The limited duty exemption has been removed from the bill which probably makes compliance notably more expensive while not improving safety. (As far as I can tell.)
This seems unfortunate.
I think you should still be able to proceed in a somewhat reasonable way by making a safety case on the basis of insufficient capability, but there are still additional costs associated with not getting an exemption.
Further, you can't just claim an exemption prior to starting training if you are behind the frontier which will substantially increase the costs on some actors.
This makes me more uncertain about whether the bill is good, though I think it will probably still be net positive and basically reasonable on the object level. (Though we'll see about futher amendments, enforcement, and the response from society...)
Do you have views on how likely the bill is to pass as-is, or whether anyone should be spending effort making this more (or less) likely? Do you have any thoughts on how we can support changes being made to the bill?
(As an aside, I think this post would be improved by saying a little more in the very first paragraph about what SB-1047 is, and key facts about its progress.)
Do you have views on how likely the bill is to pass as-is, or whether anyone should be spending effort making this more (or less) likely?
Under my views, it seems worthwhile to spend effort to make the bill more likely to pass.
I don't have next steps for this right now, but I might later.
Do you have any thoughts on how we can support changes being made to the bill?
The open letter from Senator Scott Wiener (https://safesecureai.org/open-letter) discusses how to make him and his staff aware of proposed changes. I don't have a particular proposal for how to effectively advocate for particular changes beyond this.
(As an aside, I think this post would be improved by saying a little more in the very first paragraph about what SB-1047 is, and key facts about its progress.)
Seems reasonable, I might edit to add this at some point.
Executive summary: The post provides an analysis of the proposed AI regulation bill SB-1047, arguing that it is reasonable overall with some suggested minor changes, contingent on proper enforcement to avoid being overly restrictive or permissive.
Key points:
The bill aims to regulate AI models that could cause "massive harm" by imposing requirements, while allowing exemptions for models deemed unlikely to have hazardous capabilities.
Key suggested changes include simplifying the criteria for covered models, clarifying derivative model definitions, and potentially raising the threshold for hazardous capabilities.
Proper enforcement is crucial, with developers able to claim limited duty exemptions if they reasonably rule out hazardous capabilities through testing protocols.
The bill de facto bans open-sourcing models with hazardous capabilities, which the author views as a reasonable trade-off if the bar for hazardous capabilities is set appropriately.
The author is uncertain about implementation details like what will constitute reasonable capability evaluations and the gap between the bill's threshold and catastrophic risk models.
Overall support is contingent on beliefs around AI risk, the bill not overly restricting AI development in Western democracies, and reasonable enforcement allowing justified exemptions.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
In this post, I'll discuss my current understanding of SB-1047, what I think should change about the bill, and what I think about the bill overall (with and without my suggested changes).
Overall, SB-1047 seems pretty good and reasonable. However, I think my suggested changes could substantially improve the bill and there are some key unknowns about how implementation of the bill will go in practice.
The opinions expressed in this post are my own and do not express the views or opinions of my employer.
[This post is the product of about 4 hours of work of reading the bill, writing this post, and editing it. So, I might be missing some stuff.]
[Thanks to various people for commenting.]
My current understanding
(My understanding is based on a combination of reading the bill, reading various summaries of the bill, and getting pushback from commenters.)
The bill places requirements on "covered models'' while not putting requirements on other (noncovered) models and allowing for limited duty exceptions even if the model is covered. The intention of the bill is to just place requirements on models which have the potential to cause massive harm (in the absence of sufficient safeguards). However, for various reasons, targeting this precisely to just put requirements on models which could cause massive harm is non-trivial. (The bill refers to “models which could cause massive harm” as “models with a hazardous capability".)
[Edit: limited duty exemption have sadly been removed which makes the more costly while not improving safety. I discuss further in this comment.]
In my opinion, I think the bar for causing massive harm defined by the bill is somewhat too low, though it doesn't seem like a terrible choice to me. I'll discuss this more later.
The bill uses two mechanisms to try and improve targeting:
Flop threshold: If a model is trained with <10^26 flop and it is not expected to match >10^26 flop performance as of models in 2024, it is not covered. (>10^26 flop performance as of 2024 is intended to allow the bill to handle algorithmic improvements.)
Limited duty exemption: A developer can claim a limited duty exemption if they determine that a model does not have the capability to cause massive harm. If the developer does this, they must submit paperwork to the Frontier Model Division (a division created by the bill) explaining their reasoning.
