Comments
I was there and I can report that T is awesome in that particular way consistently.


This post describes a simple forecasting tournament I ran during the 2021 Effective Altruism New Zealand retreat as an experimental exercise in improving judgement and decision making. I asked players to predict whether certain events would occur within the span of the retreat, like whether Peter Singer would post to Instagram, or whether anyone would lose their hat.
The tournament was surprisingly fun, and went in many unexpected directions. I would strongly encourage other EA retreats and similar gatherings to run their own prediction tournaments, and I provide some resources to get started.
A summary of this post:
The art of forecasting is an important part of the Effective Altruism extended universe. There are at least three reasons for this. First, if you can predict which problems are going to be important in the future, then you can start preparing solutions now (unaligned AI, runaway nanotech, engineered pandemics...) Secondly, if you can predict the future conditional on your actions, then you can choose interventions which do more good for longer (if we transfer cash to poor countries, will this help them build a self-sustaining economy, or will it foster dependence and fragility?) Thirdly, in a broad sense, good forecasting requires clear thinking and improves decision-making, which are virtues we want to cultivate in building a wiser society. In other words, cultivating forecasting skills is an act of everyday longtermism.
So how do you get better at forecasting? 80,000 Hours recommends the practicing via these methods:
The 80,000 Hours article also mentions the Calibrate Your Judgement app by ClearerThinking.org and Open Philanthropy. Although this is not a forecasting exercise per se, as it asks you to make probabilistic judgements about general knowledge and maths questions (rather than future events), it does provide quick feedback on the calibration of your confidence.
A couple of years ago I got excited about forecasting and signed up to both Metaculus and Good Judgement Open. But I never got around to actually making any predictions. Why? These platforms are pushing the limits of collective forecasting, so the questions they pose tend to both be very difficult to answer and to concern subjects which are abstractly important, but not very personally engaging. For example, here are some recent questions from Metaculus:
And from Good Judgement Open:
I don’t think it’s ever going to make sense for me to spend several hours learning the principles of Italian ministerial politics just for the sake of getting one bit of feedback half a year from now. Surely there’s an easier way to get my foot in the door of the forecasting game.
The Calibrate Your Judgement App is much better in this respect. The questions don’t require any specialist knowledge. Here’s are some typical examples:
You get immediate feedback on your answers in the form of a meticulously designed points system. However, you’re only practicing one element of forecasting: calibration. You’re not going to improve your use of heuristics, Fermi estimates, or creative data gathering from the app.
What about yearly or quarterly predictions like Scott Alexander or Vox? These have the advantage that you can make predictions about topics which you are already knowledgeable and invested in. But thinking up enough questions to get good feedback is very time consuming.
Plus, feedback takes a long time to arrive, and following through with scoring can be a challenge.
I thought forecasting practice for beginners could be significantly improved if:
So during the recent Effective Altruism New Zealand retreat I had a go at running a simple forecasting tournament to test these improvements. The retreat spanned four days, included 39 people, and featured a range of workshops, seminars, and physical activities. All in lovely weather and right next to the beach (these details will be important context for the prediction questions). The short timespan and diverse activities made an ideal stage for the kinds of prediction questions I was after. And as a bonus, the social context of the retreat spiced the tournament with competition and community.
In the following sections, I’ll go into the details of how I ran the tournament, how players fared at making predictions, what I learned from the experience, and further work worth pursuing. The headline is that the tournament went better than I expected, and I would encourage other EA retreats or related gatherings to build on the template I used.
On the first evening of the retreat (Thursday), I took 30 minutes to introduce players to the forecasting game and go over a list of 20 prediction questions. The questions are about events which may happen during the retreat, such as “Will anyone lose a hat?”. Players write predicted answers to these questions along with a confidence score on a sheet of paper (no advanced technology required!), which were then handed to me and hidden away. I call this the “prediction session” of the tournament.
On the last evening of the retreat (Saturday), I handed everyone back their prediction sheet, and went through each question again, announcing the correct answer. Players scored their predictions, using a method detailed below, and whoever ended up with the highest score won a hundred dollar donation to the charity of their choice. I call this the “evaluation session” of the tournament.
