Thanks for this in-depth writeup of what is clearly a very important factor in prioritising our work aimed at the AI transition. Your piece has built the argument for such prioritisation clearly enough that it has allowed me to put some previously inchoate responses into a more crisp form:
If we could tell with certainty which topics would receive >100x as much work as we could put in prior to when that work is needed, then I think your argument goes through. But I have a lot of uncertainty about that and such uncertainty weakens the prioritisation effect substantially.
To see the effect easily, suppose for simplicity that for some piece of apparently late-stage strategy there is a 50% chance that >100x as much work gets done on it, obviating the need for us to work on it now, and a 50% chance that there is no appreciable extra work done (e.g. because the intelligence explosion is happening in a particular lab that doesn't do this work, or because the work requires aspects of cognition that are improving more slowly, or because it turns out it was needed earlier in the explosion than expected).
In this case, the expected value of marginal work on that late-stage strategy gets roughly halved compared to if there weren't going to be this AI-driven work later (50% chance of the naive estimate + 50% chance of <1% of that estimate). Given the fairly extreme distribution in the value of a particular person working on different topics, it isn't that rare for the best thing of one category to work on being >2x as good as the best thing from another category, such that you shouldn't switch category even after downgrading the EV.
That would mean early-stage vs late-stage would be an important factor in choosing what to work on, but not any kind of filter as to what to work on. As the chance of large amounts of AI work on that topic increases, the factor gets stronger. e.g. it reaches 10x at a 90% chance, which is quite strong (though I think it is hard to reach or exceed a 90% chance here).
So I think this can have a substantial effect on the choice of what to work on on the margins, but isn't a filter.
What about its effect on the portfolio of research work aimed at the AI transition?
Suppose that there are logarithmic returns to the research work (which means that the marginal value of extra work is inversely proportional to aggregate work so far, which is a common neglectedness assumption). In that case, we should do 50% as much total work on equally-important things that we estimate to have a 50% chance of being obviated later, and 10% as much total work on those we estimate to have a 90% chance of being obviated later.
So that is still quite a lot of the share of our total work into late-stage things even when we don't think they are intrinsically more important. In the piece you suggested that we do at least some work on these topics, to avoid the possibility of being caught completely flat-footed if the anticipated AI-work on those topics doesn't happen, and I think the maths above suggests a larger amount of work than that (especially on topics that appear to be more important or more tractable).
(Note that my simplifying assumption of no appreciable AI help vs an overwhelming amount might be doing some work here. I'm not sure what the best way to relax it is.)
Thanks, I agree with your mathematics and think this framework is helpful for letting us zoom in to possible disagreements.
There are two places where I find myself sceptical of the framing in your comment:
You're framing it as something like a haircut on the value of working on a particular topic. But I think that if you're targeting just some set of worlds where we don't get meaningful automated assistance for certain kinds of strategy work, it might be important to explicitly condition on that, rather than just think of it as a haircut.
We might then also ask about whether we have more or less leverage on these worlds. Some takes:
Of course it will depend a bunch on the specifics of the question we're wondering whether we can punt.
Broadly I think worlds where we don't get a bunch of automated assistance for strategy in a timely fashion look significantly worse than worlds where we do get this assistance.
This is compatible with either being higher-leverage.
An important type of leverage we may is the possibility of moving worlds from the first bucket to the second.
I'm actually pretty unsure which worlds we have more leverage over (there seem to be quite a lot of considerations pointing each way), and suspect that this question is more to-the-point than thinking of it as a haircut.
You say that it's hard to reach or exceed a 90% chance. I find myself dubious of this. If we see something like a technological singularity, there will be an enormous amount of progress on very many dimensions. Some of the things that actors will eventually want to do will be tremendously harder than others. I certainly don't want to assume that people will get around to doing things that are a good idea and are possible as early as it's feasible for them to do so; but I think that if you go somewhat past that to the point where it's very easy to get the good thing, it's not hard for it to be a >90% safe bet to think it will happen.
As an analogy, I imagine people before the industrial revolution might reasonably have predicted that there would be a lot more capacity for thinking about space strategy before anyone went to the moon.
Maybe there's a common theme here: I have the impression that I'm more imagining a default world where we get these upgrades to strategic capacity in a timely fashion, and then considering deviations from that; and you're more saying "well maybe things look like that, but maybe they look quite different", and less privileging the hypothesis.
I guess I do just think it's appropriate to privilege this hypothesis. We've written about how even current or near-term AI could serve to power tools which advance our strategic understanding. I think that this is a sufficiently obvious set of things to build, and there will be sufficient appetite to build them, that it's fair to think it will likely be getting in gear (in some form or another) before most radically transformative impacts hit. I wouldn't want to bet everything on this hypothesis, but I do think it's worth exploring what betting on it properly would look like, and then committing a chunk of our portfolio to that (if it's not actively bad on other perspectives).