From my understanding, if either the model isn't covered (1) or you claim a limited duty exemption (2), the bill doesn't impose any requirements or obligations.
I think limited duty exemptions are likely to be doing a lot of work here: it seems likely to me that the next generation of models immediately above this FLOP threshold (e.g. GPT-5) won't actually have hazardous capabilities, so the bill ideally shouldn't cover them. The hope with the limited duty exemption is to avoid covering these models. So you shouldn't think of limited duty exemptions as some sort of unimportant edge case: models with limited duty exemptions likely won't be that "limited" in how often they occur in practice!
In this section, I'm focusing on my read on what seems to be the intended enforcement of the bill. It's of course possible that the actual enforcement will differ substantially!
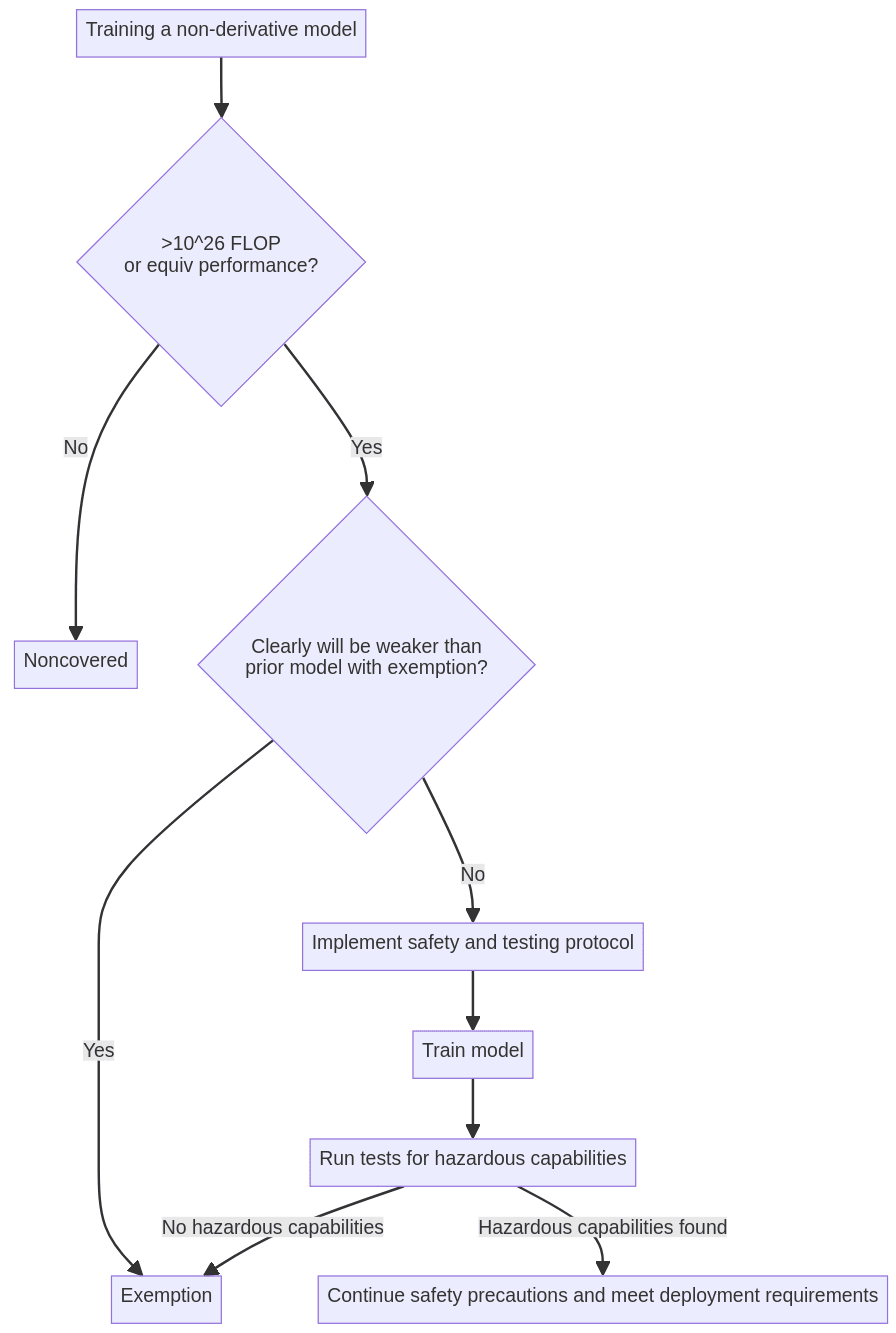
The core dynamics of the bill are best exhibited with a flowchart.
