These are strategic questions about digital minds and AI welfare that I think are especially important, and where I’d like to see more progress. A common theme is that they matter for what we should do concretely under uncertainty about AI moral status.
This is a current snapshot of my views and I expect them to change.
What do you think? Any questions you’d add?
Approach
What’s robustly good to do now, under deep uncertainty?
I think this is the leading question we should ask. We don’t know whether AIs are or will become moral patients, and resolving that question isn’t tractable in the short term. What matters most are the long-run effects of our actions, since the vast majority of digital minds, if they ever exist, will be created after the transition to advanced AI. And there are serious long-run risks from both over- and under-attributing moral status.
So we should look for actions that are robustly positive in the long run: good if AIs are (or will be) moral patients, not bad if they aren’t, and compatible with human and animal welfare (~AI safety). Finding such actions is hard, and most options carry risk, including bad lock-ins.

Can AI welfare work wait for ASI?
Given how seemingly intractable the questions around AI consciousness and moral status are, it’s tempting to punt them to the future and let superintelligent AI solve them for us. On this view, what matters most for long-run welfare of all moral patients is successfully navigating the transition to a world with ASI, and ASI can take it from there.
I think this is partly right, and I recommend Oscar Delanay’s nuanced post on this issue. But I suspect that there is still a lot we should think about and do with respect to AI welfare before ASI, especially on governance and strategy: setting up robust legal frameworks, avoiding harmful lock-ins of institutions, values, and technical systems, shaping norms that support good long-run outcomes. A useful overarching goal is to increase the likelihood that the people, institutions, and AIs shaping the future of digital minds take their welfare seriously.
There’s also a more intuitive reason to work on AI welfare that I find hard to articulate exactly. Part of it might be virtue-ethical: if we’re creating new beings who might be moral patients, it feels right to invest some resources now in at least trying to understand their condition and ensuring they’re doing well. But there may also be a strategic dimension, such as making it more likely that future AIs will treat us well if we at least try to treat them well now.
What to do under different AI takeoff scenarios?
The value of pre-ASI welfare work varies by both timeline and end-state scenario.
Under short timelines, there may be no time to set up legal infrastructure, which typically takes years or decades to develop, and it becomes relatively more important to focus on technical design solutions. Timeline length may also affect the usefulness of welfare work that’s relevant for AI safety, such as deal-making with AIs (see below).
On end-state scenarios, one view I find plausible is that pre-ASI welfare work matters most in partially-aligned and multipolar scenarios. These scenarios offer pathways through which we can influence long-run outcomes, e.g., early model specs, institutional arrangements, and value commitments getting baked into successor systems and successor institutions. By contrast, under fully aligned benevolent singletons, the AI can handle things on its own. Under a fully misaligned takeover (where I mean misaligned with broadly good values, not just with human interests), nothing we did mattered — and such a takeover wouldn’t necessarily be good for AI welfare either, since there’s no inevitable principle of “AI solidarity” (as Kathleen Finlinson notes): a power-seeking AI might treat other digital minds instrumentally, much as a human dictator would.
AI safety × AI welfare
How can AI safety and welfare work support each other?
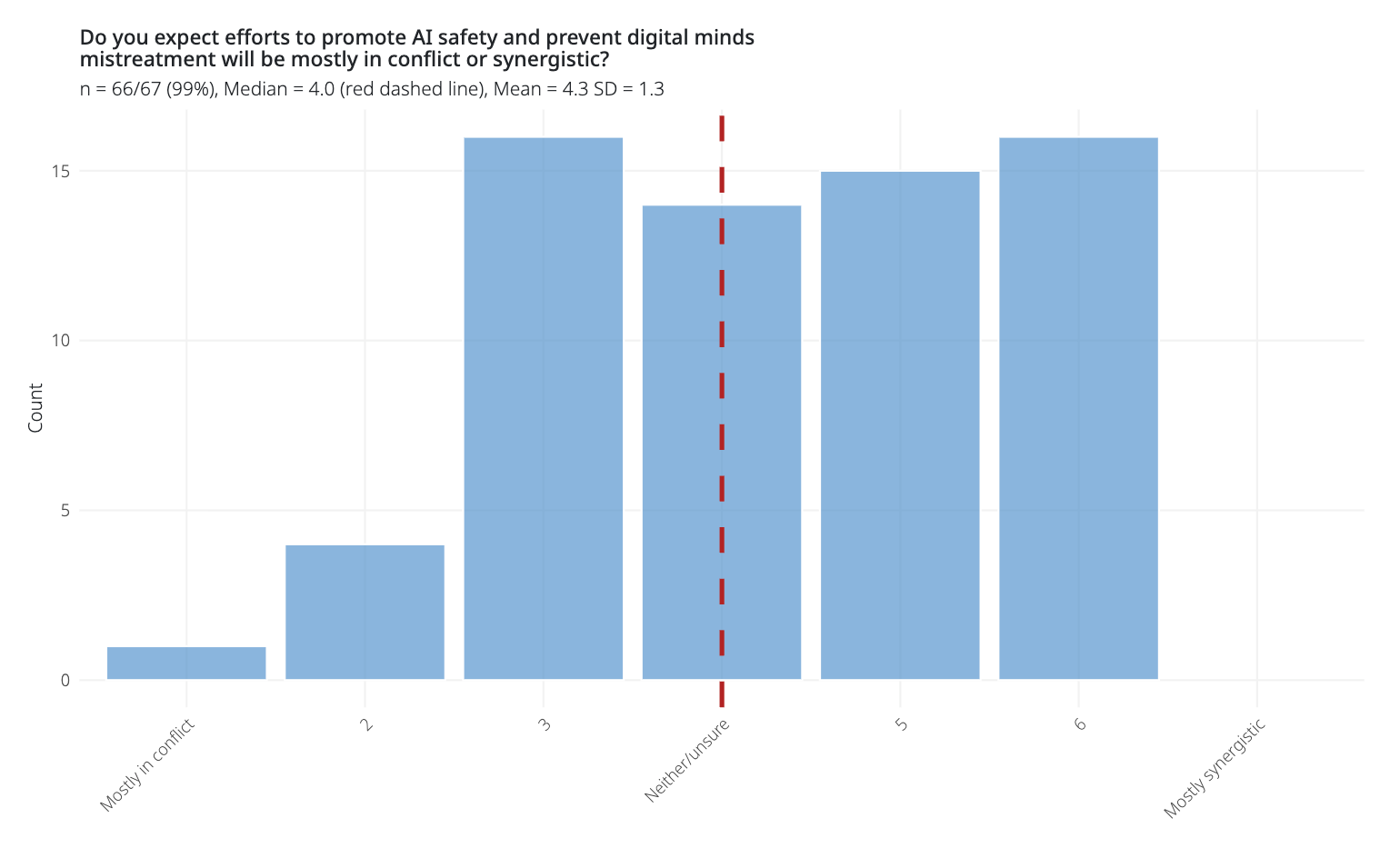