Re conditioning, I agree that this is the technically correct thing to do and that it isn't clear what difference it makes to the more simple analysis. In some cases it is fairly easy to condition (e.g. if working on a late-stage topic, one can do the project imagining that there isn't lots of advanced AI advice in time when it arrives), while at the prioritisation stage it feels a bit harder to do. Oh, and I very much agree that it could be important to act to change whether such AI analysis happens (something that is, if anything, a bit easier to see on a view that treats whether this happens as uncertain).
Re maximal reasonable probabilities, I still genuinely feel like it is hard to get >90% credence that very large amounts of AI analysis on a key issue will happen prior to the issue coming to a head. I think one could get there for some things, but not that many. This is due to there being a variety of defeaters for such high amounts of AI analysis, such as external people like us not having access to the tools, needing the analysis earlier than expected (e.g. due to the need to socialise the ideas), jaggedness in the AI capabilities (e.g. where its engineering abilities take off substantially before more conceptual, philosophical abilities). I think you are onto something re what you are imagining as default vs what I am.
Nice post! I basically agreed overall. Some rambly thoughts:
One reason to work on some "puntable" topics (which I expect you're aware of, tbc) is if doing some of the work helps you understand how what good work on that question looks like, how to automate it well, etc — analogous to how it's easier to hire for work that you know how to do well.
I feel a bit sceptical about work on "foundational and ontological" questions being worth it, though this might be kneejerk scepticism to the word "ontology" (sorry). It does seem like the work that's slowest to do/hardest to evaluate.
(In general, it does seem hard to know how to prioritise slow, not urgent (?), hard-for-AIs work, other than by trying to make AIs better at such work)
Re: AI welfare, I agree that your quoted questions are very puntable, but I think other AI welfare work looks way better to do now. My guess is that the best consequentialist reason for working on AI welfare now is to avoid locking in bad norms, or (more ambitiously) trying to set low-cost good norms; I think this is a pretty reasonable position, and overall feel good about people researching e.g. cheap AI welfare interventions now. I think we probably disagree, so I figured I'd mention it.
Similarly, I think sometimes there's a vibe of, "this will soon be salient to people, for maybe bad/misleading reasons, let's try to make the discourse saner by being early to the topic", which I find basically compelling as an argument.
I left this post feeling like, "man, so much of the plan/the hope is to punt the research to future AIs, or maybe future AI-assisted humans; it's not even clear to me that Forethought should do strategy themselves at all, vs just trying really really hard to make sure handing off strategy to future AIs goes well". (The tradeoff might in practice be small, e.g. maybe the ~best way for you to accomplish the latter is to do lots of the former to generate training data, but I think it's >0.) How do you think about this? (Or, how much is Forethought doing strategy for strategy's sake, vs instrumentally, to try to make automating strategy research go well?)
I like this, and it's simultaneously exciting and bewildering to take seriously the prospect of punting difficult things.
It could be worth emphasising more clearly that this is about (futurist) strategy, which is about as cognitive as things get. Other types of preparation and problem-solving have other critical inputs, and may face ~inherent delays. For those, 'punting' can look risky, especially if you expect later phases to move quite fast. This has bearing on strategy: it's worth attempting to foretell the kinds of lead-time-constrained preparation that might be needed to face upcoming challenges.
(A concrete example that stands out to me is bio monitoring and defenses. But in general I'd love to see more and richer work on characterising emerging threats, especially technological. Not necessarily from Forethought! Other kinds of lead-time-constrained activities might involve coalition building and spreading well-informed takes about important topics.)
An important early question I've been thinking about is "Even with aligned AI there might be a narrowing of human society, we need to make sure this is not permanent or ameliorated. How can we do this?" By narrowing of society I mean people interacting with a widely deployed AI being trained to act in a way that the dominant AI does not see as a threat or otherwise select against, e.g. with culture specific morals. Otherwise we might lose some important culture and not be able to get it back due to convergence.
We think AI strategy researchers should prioritize questions related to earlier parts of the AI transition, even when that means postponing work on some questions that ultimately seem more important.