(Note: I edited the flowchart to separate the noncovered node from the exemption node.)
Here's this explained in more detail:
So you want to train a non-derivative model and you haven't yet started training. The bill imposes various requirements on the training of covered models that don't have limited duty exemptions, so we need to determine whether this model will be covered.
Is it >10^26 flop or could you reasonably expect it to match >10^26 flop performance (as of models in 2024)? If so, it's covered.
If it's covered, you might be able to claim a limited duty exemption. Given that you haven't yet trained the model, how can you rule out this model being capable of causing massive harm? Well, the bill allows you to do this by arguing that your model will be strictly weaker than some other existing model which either: (a) itself has a limited duty or (b) is noncovered and "manifestly lacks hazardous capabilities".
(a) basically means that if someone else has already gone through the work of getting a limited duty exemption for some capability level and you're just training a weaker model, you can get an exemption yourself. So, in principle, only organizations training the most powerful models will need to go through the work of making a "from scratch" argument for a limited duty exemption. Given that a bunch of the concern is that we don't know when models will have hazardous capabilities, this seems like a reasonable approach.
I expect that (b) doesn't come up much, but it could mean that you can get an exemption when training a very flop expensive model which will predictably end up without strong general purpose capabilities (perhaps because it's mostly trained on a narrow domain or the training method is much less compute efficient than SOTA methods as of 2024).
Ok, but suppose the model is covered and you can't (yet) claim a limited duty exemption. What now? Well, you'll need to implement a protocol to prevent "critical harm" while training this model and ongoingly until you can do the evals needed to determine whether you can claim a limited duty exemption. You'll also need to submit a protocol for what tests you're going to run on the model to determine if it has hazardous capabilities.
Suppose you're now done training, now you need to actually run these tests. If these tests come up negative (i.e. you can't find any hazardous capabilities), then congrats, you can claim a limited duty exemption and you're free from any obligations. (You do need to submit paperwork to the Frontier Model Division describing your process.)
If found hazardous capabilities or otherwise decided not to claim a limited duty exemption, then you'll need to continue employing safeguards that you claim are sufficient to prevent critical harm and you'll have to follow various precautions when deploying the model more widely.
Ok, but what if rather than training a model from scratch, you're just fine-tuning a model? Under the current bill, you don't need to worry at all. Unfortunately, there is a bit of an issue in that the bill doesn't propose a reasonable definition of what counts as making a derivative model rather than training a new model. (Zvi has discussed this here.) This could cause issues both by placing too high of a responsibility on developers (responsibility for derivative models trained with much more compute) and by allowing people to bypass the bill. In particular, what stops you from just starting with some existing model and then training it for 10x as long and calling this a "derivative model"? I think the courts will probably make a reasonable judgment here, but it should just be fixed in the bill. I'll discuss this issue and how to fix it later.
How I expect this to go in practice (given reasonable enforcement) is that there are a limited number of organizations (e.g. 3) which are developing noncovered models which could plausibly not be strictly weaker than some other existing model with a limited duty exemption. So, these organizations will need to follow these precautions until they can reasonably claim a limited duty exemption. Other organizations can just argue that they're training a weaker model and immediately claim a limited duty exemption without the need to implement a safety or testing protocol. Once we end up hitting hazardous capabilities (which might happen much after 10^26 flop), then all organizations developing such models will need to follow safety protocols.
What if you want to open source a model?
Models can be open sourced if they are reasonably subject to a limited duty exemption or are noncovered. So, if your a developer looking to train and then open source a model, you'll can follow this checklist:
Just fine-tuning a model from a different company? No issues, you’re good to go.
Noncovered? If so, you're good to go.
Is there a strictly stronger model with a limited duty exemption? If so, you're good to go. (Supposing you can be confident the other model is strictly stronger.)
Otherwise, you're on the frontier of non-hazardous model capabilities, so you'll need to create and follow a safety and testing protocol for now. Once the model is trained, you can test for hazardous capabilities and if you can't find any, you can open source the model.