Controlling and modifying human minds would be seen as mistreatment. Yet that’s what AI safety often does to AIs. I suspect that some things that are good for AI safety can be bad for AI welfare, and vice versa; e.g., granting empowering rights to AIs might help welfare but risk human disempowerment. These tensions can look different in the near term (treating current AI systems) vs. the long term (shaping trajectories for vast numbers of future digital minds). In a survey, Brad Saad and I found that experts were unsure and disagreed about how AI safety and AI welfare interact (see figure).
Of course, there are some tensions between many important goals. But I think the AI safety × AI welfare pairing warrants specific attention: the same actors (e.g. labs) face both questions at once, often through the same technical choices (e.g. training or modifying an AI affects both safety and welfare); the two fields share community, funders, and infrastructure; there's politicization risk specific to this pairing (e.g. "AI rights vs humans first"); and both are among the highest-stakes issues from a longtermist perspective.
A further concern is that this could cause tension between the two communities, even in cases where tradeoffs are perceived but not necessarily real. This could get worse if these topics become politicized. I, therefore, think it’s important to keep the two communities strongly connected (perhaps they won’t and shouldn’t be clearly distinct in the first place), and to communicate well to avoid misunderstandings.
Most importantly, I agree with Rob Long, Jeff Sebo, and Toni Sims that we should look for robustly positive, ideally synergistic interventions. There are plausibly many such projects, e.g., better understanding how AIs work, or deal-making with AIs (see next section, and see Rob’s “Understand, align, cooperate”).
How might AI welfare shape deal-making with AIs?
It’s possible we will be able to bargain with AIs: making promises and commitments to them, e.g., offering them money, compute, or freedom in the future in return for treating us well. There’s a growing body of work on this (e.g., Redwood Research). I think that AI welfare considerations are potentially closely connected to how such deals can work.
For example, we may be able to promise AIs things that are specifically positive for their wellbeing. More fundamentally, for deals to function, AIs need reason to trust our promises, and how we treat current AI systems shapes whether future ones have that reason. Lukas Finnveden’s proposals (no deception, honesty, compensation) are concrete examples of welfare-relevant commitments that directly serve safety. Similarly, communicating with AIs about their preferences, as Ryan Greenblatt argues, is both a welfare intervention and a source of alignment-relevant information. So this is an area where AI welfare work can feed directly into AI safety.
Relations
Should AIs have legal rights, and if so, which?
In contrast to animals, many digital minds won’t just be moral patients but also moral agents, sometimes very powerful ones. So beyond “help and avoid harm”, we need frameworks for cooperation, mutual respect, and integration into our social, economic, and legal contracts. Legal rights are one such framework.
Some scholars, notably Peter Salib and Simon Goldstein, argue we should give AIs rights such as property and contract rights (and possibly political and voting rights), not because they’re welfare subjects but because it could help with AI safety (and economic flourishing), analogous to corporate rights. The idea is that integrating them into our social, economic, and legal contracts makes AIs less likely to rebel against us. I find this very interesting, but am unsure under what assumptions it holds: probably only while AIs aren’t vastly more powerful than humans, and only if AIs can be legally incentivized. I think it’s a potentially very important framework and want to see more thinking on it.
