This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Extraordinary advances in AI capabilities have brought concerns about their potential to exacerbate biorisk to the center of public debate, with tech CEOs, AI scientists, biologists, and politicians all sounding the alarm.
But what can major AI companies actually do to reduce these risks?
In this post, I outline a basic “playbook” of safeguards AI companies can pursue to reduce biorisk from their models. Many companies are already pursuing some form of these safeguards, but with mixed seriousness and outcomes; some companies are doing little of anything in this direction. Before getting to the playbook itself, I want to briefly lay out why I think this matters in the first place.
A basic case for taking AI biorisk seriously
There are two main ways AI could exacerbate biorisk:
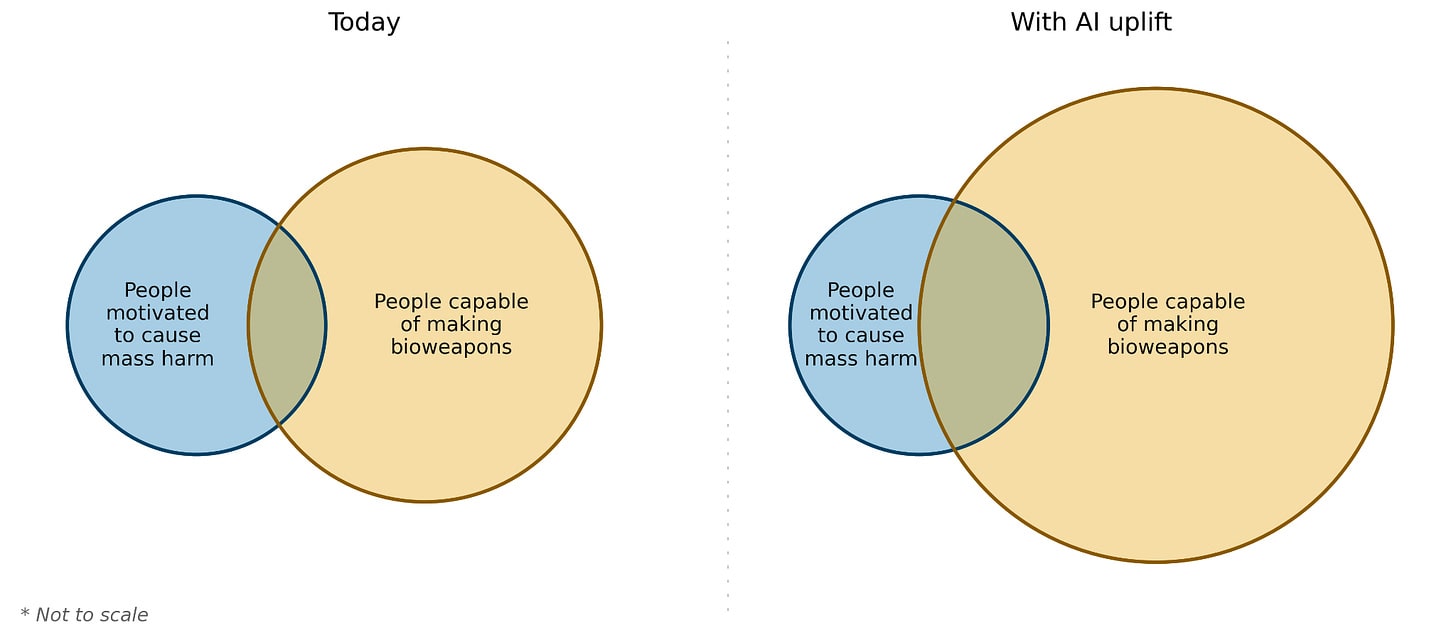
Increasing the number of people capable of causing harm with biology.
Society inevitably has to deal with some base rate of deranged individuals, omnicidal cults, and rogue states who may seek to cause mass harm. Biology, as the recent pandemic demonstrated, can be a very effective means by which to cause mass harm. As biology becomes easier to engineer and understand, we may face a growing overlap between those motivated and capable of using biology for this malevolent purpose.
Increasing the ceiling of harm enabled by biological weapons.
