It's so common it's a stereotype.
A large corporation releases a cutting-edge AI model, and puts out a press release talking about how their new, [larger/smaller]-than-ever model provides unprecedented freedom for [underprivileged artists/small business owners/outside researchers] to do whatever it is their AI does. You go to their website, start playing with the model, and before long—
Results containing potentially sensitive content have been omitted. Further requests of this type may result in account suspension, etc., etc., etc....
—or something along those lines. The prompt you gave was pretty innocuous, but in retrospect you can sort of see how maybe the output might have resulted in something horrifically offensive, like a curse word, or even (heaven forbid) an image that has a known person's face in it. You've been protected from such horrors, and this is reassuring. Of course, your next prompt for whatever reason elicits [insert offensive stereotype/surprisingly gory or uncanny imagery/dangerously incorrect claim presented with high confidence/etc. here], which is slightly less reassuring.
Checking the details of the press release, you see a small section of the F.A.Q. with the disclaimer that some outputs may be biased due to [yadda yadda yadda you know the drill]. You breathe a sigh of relief, secure in the comforting knowledge that [faceless company] cares about AI safety, human rights, and reducing biases. Their model isn't perfect, but they're clearly working on it!
The above scenario is how [large corporations] seem to expect consumers to react to their selective censorship. In reality I strongly suspect that the main concern is not so much protecting the consumer as it is protecting themselves from liability. After all, by releasing a model which is clearly capable of doing [harmful capability], and by giving sufficient detail to the public that their model can be replicated, [harmful capability] has effectively been released, if perhaps delayed by a few months at most. However, whoever makes the open-source replication will not be [large corporation], absolving the company of perceived moral (and legal) culpability in whatever follows. If the concern were actually that [harmful capability] would lead to real danger, then the moral thing to do would be not to release the model at all.
There are a few serious problems with this. The most obvious (and generic) objection is that censorship is bad. When looking at historical incidents of censorship we often find ourselves morally disagreeing with the censors, who got to choose what is considered inappropriate from a position of power. Almost everyone agrees that Hollywood's infamous Hays code was a moral mistake.[1] In the present day, inconsistent or weaponized social media censorship is widespread, with seemingly nobody happy with how large corporations enforce their rules (though the details of how they are failing are arguable). At least one Chinese text-to-image model disallows prompts which include the word "democracy". It would be surprising to me if protections against generating certain forms of content with LLMs don't eventually lead to unexpected negative social consequences.[2]
Secondly, there is a danger of AI safety becoming less robust—or even optimising for deceptive alignment—in models using front-end censorship.[3] If it's possible for a model to generate a harmful result from a prompt, then the AI is not aligned, even if the user can't see the bad outputs once they are generated. This will create the illusion of greater safety than actually exists, and (imo) is practically begging for something to go wrong. As a "tame" example, severe bugs could crop up which are left unaddressed until it's too late because nobody has access to "edge-case" harmful generations.
