the "OpenAI" launch trashed humanity's chances of survival... Nobody involved with OpenAI's launch can reasonably have been said to have done anything else of relative importance in their lives. The net impact of their lives is their contribution to the huge negative impact of OpenAI's launch, plus a rounding error.
That's in a thread explicitly about debating the social status of billionaires, but if you take his comments seriously, they seem to apply not only to Elon, but also to longtermism and AI Safety as a whole. Whether or not you were directly involved in the launch of OpenAI, if you take Yudkowsky's view seriously, the small marginal impact of having anything to do with popularizing AI Safety dominates any good these movements many have produced.
Does that sound too outlandish and contrarian? It shouldn't. Here's Alex Berger, co-CEO of Open Philanthropy, in his recent 80,000 Hours interview:
[Michael Nielsen] thinks one of the biggest impacts of EA concerns with AI x-risk was to cause the creation of DeepMind and OpenAI, and to accelerate overall AI progress. I’m not saying that he’s necessarily right, and I’m not saying that that is clearly bad from an existential risk perspective, I’m just saying that strikes me as a way in which well-meaning increasing salience and awareness of risks could have turned out to be harmful in a way that has not been… I haven’t seen that get a lot of grappling or attention from the EA community.
Until recently, you might have argued that OpenAI was clearly good for x-risk. They were taking safety seriously, had hired many top safety researchers, etc. Then in May of this year, there was a mass exodus, including many of the people supposedly there to keep an eye on things. As Scott Alexander summarized:
most of OpenAI’s top alignment researchers, including Dario Amodei, Chris Olah, Jack Clark, and Paul Christano, left en masse for poorly-understood reasons
Do you have a strong reason to think that OpenAI remains dedicated to safety? Speculation aside, here's OpenAI CEO Sam Altman in his own words:
First of all, we’re not directed at preventing an event. We’re directed at making a good event happen more than we are at preventing a negative event. It is where I spend most of my time now.
And:
I think that there are parts of it that are scary. There are parts of it that are potential downsides. But the upside of this is unbelievable.
So really, why aren't you freaking out? At what point would you start? What is your fire alarm if not GPT-3?
One objection might be that "freaking out" simply isn't tractable or productive. That's fair, but if you were freaking out, here are some of the things you might do:
- Stop giving OpenAI money (They received 30M from OpenPhil in 2017)
- Stop endorsing non-safety jobs at OpenAI (They're prominent on the 80k job board with several recent postings)
Or, if you were really serious (read: cared at all), you might:
- Organize Microsoft employees to stop funding OpenAI, and to stop offering them compute resources (this isn't outlandish, Google employees have successfully organized against military contracts, right-wing apps are denied hosting)
- Organize other AI orgs to commit to refusing to hire anyone still working at OpenAI in a non-safety role after January 2022
To be clear, I'm not advocating any of this. I'm asking why you aren't. I'm seriously curious and want to understand which part of my mental model of the situation is broken. Is it that you're confident the Holden Karnofsky board seat will be enough to hold everything together, even as the actual safety researchers flee? Or is it that you don't want to antagonize our new overlords? Is it that I'm out of touch, missing recent news, and OpenAI has recently convincingly demonstrated their ongoing commitment to safety?
–––
For what it's worth, on Yudkowsky's original point about Musk, you might feel comforted by the fact that Musk was eventually removed from the board due to conflicts of interest after hiring away OpenAI researcher Andrej Karpathy. That's somewhat fair, except that Shivon Zilis still sits on the board, is simultaneously a Director at Neuralink, and was previously "Project Director, Office of the CEO" at Tesla.