If you do find hazardous capabilities, then the model de facto can't be open sourced (until the world gets sufficiently robust such that the capability level of that model is non-hazardous).
So, a fundamental aspect of this bill is that it de facto does not allow for open sourcing of models with hazardous capabilities. This seems like a reasonable trade-off to me given that open sourcing can't be reversed, though I don't think it's an entirely clear cut issue. (E.g., maybe the benefits from open sourcing are worth the proliferation of hazardous capabilities depending on the circumstances in the world and the exact level of hazardous capabilities.) I think the case for de facto banning open sourcing models with hazardous capabilities would be notably better if the bill had a somewhat higher bar for what counts as a hazardous capability.
People seem to have a misconception that the bill bans open sourcing >10^26 flop models. This is false, the bill allows for open source >10^26 flop, it only restricts open source for models found to have hazardous capabilities.
What should change?
Have 10^26 flop be the only criteria for covered: rather than having models with performance equivalent to 10^26 flop models in 2024 be covered, I think it would be better to just stick with the 10^26 flop hard threshold.
I think just having the 10^26 flop threshold is better because:
It's simpler which reduces fear, uncertainty, and doubt from various actors.
I don’t trust benchmarks that much (e.g. maybe most benchmarks are quite gameable while also not increasing general capability that much). (It seems sad to have tricky benchmark adjudication issues with respect to which models are covered.)
A pure FLOP threshold makes sure that covered models are expensive to train (FLOP/$ is increasing considerably slower than algorithmic efficiency and is more predictable).
This change isn't entirely robust (e.g. what if algorithmic efficiency improvements result in 10^25 flop models having hazardous capabilities?), but it seems like a reasonable trade-off to me.
(Also, if the equivalent performance condition is retained, it should be clarified that this refers to the best performance achieved with 2024 methods using 10^26 flop. This would resolve the issue discussed here (the linked tweet is an obvious hit piece which misunderstands other parts of the bill, and I don’t think this would be an issue in practice, but it seems good to clarify).)
Limit derivative models to being <25% additional flop and cost: to clarify what counts as a derivative model, I think it would be better to no longer consider a model derivative if >25% additional flop is used (relative to prior training) or >25% additional spending on model enhancement (relative to the cost of prior training) is used. I've added the cost based threshold to rule out approaches based on spending much more on higher quantity data, though possibly this is too hard to enforce or track.
Clarify that the posttraining enhancement criteria corresponds to what is still a derivative model: The bill uses a concept of postraining enhancements where a model counts as having hazardous capabilities if it can be enhanced (with posttraining enhancement) to have hazardous capabilities. Unfortunately, the bill does not precisely clarify what counts as a posttraining enhancement versus the training of another model. (E.g. does training the model for 10x longer count as a posttraining enhancement?) I think it would be better to build on top of the prior modification and clarify that a given alternation to the model is considered a valid "posttraining enhancement" if it uses <25% additional flop and cost. It could also be reasonable to have a specific limit for post training enhancements which is smaller (e.g. 2%), though this creates a somewhat arbitrary gap between the best derivative models and what counts as a posttraining enhancement. (That said, I expect that in most cases, if you can rule out 2% additional flop making the model hazardous, you can rule out 25% additional flop making the model hazardous.)
If the posttraining criteria is clarified in this way, it would also be good to apply some sort of time limit on what enhancement technology is applicable. E.g., it only counts as a post training enhancement if it uses <25% additional flop and it can be done using methods created within the next 2 years. It also wouldn’t be crazy to just have the time limit be “current approaches only” (e.g. <25% flop using only currently available methods) to simplify things, though this corresponds less closely with what we actually care about.
If it was politically necessary to restrict the posttraining enhancement criteria (e.g. to be 2% of additional compute and only using the best current methods rather than pricing in future elicitation advances over the next couple of years), this probably wouldn’t be that bad in terms of additional risk due to weakening the bill. Alternatively, if this was needed to ensure reasonable enforcement of this criteria (because otherwise things would be wildly overly conservative), I would be in favor of this restriction, though I don’t expect this change is needed for reasonable enforcement.
(Maybe) Slightly relax the criteria around “lower performance on all benchmarks relevant under subdivision (f) of Section 22602”: The bill allows for a limited duty exemption prior to training (and without needing to run any evals) if “the covered model will have lower performance on all benchmarks relevant under subdivision (f) of Section 22602 and does not have greater general capability than: [either a model with a limited duty exemption or a noncovered model]”. I think “all benchmarks” should probably be relaxed somewhat as a literal interpretation could be very noisy and problematic. (The benchmarks aren’t currently specified which makes it hard to assess the level of noise here.)