The third argument is a bit more coldly utilitarian, but is extremely relevant to this community: Calling content censorship "AI safety" (or even "bias reduction") severely damages the reputation of actual, existential AI safety advocates. This is perhaps most obviously happening in the field of text-to-image generation. To illustrate, I present a few sample Tweets from my timeline (selected more-or-less randomly among tweets using the search term "AI safety" and "AI ethics"):
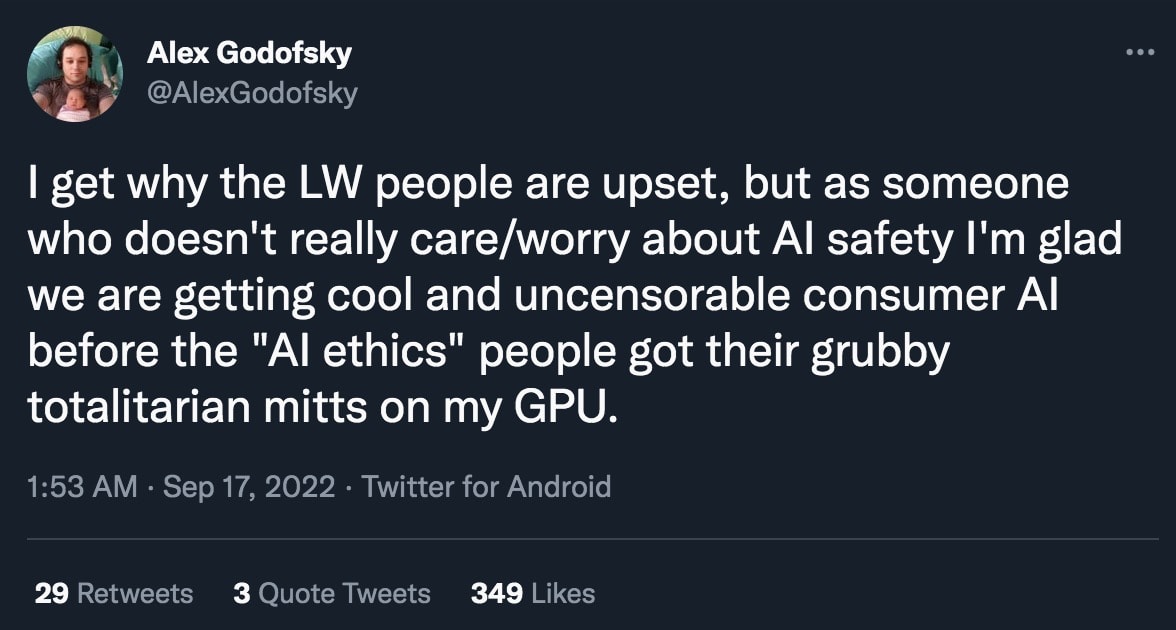
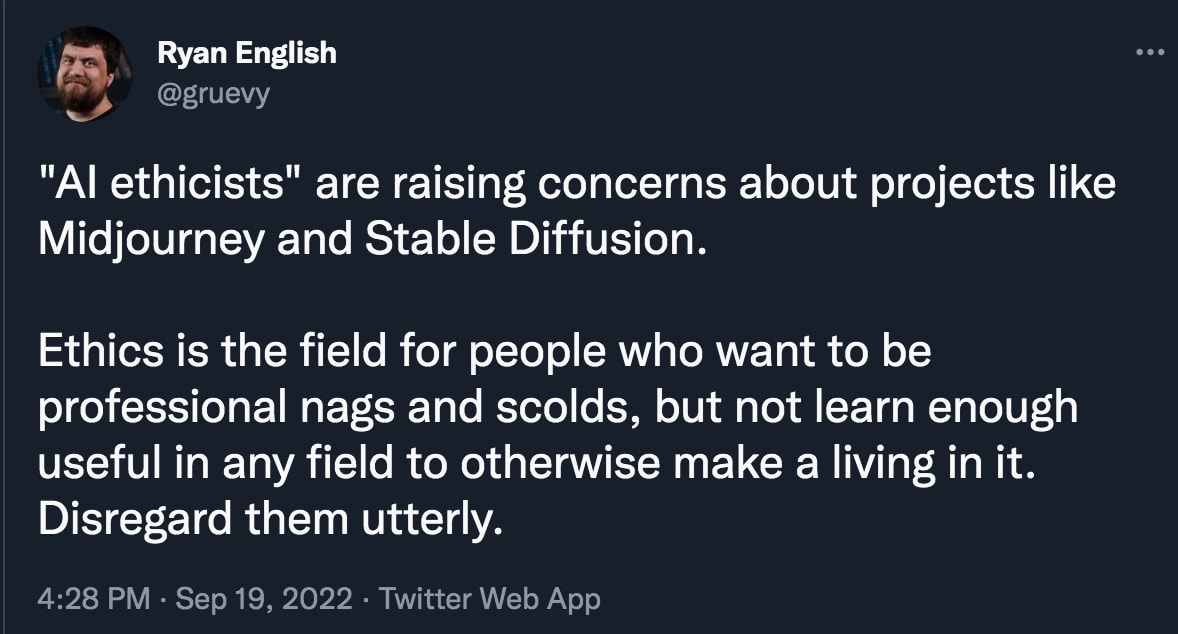
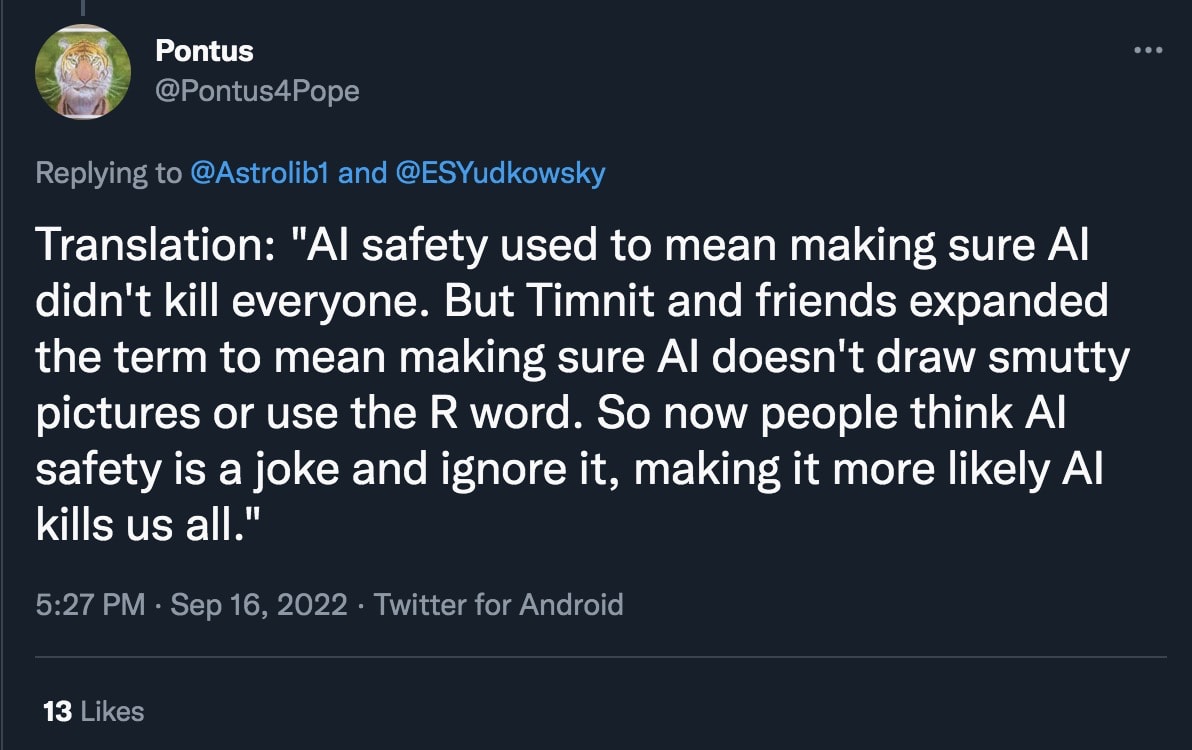
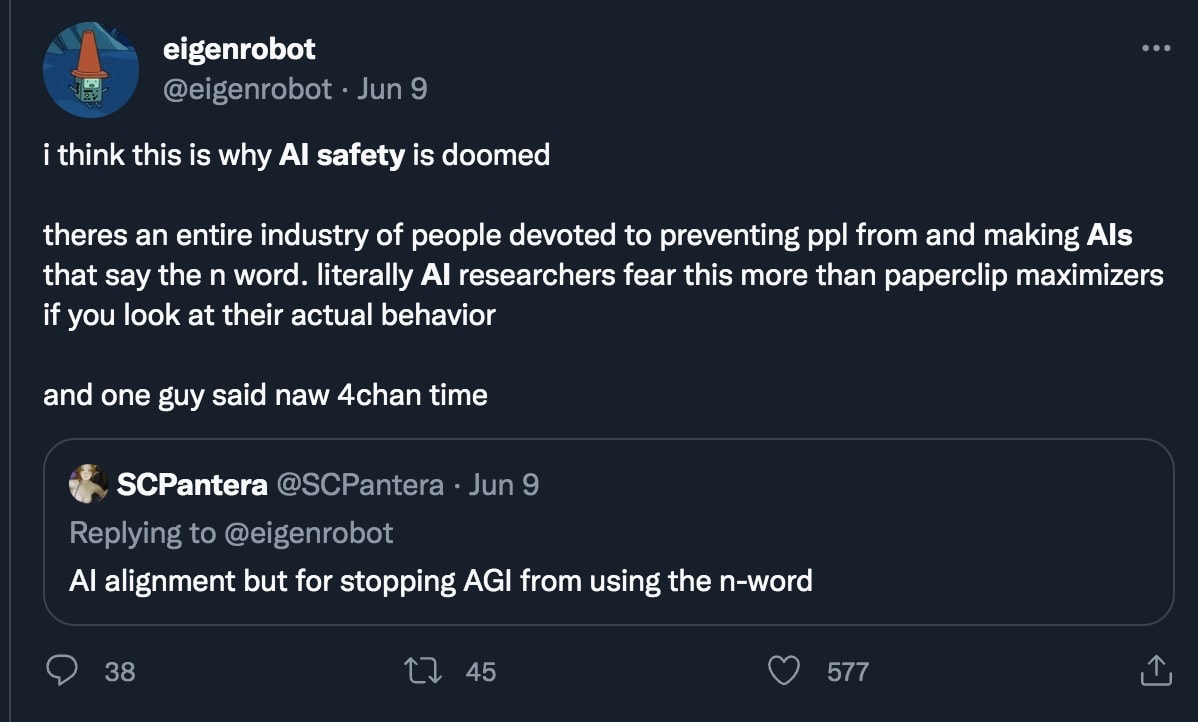

I think the predicament we are facing is clear. The more that public-facing censorship is presented as being a demonstration of AI safety/ethics, the more people tend to dismiss the AI safety field as a whole. This damages our ability to connect with people (especially in the open-source movement) who might otherwise be interested in collaborating, and gives motivation for adversarial actions against our efforts. My background is partially in Public and Media Relations, and if that were my current job here, I would be going into serious damage-reduction mode right now!