In brief, our case for taking this “just-in-time” perspective is:
There are more open AI strategy questions than we have capacity or time for right now
At some point, AI uplift (and expanded human attention) will give humanity way more capacity for strategy work
This could make the marginal research we can add today OOMs less valuable, unless it helps us before that point (or speeds up/improves AI uplift)
So the top priority for our strategy work is informing decisions we can’t punt until then
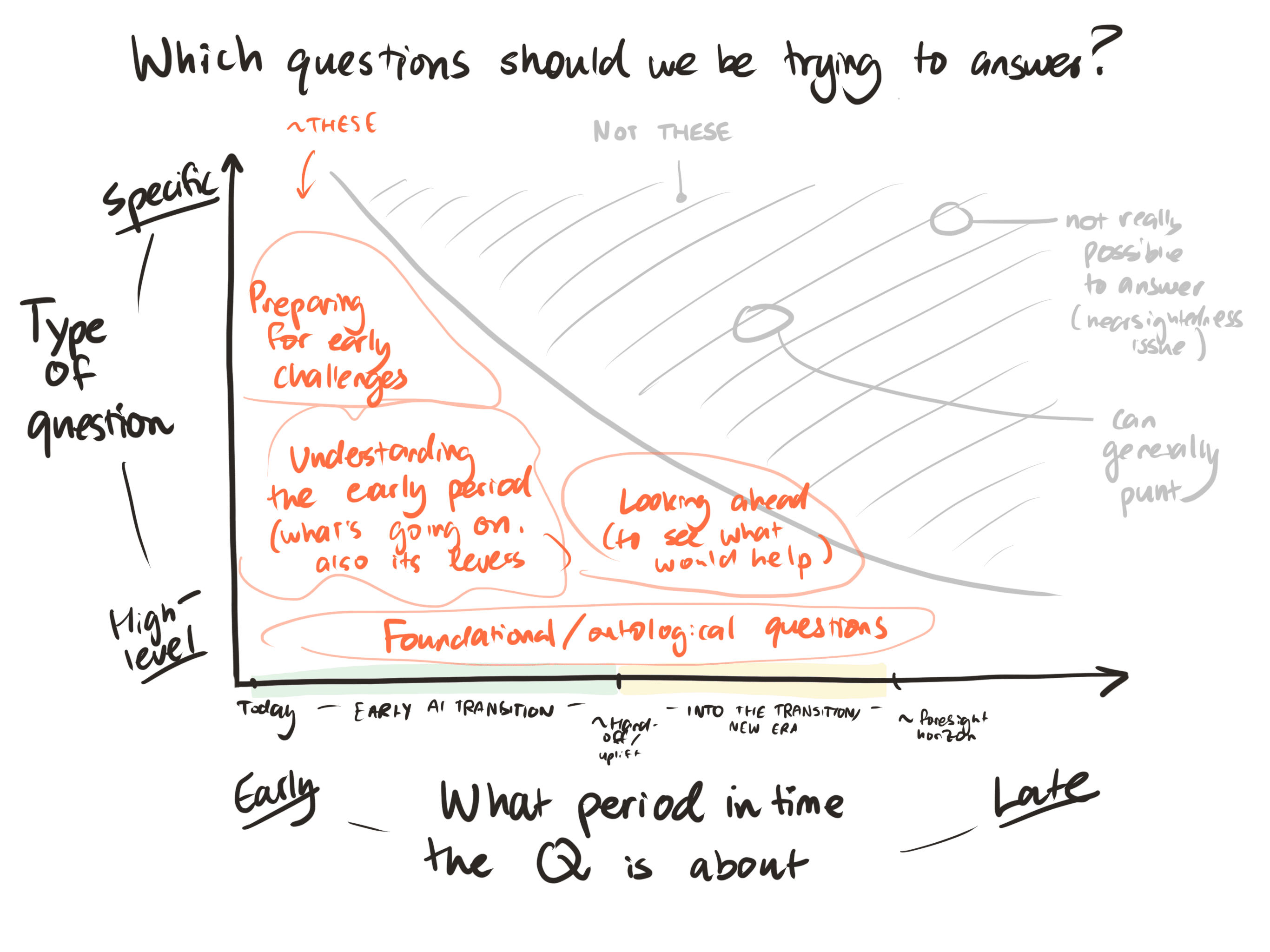
I.e. focusing more on the early period of the AI transition[1] — understanding its dynamics and levers, identifying medium-term states we'd like to steer toward, and clarifying foundational questions
Earlier-period-focused strategy is sometimes treated as resolved (as if the only remaining work is implementation and later-stage questions). We think this is wrong. We sketch out a tentative list of high-priority questions, organized into the following clusters:
Understanding the early period — What is the likely trajectory of AI? What will early transformative impacts be? How will this affect people and institutions?
Preparing for early challenges — Are there meaningful acute risks (misalignment/coups/bio) early on? How much do we need to be concerned about power concentration, and how do we need to adapt checks and balances?
Looking ahead(what would set up later periods well?) — What are the likely trajectories later in the AI transition? What determines how well that goes? Which earlier choices might be hard to reverse past that point?
Exploring the early period’s levers— What might we want to automate earlier? Our collective capacity to make sense of the world seems useful; how can we preserve and enhance it?
Clarifying foundational/ontological questions — How should we characterize AI systems, present and future? How should we think about risks?
We also briefly outline some AI strategy questions that should be postponed according to this view.[2] In particular:
Many research areas within AI strategy focus primarily on later-stage issues
E.g. alignment of superintelligent AI, preventing coups powered by strong AI, space governance, law & ASI, making deals with advanced AI agents, AI welfare, acausal trade...
That doesn’t mean these areas deserve no attention
But it does mean that more questions in the area will be puntable, and we should try harder to focus on “timely” questions
It’s not enough to justify work based mainly on a general argument that the area is important and (historically) neglected
An illustration of this perspective:
A “just-in-time TAI strategy” perspective
The core of our perspective is, roughly:
Assuming AI-driven transformation is likely to be important, and asking: what decisions will people face over the next period of AI development, and what do they need to know to make those decisions well?