For simplicity, all prediction questions had yes/no answers, rather than intervals or distributions. When writing these questions, I loosely aimed for the following qualities:
I didn’t do a great job of sticking to these qualities. I spent most of my prep time coming up with the scoring rule and finished writing these questions in a rush before the tournament started. I also thought it was more important to have a diverse range of interesting questions.
Here are the questions I came up with. Feel free to play along at home by retrospectively making your own predictions.
1. Will anyone open a specific first aid kit?
2. During the retreat, will Peter Singer post something new on his Instagram? (The most recent posts were 4, 5, and 7 weeks ago.)
3. Will a nuclear war begin during the retreat?
4. Will exactly one person lose their hat during the retreat?
5. According to my Fitbit, will I have taken at least 10,000 steps on Friday? (Below are my step counts from the previous week.)

6. During the retreat, will a new episode of the 80,000 Podcast be released? (Below are the most recent episodes)
7. Will Catherine be on the winning team of Wits and Wagers? (An annual game of devising and betting on point estimates. Catherine had been in the winning team for the last three years.)
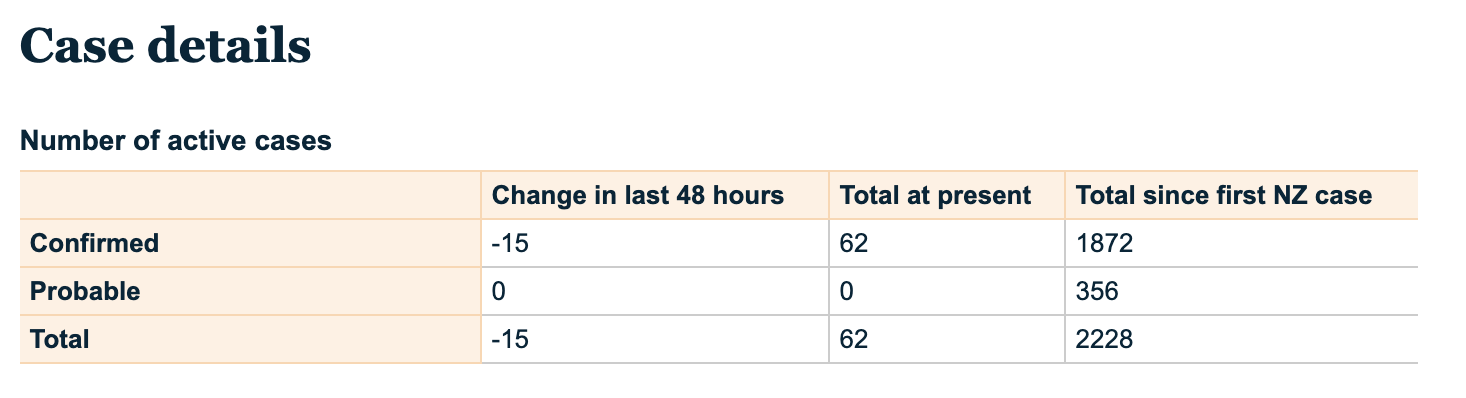
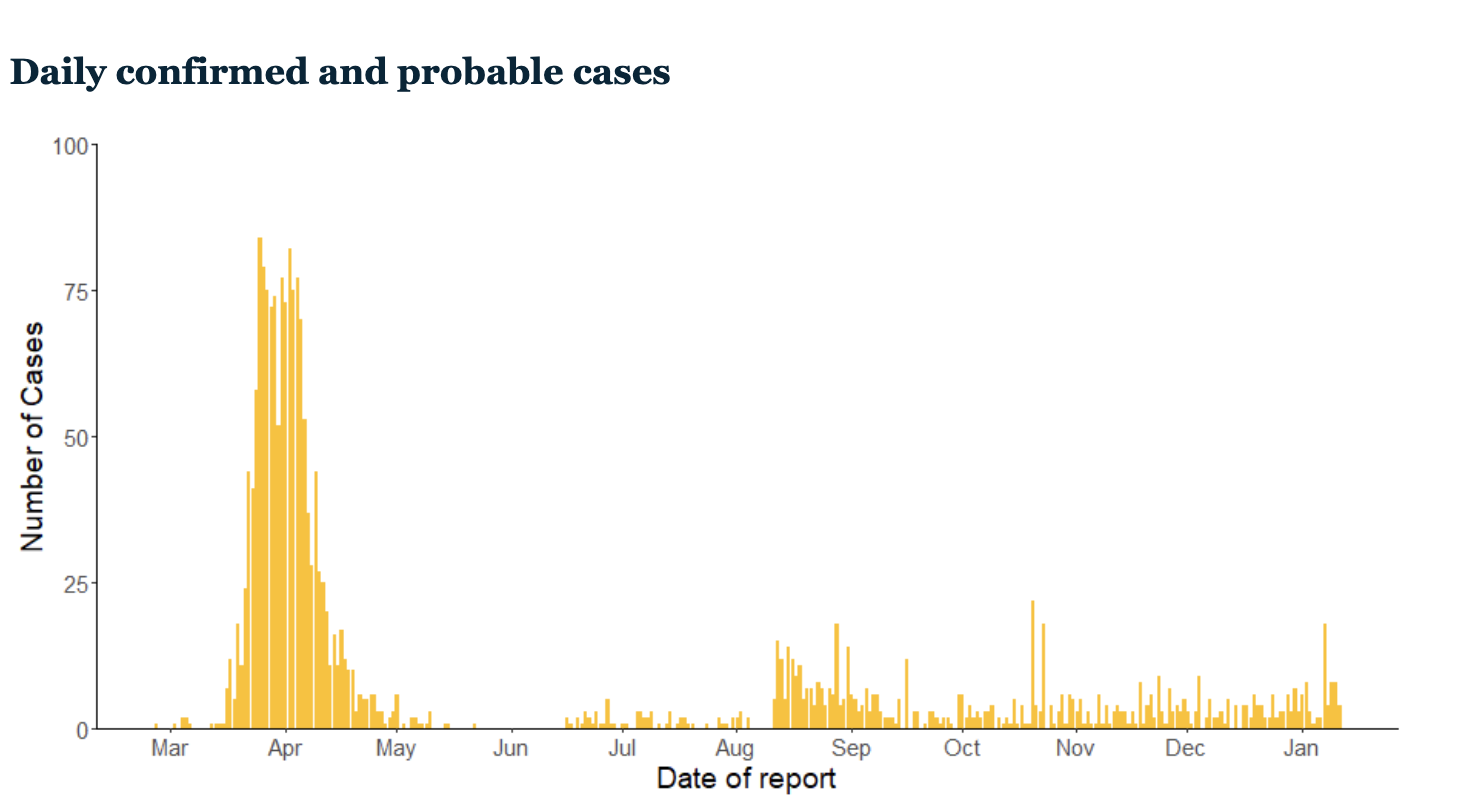
8. On Saturday, will active COVID cases in New Zealand exceed 50? (Below is a table and chart of active cases from the New Zealand Ministry of Health website. As shown, at the time of the predictions session we had 62 active cases.)
9. On Saturday, will active COVID cases in New Zealand exceed 75?
10. On Saturday, will active COVID cases in New Zealand exceed 100?
11. Will at least two people have gotten visibly sunburnt by the time we do scoring?
12. Will at least three people attend morning yoga on Saturday?
13. Will anyone end up kayaking to the island? (There was a specific island which some people had already planned to kayak to.)
14. When we do scoring, I will pick two random people and ask if they have talked to each other. Will they both say “yes”?
15. Will you go on more than two swims?
16. Will Ivan have taken more than 50 photos between getting on the boat and scoring? (Ivan was one of the retreat organisers.)
