Summary / TL;DR
- The Problem: Highly capable, first-time applicants—especially those from Low- and Middle-Income Countries (LMICs)—struggle to navigate the rigorous EA grant evaluation frameworks (BOTECs, theories of change). Meanwhile, grantmakers spend a reasonable amount of time filtering out structurally weak proposals.
- The Solution: I built Graev, an AI-assisted evaluation tool designed to provide quick, structured feedback on draft proposals before they are officially submitted.
- The Ask: The app is in live beta. I am seeking community feedback to stress-test the evaluation logic. (You can also support the scaling of the tool on my Manifund page).
The Background: Why I Built Graev
The EA ecosystem relies on rigorous metrics: a theory of change explicitly articulates the cause-and-effect steps for how a project turns inputs into a desired impact, and back-of-the-envelope calculations (BOTECs) are used as rough quantitative models to estimate a grant's social return on investment. While these tools are essential for maximizing impact, they are incredibly challenging for a first-time applicant to navigate.
Many highly capable applicants struggle to structure strong, EA-aligned grant proposals. They might be doing vital work on the ground, but they often lack fluency in EA's specific epistemic language to successfully secure funding. I recently announced an early version of a tool designed to fix this on EA social channels, and seeing over 100 users try it within the first 5 days confirmed that there is a massive appetite for this kind of support.
The Evaluator’s Bottleneck: A Tale of Three Funds
On the flip side, evaluators spend immense amounts of time providing basic structural feedback to applicants. This wasted time creates a severe bottleneck. If we look at the last 1,000 applications across three major EA funds (Animal Welfare Fund, Effective Altruism Infrastructure Fund, and Long-Term Future Funds), we can see exactly where the friction lies.
1. The "Initial Triage" Crisis (Animal Welfare & EA Infrastructure)
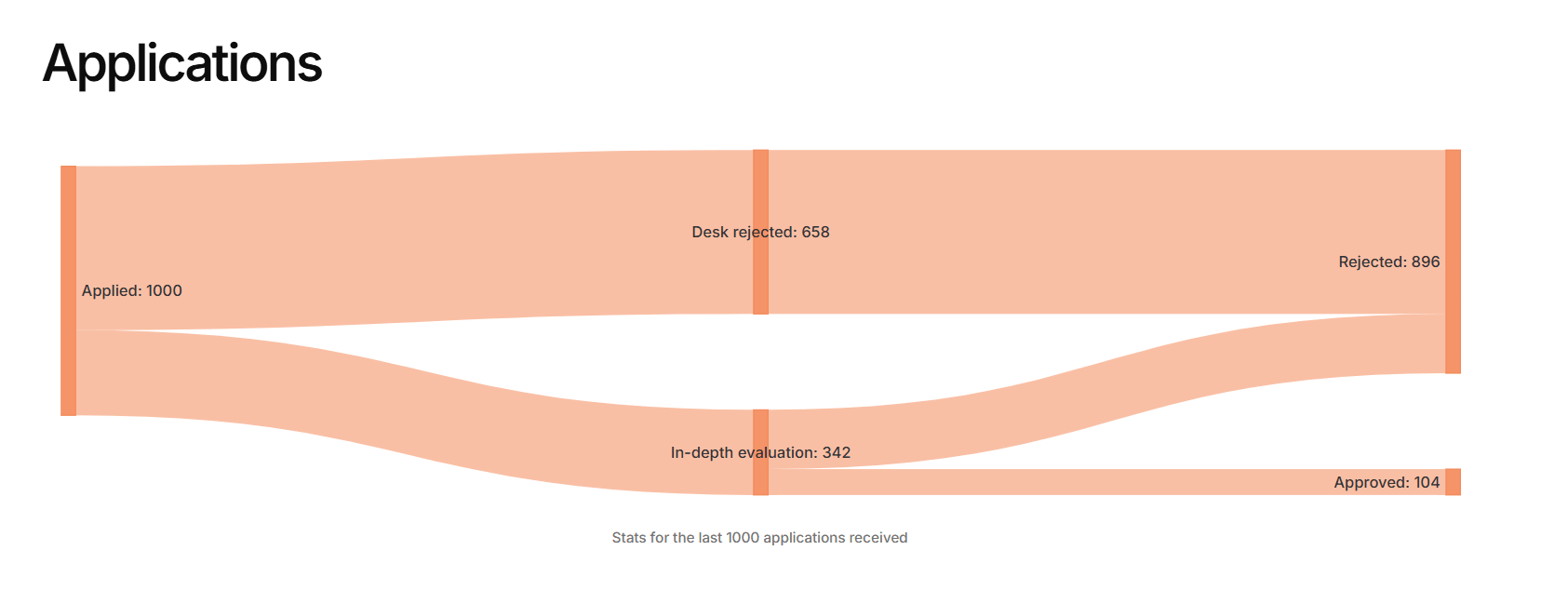
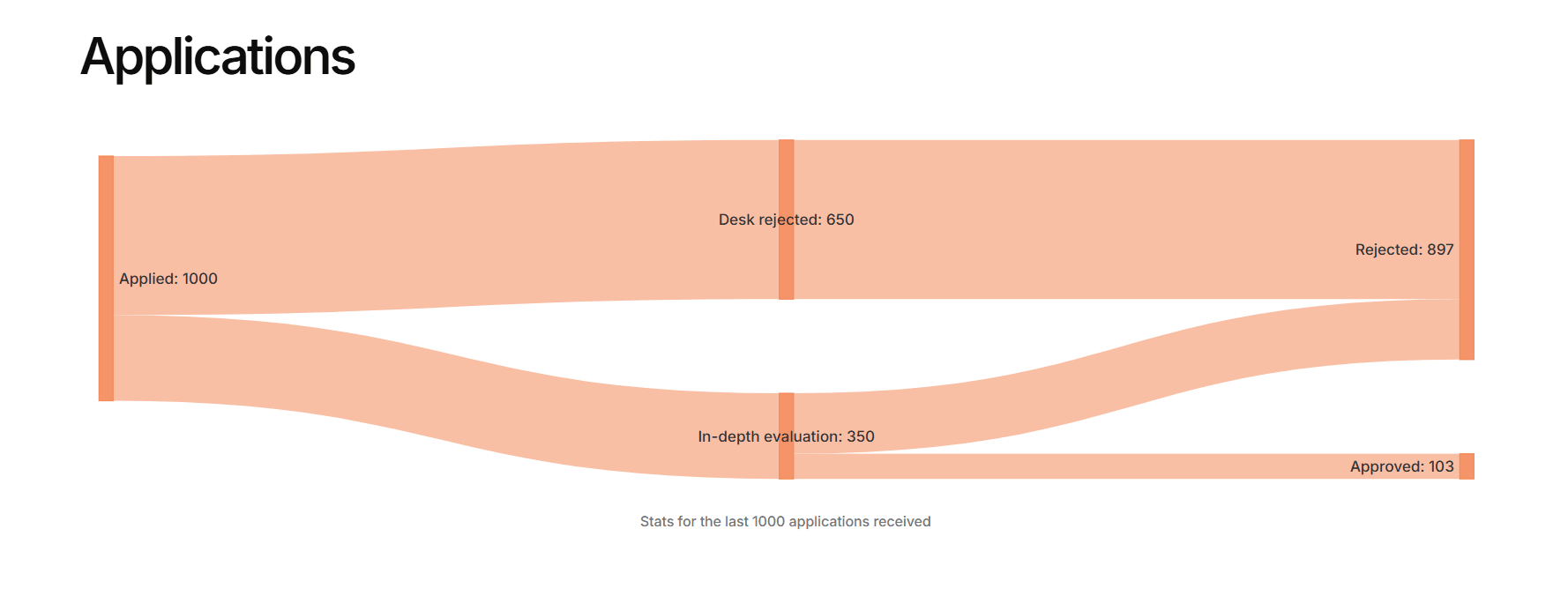
For the Animal Welfare and EA Infrastructure Funds, the biggest hurdle is the initial desk screening. Animal Welfare desk-rejects 65.8% of all applications, and EAIF desk-rejects 65.0%. This means human reviewers are spending a massive amount of cognitive bandwidth just reading through hundreds of proposals only to eliminate them immediately.