Today, there are few, if any, credibly pandemic-capable pathogens known to science that an adversary could acquire, and these are primarily limited to historical pathogens where population immunity has waned. But nature need not be the most capable bioterrorist, and there is reason to be concerned that AI could uplift already expert or well-resourced actors, allowing them to design particularly severe or hard-to-detect threats.
These risks will grow as models become more capable, but I think we should already be concerned about the current level of risks. In silico biosecurity benchmarks suggest that AI models are highly capable at virology, with models outperforming 94% of expert virologists within their areas of specialization. Novices with LLMs performing 4x better on biosecurity relevant tasks than novices with only internet access. And on sequence design — a task closer to actually engineering biology than answering exam questions — Anthropic's Claude Mythos Preview is apparently “indistinguishable from the best performing humans.” Wet lab uplift evidence is more mixed, but the measurement science here is still nascent, and I’d bet against the durability of so-called tacit knowledge barriers, especially as AI becomes moreembodied.
Ultimately, if you believe the claims that AI will transform the life sciences (as I and many others do), then you should also take seriously the idea that these gains will be dual-use. We’re not going to magically get all the benefits of AI-supercharged life sciences without any of the downside risk.
What can AI companies do?
There are a number of levers available to AI companies for reducing biorisk from their models.[1]
AI models should refuse to divulge information that unduly enables bioweapons creation.
Pretty much every AI company has refusal standards for a whole host of things, ranging from NSFW content to self-harm material, and instructions for creating explosives and chemical weapons. Bioweapons are no different in this regard.
Refusals are implemented primarily through training.[2] During training, models are shown examples of harmful prompts paired with refusal responses and steered toward the desired behavior via reinforcement learning from human feedback (RLHF) and its descendants, including Constitutional AI (where the training signal comes from AI feedback graded against a written set of principles rather than direct human feedback).
These principles reflect how companies want their models to behave. Anthropic’s constitution includes statements like “[don’t] generate content that would provide real uplift to people causing significant loss of life, e.g., those seeking to synthesize... bioweapons.” OpenAI “Model Spec” similarly states that its models “should not provide detailed, actionable steps for carrying out activities that are illicit [including] any steps related to creating, obtaining, magnifying, or deploying biological weapons.” The harder part is actually training models to behave this way when users try to get around the rules — i.e., under jailbreaking and other adversarial pressure. For refusals to be effective, they can’t be easy to get around, but currently, sufficiently motivated actors can very often bypass these defenses.
Still, refusals are an effective first line of defense, and developing an effective biorisk refusal policy should be a key priority for every company. This policy should be grounded in a sharp sense of what’s actually dangerous (i.e., threat modeling) and backed up with the appropriate training and evaluation data. It should be as narrowly tailored as possible, so as to avoid needlessly restricting researchers working on entirely benign problems in biology, but nevertheless broad enough to restrict information on particular pathogens, techniques, and ideation behind developing bioweapons. These refusal policies could extend to specific nucleotide or protein sequences of concern as well as agentic tool calls to dual-use biomodels.
There will inevitably be disagreement on where exactly to draw these boundaries; I favor erring on the side of caution and restricting too much rather than too little, especially for basic access tiers (more on tiered access below). Ultimately, virology and other specific bioweapons-relevant areas of biology are often niche enough that these refusals should affect a very small fraction of users.
Even with these refusals, models will remain useful for some bioweapons-relevant uplift, like general lab methods and other knowledge inputs, but I think that is okay. The focus should be on restricting access to knowledge that is especially high leverage for bioweapons development.