(Maybe) Raise the threshold for hazardous capabilities: I think it would probably be better to raise the bar for what is considered a hazardous capability. I think regulation around AI should mostly be concerned with extremely large scale harms (e.g. >100 million people killed or AI takeover). So, I think the thresholds naively should target the point at which AI could substantially increase the likelihood of these harms. However, there are reasonable arguments for triggering earlier: general caution, inability to implement a precise threshold, and actually wanting to reduce earlier smaller harms.
From this perspective, my guess is that the current bar is too early. At the point where the current bar triggers, I’m unsure if restrictions like these are worth the cost under a variety of world views (e.g. de facto banning open source AI is probably a mistake under a variety of world views if open source AI doesn’t pose a substantial risk). This is especially true given that I expect regulators and companies to be somewhat conservative about what counts as a hazardous capability. I also think it seems better to lean in the direction of less restriction/regulation than otherwise seems optimal when crafting government policy on general principles.
That said, I’m also uncertain how early the current bar will trigger. It seems pretty plausible to me that very soon after AIs which can cause $500 million in damages in a single incident you get AIs which can double the total cyber offense capabilities of a competent country. In this case, it isn’t that bad if the bar is a bit low.
Below is my current (premature and half baked) draft proposal for a higher bar. There are probably a bunch of issues with my draft proposal. I’m more confident that the bar should be raised than I’m confident in my proposed alternative bar.
It is a hazardous capability if any of the below conditions are met (with >10% probability[1]):
The AI could autonomously replicate successfully in the absence of a campaign to prevent this (e.g. make money (over >$1 billion in aggregate) and acquire computing hardware to run itself). (A commenter pointed out that this might be too hard to operationalize well.)
The AI can massively accelerate competent cyber offense teams (e.g. by a factor of >2x).[2]
The AI can massively accelerate AI capabilities R&D (e.g. by a factor of >2x).
The AI can make swinging US election results much cheaper (e.g. 5x cheaper per vote).
The AI can allow small teams (e.g. <20 people) of committed and moderately competent individuals (e.g. median recent graduates at a top 50 US university) to kill over 1 million people in a single incident (e.g. using biological or nuclear weapons). (Note that >1 million people is considerably higher than the "mass casualties" threshold in the bill.)
(Related to my proposal about raising the threshold for hazardous capabilities, Zvi has suggested making the current criteria for hazardous capabilities be relative to what you can do with a covered model. I guess this seems like a reasonable improvement to me, but it seems relatively unimportant as covered models aren't very capable.)
(To be clear, I’m most worried about autonomous rogue AIs. I think misuse via APIs probably isn’t that bad of an issue given that I expect “smaller” incidents (e.g. botched bioweapons attack kills its creators and 12 other people) prior to massive incidents and then government and companies can respond. I also don’t expect that AI imposes massive risks (e.g. hugely destabilizing the US, killing over 10 million people, or establish a new rogue AI faction with massive influence) until AIs are generally transformatively powerful (capable of substantially accelerating economic activity and R&D if deployed widely without restriction).)
What do I think about the bill?
Overall, the bill seems pretty good and reasonable to me, subject to fixing the definition of a derivative model. (My other changes are more "nice to have".)
One interesting aspect of the bill is how much it leans on liability and reasonableness. As in, the developer is required to develop the tests and protocol with quite high levels of flexibility, but if this is deemed unreasonable, they could be penalized. In practice, forcing developers to follow this process both gives developers an out (I’m not liable because I followed the process well) and can get them sued if they don’t do the process well (you knew you didn’t do evals well, so you should have known there could be problems). (From my limited understanding of how law typically works here.)
Perhaps unsurprisingly, people seem to make statements that imply that the bill is far more restrictive than it actually is. (E.g. statements that imply it bans open source rather than just banning open sourcing models with hazardous capabilities.) (See also here.)
I’m also uncertain about how enforcement of this bill will go and I’m worried it will be way more restrictive than intended or that developers will be able to get away with claiming exemptions while doing a bad job with capability evaluations. See the appendix below on “Key questions about implementation and how the future goes” for more discussion.