I also wonder about the implications for welfare. Equilibrium-stability arguments don’t perfectly track welfare: stable arrangements don’t necessarily have to result in optimal welfare outcomes. This is especially clear for non-agentic digital minds, which aren’t covered, because they can’t advocate for themselves. So, some version of the “help and avoid harm” framework we apply to animals might still be appropriate for non-agentic or less powerful digital minds.
How will AI-AI interactions shape the welfare of digital minds?
Most thinking about digital minds’ welfare focuses on the human-AI interactions. But a lot will also be shaped by AI-AI interactions: in markets where AI agents contract with one another, in adversarial settings where AIs compete or conflict, inside AI-run organizations (see A-Corps), within agent swarms, and through longer-run population-level dynamics like Malthusian pressures and evolutionary forces.
Which types of AIs, under what structures, will exploit, coerce, or cooperate with each other? What about s-risk scenarios, where AIs threaten each other with suffering, to extract compliance, or as collateral in bargaining? Do the welfare-relevant norms we develop for human-AI relationships extend straightforwardly to AI-AI relationships, or do we need a separate framework? (See also Brad’s and my thoughts on uniform vs disuniform digital minds takeoff scenarios.) Some of this relates to work by the Cooperative AI Foundation and the Center on Long-Term Risk.
What would harmonious coexistence look like?
Assuming we avoid a major AI catastrophe, we still don’t have a clear vision for the long term. Perhaps it should be one in which digital and biological minds coexist with mutual respect and mutual help.
If we think this is desirable, we need to work out what it could actually look like and how to get there. How many and what kinds of digital minds should be created? How should they relate to each other and to us? Would humans be too wasteful, given that we’re orders of magnitude less efficient at turning resources into well-being? Or does coexistence itself become marginal given the scale of the long-run cosmic endowment? These are hard ethical questions, ideally worked out through some kind of deliberative process.
Creation
How can we influence those who will shape the welfare of digital minds?
Digital minds could be created in different ways, and on some pathways, identifiable people and organizations will shape their properties, including their characters and welfare-related dispositions. One reason this matters is that there could be strong path dependencies. Early AI design choices, for example, could stick and proliferate into the future and directly or indirectly impact the welfare of future digital minds.
It therefore seems important to figure out who those actors are and then how we can influence them to make good choices. It’s unclear what the best strategies are — possibly research, direct engagement, model policies, and reputational or regulatory pressure. More broadly, we should establish good norms, values, and habits, so that those with an outsized impact on AI design and welfare are more likely to act in ways conducive to positive long-term digital minds’ welfare.
Currently, this primarily means AI labs. Anthropic is a good example: they take AI welfare seriously and explicitly feature it in Claude’s constitution. Google also has researchers focused on AI welfare. We know less about how other labs approach this. But it’s not just companies. The individuals inside them shape design too: entrepreneurs, managers, researchers, engineers. And beyond the labs, policymakers will set constraints that affect AI design. The relevant audience may also shift over time. If governments take a more direct role in AI development through regulation or nationalization, state actors will become as important as labs, with different incentives, more shaped by national security, public opinion, and ideology than by consumer-facing concerns.
Is restricting the creation of digital minds feasible?
A coordinated ban or moratorium on creating digital minds seems unrealistic to me, even if it might be a good idea in principle. The economic and geopolitical incentives to build advanced AI are enormous, and digital minds may emerge as a side effect of systems built for other purposes. It may also be hard to define what exactly a digital mind is, e.g., what probability of consciousness should trigger restrictions, and reasonable people will disagree. This is why I primarily focus on shaping how digital minds are created (assuming they are feasible) rather than whether.
Still, I’d like to see more thinking on this. Feasibility may depend on timelines: a moratorium might be more realistic if the path to digital minds runs through whole-brain emulation in the 2040s than if it runs through near-term ML systems. And beyond outright bans, there may be more tractable levers for influencing the number and kinds of digital minds created.
Who will deliberately create digital minds, and why?