Not being all-in on any particular model of how AI development will play out; but generally assuming some degree of continuity in AI progress, so that small transformations tend to happen before corresponding big transformations
Assuming that many decisions related to extremely advanced AI can be properly deferred to the worlds with somewhat more advanced AI than today, which will be better placed (via leveraging AI cognitive labour, as well as less nearsightedness[3]) to address questions about that
We think many people are on board with something like this perspective (which isn’t to say it’s uncontroversial!), but that the implications haven’t always been properly drawn out. This is our attempt to do so.
To put it another way, we are seeking to ask “what do human minds really need to understand, over the next few years?”; this involves ruthlessly excluding questions which can be excluded. We think that this is the appropriate stance for a good chunk of our energy in orienting to the future. Other implicit orientations we think people sometimes adopt, that we can contrast ours with:
Implementation not strategy: “We basically know what needs to be done; now it’s just implementation details”[4]
Big things first. “We should just think hard about the whole of the future and follow arguments about what will eventually be most important”
Curiosity first: “We’re so clueless/directionless that we should mostly be following intellectual curiosity, not any kind of prioritization system”
(We think each of these has its place, and we’re not claiming that everyone should stop using them. But we do think that more AI strategy right now should take the perspective above.[5])
An aside: it will remain true (even deep into an intelligence explosion) that waiting longer will yield more and better cognitive labor. Therefore there will be reason to continue the just-in-time strategy: things which are puntable generally should be punted. However, even when your general attitude is to punt on a question you should often make some minimal investment — doing a cheap amount of analysis to get a first-pass answer, partially as a hedge against model error in the judgements about what can be punted.
The early part of the AI transition as our responsibility & focus
From the perspective outlined above, the crucial questions to ask concern the immediate, mostly human future — the early part of the transition to advanced AI, rather than late in the transition or the AI era itself. This is the period that we know more about and have unique influence over, and the period before largequantities of AI research capacity change the possibility space for research endeavors.
For the sake of concreteness, we can think of this period ending a month or two after whenever our strategic research capacity becomes 100x greater than today.[6] An eyeballed guess might be that this will be in 5 years’ time (maybe something like “between 1.5 and 15 years from now”).
Some notes on this definition:
It’s not clear what sequence we will get AI capabilities in, and that makes this period kind of odd to think about — it might have an awful lot happening (if strategic research comes relatively late as a capability), or it might not have that much (if strategic research is relatively early)
That we don’t know the extent of this special responsibility is part of the challenge that we have to face
Except in very hard takeoff worlds, this period precedes the arrival of superintelligence — and everything that follows
Sometimes “what happens in the limit as AI gets really good?” is easier to think about than “what happens at this point in time on realistic pathways?” — we are explicitly encouraging people to drag their attention away from the more timeless question and down to the more grounded one
What does this mean about which questions we should prioritize?
With the early part of the AI transition as our special responsibility, we need to understand what it would even mean to navigate it well, and how to do that. So we want to have enough of a picture of what comes after to let us make informed choices about what position we want to be aiming for as we exit the early period.[7] And we want to understand the important dynamics and potential levers in the early period, as well as any challenges that we will need to face soon.[8]
We’ll now list more specific questions that seem important to us, with the warning that as we get more concrete we become somewhat less confident in our takes. These are grouped into five clusters, loosely related to the just-in-time framework suggested above.
a) Understanding the early period
We think many questions about getting a better picture of the early period deserve more attention:[9]
What is the likely technical trajectory of AI? Which capabilities will be developed, based on which paradigms, and how fast? What will drive or bottleneck different types of AI progress during this time?
How will the AI industry develop? Will it be concentrated down to ever-fewer actors capable of building bigger frontier models? Will a lot of the action move to applications that are built on top of foundation models (with the big model providers becoming more like service providers), lowering the barriers to entry? Should we expect state interference?
What are likely to be the early transformative impacts? What effects do we need to account for in all our other plans when considering this early period? How early does the uplift-to-strategy-work come, and more generally which technologies or groups will be sped up more or less by earlier AI systems?
How will AI impact human institutions? Which institutions will still matter, and which will fall behind or fall apart? We need a richer understanding of the trajectory space here, to make informed choices about what to steer towards.
How will the situation impact individual humans? How will this affect how well decision-makers act?
What else might “flip the gameboard”? Besides the effects of early-stage AI, might we see other major disruptions like international conflicts or disasters that significantly change the background situation? What seems particularly likely to happen, or to change, and how?
