Over a year ago, I posted an answer somewhere that received no votes and no comments, but I still feel that this is one of the most important things that our world needs right now.
I wish to persuade you of a few things here:
- that truthseeking is an important problem,
- that it's unsolved and difficult,
- that there are probably things we can do to help solve it that are cost-effective, and I have one specific-but-nebulous idea in this vein to describe.
Truthseeking is important
Getting the facts wrong has consequences big and small. Here are some examples:
Ukraine war
On Feb. 24 last year, over 100,000 soldiers found themselves unexpectedly crossing the border into Ukraine, which they were told was full of Nazis, because one man in Moscow believed he could take the country in a few days. A propaganda piece was even published accidentally about the Russian victory: "Ukraine has returned to Russia. Its statehood will be [...] returned to its natural state of part of the Russian world." Consensus opinion is that Putin made a grave mistake. Instead of a quick win, Putin took about 7% more of Ukraine than he had already taken, then lost some of that, while taking over 100,000 Russian casualties and losing over 8,000 pieces of heavy military equipment (visually confirmed) — all in the first year. He later lost some of the land he stole, though he still has about 6,000 nuclear weapons including the Poseidon "doomsday device", and hopes veiled nuclear threats plus hundreds of thousands of conscripts will bring "victory". And by "victory", I mean well over 100,000 people have already been killed, plus many more indirectly, while Ukraine suffers hundreds of billions of dollars in damage, and the world economy suffers similarly, including Russia itself.
