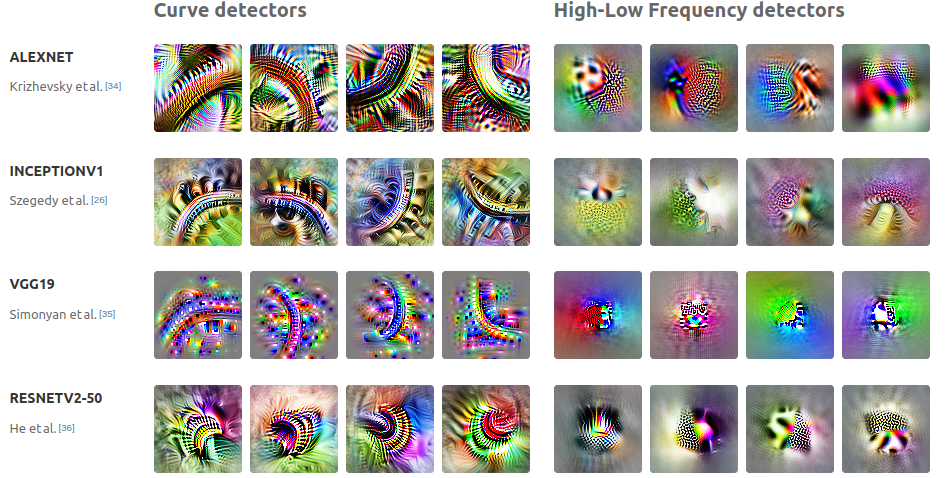
Universality:
This work demonstrates the same concepts apply in the space of neural networks modeling basic mathematical functions.
Results
Specifically, I show that the optimal network for calculating the minimum of two arbitrary numbers is fully constructed from smaller "features" and "circuits" used across even simpler mathematical functions. Along the way, I explore:
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...




Given that you have just published this on the forum, I have not yet finished watching the video, but it is playing in the background on 1.5x speed.
Your project is valuable to me since I am not up-to-date with my knowledge of the state of interpretability research and suspect that your project and manner of explanations will help slightly in this regard. Beyond the value, interpretability is simply interesting. I would very likely watch more video explanations of this nature on topics in AI Safety, interpretability, alignment, etc... which leads me to my question: Do you intend to continue to upload videos like the one you've uploaded today?
I really wish more EAs included video explanations / tutorials to supplement their work.
Thank you for posting this on the forum, and especially for creating the video.
Thanks for the comment and for watching! I don't currently have any future videos planned, but I'd definitely consider it if there's interest. I'm also a fan of learning via videos, and you're right that there aren't that many in the AI Safety space. (Robert Miles is the only AI Safety YouTuber, I'm aware of. Absolutely worth checking out if your interested in this kind of stuff.)