Comments
It just occurred to me that you don't actually need to convert the forecaster's odds to bits. You can just take the ceiling of the odds themselves:
Which is more useful for calibrating in the low-confidence range.
It just occurred to me that you don't actually need to convert the forecaster's odds to bits. You can just take the ceiling of the odds themselves:
Which is more useful for calibrating in the low-confidence range.

This post follows up my report on running a forecasting tournament at an EA retreat (teaser: the tournament ended up involving bribery, stealing, and game theory). For the tournament, I wanted a method of scoring predictions which could be computed by hand, which would simplify the set up and not make us dependent on internet/computer availability. The scoring rule I came up with for the tournament satisfied this criterion, but was ad-hoc in its construction and had counter-intuitive properties.
In this post I introduce BitBets, a prediction scoring rule which is simple, intuitive, can be computed by hand, and can be made more or less complicated to suit the sophistication of the forecasters.
This post is structured as follows:
We assume forecasters are predicting the answers to yes/no questions.
We will use the following notation:
A scoring rule should be
A popular scoring system is logarithmic scoring:
We can illustrate logarithmic scoring graphically as:
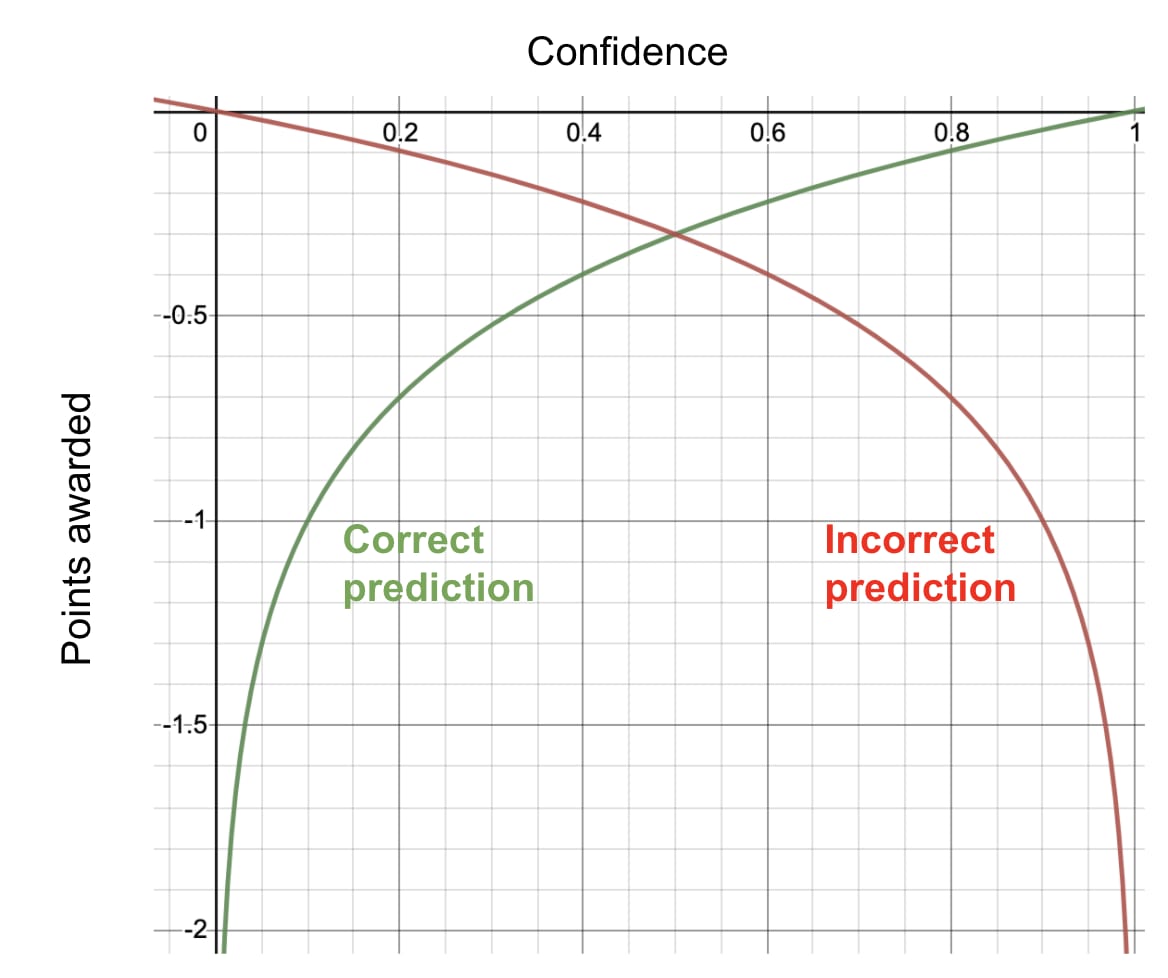
As you can see, you can never gain points from logarithmic scoring; you can only lose points. The more confident you are in an incorrect prediction, the more points you lose. At best, you can break even if you make a correct prediction with 100% confidence.