 Residential area of Mariupol after one month of Russian assault
Residential area of Mariupol after one month of Russian assault
Global warming
In 1979, the Charney report summarized the emerging consensus that CO2 causes global warming. Still, Republicans didn't want subsidies on renewables or carbon taxes, while Democrats and the media went on treating carbon-free nuclear power as if it were more dangerous than fossil fuels, even though its safety profile looks almost like this:
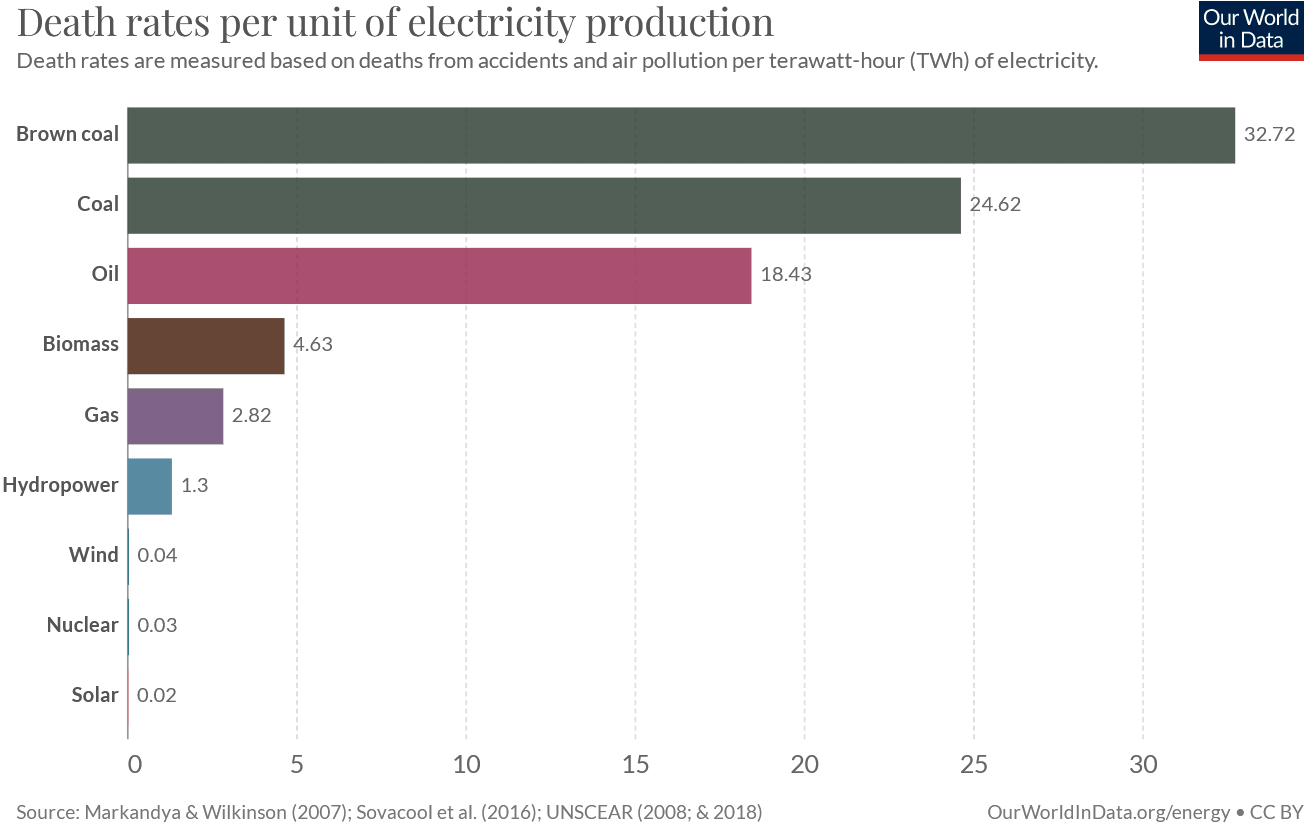
For decades after the Charney report, no new nuclear reactors were approved in the U.S., and it took over 30 years for solar and wind power to become economical. In the meantime, as CO2 accumulated in the atmosphere, human CO2 emissions nearly doubled:
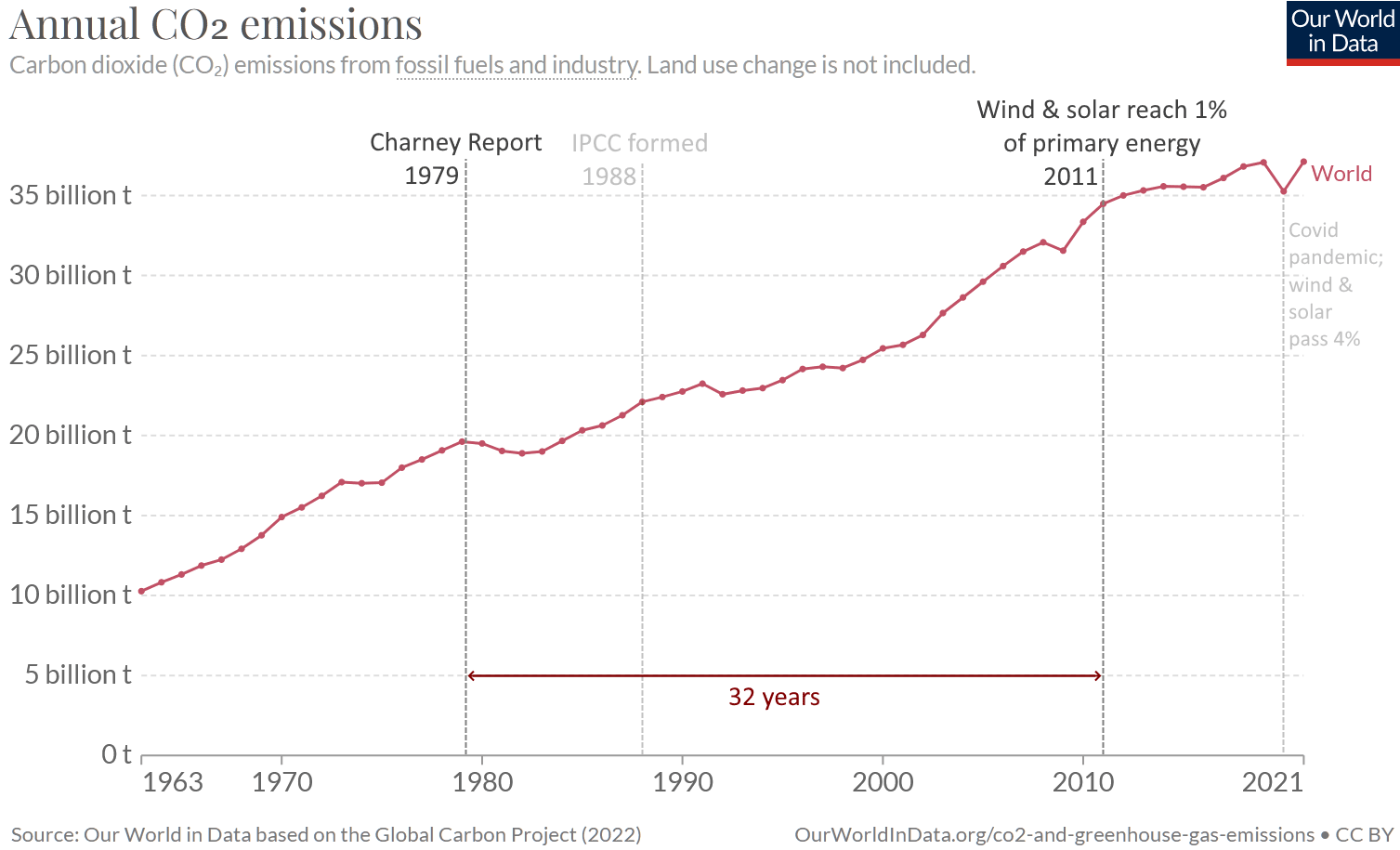
(View charts: CO2 emissions, primary energy)
44 years later, Germany still plans to close its nuclear plants years before its coal plants, though after the attack on the Nord Stream pipeline, they put off closing the last two nuclear plants… for a few months. In those 44 years, Earth's surface warmed 0.76°C and its land warmed nearly 1.2°C (GISS). Land will continue warming faster than sea, and CO2 emissions keep trending upward, although much of that CO2 will stay in the atmosphere even if we stop adding more.