17. Will Ivan have taken more than 100 photos between getting on the boat and scoring?
18. Will Ivan have taken more than 150 photos between getting on the boat and scoring?
19. Will Ivan have taken more than 200 photos between getting on the boat and scoring?
20. When we do scoring, will the highest score from all the previous questions be greater than 80?
A few of these questions were subject to last minute changes. Question 1 was originally just “will anyone require first aid”, but this was too vague. Question 20 originally asked if the highest score would be above 200, until someone pointed out that this was impossible.
So how do you evaluate player predictions? Spencer Greenberg has written the canonical paper on designing scoring rules to give intuitive feedback. He asserts a user-friendly scoring rule should have these properties:
A scoring rule should also be proper, meaning that if you report your confidences honestly you will receive the most points in expectation. That is, the scoring rule isn’t gameable.
With these principles, Greenberg concluded that this is the most user-friendly scoring rule:

where p is the confidence assigned to a prediction (p for probability), and c is the “correctness” of the prediction (c=0 for incorrect, c=1 for correct). Also, pmax is the maximum confidence players are allowed to assign, prand is the probability which would be assigned if the outcome was chosen randomly, and smax is the upper bound on scores from a single prediction.
This is a great scoring rule for a web app. However, at the retreat I couldn’t guarantee everyone would have a computer, so I couldn’t use any maths which couldn’t be computed by hand. Even if I could guarantee everyone would have a computer, I probably wouldn’t want people Googling helpful information instead of talking to each other.
So instead, I decided to use a scoring table. People are restricted to a small number of confidences with pre-computed points for being correct or incorrect. My first thought was to restrict confidences to tens: 50%, 60%, 70%, 80%, 90%, 100%. Confidences below 50% are expressed by changing a “yes” answer to a “no” answer. Because good Bayesians are never 100% confident, I changed the highest confidence to 99%.
This still seemed like more gradations than a novice forecaster needed. I further narrowed it to 50% (no idea), 60% (2/3, or slight suspicion that is correct), 80% (4/5, or good chance that prediction is correct), and 99% (near certainty that prediction is correct). I then computed the logarithmic scores for these confidence values. Logarithmic scoring is a proper scoring rule where points deducted are equal to the log of the probability assigned to the outcome. (In logarithmic scoring, you lose points for anything except 100% confidence in the right answer.) So if I said that someone would lose their hat with 80% confidence and was right, I would get points. And if I was wrong, I would get points. Logarithmic scoring is the most “natural” scoring rule. Among other properties, it deducts points equal to the number of bits of surprisal of an outcome for a forecaster.
I needed the pre-computed scores to be quickly added, so I rounded them to integers. A proper scoring rule which is linearly scaled (multiplied by something and a constant added) is still a proper scoring rule, so to make the scores more memorable and compliant with Greenberg’s criteria, I played around with linear scaling in a spreadsheet until I came up with the following scoring table:

Players now have a scoring system they can write at the top of their prediction sheet, and use to quickly calculate final scores in the evaluation session. As a bonus, the transparency of the scoring system means that players can better understand the stakes of high confidence: “am I really prepared to risk losing 60 points on this question?” Complicated scoring rule formulae are no longer a barrier to mathematically weak forecasters.
Although I was very pleased with this scoring rule when I thought of it, it does have a serious problem. The boundaries where a rational points-maximiser should switch from one confidence to another are unintuitive. Suppose your true confidence is 91%. Rounding this to the nearest allowed confidence brings you to 99%, so that should be your assigned confidence, right? Wrong. When you do the expected score calculations, you find that for a true confidence of anywhere between 73.3% and 93.9%, the best strategy is to report 80% confidence. I’ve since figured out a better way to do scoring which I’ll discuss in a future post.
In this section I’ll go over the strategies used by players, final scores, and the winner of the tournament. For the actual outcomes of the predictions, see the appendix.
The most common strategy I observed was when a question’s outcome could be influenced by player behaviour, players would predict an outcome with 99% confidence then devise a plan to make their predicted outcome happen. One player even made a to-do list:

There was one instance of this strategy which stood out in its deviousness. One player, who we will call T, assigned 99% confidence to Ivan taking at least 100, 150, and 200 photos. T then bribed Ivan with a $100 donation to the charity of his choice in exchange for taking a photo on T’s phone. T had also adjusted his camera app’s settings so that pressing the “take photo” button once in fact took 500 photos in quick succession.