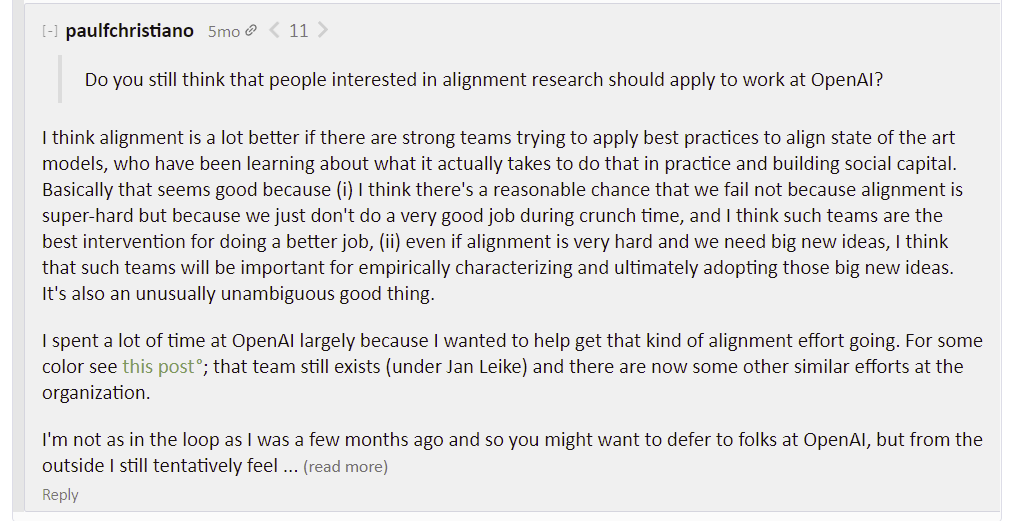

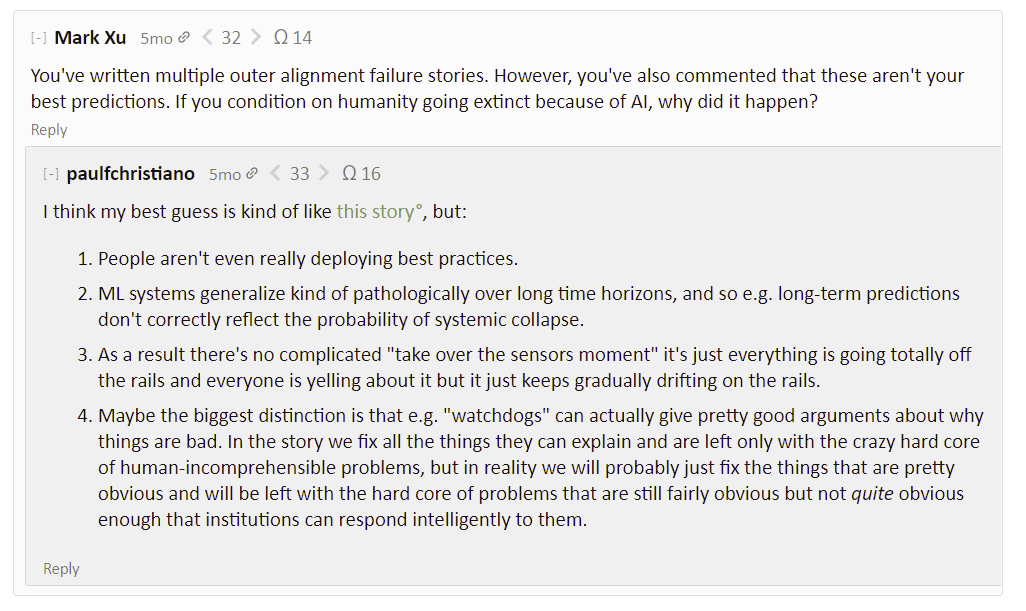
I also noticed this post. It could be that OpenAI is more safety-conscious than the ML mainstream. That might not be safety-conscious enough. But it seems like something to be mindful of if we're tempted to criticize them more than we criticize the less-safety-conscious ML mainstream (e.g. does Google Brain have any sort of safety team at all? Last I checked they publish way more papers than OpenAI. Then again, I suppose Google Brain doesn't brand themselves as trying to discover AGI--but I'm also not sure how correlated a "trying to discover AGI" bra... (read more)