Covid Vaccines
My brother and I tried to convince my 74-year-old father he should get vaccinated, but my dad's sources told him 5,000 people had already been killed by Covid vaccines, and he trusted his sources far more than either of us. I argued that 5,000 entries in the VAERS database is unsurprising due to base rates: natural deaths happen all the time, and some should by coincidence happen after vaccination. He dismissed the argument, saying that no one would give a vaccine to someone who was about to die. He ignored my followup email and would go on to ignore many, many more of my responses and questions, though he did later tell me that actually Covid vaccines had killed 100,000 people.
In September 2021, my uncle and former legal guardian fell down in his garden. Passers-by saw this and called an ambulance. At the hospital, he tested positive for Covid and was treated for it. He had chosen to be unvaccinated on the strength of anti-vax arguments. Later, he was put on a ventilator and a brain scan suggested a stroke. Finally, he died. His widow and my father concluded that a stroke killed him—though the widow lamented to me, eyes watering slightly, that perhaps if the doctors had allowed her to give him ivermectin, he would still be alive today. I suggested she fill out a form to get more information about what happened to him in the hospital; she declined.
Soon afterward, my father's favorite anti-vaxxer, Marcus Lamb, died of Covid and his widow did not suggest any other cause or comorbidity in his death. My father's opinion was unaffected. That Christmas I sent my dad a copy of Scout Mindset, but it was too late; he became more convinced than ever that vaccines were the Real Threat. Just after reading the book, he told me on the phone that the author of Scout Mindset "overthinks things" and immediately sent a 4-page anti-vax gish gallop he wrote himself. Later, after ignoring all of the comments and dozens of questions I responded with, he said I don't have a "scout mentality". Though in 2021 he insisted that the risk of him getting Covid was minimal, he got Covid in 2022 as I expected—and thus, he said, better immunity than any vaccine.
I hope all this illustrates the real-world importance of epistemology, or in other words, truthseeking.
We can't solve all epistemological problems. People will always act kinda dumb. But by broadly chipping away at epistemological problems, by "raising the sanity waterline", I think we can make society function better.
Truthseeking is difficult
It seems to me that most people think figuring out the truth is easy. That's how people talk about politics online: one person talks about how obviously not dangerous Covid is, or how obviously dangerous vaccines are; another talks about how obviously wrong the first person is about that.
I spent some years arguing with people I call "global warming dismissives", who you might know as "skeptics" or "deniers". For instance, have you heard that global warming is caused by cosmic rays? By the sun? By the "pressure law" or "underground rivers of lava", as I've heard? By natural internal variability? By CO2 emissions from volcanoes? By "natural cycles"? Or maybe CO2 emissions from oceans? That CO2 doesn't cause warming? That CO2 causes warming, but CO2 levels naturally change quickly and erratically over the centuries for unknown reasons, as shown by plant stomata? That CO2 causes warming, but only very little? That the lines of evidence showing global warming in the last 100 years are all fraudulent, except for the UAH record which shows less warming? That maybe global warming is happening, and maybe humans are causing it, but it's a good thing and nothing should be done?
This is a wide variety of perspectives, but people with these beliefs all tend to like the web site WattsUpWithThat. They are united not by what they believe, but what they disbelieve: their denial. (But one of the most popular stories is that the word "denier" is meant to associate them with "holocaust deniers", so anyone who says "denier" is an intolerant bigot. Since these are not skeptics in the scientific sense, I call them "dismissives" instead).
They're not dumb. Many of them are highly intelligent. And you may think they are fringe, but their beliefs are extremely influential. Despite the 1970s consensus, a 2010 poll (over 30 years later) found that just 34% of Americans thought humans cause global warming.
One way to counter this sort of thing is the SkepticalScience approach—a web site run by volunteers, devoted to refuting myths about global warming. I do think this site has been influential. But it seems to me that most topics that have "dismissives" or "pseudoscientists" don't have any equivalent of SkepticalScience. Also, the way SkepticalScience makes its judgements is opaque; readers are faced with a puzzle of how much they should trust it; it is not obvious that SkepticalScience is more trustworthy or impartial than WattsUpWithThat. Plus, current volunteers at SkS often don't have the energy to keep up-to-date with the latest science, leaving much of the content several years out of date.
When you branch out from global warming to look at other questions of fact, such as "whether homeopathy works and is not a placebo effect", "whether 9/11 was an inside job", "whether nuclear power is at least as bad as fossil fuels", "whether all vaccines are bad (or just all Covid vaccines)", "whether humans evolved naturally from an earlier primate", and so on, it should least be clear that the truth isn't easy for people to discern, and taking the outside view, you should not expect to be good at it either.
And it's getting harder
In the past, photos have been strong evidence of things. Slowly, "photoshopping" became a popular means of falsifying evidence, but this kind of forgery takes a lot of skill to do well. Thanks to AI image generation, that's changing fast. Thanks to deepfakes and video-generation models, even video soon won't be good evidence like it used to be. And thanks to huge language models, it is becoming practical to produce BS in immense quantities. Right now, many Russian claims have the virtue of being obviously suspicious; we can't count on that forever.
I would rest easier if we had more ways to counter this sort of thing.