But the shenanigan strategy could go wrong in several ways. Some players forgot about their plans or failed to follow through on them. One player predicted with 99% confidence that he would go on at least three swims but was too lazy to even go on two swims. Many players intended to go to morning yoga but when the morning actually came they were either sleeping in or busy kayaking to the island.
One question which was especially good at tripping up shenanigan strategists was “Will exactly one person lose their hat during the retreat?” Several people answered “yes” with high confidence and immediately began conspiring to steal someone’s hat. But this strategy will fail if two or more hats get independently stolen. The conspirators would need to coordinate amongst themselves to steal a single hat (without tipping off the hat-theft victim), and even then they would fail if another hat was coincidentally lost. A better strategy would be to answer “no” with high confidence then steal two hats. The moral is that you should think carefully about whether it’s easier to push the outcome in the “yes” or the “no” direction.
I myself had my hat stolen, but my girlfriend gave it back when I started panicking about sunburn. She stole it again near the evaluation session, but again gave it back when she realised she had actually predicted “no” with 99% confidence.
Here’s an example of someone’s prediction sheet. Look how efficient the system is!

Here is the distribution of player scores, along with a table of score statistics. For context, the highest possible score was 200, and the lowest possible score was -1200.
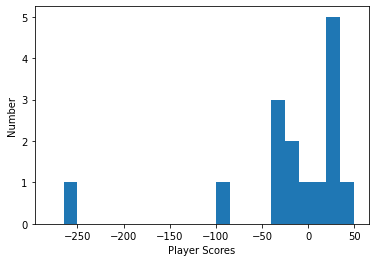

So the median forecaster was slightly better than chance, but the mean forecaster was not.
The winner of the tournament was Catherine who scored 54 points (even though she wasn’t in the winning wits and wagers team). She chose to direct her $100 donation prize to the Good Food Institute.
After the retreat, I sent a Google Form to participants for feedback. The form was filled out by 9 people. Here are the questions and their answers:
When asked about what strategies participants used for making predictions, two participants said they assigned unrealistically higher confidences as a "win or bust" strategy (if you assign higher-than-true confidences, you decrease the expected value of your final score, but increase its variance, and, perhaps, the probability of winning). Other prediction strategies included "listening to neighbours", "going with my gut", and "prior knowledge: the 80kH Podcast has recently been released on Thursdays''.
The biggest surprise from the forecasting tournament was how fun it was. Before the game, several people told me they were looking forward to it. Coming up with the prediction questions and scoring mechanism was an interesting challenge. Players were loud and lively during the game. Afterward, multiple people said the game was their highlight of the retreat. 9/9 survey respondents said they enjoyed it.
Making the questions shenanigan-proof turned out to be a red herring. Shenanigans were most of the fun! Besides, practical predictions in the real world aren’t typically shenanigan proof. As agents that are actually embedded in the world, there are really four prediction skills we should cultivate:
Often practical predictions are mixtures of several of these. For example, whether or not you should do a PhD will depend on:
Ideally then, the forecasting tournament would have had more of a mix of these different types of prediction tasks. You do need to think careful about shenanigan dynamics though. For example, suppose you used this question to test behaviour prediction:
Will you be able to solve a ten-letter anagram within one minute?
To avoid the failure mode of someone predicting “no” with 99% confidence and not trying, forecasters would be required to answer “yes”, and only have control over their confidence level. A question like this would also have a good dramatic-reveal-at-the-evaluation-session factor.
One of my test-readers added:
I would go as far as to say that the shenanigans made this tournament a superior forecasting experience to most others by adding a whole new layer of variables to account for in addition to variables independent of forecasters, and greater use/improvement of judgement and decision-making as per the tournament's fundamental aims. It certainly made things more fun also!