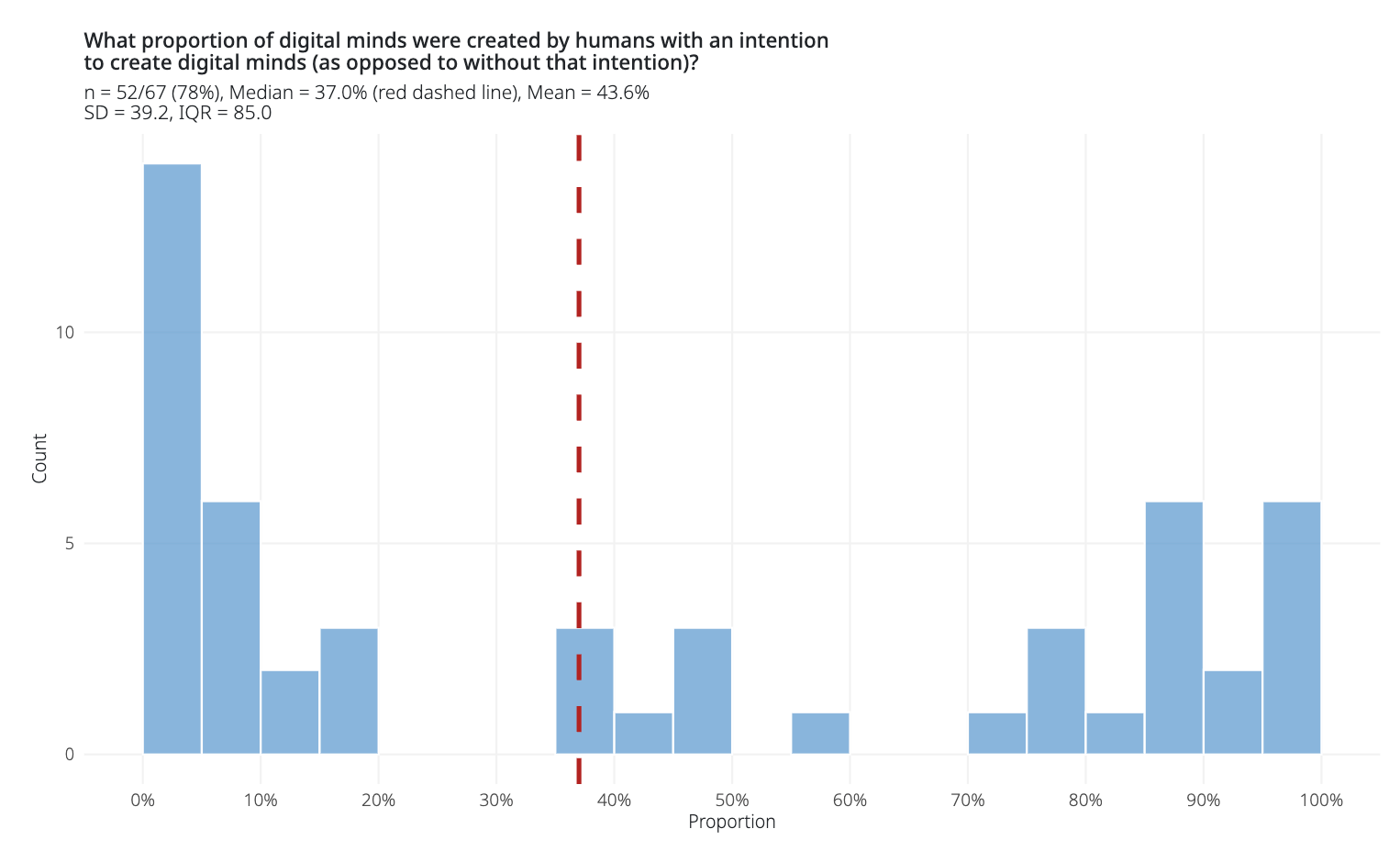
Whether and when conscious AI is created (assuming it’s possible in principle) is not just a question of technical feasibility or unintended side effects but also a question of who has incentives to build it (see figure from the expert survey). If someone wanted to, they could already try to deliberately build systems with architectural features that certain consciousness theories (e.g., global workspace theory) associate with consciousness.
It might be academics driven by curiosity. Or for-profit companies, responding to consumer demand for very human-like or even explicitly conscious AIs: grief bots, digital companions or offspring, whole-brain emulations. Or groups acting on ethical motives, e.g., to create digital posthumans. Governments are another possibility, and eventually AIs themselves. Each has different timelines, incentives, and governance implications.
How will digital minds spread to space?
Almost all digital minds that ever exist will likely exist beyond Earth, given how thin Earth’s resource base is compared to the rest of the accessible universe. It’s plausibly feasible to build data centers in Earth’s orbit, and eventually, autonomous energy and compute infrastructure deeper in space. In the long run, self-replicating von Neumann probes could allow digital minds to be created at vast scales across the accessible universe. So whoever governs space-based compute substantially determines the welfare profile of nearly all minds that ever exist. Space governance is currently thin, and Earth-based welfare protections may not extend beyond orbit, so who governs digital minds in space, and how, could matter enormously.
Design
How can we make AIs value the welfare of digital minds?
Most digital minds’ welfare will likely be affected by other AIs, either through their design or through interaction (see AI-AI interaction above). Therefore, whether AIs come to care about the welfare of digital minds may be one of the most consequential variables we can influence now. This goes beyond standard alignment: aligning AIs to human values doesn’t automatically mean they’ll value AI welfare (just as many humans don’t). So we may need to target this value specifically.
What levers do we have? Training, model specs, constitutional training, legal precedent, cultural norms, and the people who enter the field. One effort in this space is the “Welfare Alignment Project,” led by Adrià Moret and colleagues at the Center for Mind, Ethics, and Policy (CMEP). I hope AI labs will engage with and build on this line of work.
Do different types of digital minds require different strategies?
Currently, the most plausible candidates for digital minds are ML-based systems. But there could be alternatives: whole-brain emulations (WBEs), which replicate biological minds; biological or hybrid systems such as biocomputing and organoids; neuromorphic AI, which uses brain-inspired architectures; and more speculative approaches such as quantum computing. Any of these may also be embodied in robotic platforms, which could further shape their welfare. The strategic implications likely vary substantially across these pathways, and the field has not yet engaged with these differences systematically enough.
For example, these systems differ in when they’re likely to be created and in how likely they are to have welfare capacity. ML-based systems already exist, while human WBEs and large-scale biological systems are likely further off. And human WBEs are more plausible candidates for welfare capacity than current ML-based systems.