Here are some reasons why logarithmic scoring is nice:
Logarithmic scoring has properties which are attractive to philosophers and mathematicians, but which tend to be counter-intuitive to forecasters. Spencer Greenberg has argued that a scoring rule should have the following properties to be intuitive to users:
With these properties as a guide, Greenberg designed the following scoring to optimise for usability:
where
Note that Greenberg scoring is really logarithmic scoring "under the hood", but with a confidence limit and linear scaling.
Greenberg's scoring rule is illustrated below:
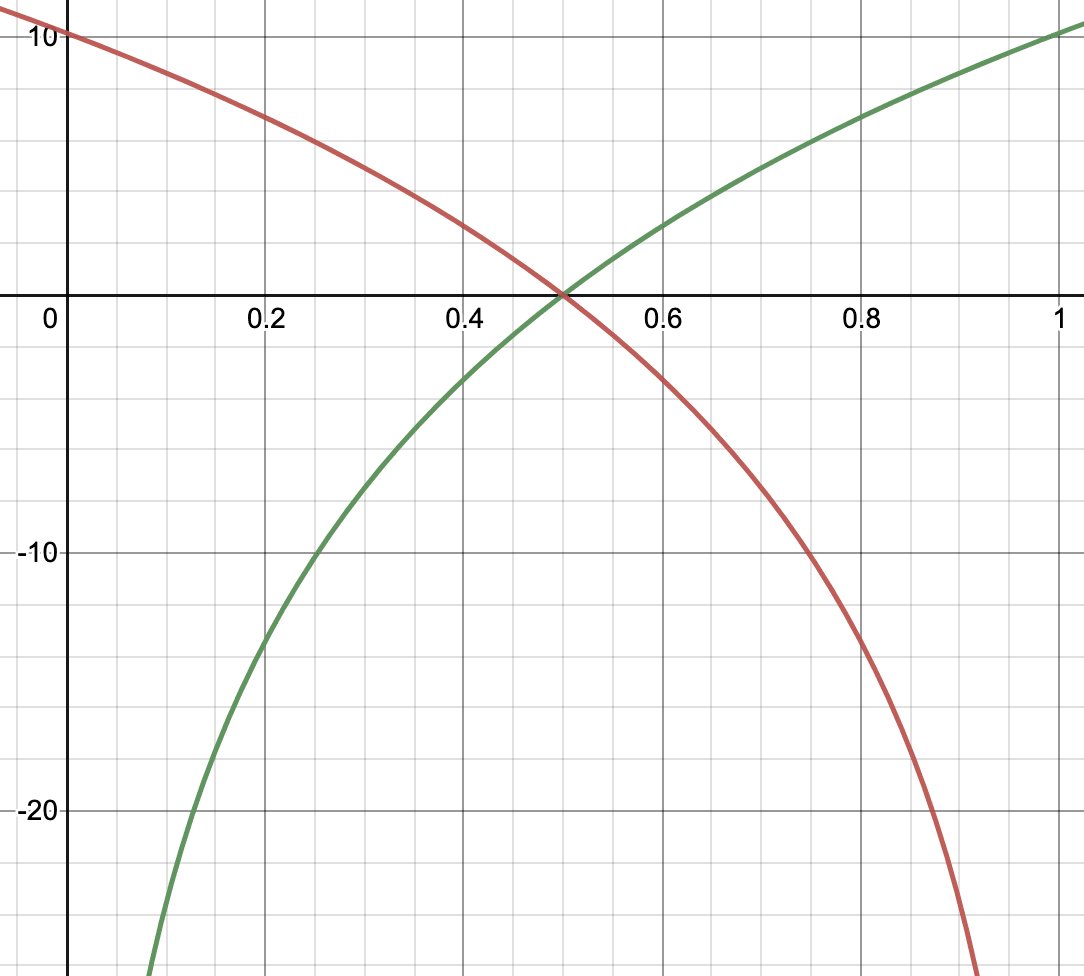
This is the scoring rule used in the Calibrate your Judgement app, created by clearerthinking.org and the Open Philanthropy Project.