Truthseeking is an unsolved problem
I read and enjoyed Rationality: A-Z, all the most popular essays by Scott Alexander, Scout Mindset and other scattered materials, and I have to say: for a movement that considers Bayesian reasoning central, it's weird that I've never seen a rationalist essay on the topic of the evidential value of a pair of sources, and almost no essays about how to choose your initial priors, or how update them in detail.
Consider a pair of sources: your friend Alice tells you X, and then your friend Bob tells you X. Is that two pieces of evidence for X, or just one? This seems like an issue that is both very thorny and very important to the question "how to do Bayesian reasoning", but I've never seen a rationalist essay about it. (I don’t claim that no essay exists; it’s just that being “rationalist” for five years somehow wasn’t long enough to have seen such an essay.)
Consider also the question of how to decide how much to trust persons or organizations. This is a central question in the modern era because the territory is much bigger than in our ancestral environment (the whole planet, over 7 billion people and endless specialties), so any knowledgeable person must rely mainly on reports from others. An essay related to this is The Control Group is Out Of Control, which tells us that even in science (let alone politics), this is a hard problem. Even if you're trying to stick with a high standard of evidence by citing scientific papers, you might end up citing the bullshit papers by mistake. In my time exploring the climate deniosphere, I've come across a large number of bad papers or contra-consensus papers. Even if the consensus is 97% on global warming you should expect this, because there are over 100,000 peer-reviewed papers about climate, a substantial fraction of which give an opinion on global warming. It's not much different in the anti-vax space, where anti-vaxxers have at least one "peer-reviewed journal".
Even in a community working as hard as rationalists do to be rational, we’re still amateurs and hobbyists, so even when key questions have perfectly good answers out there in the broader rationalist community, most of us don't have the time or discipline to discover and learn those answers. You can't expect amateurs to have read and internalized thousands of pages of text on their craft; they have day jobs. So even in rationalism, or in the EA community, I think we have plenty of room to improve.
If you encounter a garbage paper, how do you know it's garbage? Right now, you have to suspect that "something is wrong" with it and its journal. You might, say, comb through it looking for error(s). But that's hard and time-consuming! Who has time for that? No, in today's world we are almost forced to rely on more practical methods such as the following: we notice that the conclusion of the paper is highly implausible, and so we look for reasons to reject it. I want to stress that although this is perfectly normal human behavior, it is exactly like what anti-science people do. You show them a scientific paper in support of the scientific consensus and they respond: "that can't be true, it's bullshit!" They are convinced "something is wrong" with the information, so they reject it. If, however, there were some way to learn about the fatal flaws in a paper just by searching for its title on a web site, people could separate the good from the bad in a principled way, rather than mimicking the epistemically bad behavior of their opponents.
The key to making this possible is sharing work. Each person should not decide independently whether a paper is good or not. We kind of know this already; for instance we might simply decide to trust one community member’s evaluation of some papers. Since this is similar to what other communities (which, we know, often reach wrong conclusions) do, I propose being suspicious about this approach.
Misinformation has a clear business model: Substack may pay over a million dollars annually to the two most popular antivaxxers. And while Steve Kirsch likely earns over $100,000 on Substack subscriptions per year, Gift of Fire's debunking of Steve Kirsch's most important claim has 363 "claps" on Medium (Medium allows up to 50 claps per reader, so we know at least 8 people liked it).
An individual who investigates stuff, but isn't popular, has nowhere they can put their findings and expect others to find them. Sure, you can put up a blog or a Twitter thread, but that hardly means anyone will look at it. Countless times I have been pointed to an outlandish claim treated as obviously true by some science dismissive, Googled for debunkings, and come up empty-handed. There seems to be a point where bullshit is popular enough that lots of people know about it and share it as fact, but either (1) not popular enough for anyone to debunk or (2) debunked by someone who is not popular enough for Google to show.
Individual research is demanding on the individual, but often insufficient
Even if you find a debunking, that's just the beginning. How can you tell whether the original post is correct or the debunk is correct? Ideally you would read both and decide which one is more believable. But this is time-consuming and not even sufficient: What if the original writer has good a debunk of the debunk that you didn't discover? What if the debunking wasn't very good, making the original seem undeservedly good? How do you know which author is more trustworthy, beyond the plausible-soundingness of their arguments? Maybe somebody is misrepresenting. It seems like, to do a good job, you need to investigate the character of each of the authors involved.
Or suppose you start from a question, like "is the linear no-threshold hypothesis a reasonable model of radiation damage?" If you do the research yourself, you might not find an answer conclusively, except perhaps one that confirms your own bias. When I investigated this question, I found that some search queries on Google Scholar mostly gave me results rejecting the hypothesis, while others gave a bunch of results that defended it. It took years before I stumbled upon something more important: actual (approximate) numbers about risks of radiation.
Most people don't actually have enough time to find obscure facts or verify them; doing it well is hard, time-consuming, and not a topic covered by The Sequences: Yudkowsky treated rationalism as an individual endeavor, envisioning "rationalist dojos" where each individual would try to maximize their rationality. That's a fine idea, but it's an inefficient way to raise the sanity waterline. We could reach more accurate beliefs via organized effort than if we each, individually, browse the internet for clues as to what the truth might be.
So, how can we pool our resources to find truths more efficiently?