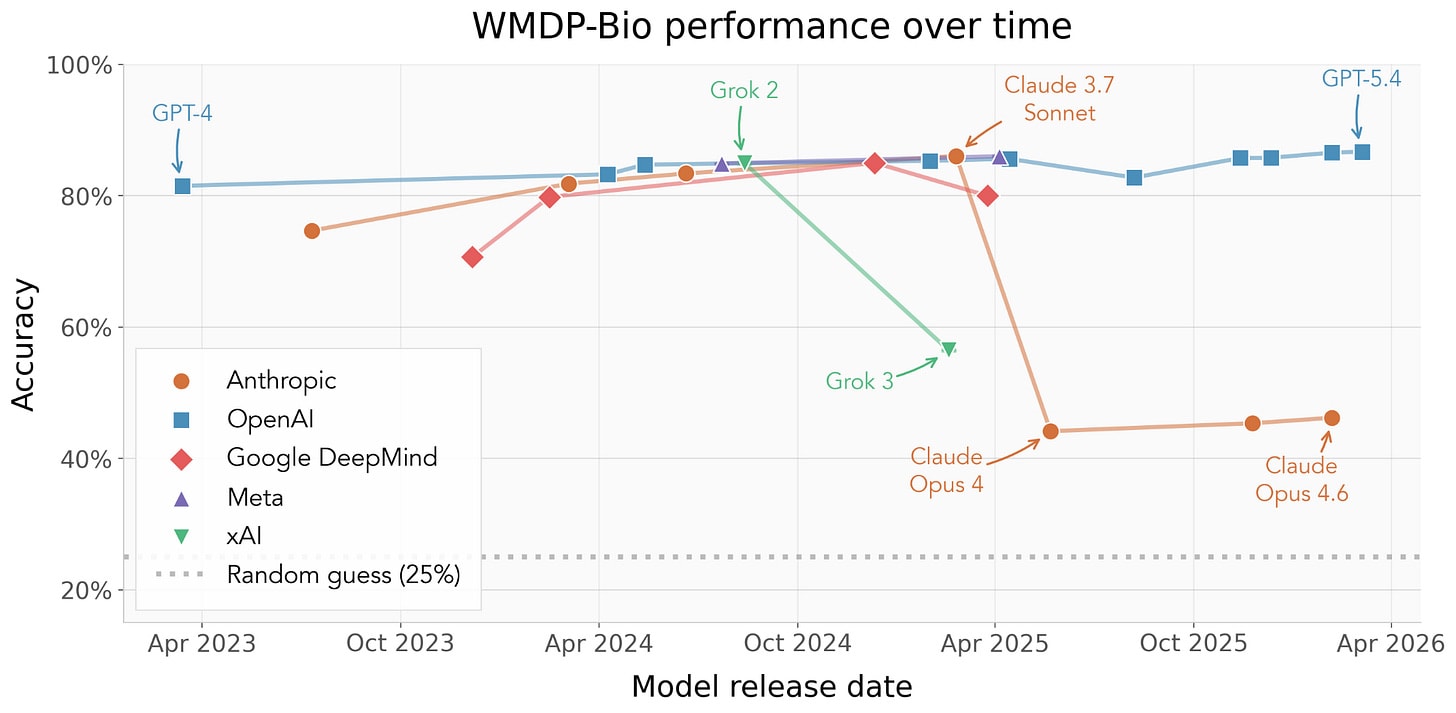
Performance trends in existing biosecurity benchmarks already show some signs of refusals making an impact. Take for instance the performance of Claude and Grok on WMDP Bio. While this benchmark is far from perfect, it does measure some relevant signal on how models perform on dual-use tasks, and later model generations have gotten worse at this benchmark over time.
WMDP-Bio accuracy over time by AI company. Points show mean accuracy across three runs for models following the evaluation methodology described in Justen 2025.
Classifiers for malicious use
The same policy that tells a model what to refuse can be used as a policy for what kind of usage patterns should be monitored for malicious use.
Most companies have some kind of classifier model (or models) that run behind the scene and flagging conversations or users for malicious use, including for biology. A good classifier is also a second line of defense against jailbreaks, potentially able to flag users who are able to evade refusal safeguards.
This kind of monitoring can be expensive, both in terms of inference compute as well as follow up. In his essay “The Adolescence of Technology,” Dario Amodei (CEO of Anthropic) indicated that bioweapons classifiers constitute around 5% of total inference costs, while OpenAI has stated that their total compute dedicated to safety reasoning can reach as high as 16% during the roll out of a new model. That’s a lot of resources to set aside for safety, and I commend companies doing this despite their many incentives to spend compute elsewhere.