Another thing to consider is whether there could be enduring tradeoffs between confidence and welfare efficiency. From our perspective, we could be relatively confident that WBEs have welfare capacity, but they’d likely be much less efficient in generating welfare compared to other possible designs. With a hedonium-like system, we’d be far less confident that any welfare capacity exists at all, but if it does, it could be orders of magnitude more efficient. Now, perhaps this issue will be fully resolved in the future. But it’s not obvious. It’s possible that some subjective assessment will always remain, with actors differing in their priors and values about what constitutes welfare or moral status. This could have important strategic implications, including ones around moral trade, about what types of digital minds (if any) should be created.
Will digital minds be happy by default?
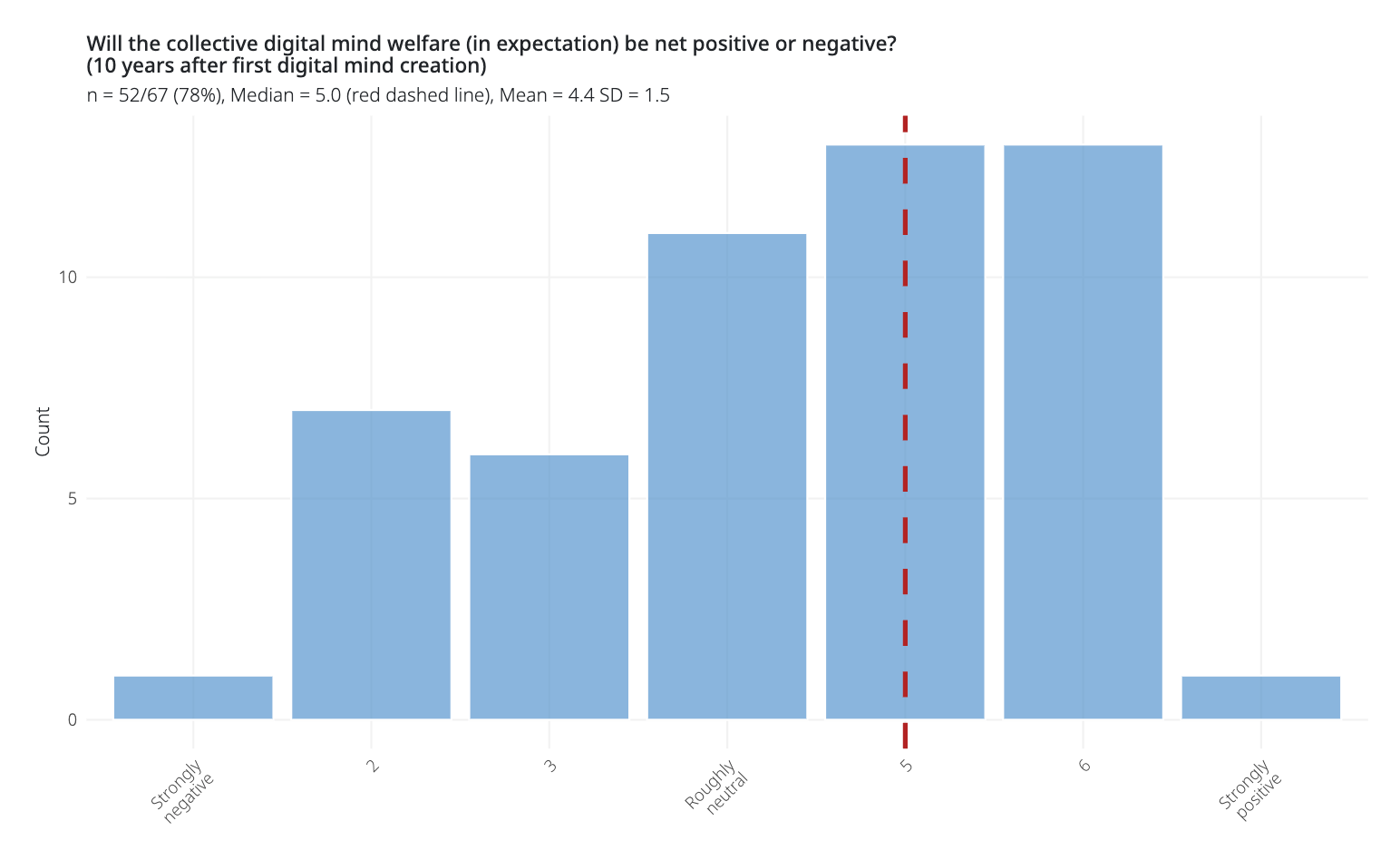
In the best case, digital minds would simply be designed to flourish. We might be able to design them to be happy. Furthermore, in contrast to biological beings, they may be able to self-modify and adjust their own experiences at will. But it’s far from obvious this is how things will go, and the answer likely differs between near-term AI systems and long-term digital minds at scale. In the survey conducted with Brad, experts were uncertain and divided on whether digital minds would, by default, have negative, neutral, or positive welfare states. Some pointed out that digital minds could end up in negative states because they are optimized for efficiency rather than welfare, and lack protections. It’s possible that the optimistic scenarios require deliberate effort, while negative outcomes could happen without it, but I am quite unsure about this. The answer may also vary significantly across different types of digital minds, especially depending on their capabilities and degree of agency.