As a general rule we’ll want to focus on questions that meaningfully change the strategic landscape (in relevant scenarios) and which haven’t gotten a huge amount of attention.
b) Preparing for early challenges
As we develop our picture of the early period, we can start to ask which challenges might be urgent and how we should prepare:
Is there meaningful risk from power-seeking AI, pre-ASI? Arguments about misaligned AI risks often focus on superintelligence. To identify the challenges we need to address right now, we need to understand what risks could look like before superintelligence, in the period before AI really boosts our strategic research capacity. For example, this could involve making sure early systems help our research as much as possible instead of burying us in convincing-seeming slop.
How much is coup risk a concern during this period? Concerns about AI-enabled coups also focus on worlds with somewhat more advanced AI. To what extent does this risk need major active mitigations even before then?
What power concentration dynamics might play out, and how concerned should we be? Short of coups, there are many ways in which powerful actors may gather more power to themselves. Addressing these might be one of the key challenges for this period.
What are the load-bearing parts of our societal checks and balances, and how will we need to adapt them for the AI era? We can’t wait to find out which of our checks and balances cease to function once AI plays a sufficiently large role in society and the economy. This is something we need to predict and patch ahead of time, if we want to preserve our institutions into the AI era. (This is sort of another take on the power concentration question.)
Are AI-driven biorisks a major challenge? We are conscious that at some point AI-driven biorisks could be severe; it is unclear to us whether we should expect this to happen in the early period, or if there are mitigations aimed at later periods that are best ramped up during the early period.
What other challenges might arise early on? Are there potential challenges we’re missing? (Or better ways of approaching the challenges we’ve identified?)
c) Looking ahead (to see what would help later periods)
If we want to exit the early period in a good position, we need to know what "well-positioned" means. To do that, we want to get a sense for what might happen a bit further into the future (and how that might depend on what happened during our “early” period).[10]
We think it makes sense to focus on a middle-ground here, and not think much about trajectories that take us past a medium-term “foresight horizon”. In principle, thinking about very late stages could be helpful if it allows us to back-chain to see where we want to be as we come out of the early period. But in practice we're skeptical about this approach: it involves reasoning about a future that’s so different from our present, and backchaining across multiple eras where the option space is so vast, that we think it’s pretty difficult to come to trustworthy conclusions.
So looking ahead could involve asking:
What are the plausible trajectories later in the AI transition? What might happen between the end of the early period and, say, the point at which the global economy grows a hundredfold? A large majority of future development or change will happen later still, but that’s more likely to be past the foresight horizon.
Which variables, coming out of the early period, make it most likely that the trajectory continues well vs poorly? E.g. maybe something like power distribution matters quite a bit here, or whether we’ve used up a critical resource, or whether some institutions persist and how they’re set up, etc. These could provide targets, for which it is useful to look for tractable interventions.
Which earlier actions will be hard to reverse?[11]Which earlier events might be fairly contingent — whether they happen or not depends on earlier choices — and have extremely persistent effects?
As a complement to starting by considering where our trajectory might lead and what we want to aim for, and then working backwards, we might start by considering the early period, asking “what levers do we have?”, and then asking whether it’s worth pulling those levers.
What potential early transformative impacts are more desirable? How (much) can we affect the sequencing? The ordering of these early impacts could significantly affect how well things go, and we may well be able to influence it by speeding up or slowing down particular applications. This is potentially one of the largest levers we have over the transition period.
What do we want to automate early and well? What would it mean to automate these things well? The foundations of later automation will be laid during the transition period. By speeding up the right kinds of automation, and making sure they are done carefully, we can put ourselves in a better position to make use of huge amounts of AI labour in future.
What are the likely trajectories for our epistemic environment, as technology changes? How do we preserve and enhance our collective ability to understand and reason about the world? One of the salient ways that we could end up in a much better or worse position to navigate is via changes to the epistemic environment. First we need to improve our understanding of the trajectory space, such that we can then choose how to steer through it.
How can we ensure we get the good impacts from uplift in coordination, without facilitating collusion by bad actors? Coordination tech is powerful, and dual-use. If we knew the right types to boost — and what to guard against — those could be key interventions.
How do we want AI systems in the near-term to behave? What levers do we have to encourage the desirable behaviour?[12]
What do we need people to be paying attention to? Coalitions and buy-in to the importance of certain ideas, originating in the early period, may well persist for some way into the AI transition — we should not assume that everyone will be quick to jump to deferring to AI strategic advice, especially at this point.
Foundational questions are less directly action-relevant. But they feed into how we think about strategy, and paying attention to them seems high priority to us.[13] There are two reasons for this:
They could help us to more clearly address the questions above
E.g. better concepts for thinking about how AI intersects with checks and balances might make it easier for us to come to sensible conclusions there
This seems especially true as AI progress breaks long-standing assumptions / strains our concepts
We might be able to automate strategic research within a fixed ontology before AI can do a good job of automating devising new foundations or ontologies.
If so, then work we do on helping people to think with clearer concepts might be relevant for a longer period — helping us to better leverage large amounts of (jagged) cognitive labour for strategy work
We cannot give a complete list of foundational questions that might be helpful to address. A few stubs which seem appealing to us:
How should we characterise how AI systems currently reason and behave? This informs how we should expect future AI systems to behave, and how we want to change AI development at the margins. And it’s a topic where earlier understanding has compounding benefits.