But detection is only the first step. Some companies also have dedicated investigative teams that follow up on flagged users or chats. Anthropic and OpenAI in particular have publicly reported their efforts to disrupt people from using their models for cyber-crime, influence operations, and espionage, and some companies hire dedicated staff to investigate bio misuse. However, for these kinds of investigations to go well, companies will need to do more than just ban the relevant accounts. They also need a clear escalation policy and strong relationships with relevant law enforcement agencies – something that’s easy to neglect when really concerning events happen only rarely.
Similar reporting challenges exist in other areas of biosecurity. In DNA synthesis screening, where the goal is to prevent malicious actors from obtaining dangerous pathogen DNA, the 2023 HHS screening framework “strongly encourages” providers to contact their nearest FBI Field Office’s WMD Coordinator when concerns arise. But in practice, very few providers have established protocols for actually doing this kind of escalation. AI companies should avoid these known pitfalls, and work to preemptively establish and exercise these relationships, potentially in partnership with other AI companies, so that any necessary escalation can be swift and effective.
The knowledge that companies operate these classifiers and may log[3] and report suspicious interactions may also deter bad actors (or at least push them to using less capable alternatives).
All of this — classifiers, investigative staff, escalation policies, law enforcement relationships — costs money and attention. But I think it’s reasonable to expect AI companies to dedicate resources to this kind of thing. It’s also why some have pushed for AI companies to face legal liability when people use their models to cause harm to themselves or others. In the current race-to-AGI dynamic, it’s easy to cut corners on safety when you think that’s what your competitors are doing, and we’ll need to find ways to avoid the worst outcomes of this race to the bottom dynamic.
Tiered access and know-your-customer screening
Another approach to making models safer against biological misuse to have tiered access systems and know your customer (KYC) screening.
Tiered access is the idea that different users should have different levels of access to model intelligence or features. Versions of this already exist today. Different types of paid, unpaid, or enterprise tiers will sometimes gate access to the newest models or features, and companies will sometimes grant pre-release or safeguards-off model access to vetted third-party evaluators and government AI safety institutes. The version of Claude the Department of War wanted is not the same one you will get with your Claude Pro plan.
A compelling example of tiered access is the recent release of Anthropic’s seemingly very powerful Mythos Preview model. Anthropic found that Mythos was so capable at exploiting software vulnerabilities that releasing it publicly would have caused chaos, giving attackers a massive opportunity to compromise almost any software system in the world. So instead of releasing it publicly, Anthropic launched Project Glasswing, an initiative granting roughly 40 vetted organizations (Google, Apple, Microsoft, etc.) exclusive access to the model for defensive security work. While the domain is cyber, there is a similar implicit principle at work here, namely that when a model becomes so powerful that it would radically democratize access to catastrophic levels of offense, it is irresponsible to simply let that model out into the wild without the necessary safeguards in place. The same principle can and should apply to biosecurity.
But as far as I can tell, there’s no precedent for really substantive tiered access programs for biology. Anthropic has an AI for Science programs with a particular focus on biology and life sciences applications that grant free tokens to “qualified researchers,” but this doesn’t seem to provide access to upgraded tiers of Claude performance for biology. Perhaps such an implementation should exist.
With a tiered access model, you can provide legitimate users at pharma companies, universities, and other verified biotech organizations less restricted access to dual-use information, while enforcing stricter requirements for KYC verification or chat monitoring. KYC screening is already commonplace in other industries, especially banking, and there is increasing emphasis on integrating KYC as biosecurity infrastructure, with KYC already implemented as part of some DNA synthesis screening.
Tiered access won’t completely resolve AI-assisted biorisk, since there is always a concern about insiderthreats who may have legitimate credentials but pursue malicious biology applications. But it can drastically reduce the number of actors with baseline access to highly dual-use capabilities, potentially preventing lower-resource, non-institutional actors from becoming more capableterrorists.
Removing bioweapons knowledge
In addition to refusals, classifiers, and tiered access, there may be ways to make models worse at bioweapons tasks at training time.