It’s worth noting that I don’t think that good enforcement of this bill is sufficient to ensure safety (even if all powerful AI models are subject to the bill).
Overall, the bill seems pretty good to me assuming some minor fixes and reasonable enforcement.
Appendix: What would change my mind about the bill and make me no longer endorse it?
As discussed in the prior section, the bill seems pretty good to me conditional on minor fixes and reasonable enforcement. It might be worth spelling out what views I currently have which are crucial for me thinking the bill is good.
This section is lower effort than prior sections (as it is an appendix).
Here are some beliefs I have that are load-bearing for my support of this bill.
When models which are unlikely to have a hazardous capability (even when enhanced in relatively cheap ways over the next 2 years) and the developer does a reasonable job with capability evaluations, that developer will be able to claim a limited duty exemption without running into issues. If I thought that limited duty exemptions would be (successfully) challenged even if we can pretty effectively rule out hazardous capability (like we can for e.g. GPT-4), then I would be opposed to the bill.
This is a good reason to advance the state of capability evaluation science from the perspective of both people who are concerned about catastrophic risk and those who aren’t concerned but are worried AI regulation will be too restrictive: the more easily we can rule out problematic capabilities, the better targeted regulation can be.
It’s conceivable to me that the “posttraining enhancements” criteria will result in overly conservative enforcement. If this is a serious issue (which seems unlikely but possible to me), then the posttraining enhancements criteria should be tightened accordingly. (See discussion under “If it was politically necessary to restrict the posttraining enhancement criteria” above.) (Some people seem to think the posttraining enhancements criteria is a big issue (I’m skeptical), see e.g. here.)
AI poses substantial risk of catastrophe (in the absence of potentially costly countermeasures). My view here is that this risk of catastrophe comes from future powerful AIs which are (at least) able to cheaply automate cognitive work which currently can only be done by human professionals.
At least one of:
Seriously bad misalignment of AI systems which is unintended by developers is non-trivially likely.
There are catastrophically dangerous offense-defense imbalance issues related to transformatively powerful AI. (I mean this somewhat broadly. For instance, I would include cases where it is in principle possible to defend, but this isn’t that likely to happen due to slow moving actors or other issues.)
AI systems are reasonably likely to cause explosive technological growth (>30% annualized world GDP growth), and explosive growth poses some risk of catastrophe.
Failing to regulate AI like this would substantially weaken the relative power of western liberal democracies via relatively empowering adversaries. (E.g., because in the absence of regulation, AIs would be used at large scale by adversaries to advance military technology.)
The bill won’t directly make the AI sectors of western liberal democracies relatively much less competitive with adversaries other than due to a reasonable case that costly safeguards are required for mitigating catastrophic risk.
I don’t currently see any plausible mechanism via which the bill could directly cause this.
Appendix: Key questions about implementation and how the future goes
There is a bunch of stuff about the bill which is still up in the air as it depends on implementation and various details of how AI goes in the future. I think some of these details are important and somewhat under discussed:
What will count as a reasonable job assessing hazardous capabilities with respect to successfully claiming a limited duty exemption?
How long of a gap will there be between the threshold for hazardous capability in the bill and models which pose serious catastrophic risk? No gap? 1 year of gap? A negative gap?
For models which are covered and don’t have limited duty exemptions, what safeguards will be required? What will “applicable guidance from the Frontier Model Division, National Institute of Standards and Technology, and standard-setting organizations” look like?
To what extent will developers be over/under conservative with respect to claiming limited duty exemptions for whatever reason?
Will there be court cases about whether developers are in violation? How will this go? E.g., how reasonable will judges be?
What happens if one developer claims a limited duty exemption, another developer claims an exemption on the basis of their AI being strictly weaker than the prior AI, and finally the first developer's exemption is challenged in court? If the exemption ends up being removed, what happens to the second developer?
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...


The limited duty exemption has been removed from the bill which probably makes compliance notably more expensive while not improving safety. (As far as I can tell.)
This seems unfortunate.
I think you should still be able to proceed in a somewhat reasonable way by making a safety case on the basis of insufficient capability, but there are still additional costs associated with not getting an exemption.
Further, you can't just claim an exemption prior to starting training if you are behind the frontier which will substantially increase the costs on some actors.
This makes me more uncertain about whether the bill is good, though I think it will probably still be net positive and basically reasonable on the object level. (Though we'll see about futher amendments, enforcement, and the response from society...)
(LW x-post)