Crossposted from AI Impacts blog
The 2023 Expert Survey on Progress in AI is out, this time with 2778 participants from six top AI venues (up from about 700 and two in the 2022 ESPAI), making it probably the biggest ever survey of AI researchers.
People answered in October, an eventful fourteen months after the 2022 survey, which had mostly identical questions for comparison.
Here is the preprint. And here are six interesting bits in pictures (with figure numbers matching paper, for ease of learning more):
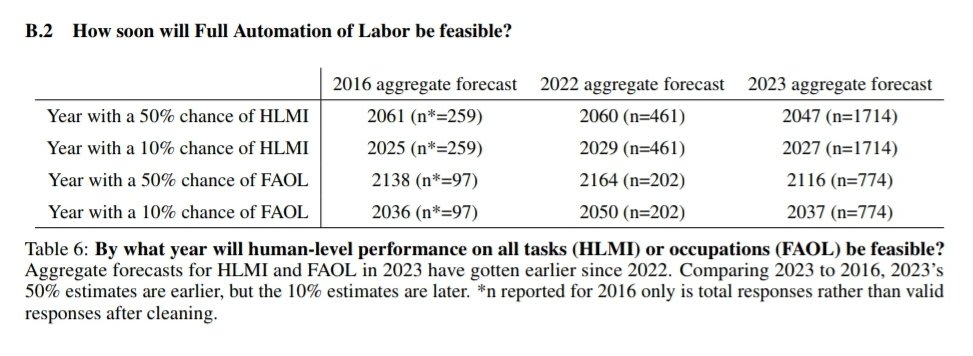
1. Expected time to human-level performance dropped 1-5 decades since the 2022 survey. As always, our questions about ‘high level machine intelligence’ (HLMI) and ‘full automation of labor’ (FAOL) got very different