The question
When we do scoring, I will pick two random people and ask if they have talked to each other. Will they both say ‘yes’?
was originally intended to be an operationalisation of “how likely are any given to people to have talked to each other”. But because I didn’t require that the two people answer honestly, the problem actually ends up resembling a prisoner’s dilemma. If there were only two players - Alice and Bob - who had in fact talked to each other, then Alice might realise she can predict “no” with 99% confidence, then lie “no, I haven’t talked to Bob”, and thus guarantee her prediction was correct. In the two-player case then, the unique Nash equilibrium is for both players to predict “no” with 99% confidence and answer “no” when asked if they’ve talked to one another.
I believe the three-player version will also have a unique Nash equilibrium of all players predicting and answering “no”, but for four or more players the “no” equilibrium stops being unique. But I really love that you can apply a game-theoretic analysis to this question. It reminds me of the “Guess 2/3 of the average” Game. In future iterations of forecasting tournaments, I’d like to more explicitly invoke situations where game theoretic analysis is useful.
By the laws of narratology, the questions should’ve progressed from easy to hard.
The trouble with doing all the scoring with pen and paper is that announcing the winner turned into an auction. “Does anyone have a score above 20? Yes, thank you to the lady in the corner. Do I hear a 40? Thank you sir. 60?” The original “winner” actually turned out to have miscalculated their score when audited. And after that, there was some ambiguity over who the winner actually was. The highest score was obtained by a late-comer. By the time he had arrived, the answer to the “Will at least two people have gotten visibly sunburnt?” question was clearly answered. He graciously decided not to count the points he won from this question, which bumped him down to second place. To avoid winner ambiguity, I should have explicitly removed this question before letting him make predictions.
It was cool to plot the histogram of scores shown above. But I was only able to make this thanks to luck. I hadn’t planned to collect prediction sheets from players after the tournament, and it only occurred to me that this might be useful a few hours after everyone had left. I had to dig them out of the bin!
Also, it would’ve been nice to get more insight into how forecasters made their predictions. Maybe then I could do a Tetlock-style analysis of cognitive styles or something. I tried to get some information with the Google Form, but I think actually talking to people would have been better.
What would’ve made my life much easier was to get everyone to enter their final scores into a spreadsheet or Google Form during the evaluation session. This would strike a nice compromise between automating boring data collection and minimising computer requirements. It would also solve the problem of determining who the winner is.
Remember how participants who took the survey said they assigned higher-then-true confidences to their predictions as a “win-or-bust” strategy? To avoid this pathology, I think I should make the size of the donation prize for the winner equal to the total points across all players. This way, everyone is incentivised to get maximum points in expectation. This feels more in the spirit of EA: the goal isn't to be the most effective altruist, it's for us all to collectively achieve effective altruism. (Although if the aggregate score does end up in the negative, it would make a very awkward phone call to AMF. “Hello? I’d like you to give me $173. You see, I was running this tournament…”)
The Effective Altruism New Zealand retreat was a great place to test this forecasting tournament. What more could I want than a captive group of smart helpful people? What other experiments could be run on this valuable resource?
Here’s a few ideas, from least to most crazy:
Could EA retreats (and similar gatherings) be used as test-beds for institutional mechanisms? Maybe.
Another question I’ve been thinking about: after you’ve introduced someone to forecasting with a quick tournament, how can you move them up the ladder of forecasting sophistication until they become superforecasters? To increase the time horizons of forecasters, you could do something like spaced repetition: practice on short time horizons until accuracy reaches a certain threshold, then increase the horizon by an order of magnitude. The scope of questions could similarly increase from everyday matters up to global affairs. Perhaps this could be implemented in an app.
I’m planning to run the tournament again next year. Hopefully I’ll have enough overlap in forecasters to say something sensible about the intertemporal correlation of player scores.
I’ve created a google drive folder of resources for anyone interested in running their own prediction tournament. It’s got the slides I used and a document of prediction questions. This includes the questions described here, and others I’ve thought of since. If you can think of any good questions yourself, please suggest an edit to the document. If anyone does run their own forecasting tournament, please write up how it went and add your resources to the folder, so the format can be further refined.
