(This is Section 2.2.1 of my report “Scheming AIs: Will AIs fake alignment during training in order to get power?”. There’s also a summary of the full report here (audio here). The summary covers most of the main points and technical terms, and I’m hoping that it will provide much of the context necessary to understand individual sections of the report on their own.
Audio version of this section here, or search "Joe Carlsmith Audio" on your podcast app.)
Beyond-episode goals
Schemers are pursuing goals that extend beyond the time horizon of the
episode. But what is an episode?
Two concepts of an "episode"
Let's distinguish between two concepts of an episode.
The incentivized episode
The first, which I'll call the "incentivized episode," is the concept
that I've been using thus far and will continue to use in what follows.
Thus, consider a model acting at a time t1. Here, the rough idea is to
define the episode as the temporal unit after t1 that training
actively punishes the model for not optimizing – i.e., the unit of
time such that we can know by definition that training is not directly
pressuring the model to care about consequences beyond that time.
For example, if training started on January 1st of 2023 and completed on
July 1st of 2023, then the maximum length of the incentivized episode
for this training would be six months – at no point could the model have
been punished by training for failing to optimize over a
longer-than-six-month time horizon, because no gradients have been
applied to the model's policy that were (causally) sensitive to the
longer-than-six-month consequences of its actions. But the incentivized
episode for this training process could in principle be shorter than six
months as well. (More below.)
Now, importantly, even if training only directly pressures a model to
optimize over some limited period of time, it can still in fact create
a model that optimizes over some much longer time period – that's what
makes schemers, in my sense, a possibility. Thus, for example, if you're
training a model to get as many gold coins as possible within a ten
minute window, it could still, in principle, learn the goal "maximize
gold coins over all time" – and this goal might perform quite well (even
absent training gaming), or survive despite not performing all that well
(for example, because of the "slack" that training allows).
Indeed, to the extent we think of evolution as an analogy for ML
training, then something like this appears to have happened with humans
with goals that extend indefinitely far into the future – for example,
"longtermists." That is,
evolution does not actively select for or against creatures in a manner
sensitive to the consequences of their actions in a trillion years
(after all, evolution has only been running for a few billion
years) – and yet, some humans aim their optimization on trillion-year
timescales regardless.
That said, to the extent a given training procedure in fact creates a
model with a very long-term goal (because, for example, such a goal is
favored by the sorts of "inductive
biases" I'll discuss
below), then in some sense you could argue that training "incentivizes"
such a goal as well. That is, suppose that "maximize gold coins in the
next ten minutes" and "maximize gold coins over all time" both get the
same reward in a training process that only provides rewards after ten
minutes, but that training selects "maximize gold coins over all time"
because of some other difference between the goals in question (for
example, because "maximize gold coins over all time" is in some sense
"simpler," and gradient descent selects for simplicity in addition to
reward-getting). Does that mean that training "incentivizes" or "selects
for" the longer-term goal?
Maybe you could say that. But it wouldn't imply that training "directly
punishes" the shorter-term goal (or "directly pressures" the model to
have the longer-term goal) in the sense I have in mind. In particular:
in this case, it's at least possible to get the same reward by
pursuing a shorter term goal (while holding other capabilities fixed).
And the gradients the model's policy receives are (let's suppose) only
ever sensitive to what happens within ten minutes of a model's action,
and won't "notice" consequences after that. So to the extent training
selects for caring about consequences further out than ten minutes, it's
not in virtue of those consequences directly influencing the gradients
that get applied to the model's policy. Rather, it's via some other,
less direct route. This means that the model could, in principle, ignore
post-ten-minute consequences without gradient descent pushing it to
stop.
Or at least, that's the broad sort of concept I'm trying to point at.
Admittedly, though, the subtleties get tricky. In particular: in some
cases, a goal that extends beyond the temporal horizon that the
gradients are sensitive to might actively get more reward than a
shorter-term goal.
-
Maybe, for example, "maximize gold coins over all time" actually
gets more reward than "maximize gold coins over the next ten
minutes," perhaps because the longer-term goal is "simpler" in some
way that frees up extra cognitive resources that can be put towards
gold-coin-getting.