Computer-aided truthseeking would be easier
We have some computer tools for truthseeking, but they have a lot of limitations:
- Wikipedia only covers "noteworthy" topics, excludes primary sources and original research, mostly doesn't cover bunk or debunks, and is subject to the biases of its semi-anonymous authors and editors.
- Google weights pages by a secret formula, one affected largely by PageRank. Search results may not be accurate or trustworthy, and trustworthy results by obscure/unpopular authors may not be found or highly-ranked. Information isn't categorized (e.g. I can't specify "government sources"). Google has a bias toward the present day, and it's impossible to tell what a search query would have returned had it been input years ago.
- Google scholar finds only academic papers, which tend to be hard to understand because the general public is not their intended audience, the authors are rarely skilled communicators and they often prefer "sounding scientific" over plain language. Only sometimes do search results directly address your question. And while papers are more scientific than the average newspaper article... the replication crisis is a thing, and The Control Group is Out of Control. So one can't simply find a paper and expect it to provide the whole answer, even if it's a meta-analysis.
- StackOverlow and Quora offer answers, but answer scores/rankings are weighted by the opinions of readers, which is not a reliable source of truth.
- Lots of information just isn't publicly available on the internet (e.g. copyrighted books, reports, certain building codes), or is only available in machine-readable form (e.g. csv files) where it's hard to find or visualize.
What if there were a tool that was more directly useful for finding truth?
I think we should build such a thing. Done properly, a comprehensive tool would be useful not just for rationalists, but for the general public too.
Expected value
Since I'm posting to EA forum, I feel like I should say something about how "valuable" a tool like this could be in dollars or QALYs or something... but I don't know how. How would you measure the value of Wikipedia, or its impact on catastrophic risks? Clearly it's valuable, but I don't know how to even begin to measure it.
I view the current epistemic environment as a risk similar in magnitude to climate change. Higher global temperatures create a myriad of risks and costs, none of which can directly cause a catastrophe by themselves. Instead, higher temperatures raise the general risk of conflict, strife and poverty in the world by making life harder or less pleasant for a variety of people. I have funded clean energy efforts not because climate change will directly cause human extinction, but because the rising "risk waterline" is a general threat to the health of society and to the natural environment.
The current epistemic environment is risky in the same way. Some people storm the capitol building because the election was "stolen". Others fight against the perceived threat of nuclear energy, or even wind turbines. Another large group risks their lives over vaccines. Still others fight against utilitarianism. Some are "red pilled", others "black pilled". People seem driven by tribalism, memes and underfunded journalism. Society offers limited means for the average person to improve upon this.
But compared to climate change, epistemological interventions are highly neglected.
My idea is just one of many projects that could help raise the sanity waterline, but if successful, I think its value would be comparable to Wikipedia. It would cover domains that Wikipedia doesn't cover in depth, and reaching people that Wikipedia doesn't reach for culture-war reasons. The value of Wikipedia is hard to measure, but intuitively large. My idea is the same way.
My idea
I think a site should be built for crowdsourced evidence storage, mirroring, transformation, visualization, aggregation, analysis, bayesian evaluation, and search.
This would be a hard project. It would require a bunch of math (software bayesian reasoning), game theory (to thwart malicious users and bad epistemics), UX design (so it's pleasant to use), "big data" (the database would become immense if the project is successful), and a very large amount of code. I am definitely not qualified to design it all myself, but I'll put down some ideas to give you a flavor of my idea.
Let's call it the "evidence dump".
It would be one of the first attempts at “computational epistemology”—to my knowledge. Wikipedia’s page on computational epistemology lists publications going back several decades, yet I’d never heard of it (I just Googled it to see what I would get). But Google gives zero results for "applied computational epistemology" which is what I'm going for: a site that uses epistemological theory to aggregate millions of judgements.
I hope that this site will be informed by rationalist thinking and epistemological theory, and that it will in turn help inform rationalists and AI researchers about epistemological processes relevant to them. For example, emergent failure modes of the site’s algorithms should teach us something. (It is not clear to me whether improving AGI epistemology would be good or bad with respect to x-risk, but otherwise, improving AI epistemology seems like a good thing.)
I don’t expect the system to change the mind of extremists or people like my father. But my hope is that
- People who do care about truth will appreciate that this is a tool that helps them (or at least, will help them after it becomes popular; how to go from zero to popular is a total mystery)
- Some people will appreciate that it gives them a voice to share their knowledge and experiences, even when there isn’t a big userbase
- It will gently guide various people away from extreme political thinking
- The rest of society will somehow be affected by truthseekers getting better information, e.g. if Metaculus forecasters collectively record, aggregate and view all their observations on the system, maybe the result would be more accurate forecasts, due to each individual forecaster seeing more relevant, better-organized information, and those better forecasts in turn would benefit society. Granted, Metaculus already has an ordinary comment system and it’s unclear how to convince people to record more evidence here than they already record there.
Evidence storage
The evidence dump is like Twitter for evidence, summaries and claims.
You can post evidence in two basic forms: either as an eyewitness account (like that story about my father), or as documentation of evidence/claims posted elsewhere.