Greenberg's scoring rule is well suited to a calibration app like Calibrate your Judgement. But when running an in-person forecasting tournament which is accessible to beginners, there are further desiderata we should aim for:
When I ran a forecasting tournament at the EANZ retreat, I used what I'm calling "logarithmic point scoring" to achieve these desiderata. Essentially, I restricted users to only reporting one of 4 confidences, so that the logarithmic scores for these confidences could be pre-computed and looked up in a small table. The logarithmic scores were scaled to achieve Greenberg's criteria (except for continuity), and rounded to the nearest integer.

The confidence values were chosen to roughly map onto the intuitive confidences of "don't know", "more likely than not", "probable", and "near certainty".
Logarithmic point scoring is plotted below as a series of points. For comparison, Greenberg scoring is also included as a dashed line.
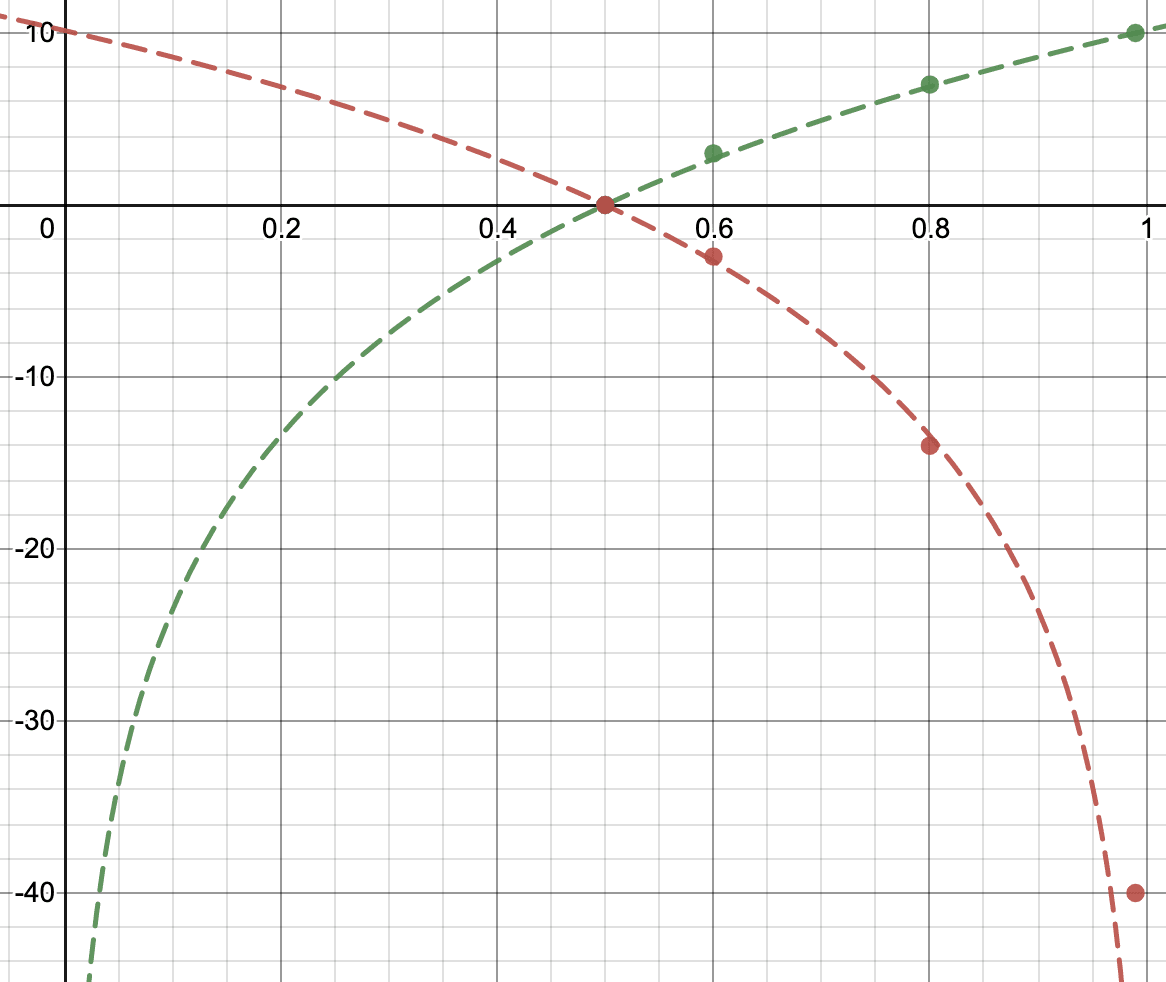
It's debatable whether logarithmic point scoring really achieves mathematical triviality. On the one hand, computing your score only requires adding up integers from a table. On the other hand, to understand where those integers came from you still need to understand logarithms and linear scaling.