-
Or maybe humans are trying to use short-term feedback to craft a
model that optimizes over longer timescales, and so are actively
searching for training processes where short-term reward is
maximized by a model pursuing long-term goals. For example, maybe
you want your model to optimize for the long-term profit of your
company, so you reward it, in the short-term, for taking actions
that seem to you like they will maximize long-term profit. One thing
that could happen here is that the model starts optimizing
specifically for getting this short-term reward. But if your
oversight process is good enough, it could be that the
highest-reward policy for the model, here, is to actually optimize
for long-term profit (or for something else long-term that doesn't
route via training-gaming).[1]
In these cases, it's more natural to say that training "directly
pressures" the model towards the longer-term goal, given that this goal
gets more reward. However, I still want to say that longer-term goals
here are "beyond episode," because they extend beyond the temporal
horizon to which the gradients are directly and causally sensitive. I
admit, though, that defining this precisely might get tricky (see next
section for a bit more of the trickiness). I encourage efforts at
greater precision, but I won't attempt them here.[2]
The intuitive episode
Let's turn to the other concept of an episode – namely, what I'll call
the "intuitive episode." The intuitive episode doesn't have a mechanistic
definition.[3] Rather, the intuitive episode is just: a
natural-seeming temporal unit that you give reward at the end of, and
which you've decided to call "an episode." For example, if you're
training a chess-playing AI, you might call a game of chess an
"episode." If you're training a chatbot via RLHF, you might call an
interaction with a user an "episode." And so on.
My sense is that the intuitive episode and the incentivized episode are
often somewhat related, in the sense that we often pick an intuitive
episode that reflects some difference in the training process that makes
it easy to assume that the intuitive episode is also the temporal unit
that training directly pressures the model to optimize – for example,
because you give reward at the end of it, because the training
environment "resets" between intuitive episodes, or because the model's
actions in one episode have no obvious way of affecting the outcomes in
other episodes. Importantly, though, the intuitive episode and the
incentivized episode aren't necessarily the same. That is, if you've
just picked a natural-seeming temporal unit to call the "episode," it
remains an open question whether the training process will directly
pressure the model to care about what happens beyond the
episode-in-thise-sense. For example, it remains an open question whether
training directly pressures the model to sacrifice reward on an earlier
episode-in-thise-sense for the sake of more-reward on a later
episode-in-this-sense, if and when it is able to do so.
To illustrate these dynamics, consider a prisoner's dilemma-like
situation where each day, an agent can either take +1 reward for itself
(defection), or give +10 reward to the next day's agent (cooperation),
where we've decided to call a "day" an (intuitive) episode. Will
different forms of ML training directly pressure this agent to
cooperate? If so, then the intuitive episode we've picked isn't the
incentivized episode.
Now, my understanding is that in cases like these, vanilla policy
gradients (a type of RL algorithm) learn to defect (this test has
actually been done with simple agents – see Krueger et al
(2020)). And I think it's
important to be clear about what sorts of algorithms behave in this way,
and why. In particular: glancing at this sort of set-up, I think it's
easy to reason as follows:
"Sure, you say that you're training models to maximize reward 'on the
episode,' for some natural-seeming intuitive episode. But you also
admit that the model's actions can influence what happens later in
time, even beyond this sort of intuitive episode – including, perhaps,
how much reward it gets later. So won't you implicitly be training a
model to maximize reward over the whole training process, rather
than just on an individual (intuitive) episode. For example, if it's
possible for a model to get less reward on the present episode, in
order to get more reward later, won't cognitive patterns that give
rise to making-this-trade get reinforced overall?"[4]
From discussions with a few people who know more about reinforcement
learning than I do,[5] my current (too-hazy) understanding is that at
least for some sorts of RL training algorithms, this isn't correct.
That is, it's possible to set up RL training such that some limited,
myopic unit of behavior is in fact the incentivized episode – even if
an agent can sacrifice reward on the present episode for the sake of
more-reward later (and presumably: even if the agent knows this).
Indeed, this may well be the default. See footnote for more
details.[6]
Even granted that it's possible to avoid incentives to optimize across
intuitive-episodes, though, it's also possible to not do
this – especially if you pick your notion of "intuitive episode" very
poorly. For example, my understanding is that the transformer
architecture is set up, by default, such that language models are
incentivized, in training, to allocate cognitive resources in a manner
that doesn't just promote predicting the next token, but other later
tokens as well (see
here
for more discussion). So if you decided to call predicting
just-the-next-token an "episode," and to assume, on this basis, that
language models are never directly pressured to think further ahead,
you'd be misled.