Which paradigms could we develop powerful AI in, and what determines which are more likely and more desirable? This directly impacts how we steer the AI development work that happens on our watch during the transition period, and could be a large lever on how much risk we have to face down the line.
What are the likely selection effects, good and bad, on AI systems during this transition? Which basins of attraction should we be most worried/excited about? Our understanding of the risks and opportunity space is currently patchy and ad hoc. A better sense (even if still very high-level!) for what drives these selection effects and determines whether they favor “good” or human-aligned systems would help us shape the selection environment and generally make informed choices about where we want to go.
What sort of things are different types of AI systems? Which should be regarded as “entity-like” in some sense? (Or “tool-like”, or something?) Whatshapes should we imagine AI entities will be in (or are)? How should we think about systems which are composed of other systems, or composed of a combination of humans and AI systems?
How can entities of vastly different scales relate to each other in healthy ways? Ultimately, the future is likely to contain entities of extremely different scales to those we’re used to, e.g. in terms of cognitive capabilities and spatial expansion. Although the answers to this question might not become important until later on in the AI era, reaching them could require new theoretical underpinnings and a lot of serial time, such that we need to begin working on it now, if we want to reach the AI era prepared for what is to come.
Can we better characterize possible threat models around advanced AI? A couple of paradigm cases (misaligned agent takeover, catastrophic misuse, coups) are somewhat clearly articulated. But how much do these represent the key cases, versus being just the most legible instances of a more complex space of possibilities? How robustly useful are various interventions that focus primarily on the paradigm cases (i.e. if reality strays a bit from those scenarios, do the plans break)?
Which AI strategy questions does this tell us to drop?
Many research areas in AI strategy focus primarily on later-stage issues. This shouldn’t seem very surprising; these are often precisely the highest-stakes and most neglected-seeming areas. However, this does also mean that a larger fraction of the questions in these areas will be hit by the “shouldn’t we punt that?” consideration than would be the case for work on e.g. near-term implementation questions.[14]
Ultimately we think that for later-stage issues — like alignment of superintelligent AI, space governance, AI welfare, and so on — we should start by assuming that a question should be postponed and then rule it in if we have an active reason to believe it’s “timely” (rather than the other way around).
Note:
A generic exception here is that it’s often useful to better understand the timing: asking whether a given issue is likely to arise during the early period
Better answers to some of these questions could help us differentially speed up the AI uplift of relevant strategy research[15]
Besides that, however, we’d want to separate out sub-questions that do concern earlier periods,[16] and/or focus on higher-level questions ("looking ahead" & "foundational questions" above)
So what does deprioritizing based on this reasoning actually look like?
Below we take some areas in AI strategy and briefly consider which questions might be in/out (these notes depend to varying degrees on various background views that we don’t justify here):[17]
Law & AI
Work that tries to design legal regimes for coexisting with superintelligent AI agents seems worth postponing. It’s hard to say if we’ll actually end up in a world where the same kinds of legal regimes predictably matter and humans are trying to coexist with superintelligent agents, and even if we do, we expect that most of this work would be much easier to pursue later on (with AI help and easier access to relevant info).
However, exploring legal/governance regimes that would help us manage weaker AI systems or provide healthy stepping stones towards the next type of legal regime could be “timely”. And it could be useful to explore higher-level questions like “What role do legal systems currently perform, will that still be needed in some scenarios, what other institutions might do this?”
AI safety — specifically the alignment or governance of superintelligent systems
Some versions of work on questions like “How could governments deploy or align superintelligent AI?” seems to assume that ~ASI is dropped into a world much like ours, before any other real changes arrive — or lays plans for dealing with agents as their intelligence goes to some limit. Much of that seems worth postponing to us.
Still, prioritizing work focused directly on strong superintelligence could be reasonable on some worldviews. And there's plenty of "timely" AI safety work. For instance:
Understanding misalignment risks in the early and early-middle periods, or trying to build systems that are safe/robust enough to trust with higher-stakes/later-stage challenges
Developing better concepts for thinking about alignment
Understanding which selection effects, in practice, affect the kinds of AI systems that get built and deployed
Guarding against coups that are only possible with strong AI
We think that guarding against nearer-term coups (or power concentration more generally) may be important; and that building coalitions who will guard against longer-term coups may be important. But we see relatively little case for trying to address the longer-term challenges directly today. It might be useful, however, to explore how earlier work might predictably affect later risks — e.g. by setting precedent.
Space governance, and long-lasting deals about the future (e.g. “how should we split up galaxies and enforce that allocation?”)
We think that these are things which will naturally happen only after the early period, when people will be able to benefit from much more AI strategic advice. Still, it’s possible that developing concepts to help future thinking, or building coalitions around some ideas, might be valuable. And we are not against a certain amount of scoping work to understand what might happen on this front in the middle period.