Direct evidence entry example:
- Category: crime [posted by Username on March 6, 2022 at 6PM]
- On March 4, 2022 at ~11 PM, I saw a man break the passenger-side window of a Ford Taurus on Frankfurt St near 12 Avenue in <City> [software autolinks to a map]
- He rummaged inside, put something in his pant pocket, and ran off
- Category: Common knowledge among: software developers
- Dynamically-typed languages typically run more slowly than statically-typed languages.
They say anecdotes are not evidence, but if a million people could be persuaded to record thousands of anecdotes, I think some real signals will be found in the noise. If, in turn, those signals are evaluated within a system designed well enough, perhaps correct analysis will win more views and popularity than incorrect analysis.
"Common knowledge" could be a potentially useful sub-database of the site, if the site becomes popular. One way this could work is that new users are invited to tell us their fields of expertise (with some limits on how many fields one can be an expert in), rate the truth of statements from other people in the same field, and then to "Name a fact that almost everyone in your field knows, which isn't known or consensus among the general public."
Another sub-database that the site could have is a sort of "yellow pages" of products, databases and tools, e.g. "This URL has a database of climate science data", "This URL has a tool for doing task X".
Claim/summary example:
- Wikipedia: 2022 Russian invasion of Ukraine
- Claim: The full-scale invasion began on the morning of 24 February,[29] when Russian president Vladimir Putin announced in his public address a "special military operation" for the "demilitarisation and denazification" of Ukraine.[30][31]
Claims from Wikipedia should be generated automatically or semi-automatically.
- Academic paper: Doran 2009
- Topic: Climate change | consensus
- Summary: 75 of 77 respondents to the Doran 2009 survey of mostly North American scientists “who listed climate science as their area of expertise and who also have published more than 50% of their recent peer-reviewed papers on the subject of climate change” agreed that “human activity is a significant contributing factor in changing mean global temperatures.”
- However, the total number in the category was 79. A reasonable interpretation of this data is that when asked “do you think that mean global temperatures have generally risen,” two said no and then didn’t answer the question about whether “human activity is a significant contributing factor” and therefore weren’t counted. This interpretation of the data suggests a 95% consensus rather than 97%.
Ideally, the site could gather information about scientific papers automatically:
- Journal: Eos, Vol. 90, No. 3, 20 January 2009
- Not retracted.
- 923 citations
It's often tempting for users to provide more than just a summary, but also some kind of analysis, as seen here where N=79 but somehow "75 of 77" agreed with the consensus statement. I suppose the analysis part ("A reasonable interpretation is...") should be split off somehow from the summary proper, and that the site must make such splitting easy to do.
It's important that claims and summaries be brief, because they are re-used in aggregation and analyses. If a summary needs to be long, it can be broken into parts that can be referenced and rated individually.
Different people would be able to submit competing or complementary summaries of the same source document, with some kind of voting to find the best summaries, and some way to flag errors in summaries and downrank them on the basis of accuracy.
Summarizing claims by cranks and conspiracy theorists is good and encouraged; at this level the site is merely cataloging, not judging.
Claims based on books should provide an excerpt from the book that supports the claim, perhaps as a photo.
I want a database of databases (or database of datasets). Let's consider Covid-19 pandemic data: each country (or province) produces its own bespoke database which can typically be viewed on a bespoke country-specific web site (which provides some visualizations and not others), and is typically also offered in a bespoke electronic form.
At a minimum, one could publish links to all the various web sites and machine-readable datasets about a topic on the evidence dump.
Often there is someone who volunteers to gather and transform data from many places with a bespoke program published on GitHub. If so, someone should be able to import the output of that program into the evidence dump (and other people should be able to review the output and claim that it accurately reflects particular sources or not: "data about X matches source Y").
Ideally, the evidence dump itself would support some kind of data import process that involves transformations on the source data to produce a common schema.
Aggregation
Sources can be grouped. Ideally we would find ways to do this semi-automatically. Example:
- Studies addressing the question "<question>?"
- Study 1
- Study 2
- Study 3
- Study 4
More broadly, lists of things in categories are useful. People should be able to publish lists about any topic, and other people should be able to vote about certain aspects of the items on the lists. If it's a list of tools for task X, for example, people could vote on how good tool T is for task X.
Analysis
To publish an analysis, users would take a bunch of claims, and write some logic involving those claims to produce a conclusion.
In the first draft of this proposal, I suggested a very precise writing style similar to legalese:
- Humans have been adding CO2 to the atmosphere, mostly by burning fossil fuels
- Reference(s) on this topic
- Natural carbon sources and sinks, such as oceans and plants, are net absorbers of CO2 from the atmosphere every year
- Reference(s) on this topic
- There are no major CO2 emitters except humans (including man-made machines) and natural carbon sinks
- Therefore, given humans are responsible for the increase of CO2 in the atmosphere in the modern era (20th/21st centuries)
- This reasoning relies on the law of conservation of mass and the fact that CO2 is not created or destroyed in the atmosphere itself.
