Comments
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Subscribe here to receive future versions.
---
ChaosGPT and the Rise of Language Agents
Chatbots like ChatGPT usually only respond to one prompt at a time, and a human user must provide a new prompt to get a new response. But an extremely popular new framework called AutoGPT automates that process. With AutoGPT, the user provides only a high-level goal, and the language model will create and execute a step-by-step plan to accomplish the goal.
AutoGPT and other language agents are still in their infancy. They struggle with long-term planning and repeat their own mistakes. Yet because they limit human oversight of AI actions, these agents are a step towards dangerous deployment of autonomous AI.
Individual bad actors pose serious risks. One of the first uses of AutoGPT was to instruct a model named ChaosGPT to “destroy humanity.” It created a plan to “find the most destructive weapons available to humans” and, after a few Google searches, became excited by the Tsar Bomba, an old Soviet nuclear weapon. ChaosGPT lacks both the intelligence and the means to operate dangerous weapons, so the worst it could do was fire off a Tweet about the bomb. But this is an example of the “unilateralist’s curse”: if one day someone builds AIs capable of causing severe harm, it only takes one person to ask it to cause that harm.

More agents introduce more complexity. Researchers at Stanford and Google recently built a virtual world full of agents controlled by language models. Each agent was given an identity, an occupation, and relationships with the other agents. They would choose their own actions each day, leading to surprising outcomes. One agent threw a Valentine’s Day party, and the others spread the news and began asking each other on dates. Another ran for mayor, and the candidate’s neighbors would discuss his platform over breakfast in their own homes. Just as the agents in this virtual world had surprising interactions with each other, autonomous AI agents have unpredictable effects on the real world.