Deals with AIs
Given background views we won't justify here, we don't expect safety-relevant deals with AI systems to be relevant during the early period. Exploring the timing question itself does (as usual) seem potentially useful (“Will we see deal-capable agents, before we want to make the kinds of deals that get proposed?”), and it could also make sense to check things like “How likely is it that we’ll later regret not building a coalition around this, and how long might that take?” But (even if later on it’ll make sense for certain human groups to try to make deals with advanced AI systems) we think it’d make sense to postpone questions like “Exactly what kind of utility function would a misaligned AI agent need to have to go for a deal instead of sabotaging?”. We do think that conceptual work could be helpful (not one of our top priorities, however; we think that a lack of the right concepts inhibits people from developing good models of how these might play out in the middle period and beyond).
AI welfare (or: “digital minds”)
It seems useful to explore things like provisional/preventative interventions on this front, the “meta” question of timing (“Which kinds of digital systems ought to be treated as moral patients, and when might we see those? Which decisions or trends here might be particularly sticky?”) or pragmatic responses to plausible especially scary scenarios (in which it looks like we have to make some hard-to-reverse decisions early on, with bad info). It could also make sense to ask things like “By default, what might the public end up believing on this issue over the next N years, how might various groups respond, how will this play into AI risk?” And it can help to explore foundational questions like “What even is the thing that would be the moral patient” or “how can we work towards worlds where different sorts of entities interact well?” or “How can we avoid wrongly imposing human concepts here...?”
But — assuming we’re not expecting digital moral patients en masse in the very near term — it seems less useful to explore things like “What kind of deployment scaffolding is welfare-increasing?” or “How exactly should AI companies respond to self-reports of different kinds?”
Acausal trade
It could be worth firming up the conceptual foundations here, and exploring the cases in which something like this could be very relevant early on. But we are (tentatively) skeptical that object-level arguments will have much impact on our actions in the early period.
A final note on asking “Which questions matter?”
These ideas grew out of a couple discussions about “which questions really truly matter?”
Whether or not you like our answers, we think that the question is a useful one to ask, and would recommend trying to answer it yourself. Some of the prompts we used, in case they are useful for inspiration:
What kinds of decisions might people make soon that they might screw up if confused?
You're one year into the intelligence explosion. Things have gone badly wrong. What do you wish you'd understood earlier?
User interview yourself; what do you find yourself bumping into and wanting a better sense for?
What do people whose judgement you trust/respect seem to strongly disagree about (or get wrong)?
Imagine that there are adults in the room. What have they figured out? What are they not bothering to try and understand?[18]
Thanks to various people who left comments on an earlier draft of this memo!
For the sake of concreteness, we can think of this period ending a month or two after whenever our strategic research capacity becomes 100x greater than today. See more below.
Perspectives that aren’t directly related to “we should focus on timely questions”, like our expectations on which AI developments we might see earlier/later, inform our views here.
Or a variant: “We basically know the menu of possible outcomes, and we just need to work to make the good ones more likely by helping to avoid the bad ones”.
We also ignore most practical questions here. We’re trying to outline a high-level strategic view; in practice this could feed into many localized decisions people make, but engaging with the details of those decisions, while necessary, is beyond our scope here.
Why “a month or two after”? Simply because we must have some time for the new strategic capacity to bear fruit. But for practical purposes we don’t think it’s important to engage with the nuance of the definition.
Of course, these are more-or-less two versions of the same goal. Handling the early period well is just a version of setting things up for the later period well. But they invite us to direct attention to different places, and we guess it is worth considering each separately.
A sketch of our high-level view here: there’s a lot going on, new developments will interact with everything in confusing ways, and there are a bunch of different ways things could go. Our current understanding of this period is shallow & limited; we can do things like forecast one-dimensional questions reasonably well, but that’s not enough to find the intervention points and navigate this whole thing well.
Note that we shouldn’t (and can’t) get extremely specific here — the specifics matter less when we’re just trying to pick a high-level target than when we’re trying to prepare for near-term challenges; and we’ll be too near-sighted to answer overly specific questions.
We’re especially interested in these questions to the extent they might have answers that we could aim for; but perhaps thinking beyond that could help us to identify precursor states that are more likely to end up on a good track, even if they’re not there for sure.
Note: in some cases you might expect that these questions will take longer to “cash out”. So, in terms the diagram above, the bottom-left part (foundational questions that are concerned with the immediate future) should plausibly be greyed out.
Put another way, taking this consideration into account can save us more effort on these high-stakes long-term issues than would be the case for naturally-nearer-term areas of research.
Note: Early research on later-stage questions could also improve how later-stage research goes; that seems to fit in the framework. (See also "parallelizable vs serial".)
For some discussion of what speeding up AI uplift of research could look like in practice, see e.g. this post (which considers this question for AI safety).
- Questions that condition specifically on scenarios in which the issues do arise early. (Note that these scenarios might be pretty unusual — not the modal/median worlds in which the issue is imagined or shows up.)