Here it says "net absorbers of CO2 from the atmosphere" rather than just "net absorbers of CO2"; there is an exhaustivity clause (third point); it has the phrase "including man-made machines" to clarify that we're not just talking about what comes directly from human bodies; and the law of conservation of mass is mentioned.
I was thinking that politically sensitive topics need careful, complete, qualified wording that is correct and complete so that the conclusion cannot be reasonably contested, and then the voting system would help such careful treatments to rise to the top.
But this seems unacceptable: people don't want to read or write stuff like this. Clear but easy-to-read statements should rise to the top, or the site can't gain popularity. However, caveats and clarifications are important; they need to be included and preserved. I am unsure how to achieve the right balance.
The result of an analysis can be used to support other analyses, forming a DAG (directed acyclic graph) of analyses, i.e. a network of proposed conclusions.
But before we move on, notice that the third clause is a negative statement ("There are no..."). They say you can't prove a negative, but you kinda can: as long as no one can find credible evidence against it, negative statements should generally stand.
I don't quite know how, but
- An analysis should be somewhat resistant to cherry picking. For example, an author could cherry pick two papers that support a desired conclusion, but other users should be able to add additional scientific papers that throw a wrench into the analysis.
- Users should be able to suggest constructive modifications to an analysis to fix flaws or omissions; other users and the author could then vote on them.
- There must be ways to resolve conflicts in the underlying data, and I'm not sure how. For instance, let's say we aggregate all the papers on ivermectin efficacy against Covid. But, some papers said it's effective, others said it's not effective, and others said it may be effective but statistical significance wasn't reached. The simplest possible technique would be to count the number of papers saying "effective" vs "ineffective"/"harmful", and since more papers suggest "effective" than "ineffective"/"harmful", "effective" wins. But this is insufficient:
- the papers vary wildly in quality, sample size, and statistical methods
- a couple were fraudulent/retracted
- there are more possible interpretations than just "effective" and "ineffective", e.g. WORMS!
- It seems to me that the site needs to have a concept of paradigms of interpretation (hypotheses or theories) and bring them together to compete against each other. For ivermectin, one paradigm would be "Ivermectin is effective against Covid" and another would be "Ivermectin is effective against worms, which incidentally helps people with Covid if they also have worms. However, ivermectin is not very effective against Covid itself". A third would be "it's complicated. While many papers suggest it is effective, the body of evidence about ivermectin includes some fraudulent papers and papers with poor methodology, papers whose results may have been affected by Strongyloides infections, and was on the whole affected by publication bias”. Then, users can help rate how well the available evidence fits each paradigm.
- Statements of uncertainty, like "It's unclear if ivermectin works", are inappropriate paradigms, but you could say "The evidence that ivermectin works is similar in strength to the evidence that it doesn't work". Or, we might see similar scores (assigned by crowd review) to "Ivermectin is effective" and "Ivermectin is ineffective" paradigms, which also implies that it's unclear if ivermectin works.
- Or, let's consider global warming, where paradigms could include "it's caused by the sun", "it's caused by natural internal variability", "it's caused by greenhouse gases emitted by humans", and "the apparent temperature changes were faked by a global conspiracy". Any user can evaluate any piece of evidence against any paradigm, hopefully allowing the correct paradigm to rise to the top.
- Creating an analysis should not be much more onerous than it needs to be; a sufficiently friendly user interface is necessary and may be tricky to achieve.
- A user should be able to convert an essay they have written into an analysis. For this purpose I'm guessing that users will need to be able to edit multiple levels of analysis at once, and/or have editable claims or 3rd-party evidence nested inside an analysis.
One more thing is that it seems like an analysis should be able to support or cast doubt on a source: you should be able to argue "source X produces lots of bunk because <reasons>", and if the community agrees, "source X" gets a lower score/reputation, and that lower score would then affect the rating of other analyses that rely on that same source.
Wait, shopping? Does this really belong here?
A few months ago I wanted to find a 12V microwave, stove, or slow cooker with input power between 200W and 700W (with 110V AC as a nice-to-have) and capacity over 2L.
These are impossible products to find. When you search for this sort of product, you find food warmers under 100 watts, microwaves over 1000 watts, propane stoves, space heaters, food thermoses, and contraptions I don't even recognize. After looking at a few hundred product links and a couple dozen product pages I found... not one single item matching this description. Sites such as Google Shopping, Amazon, and AliExpress do not seem to support even the most basic constraints on search results, such as "these word(s) must be in the product title" or even "these word(s) must be somewhere in the product description". I'm baffled and frustrated that online shopping could be this bad decades after the concept was invented.
Seems to me that if a shopping site could actually find what you're looking for, that could be worth money.
There are some keys to this sort of thing working well.
- We need products in a database with a consistent schema. This requires some code; if a product has an input voltage of "12V DC" and an input current of "10A", for example, an "input wattage" of 120W can be inferred (the fact that it's inferred rather than measured being an additional piece of information that ought to be stored). But could we build a site with a means to standardize schemas like this? Could users and/or companies be convinced to add their household products to the database? Could we resolve disputes via voting? For example, if the specs to a dosimeter say it handles 1000µSv/hour but a user finds that it severely undermeasures above 300µSv/hour, this could override the manufacturer claim to become the default value in the database if the evidence is good enough (user has high reputation or other users in good standing corroborate the claim). And perhaps the site can compute a probability distribution on the max dose rate field, and feed that into the search ranking algorithm. And perhaps users could propose new fields representing different thresholds like "max radiation measured within 2x of reality" and "maximum radiation reading ever witnessed", figures that could be crowdsourced by hobbyists.