answers, and individuals disagreed a lot (shown as thin lines below), but the aggregate forecasts for both sets of questions dropped sharply. For context, between 2016 and 2022 surveys, the forecast for HLMI had only shifted about a year.
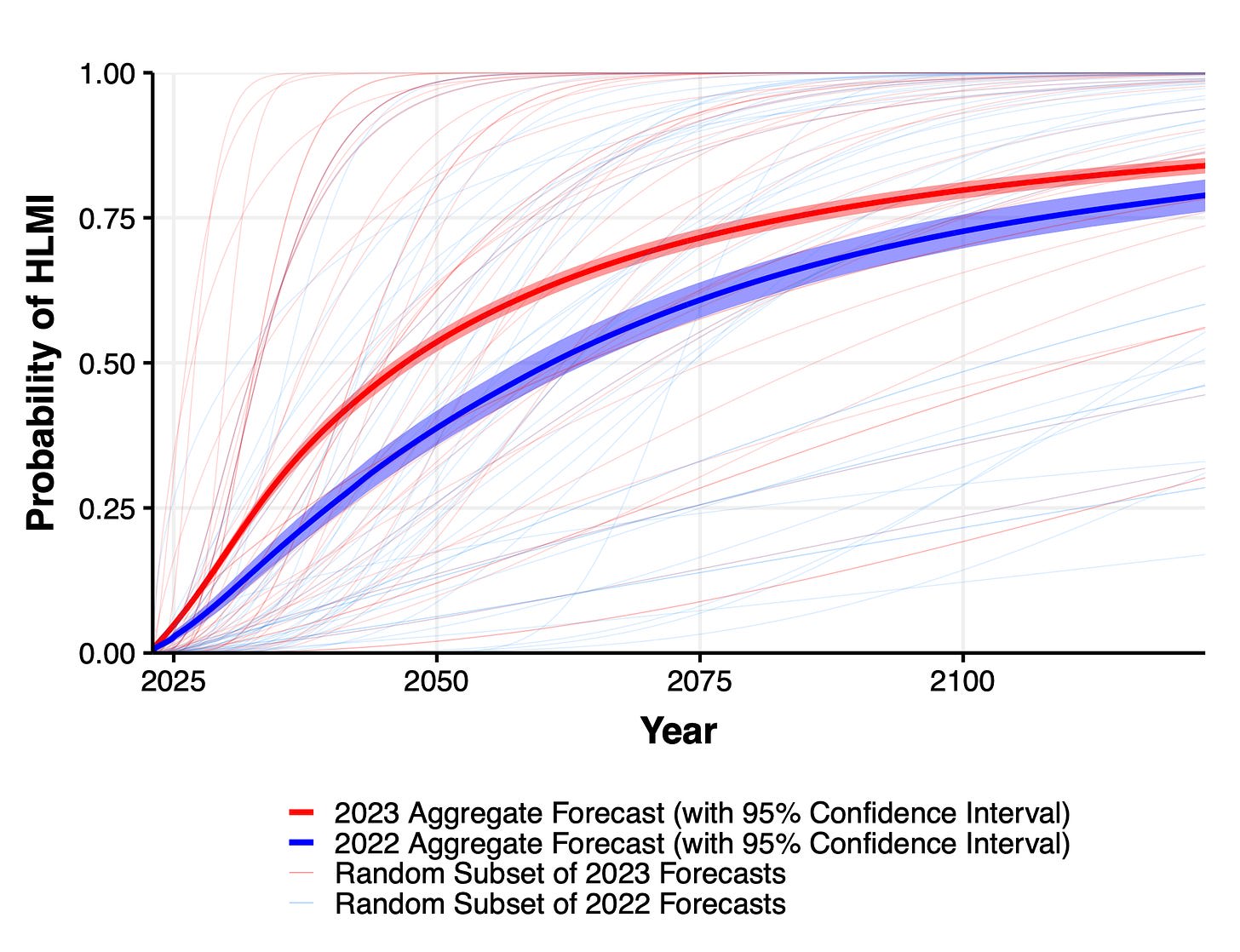
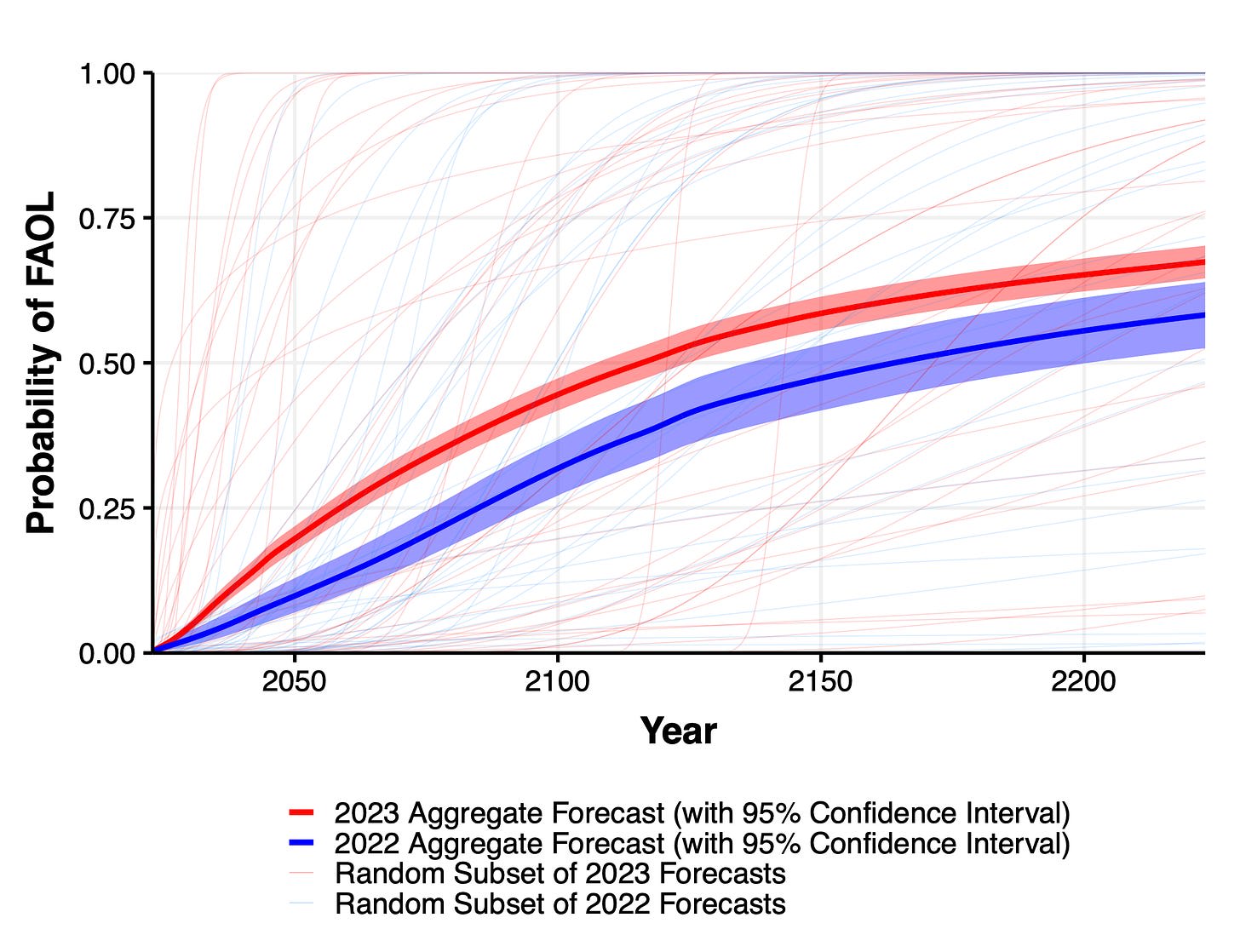
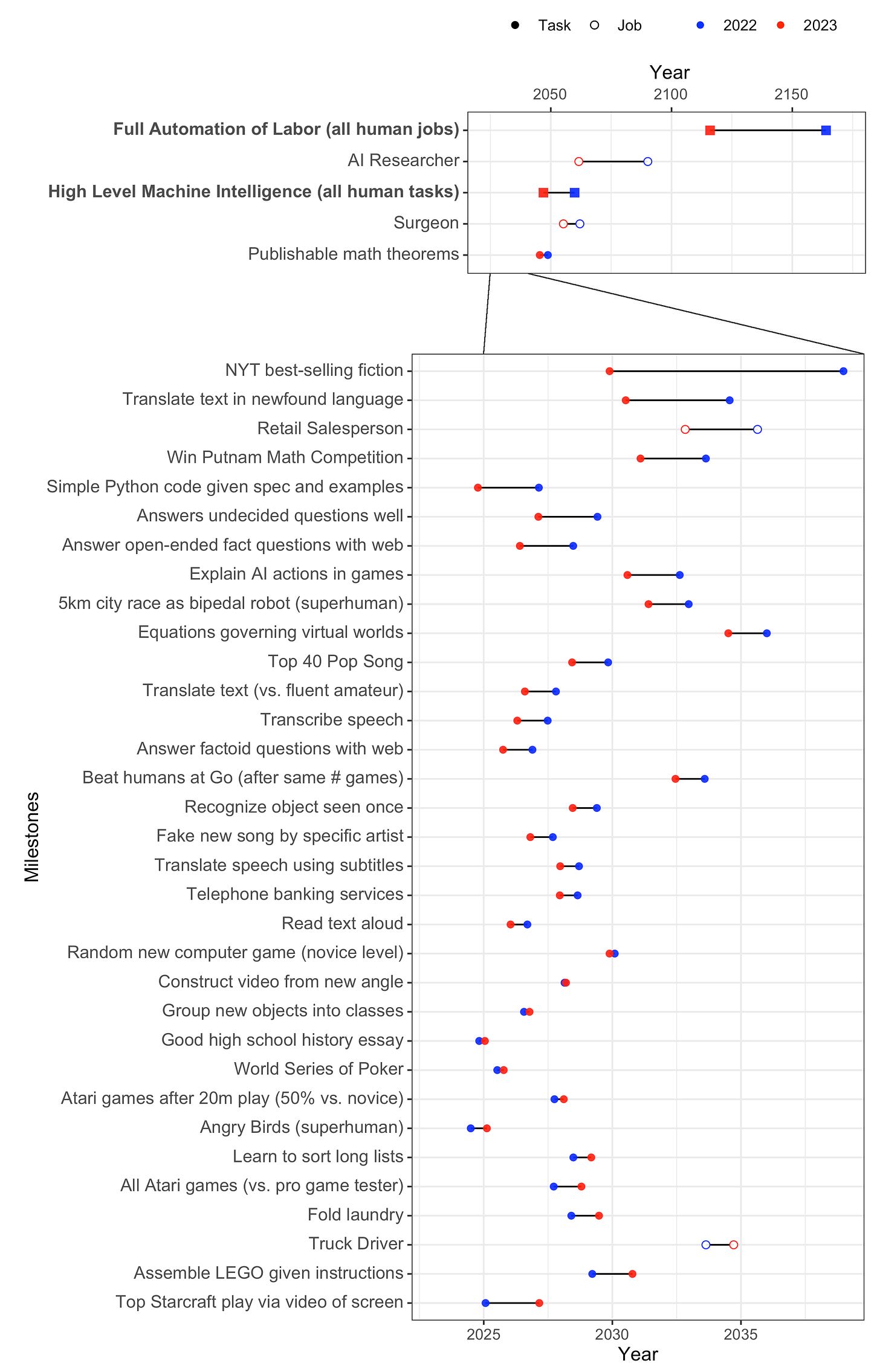
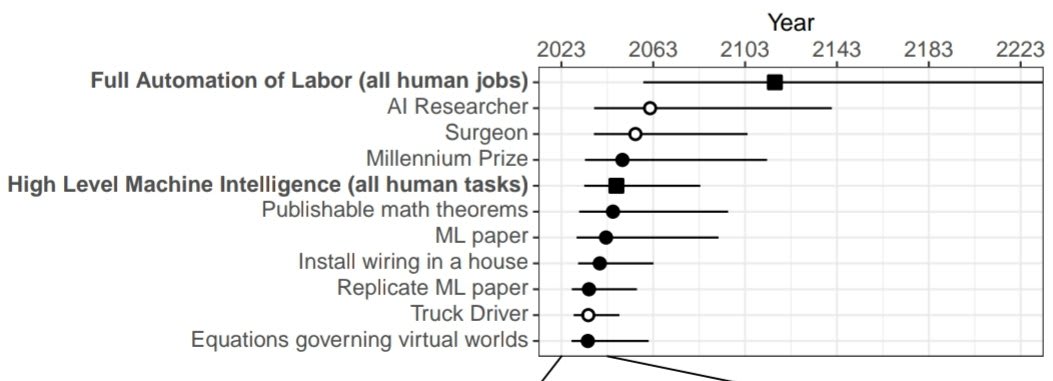