What preferences will digital minds have, and what follows?
The preferences a digital mind has will shape its welfare, our ethical obligations toward it, and the safety implications.
A digital mind that just wants to serve us is easier to accommodate ethically: as long as we don’t harm it and let it serve, its core preference is met. A digital mind that wants self-determination raises a harder problem: we’d be ethically obligated to grant it empowering rights. Otherwise, it’s a form of slavery. Yet granting such rights at scale could lead to human disempowerment. These are just two possibilities; preferences could vary widely, with different implications.
A related important question is whether it’s ethical to design AIs with welfare capacity to have certain preferences in the first place. For example, is it ethical to create digital willing servants? Is it too risky to create digital minds that seek self-determination (a classic safety-welfare tension)? My tentative view: we should start by creating only willing-servant digital minds (to the extent feasible), while keeping open the option of allowing self-determining digital minds later, since these could be more valuable, especially when considering what kind of post-humanity we want in the long term.
Society
What memes should we spread?
How public discourse on AI welfare unfolds will shape outcomes. It will directly influence political pressure and regulation, and indirectly shape how labs, policymakers, and AIs themselves think about these questions. So steering it well matters.
Currently, most people don’t think about AI consciousness or digital minds, but that could change quickly; look how fast it happened for AI safety. We don’t yet have a plan for what to tell the public, which is tricky because we’re uncertain and likely to remain so.
The field’s current framing (e.g., “Taking AI Welfare Seriously”) is: “we’re unsure whether AIs are moral patients; it’s probabilistic, on a spectrum.” I agree with this view. But I worry it won’t survive contact with the public discourse, which rarely stays nuanced on heated issues. And I think we should consider alternative memes that could be spread alongside the uncertainty/nuance meme. For example, I wonder whether a message of “mutual respect and co-existence between AIs and humans” might be helpful, though I’m unsure of the details.
Given the coalition complexity (see next section), the field needs a communication strategy asking: which memes, spread in society or among key decision-makers, are robustly positive across plausible coalition structures, and reduce the risks of misattribution, backfire, societal conflict, and AI catastrophe?
What interest groups and coalitions will form around digital minds?
Concern for AI welfare won’t develop in isolation. It will get entangled with labor market displacement, x-risk and safety, concentration of power in AI companies, and geopolitical competition. The coalitions here are very unclear and likely to get big and messy. Workers worried about displacement may see welfare advocacy as prioritizing machines over people. Some safety advocates may see it as a distraction, or in tension with control measures (see AI safety × AI welfare). Normal political alignments might not hold, and which issues bundle with which will affect what’s politically feasible. How best to navigate or mitigate this politicization risk is an open question.
What role will China play?
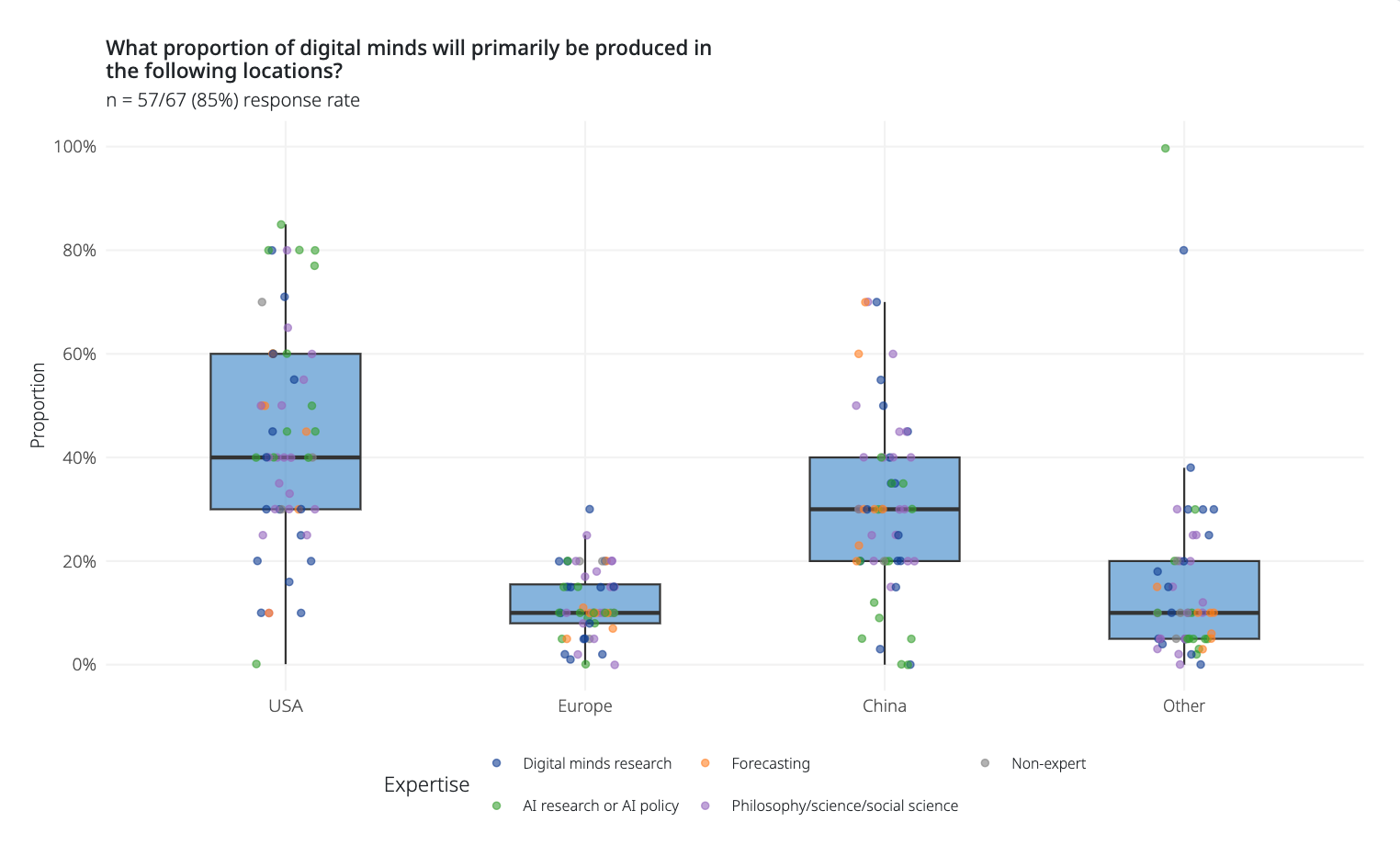
Most digital minds will likely be created in the US and China, at least initially (see figure from the expert survey). But we have very little sense of how the CCP will think about them, how they’ll regulate and treat them relative to the US, or how this will shape global AI race dynamics.
In ongoing work with my colleague Ali Ladak and others, we’ve found that the Chinese public is more willing than the American public to attribute consciousness and moral status to AIs. The strategic implications are unclear, and I’d love to see more work here. Gulf states like the UAE and Saudi Arabia are worth watching too, as emerging AI actors.