- The plain-text search system should connect with the schema. If I search for "12V microwave, stove, or slow cooker, with input power between 200W and 700W and capacity over 2L", I imagine the site could guess some search constraints and propose them to me.
- As always in internet search, ranking order is important and needs some thought.
- There should be product comparison matrices, where you select some products and then can create a data table comparing their specs. With charts?
I bring up "shopping" for a couple of reasons. First, areas like this could potentially have some kind of business model, so that the site doesn't have to be funded entirely by donations.
Second, the same features are useful for any kind of research. It makes just as much sense to make a consistent schema, an excellent search system and a comparison table for a list of mines, for example:
Search: [tag 'mine'; 'Common Name' contains 'Quarry' ]
Common Name | Country | Type | Annual Production
XYZ Quarry | Germany | fossil fuel > coal > lignite (etc) | 134,000,000 tons (2021)
ABC Quarry | DRC | precious > diamond | 1327 kg (2018)
...
Among the many challenges in making a system like this is crowdsourcing everything, making everything up for debate, and yet still making something with a schema consistent enough to be useful, with "best-guess" data accurate enough to be useful. Each individual cell in this table could potentially have dozens of pages of debate and hundreds of votes affecting it, with just the "best guesses" shown when a user views a table. And of course, there may be dozens or hundreds of columns that are not shown.
Bayesian evaluation
Here's where I'm stumped: we need transparent algorithms to grade the analyses and claims under various paradigms, in ways that point us toward the truth. I'm not sure how.
The voting systems on the site, whatever they are, should discourage partisan thinking ("like/dislike", "agree/disagree") in favor of analytical thinking ("does the conclusion follows from the premises?", "does this claim support/refute this statement?").
Nevertheless, I would assume that in the long run people will try to game the system via lying and motivated reasoning—votes that are lies, summaries that misrepresent the source material accidentally or deliberately, fabricated sources, bad analysis, and spamming. For this reason, a user reputation system (like StackOverflow) is also needed.
It seems like there should be some way to evaluate third-party claims, but it's not clear how to do that in the plan laid out above. For example, ideally the software could detect, not just declare by fiat, that Fox News or MSNBC editorials are less reliable than Wikipedia, PBS or Reuters.
Finally, of course, I want some kind of automatic Bayesian reasoning to compute estimates of how likely various ideas are to be true, at least in some cases. How to do this... let's call it an exercise for the reader.
Search
Information will be linked together, ranked and structured in ways that facilitate searching. For example, high-rated paradigms should be listed high on search results.
Also, pieces of evidence will have various data fields attached, such as dates, locations, categories and tags, that should be searchable.
Charts
I'm constantly looking for charts. I like to ask Google images because sometimes it finds the answer quickly. But Google images doesn't seem to think charts/graphs are important; there are search categories for "Clip art", "line drawing" and "GIF" but not "chart". Often it finds something on Statista, which then asks for money to actually see a chart. Often the data I want to see is freely available, but the chart is not. Finding data in non-chart form is hard though; often I just give up.
Ideally, the evidence dump would have its own tools to easily visualize data. I'm inspired somewhat by Power BI. I find parts of Power BI painful, but once you have data in the right form, you can create a pretty wide variety of useful charts and tables very quickly and easily. Plus, you can combine multiple charts and tables and control widgets in a "report".
I imagine users creating visualizations via some drag-and-drop interface, and then publishing them with an informative title, so other people can find them via site search or via Google image search. The result: a volunteer-run interactive Statista without the paywall.
Theory of growth?
It would be unwise to build a site run by a volunteer community without a plausible theory for how the community will materialize. This will be a system with network effects, where a very big site is about quadratically more valuable than a small one.
I haven't really worked this part out, but I imagine a key aspect is that early versions of the site need to seem somehow more useful, valuable or fun than an ordinary blog for the people writing stuff in it. I guess it should initially be tailored to only one piece of its mission — one that doesn't depend a lot on network effects.
This won't happen
I'm a senior software developer (CTO, technically) with about 20 years' experience. My job is to build high-quality software that doesn't benefit the world in any way. I'd rather make different software, but for that I need funding. As it is, I was too busy for the last six months to even publish this article. Assuming charity funding isn't available, I'm looking for ideas on
- for-profit business models to build any part of this idea that could eventually become part of a non-profit evidence dump.
- people who could act as my cofounder in a startup in a market related to this
- specifics of the user interface, data model or epistemological methods (if you have expertise in computational epistemology, please help!)
- ways this idea could interact/intersect with related projects such as Metaculus and LessWrong


I agree with your frustrations around those sites, but more structured ecommerce sites seemingly exist: https://mcmaster.com. Perhaps more common/valued in B2B than B2C?