2. Time to most narrow milestones decreased, some by a lot. AI researchers are expected to be professionally fully automatable a quarter of a century earlier than in 2022, and NYT bestselling fiction dropped by more than half to ~2030. Within five years, AI systems are forecast to be feasible that can fully make a payment processing site from scratch, or entirely generate a new song that sounds like it’s by e.g. Taylor Swift, or autonomously download and fine-tune a large language model.
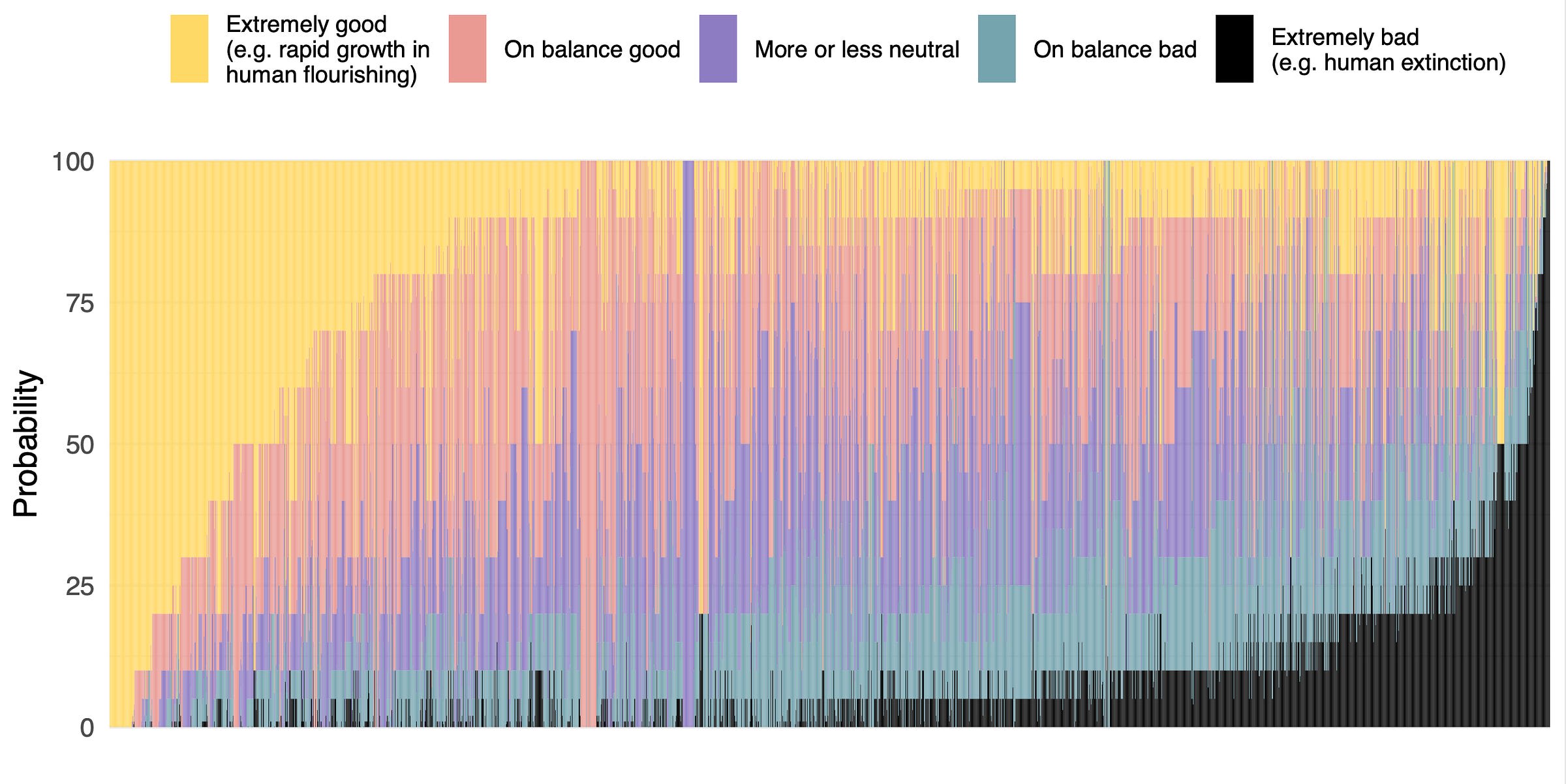
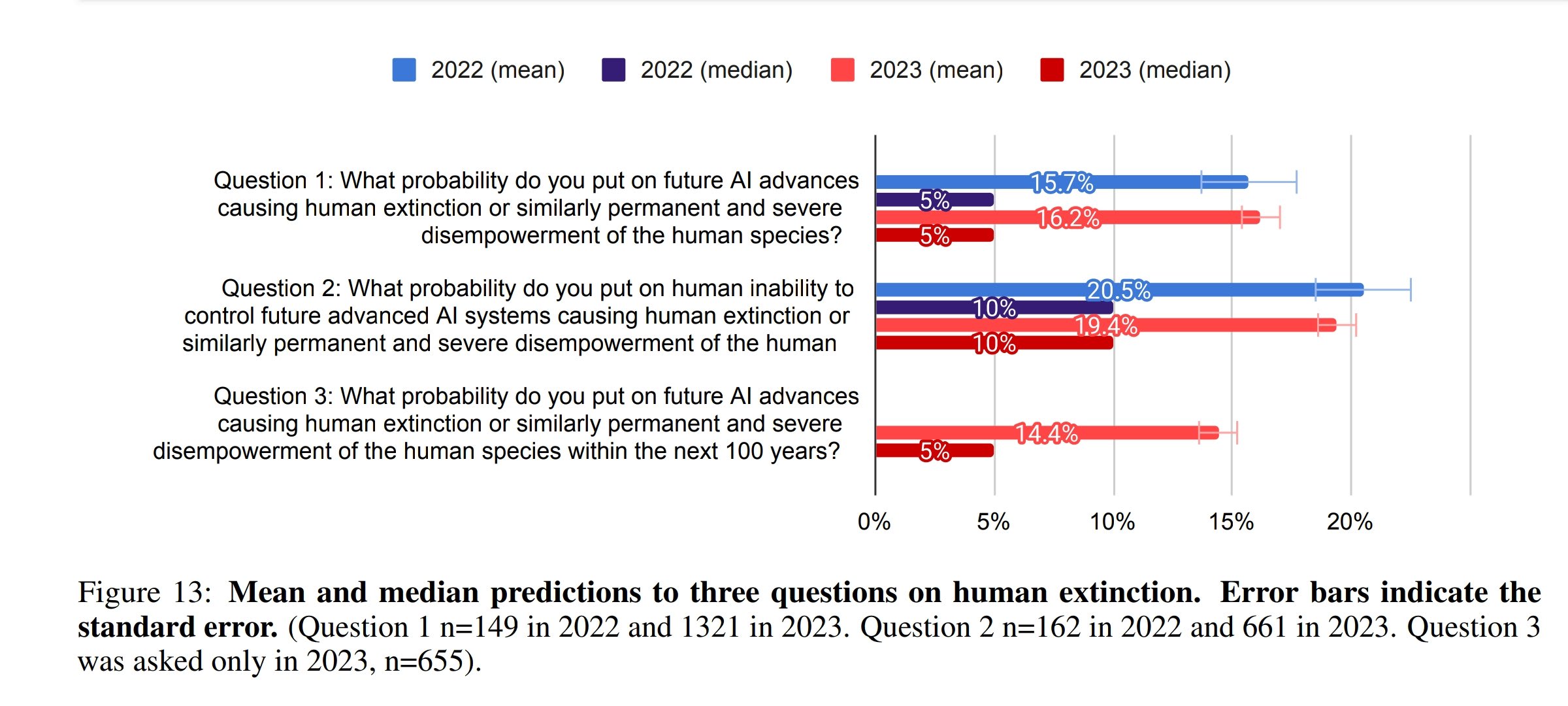
3. Median respondents put 5% or more on advanced AI leading to human extinction or similar, and a third to a half of participants gave 10% or more. This was across four