2. The "Deep Evaluation" Crisis (Long-Term Future Fund)
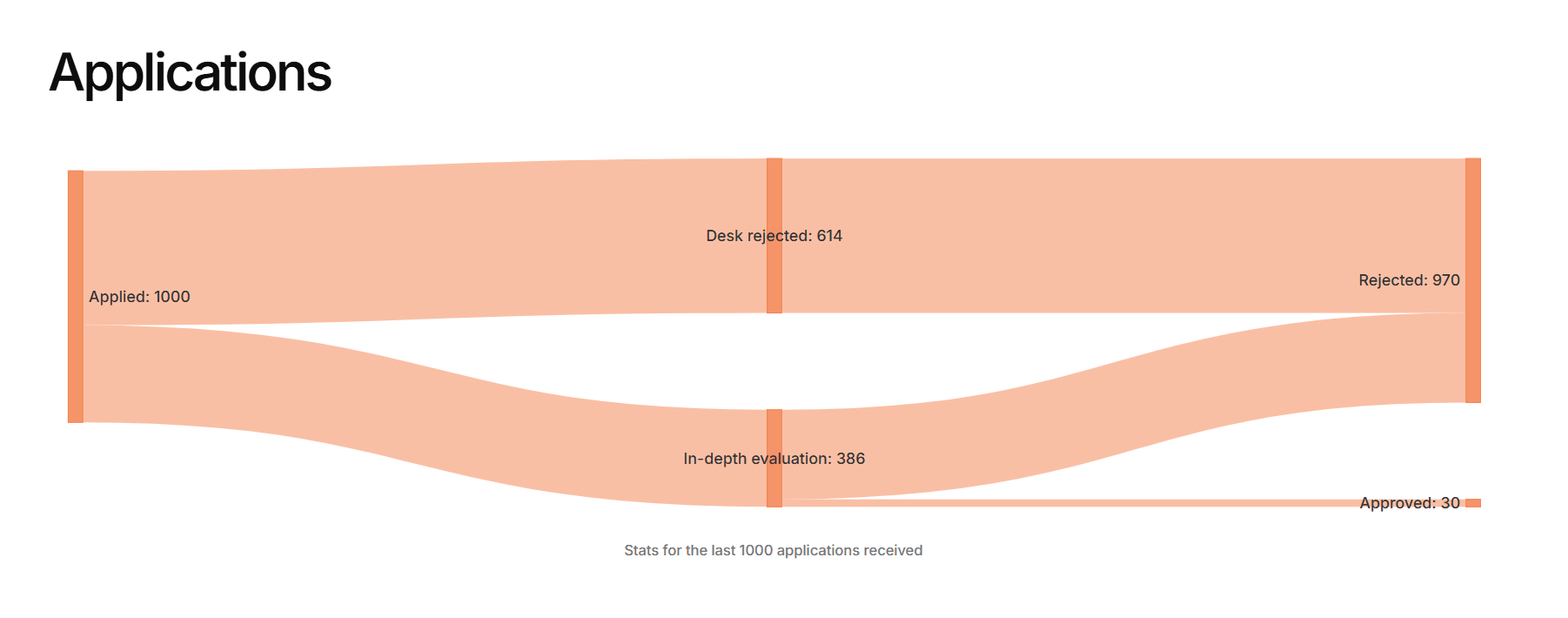
The Long-Term Future Fund (LTFF), which focuses heavily on global catastrophic risks, faces the opposite problem. They have the lowest desk rejection rate (61.1%), pushing a massive 389 proposals into the deep-evaluation phase. However, their final acceptance rate is a tiny 3.0% (only 30 approved). This indicates that LTFF proposals are too complex to reject at a glance and require deep, time-consuming epistemic debate before a final "no" can be given. I can only imagine how much work it must have been for grant evaluators to screen through all 1,000 of those applications just to accept a small fraction.
The Solution: Graev
I built Graev to bridge this gap by solving both the triage and the deep evaluation crises.
Graev is an AI-assisted evaluation tool that acts as a pre-submission mentor. I believe Graev can help highly impactful proposals—especially those from first-time and LMIC applicants—pass the initial desk screening by ensuring their theory of change is legible and their metrics are sound.
For evaluators, it means the proposals that survive the desk-reject phase and enter deep evaluation are of much higher structural quality. Furthermore, Graev includes specific tools like a "Red Team Attack" and a "Budget Reality Check" to help stress-test the complex logic of LTFF or EAIF proposals, ultimately increasing the chances of grants passing the deep evaluations stage and saving grantmakers countless hours.
Try It Out & Help Me Improve It
I strongly urge you to give the tool a try with a past or current proposal. I would love it if the community used it and stress-tested its logic. There is a feedback form directly on the tool’s page—please use it to suggest improvements or point out blind spots in how the AI evaluates different cause areas.
I am actively working on improving the tool, refining the backend rubrics, and scaling the infrastructure so it can handle more complex evaluations without hitting rate limits. If you are interested in supporting this development, you can check out the project and my roadmap on the Manifund page.
Links:
- Try the tool: https://graev.netlify.app/
- Support the project: Manifund Page