Furthermore, there's the glaring problem that if your true confidence is between two of the allowed values, you don't know which one you should choose! If you do the expected value calculations, you'll find that the cutoffs between when you should choose one confidence vs another are not very intuitive. For example, if you have anywhere between 73.3% and 93.9% confidence, the best strategy is to report 80% confidence.
Currently, my preferred scoring system for forecasting tournaments is what I will call BitBet scoring. It fulfills Greenberg's criteria (except continuity), is quite simple and intuitive, can be computed with pen and paper, and avoids the failures of point scoring.
We simply offer the forecaster a series of bets with decreasingly favourable odds:
And so on with successive powers of two. Note that if a forecaster is willing to accept the -th bet, then they should also accept bets to , which have more favourable odds. The marginal bets thus accumulate as shown in this table:
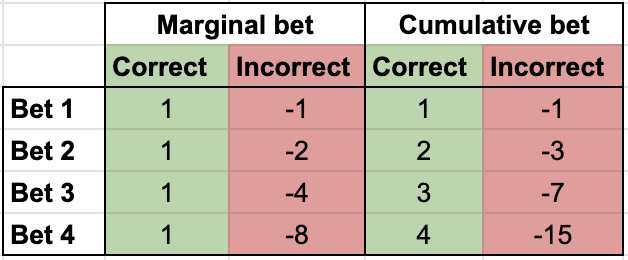
The idea is to award one point per "bit of confidence" in a correct prediction. That is,
and so on. The expected payoff of a marginal bet will be positive iff the forecaster's subjective odds of winning are more favourable than the betting odds (see the appendix for additional details). Thus, the following table describes a proper scoring rule:
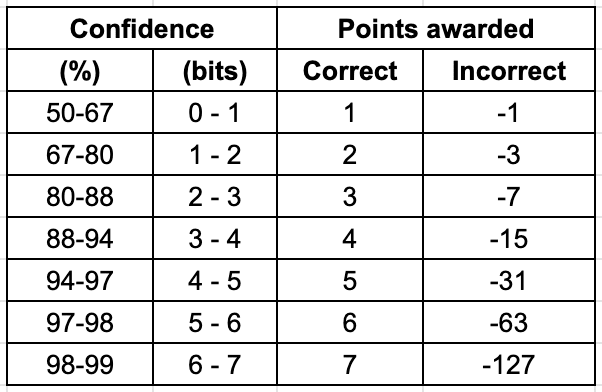
Thus rather than reporting a point confidence value (as all the previous scoring systems did), players report the interval within which their confidence falls.