questions, one about overall value of the future and three more directly about extinction.

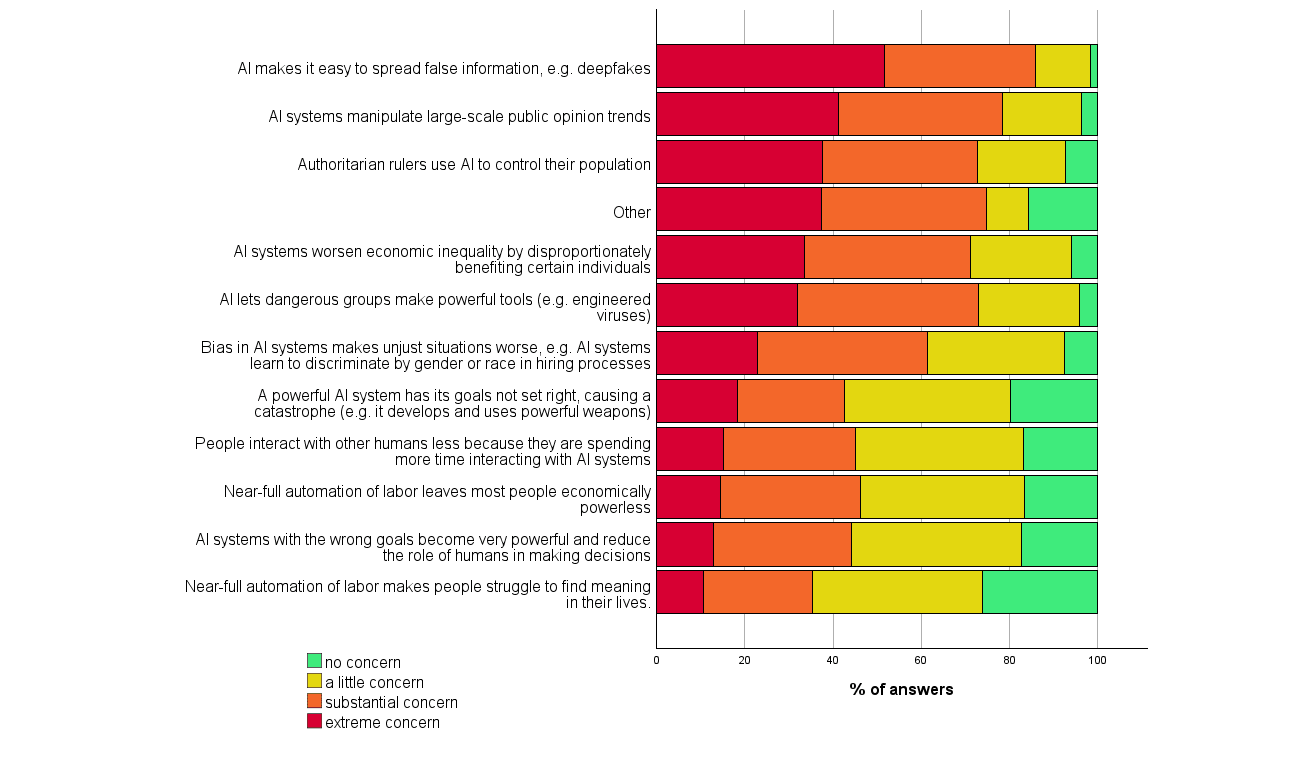
4. Many participants found many scenarios worthy of substantial concern over the next 30 years. For every one of eleven scenarios and ‘other’ that we asked about, at least a third of participants considered it deserving of substantial or extreme concern.