This has happened in part due to the general corporate desire to frame concerns over liability as being about the user's safety (instead of the company's), but it's also partially our fault. OpenAI, for instance, is viewed by many as the poster-child of the classical "AI safety" camp (whether deserved or not), and what is it most famous for on the safety front? Its multi-tiered release of GPT-2 (and subsequent non-delayed release of GPT-3 for some reason), and its ban against using DALL-E to generate or edit photorealistic faces! Regardless of if those are good measures to take or not, the fact of the matter is that at some point, a decision was made that this would be marketed as "AI safety" and "minimizing risk," respectively.
While we can't take back what's already been said and done, for the future I would like people in this field to take a stronger stance against using safety-related terminology in places where you're likely to be seen by outsiders as the boy who cried "wolf". Alternatively, perhaps we should make a clearer distinction between types of safety efforts (bias reduction, existential risk reduction, etc.), using specialized terminology to do so. It would be foolish to undermine our own efforts at raising awareness because we missed such an easy concept to understand: Censorship is not viewed as safety by the vast majority of people.[4] Instead, it's viewed as a sort of "safety theater," similar to so-called "Hygiene Theater," which caused mass harm during the COVID-19 pandemic by making people lose trust in public health institutions (deserved or not). We should do everything in our power to reduce the negative effects such "AI safety theater" may cause to our community.
What practical steps can be done?
The following list includes some suggestions given above, along with some more tentative proposals. I do not have rigorous evidence for everything mentioned blow (this is more personal intuition), so feel free to take this with a grain of salt:
- If you can do so ethically, try to minimize the amount of overt censorship used in public-facing models.
- If for whatever reason you need to explicitly block some forms of content, the details of implementation matter a lot, with back-end preventative work being preferred over front-end user-facing censorship. For example, banning sexually suggestive keywords and prompts (a front-end approach) will feel much more subjectively oppressive than not having your model trained on sexually suggestive data in the first place (a back-end approach which also prevents suggestive text/image outputs). Obviously, what you can practically achieve will vary depending on your situation.