As mentioned at the start, I’d strongly recommend anyone else with the interest and opportunity to organise a forecasting tournament to do so. I reckon it took me 5-10 hours to organize this one, although most of that was coming up with the scoring rule (whereas you will be able to copy my scoring rule).
I have two follow-up EA forum posts planned. The first concerns the aforementioned scoring rule which fixes the unintuitive boundary problem. The second is about forecasting heuristics for making principled predictions quickly.
Thanks for reading, and I look forward to your feedback.
Thanks very much to the organisers of the retreat for making this possible.
Thanks to Christelle Quilang for helping me write the prediction questions.
Thanks to everyone who participated in the tournament.
Thanks to Catherine Low, Christelle Quilang, Kyle Webster, and Mac Jordan for comments and suggestions on this post.
Warning: If there’s any chance you will participate in a future tournament where these questions are recycled, you may want to hold off reading this.
1. Yes. Several people needed to use the first aid kit. For example, one person scraped their leg against a rock while swimming.
2. No. Peter Singer did not post to Instagram.
3. No. Nuclear war did not begin. But this question did get a laugh and gave everyone a chance to be 99% confident on at least one question.
4. No. No one lost their hat.
5. Yes. I took more than 10,000 steps.
6. No. No new 80,000 Hours Podcast Episode.
7. No. Catherine did not win wits and wagers.
8. Yes. Active COVID cases in New Zealand reached 81, which is greater than 50.
9. Yes. Active COVID cases in New Zealand reached 81, which is greater than 75.
10. No. Active COVID cases in New Zealand reached 81, which is less than 100.
11. Yes. At least 10 people got visibly sunburnt.
12. No. No one attended the morning yoga on Saturday.
13. Yes. Two kayaking expeditions went to the island. Some maniacs even slept outside so they could start kayaking as soon as they woke up at dawn.
14. Yes. When I randomly selected players and asked if they had talked to each other, they both said yes.
15. Outcome was conditional on the player. Most, but not all, people went for two swims.
16. Yes. Ivan took over 500 photos, which is greater than 50.
17. Yes. Ivan took over 500 photos, which is greater than 100.
18. Yes. Ivan took over 500 photos, which is greater than 150.
19. Yes. Ivan took over 500 photos, which is greater than 200.
20. No. No one had 80 points by this stage.
Really enjoyed reading your report, I feel very motivated to organize such a tournament at our next local group unconference in Germany and think that your report and resources will make it more likely that I’ll go through with it. What the heck, let’s say 60% that I’ll organize it in the next unconference, conditional on me participating and nobody else bringing it up before me!
Let me know if you do. I'd be keen to help!
@Simon_Grimm and me ended up also organizing a forecasting tournament. It went really well, people seemed to like it a lot, so thanks for the inspiration and the instructions!
One thing we did differently
Questions we used
1. Will the probability of Laschet becoming the next German chancellor be higher than 50% on Hypermind on Sunday, 3pm?
2. Will more than 30 people make a forecast in this tournament?
3. Will one person among the participants do the Giving What We Can pledge during the weekend?
4. During scoring on Sunday before dinner, will two randomly chosen participants report having talked to each other during the weekend? Needs to be more than „Hi“!
5. At the end of Sunday‘s lunch, will there be leftover food in the pots?
6. At Sunday‘s breakfast at 9am, will more than 10 people wear an EA shirt?
7. Will a randomly chosen participant have animal suffering as their current top cause?
8. Will a randomly chosen participant have risks associated with AI as their top cause?
9. At breakfast on Sunday at 9am, will more than half have read at least half of Doing Good Better?
10. Will there be more packages of Queal than Huel at Sunday‘s breakfast?
11. Will there be any rain up until Sunday, 5pm?
12. Will you get into the top 3 forecasters for all other questions except this one?
13. Will participants overall overestimate their probability of getting into the top three?
14. Will more people arrive from the South of Germany than from the North?
15. On average, did people pay more than the standard fee of 100€?