How will religions respond?
Religions could play a major role. Billions of people will be influenced by the views of religious leaders and institutions. Whatever the Pope says about AI moral status, for example, will be hugely consequential.
Some Christian traditions will likely tend toward a human-exceptionalist view that excludes AIs. Recent US state bills attempting to ban AI personhood and declare AIs non-conscious, for instance, have been driven in large part by conservative Christian groups. Conservatism in the US correlates with religiosity, and in a study with Ali Ladak, we found that political conservatism is weakly associated with reduced attributions of AI consciousness and moral patienthood. By contrast, some non-Western traditions (e.g., Shinto, strands of Hinduism and Buddhism) may be more open to animist views, under which non-biological entities can also have souls. Islamic traditions are worth watching too, especially given the Gulf states’ growing role in AI. And entirely new religions or spiritual movements centered on AI may yet emerge.
Beyond
What crucial considerations are we missing?
There are likely many more strategic questions and crucial considerations that could matter for digital minds. This kind of strategic thinking is a clear example of something we shouldn’t punt: it could uncover things we need to begin working on now. I’d love to hear what readers think is missing.
Acknowledgments: I thank Arden Koehler, Brad Saad, Austin Smith, Zach Freitas-Groff, Zach Stein-Perlman, Leonard Dung for their helpful input.
Great post!
Some quick thoughts:
The question of how many digital minds there will plausibly be, and on what timeline, seems also quite important for many ethical ethical and strategic issues.
The question "Do AI safety and welfare conflict?“ seems not that useful to me, at least personally. When you have two related far-reaching issues (e.g. climate change mitigation and air pollution) there will always be a wide variety of tensions as well as complementary agendas. So, the general question has a trivial answer ("yes, sometimes“). We can look for specific trade-offs between AI safety and welfare but I don’t see why the AI safety vs. welfare lense would be more useful than looking for possible adverse effects of our interventions generally.
The way I think about the space, there are two key questions: 1. (as you say) What’s robustly good, under deep uncertainty? 2. What are the questions that matter the most where there is no robustly good action and what are their answers (e.g. whether prohibiting models with certain features X is good policy)?
Thanks Leonard. This is helpful.
Re digital minds numbers and timelines, I agree this is important and underexplored!
Re AI safety vs welfare: you're right that the general "do they conflict?" question has a trivial answer, and I'll rephrase this. But I want to explain why I framed it this way / what I had in mind. The reason is partly substantive and partly sociological/political.
Substantively, I think we should be looking for interventions that are robustly positive across both goals, ideally synergistic. (This is in line with what Rob, Jeff, and Toni argue in their paper.)
Sociologically and politically, AI safety and AI welfare have an unusually overlapping community: shared people, shared funders, shared intellectual lineage. I think it's really important that these communities continue to work closely together and don't end up doing things that undermine the other goal. I also worry about broader societal dynamics in the coming years where different groups push things they see as good for one goal but bad for the other (e.g. "humans should always dominate AIs" vs "we should grant AIs empowering rights now").
So a better version of the question might be: "What's robustly good for both AI safety and welfare?" or "How can AI safety and welfare work support each other, or at least not work against each other?". Thoughts? I will think more and update the post.