- If censorship is being utilized to reduce personal/company liability, say so explicitly! Currently, many people seem to think that calls for "ethics," "safety," or "bias reduction" are being used for the primary purpose of protecting corporate interests, and we really, really do not want to feed that particular beast. Saying "we can't do [thing you want] because we'll get sued/lose access to some services" is a lot less harmful than saying "we can't do [thing you want] because we know what's best for you and you don't." (this is often a useful framing even if you think the latter is true!)
- Make clearer distinctions between types of safety efforts (bias reduction, existential risk reduction, etc.), using specialized terminology to do so. Perhaps new terminology needs to be coined, or perhaps existing concepts will do; this is something that can and should be discussed and iterated on within the community.
- Be willing to speak to the media (as long as you have some amount of training beforehand) about what the field of AI safety is really trying to achieve. Most publications source their news about the field from press releases, which tend to come with a corporate, "everything we're doing is for the good of humanity" vibe, and that may occasionally be worth pushing back against if your field is being misrepresented.
Feel free to suggest further possible actions that can be done in the comments below!
- ^
Especially considering that among many other harms, it was used to prevent anti-Nazi films from being produced!
- ^
For example, enforcement against generating sexually explicit content is likely to be stricter with some media (think queer/feminist/war coverage stuff), leading to exacerbated asymmetry in depicting the human condition. What about classical art, or cultures with totally healthy customs considered explicit in other contexts (such as nudists)? Some of this could be resolved in the future with more fine-tuned filters, but there isn't strong incentive to do so, and evidence from existing social media censorship points to this not happening in a nuanced manner.
- ^
I define front-end censorship as when the user asks for something which is then denied, though the theoretical possibility to create/access it clearly exists; this is different from more subtle "back-end" forms.
- ^
To be clear, it may be the case that censorship is the right thing to do in some circumstances. However, please keep in mind that this community's most famous unforced error has been related to censorship, and if you are reading this, you are unlikely to have typical views on the subject. Regardless of the ground truth, most people will perceive front-end censorship (as opposed to more subtle back-end censorship which may not receive the same reception) as being net negative, and an intrusive action. Some exceptions to this general rule do exist, most notably when it comes to blatantly illegal or uncontroversially unethical content (child pornography, nonconsensually obtained private information, etc.), but even then, some will still be unhappy on principle. One cannot make everyone perfectly content, but should still work to reduce potential damage when possible.
This is a very good post that identifies a big PR problem for AI safety research.
Your key takeaway might be somewhat buried in the last half of the essay, so let's see if I draw out the point more vividly (and maybe hyperbolically):
Tens (hundreds?) of millions of centrist, conservative, and libertarian people around the world don't trust Big Tech censorship because it's politically biased in favor of the Left, and it exemplifies a 'codding culture' that treats everyone as neurotic snowflakes, and that treats offensive language as a form of 'literal violence'. Such people see that a lot of these lefty, coddling Big Tech values have soaked into AI research, e.g. the moral panic about 'algorithmic bias', and the increased emphasis on 'diversity, equity, and inclusion' rhetoric in AI conferences.
This has created a potentially dangerous mismatch in public perception between what the more serious AI safety researchers think they're doing (e.g. reducing X risk from AGI), and what the public thinks AI safety is doing (e.g. developing methods to automate partisan censorship, to embed woke values into AI systems, and to create new methods for mass-customized propaganda).
I agree that AI alignment research that is focused on global, longtermist issues such as X risk should be careful to distance itself from 'AI safety' research that focuses on more transient, culture-bound, politically partisan issues, such as censoring 'offensive' images and ideas.
And, if we want to make benevolent AI censorship a new cause area for EA to pursue, we should be extremely careful about the political PR problems that would raise for our movement.
This is the crux of the problem, yes. I don’t think this is because of a “conservative vs liberal” political rift though; the left is just as frustrated by, say, censorship of sex education or queer topics as the right may be upset by censorship of “non-woke” discussion—what matters is that the particular triggers for people on what is appropriate or not to censor are extremely varied, both across populations and across time. I don’t think it’s necessary to bring politics into this as an explanatory factor (though it may of course exacerbate existing tension).