For example, if my true confidence is 89%, then I report my confidence as "88-94%". If my prediction is corrrect, then I will be awarded +4 points. If I am incorrect, I will be awarded -15 points.
Formally, we define the bits of confidence corresponding to confidence as
To satisfy the hand-computability and upper/lower bound criteria, we take the floor of this value and cap the number of bits at :
The scoring system is then given by
the equivalence between this scoring system and the above series of bets is shown in the appendix. The scoring rule is plotted below:
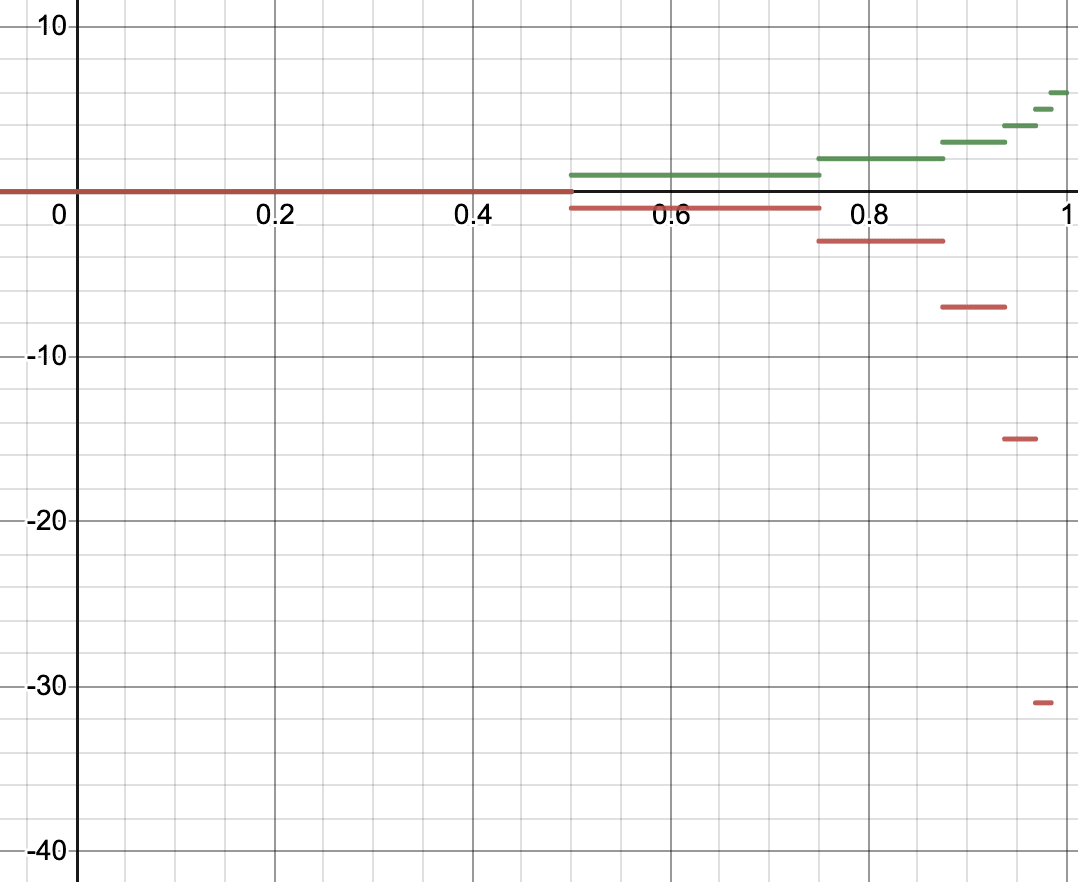
As a bonus, BitBet scoring can also be converted into a continuous scoring rule by omitting the ceiling. The continuous version may be more appropriate in a training app.
