This is a linkpost for https://deepmind.google/technologies/gemini/
Gemini Pro (the medium-sized version of the model) is now available to interact with via Bard.
Here’s a fun and impressive demo video showing off Gemini’s multi-modal capabilities:
[Edit, Dec. 8 at 5:54am EST: This demo video is potentially misleading.]
How Gemini compares to GPT-4, according to Google DeepMind:
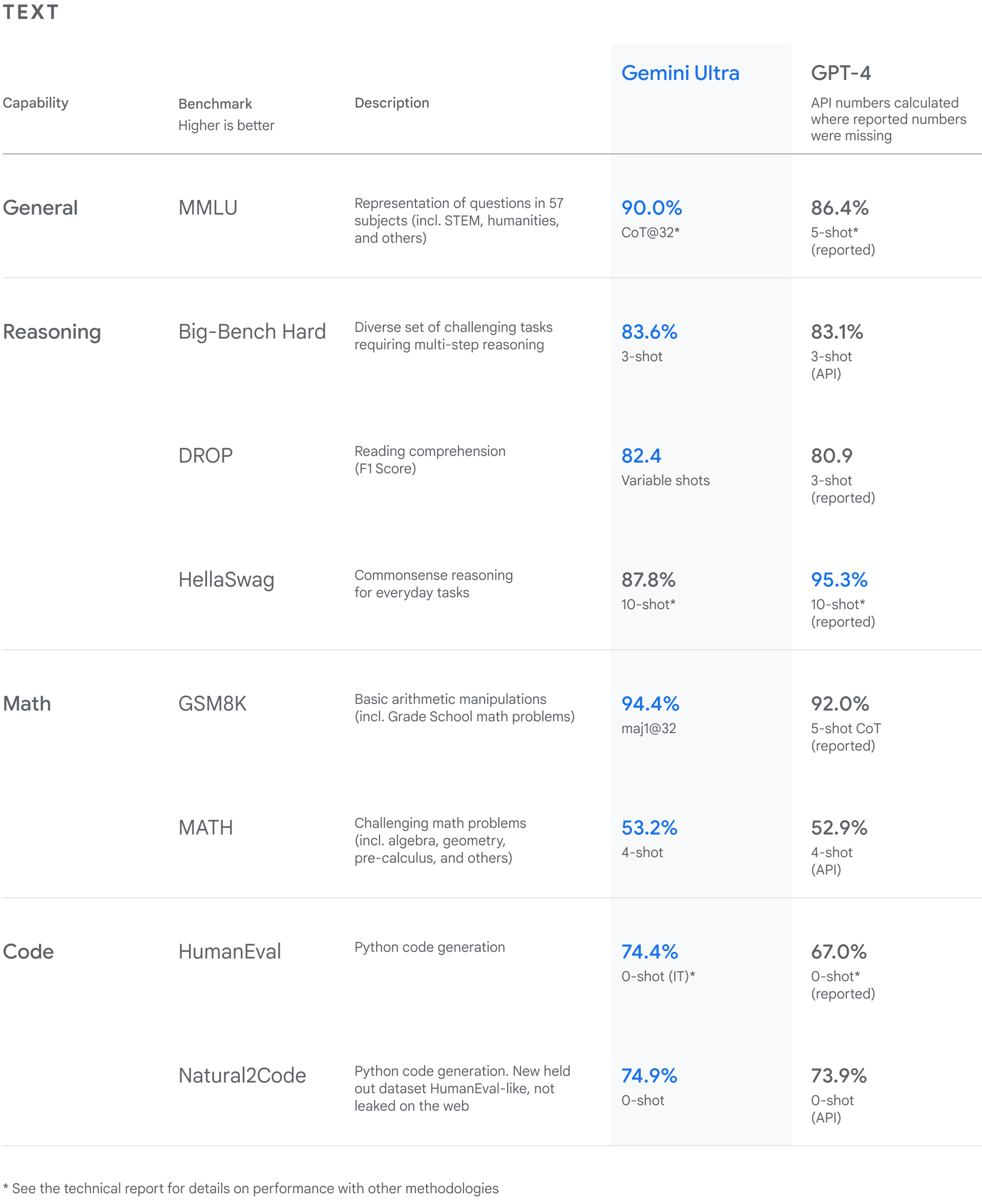
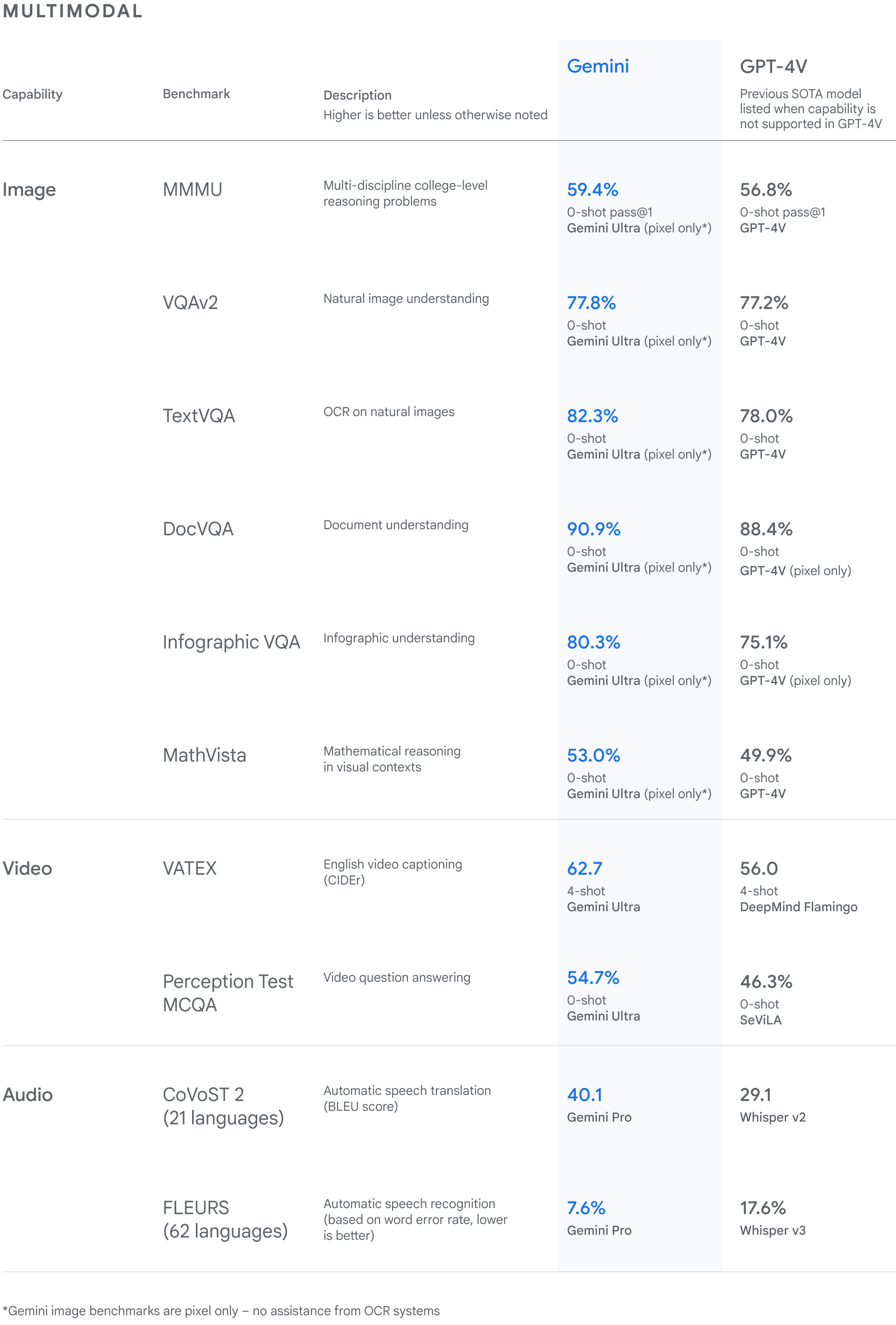
I think the forecast seems broadly reasonable, but the question and title seem quite poor. As in, the operationalization seems like a very poor definition for "weakly general AGI" and the tasks being forecast don't seem very important or interesting.
I think GPT-4V likely already achieves 2 (winograd) and 3 (SAT) while 4 (montezuma's revenge) seems plausible for GPT-4V, though unclear. Beyond this, 1 (turing test) seems to be extremely dependent on the extent to which the judge is competently adversarial and whether or not anyone actually finetunes a powerful model to perform well on this task. This makes me think that this could plausibly resolve without any more powerful models, but might not happen because no one bothers running a turing test seriously.
Can't we just use an SAT test created after the data cutoff? Also, my guess is that the SAT results discussed in the GPT-4 blog post (which are >75th percentile) aren't particularly data contaminated (aside from the fact that different SAT exams are quite similar which is the same for human students). You can see the technical report for more discussion on data contamination (though account for bias accordingly etc.)