- Questions that focus on a way to start bootstrapping towards a solution to the broader problem. (A related post explores the idea of bootstrapping to "viatopia".)
Some early-period-related questions seem to get swallowed up (or overshadowed) by higher-stakes-seeming and/or more idealized (easier to formalize) questions that concern later periods (but are "untimely"). I think this happens, for instance, with modeling imperfect agents or early AI impacts.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...


Thanks for this in-depth writeup of what is clearly a very important factor in prioritising our work aimed at the AI transition. Your piece has built the argument for such prioritisation clearly enough that it has allowed me to put some previously inchoate responses into a more crisp form:
If we could tell with certainty which topics would receive >100x as much work as we could put in prior to when that work is needed, then I think your argument goes through. But I have a lot of uncertainty about that and such uncertainty weakens the prioritisation effect substantially.
To see the effect easily, suppose for simplicity that for some piece of apparently late-stage strategy there is a 50% chance that >100x as much work gets done on it, obviating the need for us to work on it now, and a 50% chance that there is no appreciable extra work done (e.g. because the intelligence explosion is happening in a particular lab that doesn't do this work, or because the work requires aspects of cognition that are improving more slowly, or because it turns out it was needed earlier in the explosion than expected).
In this case, the expected value of marginal work on that late-stage strategy gets roughly halved compared to if there weren't going to be this AI-driven work later (50% chance of the naive estimate + 50% chance of <1% of that estimate). Given the fairly extreme distribution in the value of a particular person working on different topics, it isn't that rare for the best thing of one category to work on being >2x as good as the best thing from another category, such that you shouldn't switch category even after downgrading the EV.
That would mean early-stage vs late-stage would be an important factor in choosing what to work on, but not any kind of filter as to what to work on. As the chance of large amounts of AI work on that topic increases, the factor gets stronger. e.g. it reaches 10x at a 90% chance, which is quite strong (though I think it is hard to reach or exceed a 90% chance here).
So I think this can have a substantial effect on the choice of what to work on on the margins, but isn't a filter.
What about its effect on the portfolio of research work aimed at the AI transition?
Suppose that there are logarithmic returns to the research work (which means that the marginal value of extra work is inversely proportional to aggregate work so far, which is a common neglectedness assumption). In that case, we should do 50% as much total work on equally-important things that we estimate to have a 50% chance of being obviated later, and 10% as much total work on those we estimate to have a 90% chance of being obviated later.
So that is still quite a lot of the share of our total work into late-stage things even when we don't think they are intrinsically more important. In the piece you suggested that we do at least some work on these topics, to avoid the possibility of being caught completely flat-footed if the anticipated AI-work on those topics doesn't happen, and I think the maths above suggests a larger amount of work than that (especially on topics that appear to be more important or more tractable).
(Note that my simplifying assumption of no appreciable AI help vs an overwhelming amount might be doing some work here. I'm not sure what the best way to relax it is.)
Thanks, I agree with your mathematics and think this framework is helpful for letting us zoom in to possible disagreements.
There are two places where I find myself sceptical of the framing in your comment:
Maybe there's a common theme here: I have the impression that I'm more imagining a default world where we get these upgrades to strategic capacity in a timely fashion, and then considering deviations from that; and you're more saying "well maybe things look like that, but maybe they look quite different", and less privileging the hypothesis.
I guess I do just think it's appropriate to privilege this hypothesis. We've written about how even current or near-term AI could serve to power tools which advance our strategic understanding. I think that this is a sufficiently obvious set of things to build, and there will be sufficient appetite to build them, that it's fair to think it will likely be getting in gear (in some form or another) before most radically transformative impacts hit. I wouldn't want to bet everything on this hypothesis, but I do think it's worth exploring what betting on it properly would look like, and then committing a chunk of our portfolio to that (if it's not actively bad on other perspectives).
Thanks Owen. I also agree with your maths.
Re conditioning, I agree that this is the technically correct thing to do and that it isn't clear what difference it makes to the more simple analysis. In some cases it is fairly easy to condition (e.g. if working on a late-stage topic, one can do the project imagining that there isn't lots of advanced AI advice in time when it arrives), while at the prioritisation stage it feels a bit harder to do. Oh, and I very much agree that it could be important to act to change whether such AI analysis happens (something that is, if anything, a bit easier to see on a view that treats whether this happens as uncertain).
Re maximal reasonable probabilities, I still genuinely feel like it is hard to get >90% credence that very large amounts of AI analysis on a key issue will happen prior to the issue coming to a head. I think one could get there for some things, but not that many. This is due to there being a variety of defeaters for such high amounts of AI analysis, such as external people like us not having access to the tools, needing the analysis earlier than expected (e.g. due to the need to socialise the ideas), jaggedness in the AI capabilities (e.g. where its engineering abilities take off substantially before more conceptual, philosophical abilities). I think you are onto something re what you are imagining as default vs what I am.