Also, framing forecasting in terms of "bits of confidence" raises interesting questions like
One final virtue of BitBets: in my previous post I asked the question
After you’ve introduced someone to forecasting with a quick tournament, how can you move them up the ladder of forecasting sophistication until they become superforecasters?
BitBets gives us a natural ladder construction method. Start with a low cap on the maximum bits; restrict novices to at most assigning three bits to predictions, for example. If someone can't discirimate between a zero-bit belief and a one-bit beliefs, then there's no point in giving them the option of ten-bit beliefs.
After the forecaster has demonstrated mastery over the current cap, incrementally extend it. For example, the forecaster first masters the question: do you have more or less than one bit of confidence
We can do this by requiring forecasters to keep meet some kind of reserve requirement for the point they hold, analagous to the reserve requirements of central banks. For example, perhaps you're not allowed to make a bet that could lose 6 points unless you have earned 5 points already.
Under what circumstances should you use one or another training rule? If your goal is simply to evaluate the quality of forecasters, logarithmic scoring is a simple and effective solution. If your goal is to provide forecasters meaningful feedback in an in-person tournament, BitBets looks like a clear winner to me. It's simple, intuitive, can be computed by hand, and can be adjusted in complexity to suit the sophistication of forecasters. In general, I wouldn't recommend logarithmic point scoring, as BitBets has all the same advantages plus some.
If providing feedback to forecasters through an app, then either BitBets or Greenberg scoring may be preferrable. The points awarded for correct predictions increase as in Greenberg scoring, but as in BitBet scoring. I suspect this means that Greenberg scoring is better for calibrating forecasters at low degrees of confidence (e.g., 0.6 vs 0.7), whereas BitBets is better at calibrating forecasters at high degrees of confidence (e.g., 0.99 vs 0.999). Which of these is more important will depend on the context.
If you don't have a clear preference for low-confidence calibration, I think BitBets is the better method of providing feedback to users. It admits incremental difficulty, by changing , or by switching from the discrete to continuous version, so is better for a cumulative calibration curriculum. Arguably the difficulty of Greenberg scoring can be adjusted with , although this is a relatively crude way of setting the difficulty.
We first wish to show:
The expected payoff of a marginal bet will be positive iff the forecaster's subjective odds of winner are more favourable than the betting odds.
Let us suppose the forecaster has a subjective probability that their prediction is correct. Then their probability that the prediction is incorrect is and their odds of being correct are
Let us say a probability is assigned to a prediction being correct. Then the odds assigned to the prediction being correct is
If a forecaster is offered a bet with payoff if the prediction is correct, and if the prediction is incorrect, then the betting odds are . If is the forecaster's subjective probability that the prediction is correct, then the expected payoff of taking the bet will be positive iff:
That is, if the forecaster's subjective odds of winner are more favourable than the betting odds. Thus a rational forecaster will accept all bets less favourable odds than hers, and be indifferent to those with equal odds. □
We now show that the BitBets scoring rule is equivalent to offering a series of bets with odds of one against ascending powers of two. We have that
And so
Thus the powers-of-two bets which the forecaster will accept because the odds are less favourable than her own estimate are (with at best indifference to ). Summing the payoffs of these bets yields
for a correct prediction and
for an incorrect prediction. □
Proving that the continuous version of BitBets is proper is left as an exercise for the reader.
This has beautiful elements.
I'm also interested in using scoring rules for actual tournaments, so some thoughts on that:
Thanks for the insightful comments.
One other thought I've had in this area is "auctioning" predictions, so that whoever is willing to assign the most bits of confidence to their prediction (the highest "bitter") gets exclusive payoffs. I'm not sure what this would be useful for though. Maybe you award a contract for some really important task to whoever is most confident they will be able to fulfill the contract.
The auctioning scheme might not end up being proper, though