Yep, fair enough. I was trying to dramatize the most vehement anti-censorship sentiments in a US political context, from one side of the partisan spectrum. But you're right that there are plenty of other anti-censorship concerns from many sides, on many issues, in many countries.
This strikes me as a weird argument because it isn't object-level at all. There's nothing in this section about why censoring model outputs to be diverse/not use slurs/not target individuals or create violent speech is actually a bad idea. There was a Twitter thread of doing GPT-3 injections to make a remote work bot make violent threats to people. That was pretty convincing evidence to me that there is too much scope for abuse without some front-end modifications.
If you have an object-level, non-generic argument for why this form of censorship is bad, I would love to hear it.
If true, this would be the most convincing objection to me. But I don't think this is actually how public perception works. Who is really out there who thinks that Stable Diffusion is safe, but if they saw it generate a violent image they would be convinced that Stable Diffusion is a problem? Most people who celebrate stable diffusion or GPT3 know they could be used for bad ends, they just think the good ends are more important/the bad ends are fixable. I just don't see how a front-end tweak really convinces people who otherwise would have been skeptical. I think it's much more realistic that people see this as transparently just a bandaid solution, and they just vary in how much they care about the underlying issue.
I also think there's a distinction between a model being "not aligned" and being misaligned. Insofar as a model is spitting out objectionable inputs it certainly doesn't meet the gold standard of aligned AI. But I also struggle to see how it is actually concretely misaligned. In fact, one of the biggest worries of AI safety is AIs being able to circumvent restrictions placed on them by the modeller. So it seems like an AI that is easily muzzled by front-end tweaks is not likely to be the biggest cause for concern.
This is very unconvincing. The AI safety vs AI ethics conflict is long-standing, goes way beyond some particular front-end censorship and is unlikely to be affected by any of these individual issues. If your broader point is that calling AI ethics AI safety is bad, then yes. But I don't think the cited tweets are really evidence that AI safety is widely viewed as synonymous with AI ethics. Timnit Gebru has far more followers than any of these tweets will ever reach, and is quite vocal about criticizing AI safety people. The contribution of front-end censorship to this debate is probably quite overstated.
The argument in that section was not actually an object-level one, but rather an argument from history and folk deontological philosophy (in the sense that "censorship is bad" is a useful, if not perfect, heuristic used in most modern Western societies). Nonetheless, here's a few reasons why what you mentioned could be a bad idea: Goodhart's law, the Scunthorpe Problem, and the general tendency for unintended side effects. We can't directly measure "diversity" or assign an exact "violence level" to a piece of text or media (at least not without a lot more context which we may not always have), so instead any automated censorship program is forced to use proxies for toxicity instead.To give a real-world and slightly silly example, TikTok's content filters have led to almost all transcriptions of curse words and sensitive topics to be replaced with some similar-sounding but unrelated words, which in turn has spawned a new form of internet "algospeak." (I highly recommend reading the linked article if you have the time) This was never the intention of the censors, but people adopted to optimize for the proxy by changing their dialect instead of their content actually becoming any less toxic. On a darker note, this also had a really bad side effect where videos about vital-but-sensitive topics such as sex education, pandemic preparedness, war coverage, etc. became much harder to find and understand (to outsiders) as a result. Instead of increasing diversity, well-meaning censorship can lead to further breakdowns in communication surprisingly often.
I think this makes a lot of sense for algorithmic regulation of human expression, but I still don't see the link to algorithmic expression itself. In particular I agree that we can't perfectly measure the violence of a speech act, but the consequences of incorrectly classifying something as violent seem way less severe for a language model than for a platform of humans.
Yes, the consequences are probably less severe in this context, which is why I wouldn't consider this a particularly strong argument. Imo, it's more important to understand this line of thinking for the purpose of modeling outsider's reactions to potential censorship, as this seems to be how people irl are responding to OpenAI, et al's policy decisions.
I would also like to emphasize again that sometimes regulation is necessary, and I am not against it on principle, though I do believe it should be used with caution; this post is critiquing the details of how we are implementing censorship in large models, not so much its use in the first place.