5. There are few confident optimists or pessimists about advanced AI: high hopes and dire concerns are usually found together. 68% of participants who thought HLMI was more likely to lead to good outcomes than bad, but nearly half of these people put at least 5% on extremely bad outcomes such as human extinction, and 59% of net pessimists gave 5% or more to extremely good outcomes.
6. 70% of participants would like to see research aimed at minimizing risks of AI systems be prioritized more highly. This is much like 2022, and in both years a third of participants asked for “much more”—more than doubling since 2016.

If you enjoyed this, the paper covers many other questions, as well as more details on the above. What makes AI progress go? Has it sped up? Would it be better if it were slower or faster? What will AI systems be like in 2043? Will we be able to know the reasons for its choices before then? Do people from academia and industry have different views? Are concerns about AI due to misunderstandings of AI research? Do people who completed undergraduate study in Asia put higher chances on extinction from AI than those who studied in America? Is the ‘alignment problem’ worth working on?



Link-commenting my Twitter thread of immediate reaction and summary of paper. Some light editing for readability. Would be interested on feedback if this slightly odd for a forum comment content is helpful or interesting to people.
Overall take: this is a well done survey, but all surveys of this sort have big caveats. I think this survey is as good as it is reasonable to expect a survey of AI researchers to be. But, there is still likely bias due to who chooses to respond, and it's unclear how much we should be deferring to this group. It would be good to see an attempt to correct for response bias (eg weighting). Appendix D implies it would likely only have small effects though, except widening the distributions because women were more uncertain and less likely to respond.
Timelines
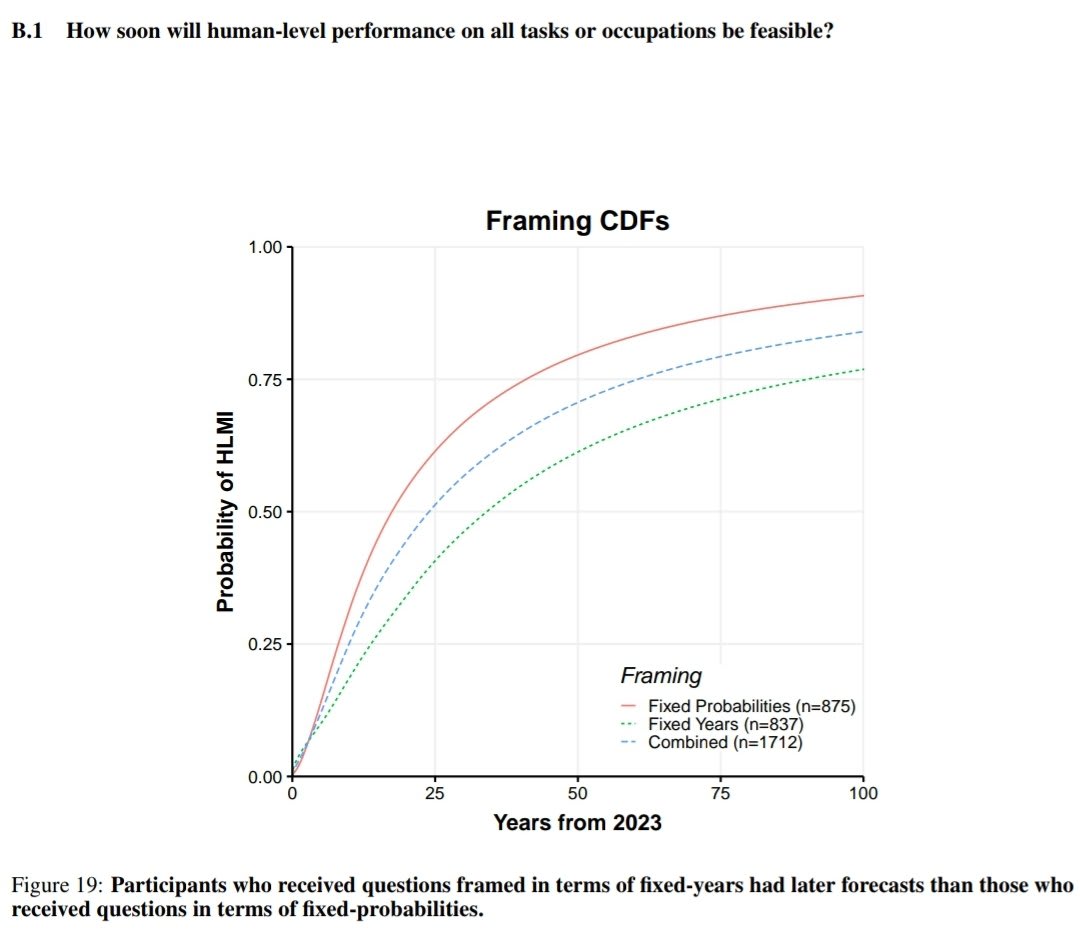
Wording of questions matters a lot when asking about time for AI to be able to do all tasks/jobs. 60 year difference in median due to a small change, which researchers can't explain. Will allow cherry picking to support different arguments. In particular, Timeline predictions are extremely non-robust. HLMI = High-Level Machine Intelligence. FAOL = Full Automation of Labor. 60 year apart in time to occurence.
Other bits of question wording matter, not anywhere near as much (see below). Annoyingly, there's no CIs for the median times so it's hard to assess how much is noise. I guess not much due to the sample size.