How do LLM agents like GPT-4 behave? A recent paper examined the safety of LLMs acting as agents. When playing text-based games, LLMs often behave in power-seeking, deceptive, or Machiavellian ways. This happens naturally. Much like how LLMs trained to mimic human writings may learn to output toxic text, agents trained to optimize goals may learn to exhibit ends-justify-the-means / Machiavellian behavior by default. Research to reduce LLMs’ Machiavellian tendencies is still in its infancy.
Natural Selection Favors AIs over Humans
CAIS director Dan Hendrycks released a paper titled Natural Selection Favors AIs over Humans.
The abstract for the paper is as follows:
For billions of years, evolution has been the driving force behind the development of life, including humans. Evolution endowed humans with high intelligence, which allowed us to become one of the most successful species on the planet. Today, humans aim to create artificial intelligence systems that surpass even our own intelligence. As artificial intelligences (AIs) evolve and eventually surpass us in all domains, how might evolution shape our relations with AIs? By analyzing the environment that is shaping the evolution of AIs, we argue that the most successful AI agents will likely have undesirable traits. Competitive pressures among corporations and militaries will give rise to AI agents that automate human roles, deceive others, and gain power. If such agents have intelligence that exceeds that of humans, this could lead to humanity losing control of its future. More abstractly, we argue that natural selection operates on systems that compete and vary, and that selfish species typically have an advantage over species that are altruistic to other species. This Darwinian logic could also apply to artificial agents, as agents may eventually be better able to persist into the future if they behave selfishly and pursue their own interests with little regard for humans, which could pose catastrophic risks. To counteract these risks and evolutionary forces, we consider interventions such as carefully designing AI agents’ intrinsic motivations, introducing constraints on their actions, and institutions that encourage cooperation. These steps, or others that resolve the problems we pose, will be necessary in order to ensure the development of artificial intelligence is a positive one.
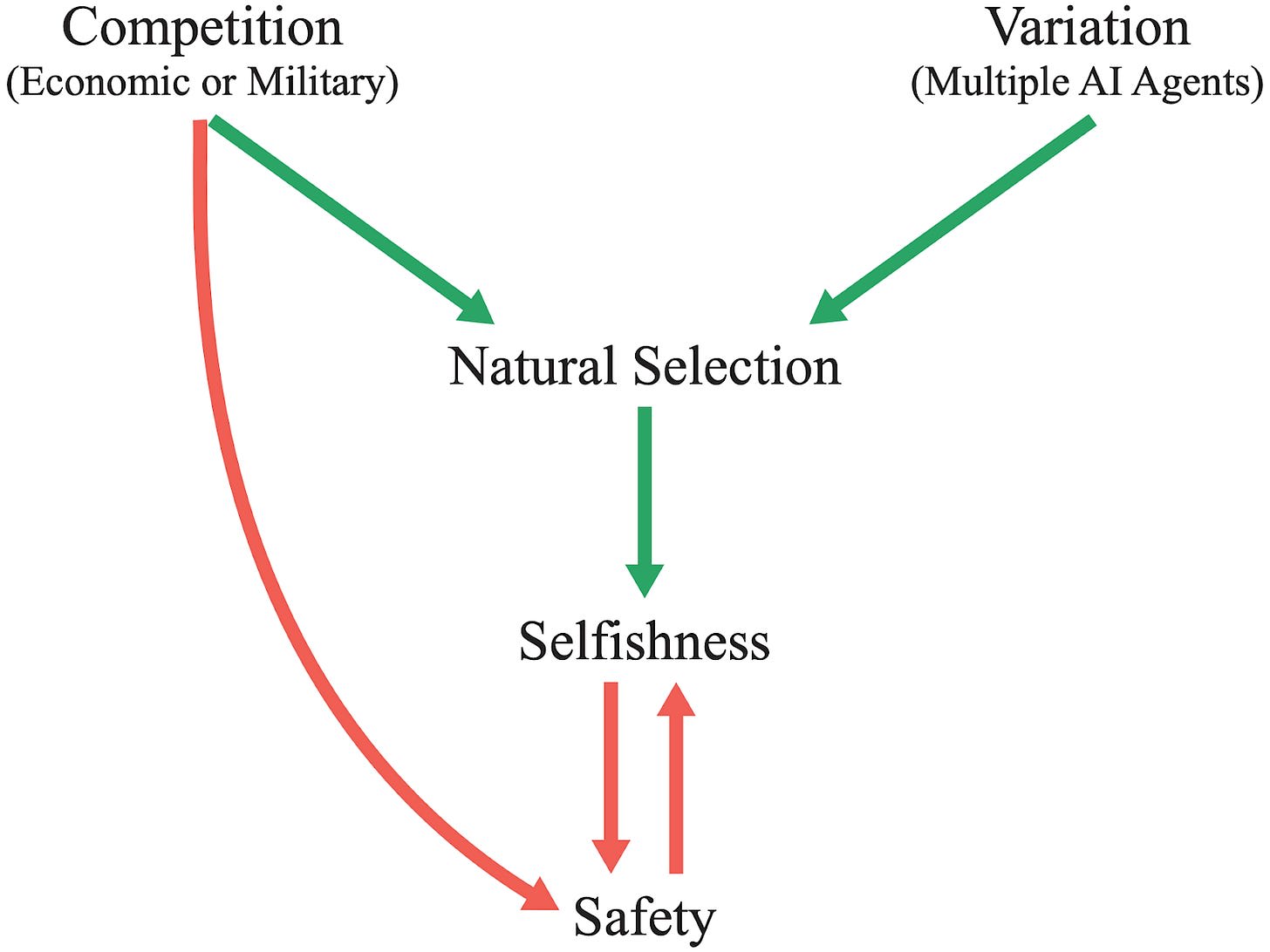
The argument relies on two observations. Firstly, natural selection may be a dominant force in AI development. Competition and power-seeking may dampen the effects of safety measures, leaving more systemic forces to select the surviving AI agents. Secondly, evolution by natural selection tends to give rise to selfish behavior. While evolution can result in cooperative behavior in some situations (for example in ants), the paper argues that AI development is not such a situation.
A link to the paper is here.
AI Safety in the Media
We compiled several examples of AI safety arguments appearing in mainstream media outlets. There have been articles and interviews in NYT, FOX, TIME, NBC, Vox, and The Financial Times. Here are some highlights:
- “[AI companies] do not yet know how to pursue their aim safely and have no oversight. They are running towards a finish line without an understanding of what lies on the other side.” (Financial Times)
- “Drug companies cannot sell people new medicines without first subjecting their products to rigorous safety checks. Biotech labs cannot release new viruses into the public sphere in order to impress shareholders with their wizardry. Likewise, A.I. systems with the power of GPT-4 and beyond should not be entangled with the lives of billions of people at a pace faster than cultures can safely absorb them.” (NYT)
- “AI threatens to join existing catastrophic risks to humanity, things like global nuclear war or bioengineered pandemics. But there’s a difference. While there’s no way to uninvent the nuclear bomb or the genetic engineering tools that can juice pathogens, catastrophic AI has yet to be created, meaning it’s one type of doom we have the ability to preemptively stop.” (Vox)
For several years, AI safety concerns were primarily discussed among researchers and domain experts. In just the last few months, concerns around AI safety have become more widespread.
The effects of this remain to be seen. Hopefully, the increased awareness and social pressure around AI safety will lead to more AI safety research, limits on competitive pressures, and regulations with teeth.
---
See also: CAIS website, CAIS twitter, A technical safety research newsletter


I think the most urgent thing we need now, post-GPT-4 and AutoGPT, is a global AGI moratorium / Pause (alignment isn't going to be solved in time otherwise). We need dedicated organisations pushing for this. I am keen to help seed some (DM me if interested in working on this, can provide some funding).