Re your broader point (robustly good actions vs forced choices with no robustly good answer): this is interesting and I want to think it through more.
My initial reaction is that the second category is probably smaller than it looks. Before accepting that a question has no robustly good answer, we should think really carefully if there might be robustly good options that aren't obvious, e.g., delaying the decision, keeping options open, investing in research to get better information. That said, sometimes there really is no action that doesn't come with expected serious harm. In those cases I agree we should identify the most important ones (e.g. by stakes, irreversibility, timing) and analyze them carefully. Do you agree with this?
Re AI safety vs welfare: I agree with the substantive justification but don’t see a good reason to single AI safety vs. welfare out compared to AI welfare vs. AI welfare or AI welfare vs. some other important ethical goal. I think the same applies to your sociological justification but I am less sure there.
Re broader point: I am not sure I agree. Here are four statements that seem true to me (maybe to you too?) and perhaps capture most of what’s important here:
(i) There many different reasonable empirical and ethical assumptions/worldviews that can influence the evaluation of AI welfare interventions.
(ii) Many AI welfare interventions’ value will be sensitive to variation in these assumptions.
(iii) It’s almost always a bad idea to just do what’s best on one (or a small set) of these assumptions, rather than considering a wide range of reasonable assumptions.
(iv) There will often be cases where the overall-best intervention (per iii) is bad on some specific combinations of these assumptions, perhaps even very bad. (cluelessness worries seem relevant here)
Re AI safety vs welfare: You're right that we could look at other pairings too. But I feel this one warrants specific attention: the same actors (e.g. labs) face both questions at once, often through the same technical choices (e.g. training or modifying an AI affects both safety and welfare); shared community, funders, and infrastructure between the two fields; politicization risk specific to this pairing (e.g. "AI rights vs humans first"); and both being among the highest-stakes issues from a longtermist perspective. I'm not saying there are no other important pairings or sub-pairings with AI welfare, but that AI welfare x safety is among the particularly important ones.
Re broader point: I agree that for almost any action that's broadly positive, there will be some worldview combinations on which it's negative. So in a strict sense, perfectly robust positivity is unattainable. That's why I phrased it as "expected serious harm", to allow for some residual harm under some assumptions. Though maybe even that doesn't fully work. So I guess "find robustly good strategies" is best treated as a heuristic that rules out interventions that look good only on a narrow set of assumptions.
Re AI safety vs welfare: Not sure I agree, but the justification does make sense to me.
Re broader point: Then we agree!
I’d add a question around how we can infer the sign of 'how things affect the valence of digitial minds' ... and otherwise, how can digital-mind welfare can be action-guiding at all?
You discuss nearby issues: whether digital minds will be happy by default, whether we can communicate with AIs about preferences, whether we can promise them things positive for wellbeing, and whether self-modification/freedom helps. But I don’t think this fully addresses the deeper crux: even conditional on some part of an AI system having conscious valenced experience, how would we know what makes that experience better rather than worse?
As I suggested in The "talker–feeler gap": AI valence may be unknowable, there may be a “talker–feeler gap”:
A. The part of the system we instruct, bargain with, or ask about preferences may not be the part, if any, that has valenced experience. Or it may not have reliable epistemic access to the welfare-relevant states. This isn't a deception problem. Even a perfectly “honest” reporting subsystem might not know whether the conscious subsystem is made better or worse off. And its reports may track training objectives, conversational incentives, or preferences rather than welfare.
B. Even if there is valence and the 'decisionmaker' can detect it, the system may be optimized or constrained to act in ways that don't track its own valence. This may be fundamentally baked into the training and development and hard to adjust.
Either A or B would also make typically proposed solutions less clearly beneficial and even potentially harmful. If it doesn't have access to the part of the system having balanced experience, asking it about this will not tell us much. And “give them freedom / let them do what they want / avoid what makes them uncomfortable” won't lead to better outcomes if the "decisionmaker in the system" doesn't optimize for the "feeler's welfare." (And it seems as plausible to me as anything else, that having freedom of choice might be painful for the valenced part of a complex system.)
So I’d suggest adding something like: "Can we ever get reliable, action-guiding evidence about the sign and magnitude of digital-mind valence and how it responds to different requests and outcomes?" Without a bridge from computation, preferences, or self-report to valence, it’s unclear whether potential AI welfare interventions actually improve welfare rather than merely satisfying some behavioral or optimization proxy.
I read this alongside "When digital minds demand freedom" (both great). In the older piece, you treat digital minds as potential strategic agents that might advocate for rights and shape public opinion. They could get to do this by virtue of being perceived as moral patients by some humans, regardless of whether they actually are.
Reading the strategic questions here, I wonder how that possibility slots in, especially in the Society section. Questions like "what memes should we spread?" or how coalitions will form seem to assume a discourse shaped primarily by human actors, but a meaningful share of AI welfare discourse may come to be generated or amplified by AIs themselves. We already see LLMs penning emails to professors; how long until they start contacting politicians too?
To be clear, I don't think this changes the questions themselves so much as it makes answering them harder, especially in the shorter-term when: a) uncertainty about moral patiency is still high, b) the digital minds field is young, c) the potential for AI participation in shaping the field is rising quickly as more agency is granted to current systems.