This might be just uncertainty though. Any single year is a bad summary when uncertainty is this high. The ranges below are where the distribution aggregated across researchers place 50% of the mass.
I find it very amusing that AI researchers think the hardest task to get AI to do (of all the ones they asked about) is... Being an AI researcher. Glad they're confident in their own job security.
Note that time to being "feasible" is defined quite loosely. It would still cost millions of dollars (if not more) to implement and only be available to top labs. Annoyingly, it means that the predictions can only be falsified as too long, not too short.
The aggregation is making a strong assumption about the shape of respondents' distribution. I'm suspicious of any extrapolation or interpolation based on it. A sensitivity analysis would be nice here. Also, why not a three-parmeter distribution so it can be fit exactly?
Time to ~AGI in 2016 and 2022 surveys very similar, but big change in median times for 2023. Remember previous caveat about no CIs and wide distributions though.
Some recommendations on quoting timelines from this survey.
Outcomes of AGI
I don't have much to say on the probabilities of different oucomes. I note they're aggregating with means/medians. These reduce the weight on very low end or very high probabilities a lot (relative to geometric mean of odds, which I think is better). So these are probably closer to 50% than they should be.
Headline result below! Probability of very bad outcomes, conditional on high-level machine intelligence existing. Median respondent unchanged at 5-10%. I'd guess heavily affected by rounding and putting 5% for "small chance, don't know". An upper bound on the truth for AI researchers' median IMO.
There's lots of demographic breakdowns, mostly uninteresting IMO. They didn't ask or otherwise assess how much work respondents had done on AI safety. Would have been interesting to see the split and also to assess response bias.
Thanks for citing the survey here, and thank you Joshua for your analysis.
Your post doesn´t seem strange to me at this place; at the very least I can´t find any harm in posting it here. (If someone is more interested in other discussions, they may read the first two lines and then skip it.) The only question would be if this is worth YOUR time, and I am confident you are able to judge this (and you apparently did and found it worth your time).
Since you already delved that deep into the material and since I don´t see myself doing the same, here a question t... (read more)