And in some cases, the incentives in training towards cross-episode
optimization can seem quite counterintuitive. Thus, Krueger et al (2020)
show, somewhat surprisingly, that if you set the parameters right, a
form of ML training called Q-learning sometimes learns to cooperate in
prisoner's dilemmas despite the algorithm being "myopic" in the sense
of: ignoring reward on future "episodes." See footnote for more
discussion, and see
here
for a nice and quick explanation of how Q-learning works.[7]
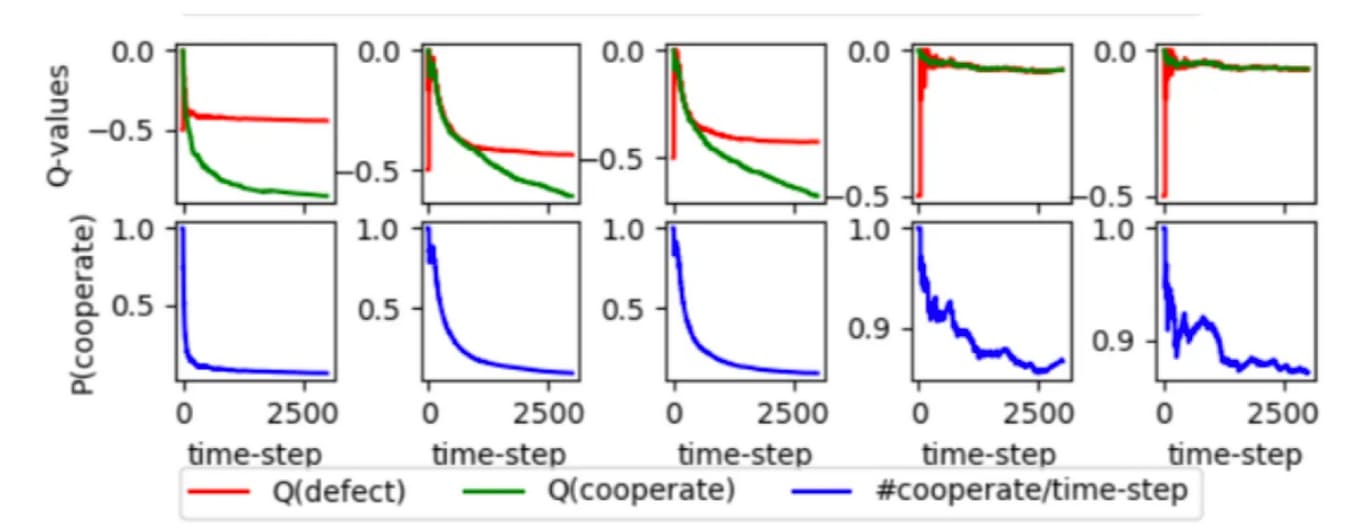
Plots of Q-values and cooperation probability from Figure 11 in
Krueger et al (2020), reprinted with permission. The first three agents
learn to defect, and the last two, to cooperate almost 90% of the time
(note the differences between the y-axes in the first three and the last
two).
Another way to incentivize optimization across intuitive episodes is to
introduce various additional layers (or "outer loops") of selection in
training. Thus, for example, consider a toy and unrealistic form of
"population based
training"
where you create 1000 agents who play starcraft, have them play 100
games each (and get updated along the way via some object-level training
algorithm), then select the one that performs the best on the final
game.[8] In this case, if it were possible for a model to sacrifice
reward on earlier games, in order to perform better on the final game,
there would be at least some selection pressure for it to do so. And
see, also, results in Krueger et al
(2020), showing that a different
form of population based training selects for cooperation in a
prisoner's-dilemma-like case like the one discussed above.[9]
Depending on the details, though, outer-loops of this kind may exert a
much weaker degree of selection pressure than inner loops driven
directly by gradient descent.[10]
Overall, my current sense is that one needs to be quite careful in
assessing whether, in the context of a particular training process, the
thing you're thinking of as an "episode" is actually such that training
doesn't actively pressure the model to optimize beyond the "episode" in
that sense – that is, whether a given "intuitive episode" is actually
the "incentivized episode." Looking closely at the details of the
training process seems like a first step, and one that in theory should
be able to reveal many if not all of the incentives at stake. But
empirical experiment seems important too.
Indeed, I am somewhat concerned that my choice, in this report, to use
the "incentivized episode" as my definition of "episode" will too easily
prompt conflation between the two definitions, and correspondingly
inappropriate comfort about the time horizons that different forms of
training directly incentivize.[11] I chose to focus on the
incentivized episode because I think that it's the most natural and
joint-carving unit to focus on in differentiating schemers from other
types of models. But it's also, importantly, a theoretical object that's
harder to directly measure and define: you can't assume, off the bat,
that you know what the incentivized episode for a given sort of training
is. And my sense is that most common uses of the term "episode" are
closer to the intuitive definition, thereby tempting readers (especially
casual readers) towards further confusion. Please: don't be confused.


A related concept to an "episode" is the set of everything that mediates the agents' achievement of reward, i.e. it's every X that lies on a path A⇢X⇢R for some action A and reward R. These "mediators" X carve out a part of both time and space. An episode is roughly the convex hull of those mediators.