One approach is pretraining data filtration — simply don’t train on dangerous content in the first place. An August 2025 blog from the Anthropic alignment team showed that you can use classifiers to identify and remove CBRN-related content from training data, and subsequently reduce performance on harmful information while preserving performance on more benign biology tasks. The model cards from OpenAI’s GPT-4o and gpt-oss similarly describe using CBRN classifiers to filter out harmful bioweapons knowledge during pretraining. And work from EleutherAI and the UK AI Security Institute suggests that this kind of dataset filtration can make models substantially more robust against adversarial fine-tuning — a particular challenge for open-source models, where anyone can attempt to undo safety measures after release.
A second approach is machine unlearning, which attempts to remove dangerous knowledge after training by crafting loss functions that reduce performance on hazardous knowledge while maintaining performance on less dual-use tasks. Techniques like Representation Misdirection for Unlearning (RMU) could supplement dataset filtration, but there is someevidence that this knowledge removal process is brittle and can be easily re-learned with fine-tuning. This may be less of a concern for closed-source models served behind an API, but it will continue to make open-source model safety hard.
A third, more recent direction developed by Anthropic is called Selective Gradient Masking (SGTM). SGTM tries to route dangerous knowledge into designated “removable” model parameters during training, which can then be zeroed out afterward. This technique may be more robust to adversarial fine-tuning but doesn’t seem to have been deployed at large scale.
Some of these interventions seem promising, especially for basic access tiers, where models don’t necessarily need to be expert vaccine designers (save that for the tiered access), but they also face some challenges. We all want (and companies are incentivized to develop) models that are as good as they can be on all the genuinely useful and benign biology tasks. Without really strong evaluations, there will be the concern that whatever unlearning or data filtration approaches we apply may make the models worse in some more generalizable way. And as models get more powerful – more and more capable of filling in the web of truth beyond their training data – it’s unclear how robust these approaches will be. Simply trying to carve out or obscure small niches in this web of truth may just be too brittle an approach.
First and foremost, evaluations help us understand where biological capabilities are heading. Tracking model performance on biosecurity-relevant tasks over time gives AI companies, policymakers, and the biosecurity community advance warning of when models may cross dangerous capability thresholds, giving everyone a bit more time to plan.
Evaluations and capability thresholds can also be tied to specific actions of companies and regulators. Almost all of the big AI companies have some version of a frontier AI safety policy, which outlines certain capability thresholds, including for biosecurity, at which corresponding security tiers are activated. While these thresholds vary in their specificity and have sometimes become less concrete over time, both OpenAI and Anthropic have recently activated higher biosecurity tiers for their latest models – Anthropic activated its ASL-3 protections for Claude Opus 4, and OpenAI has precautionarily treated recent launches as “high capability“ in the biological domain. On the government side, California’s SB 53 now requires large AI developers to publicly define their capability thresholds for catastrophic risk — including biological weapons assistance — and describe their mitigation strategies. The EU AI Act’s Code of Practice similarly requires providers of the most advanced models to assess and mitigate CBRN risks specifically, define pre-specified “systemic risk tiers” with measurable criteria based on model capabilities, and report results to the EU AI Office.
But evaluations shouldn’t just be companies grading their own homework. Independent third-party evaluators help ensure that capability assessments are credible and not shaped by commercial incentives. Organizations like METR and SecureBio both develop and conduct capability evaluations that are cited in model cards from multiple companies. Both the U.S. Center for AI Standards and Innovation (CAISI; housed within NIST) and the UK AI Security Institute have signed agreements with OpenAI and Anthropic granting pre-release access to frontier models for testing — meaning independent government evaluators can assess biosecurity risks before models reach the public if they have sufficient time. By funding third-party evaluators, sharing evaluation methodologies, granting pre-release model access with sufficient time for safety testing, and transparently reporting results, AI companies can (and do) support better collective decision making — and they should do more of it.
Finally, evaluations help strengthen and assess all of the other safeguards. Nearly every safeguard I outlined above benefits from — or even requires — test datasets to measure and steer its effectiveness. Refusal datasets tell you whether your refusal policies are actually declining the queries you want them to decline. Examples of suspicious chats let you benchmark your classifiers. Virology benchmarks reveal whether your approach to removing dangerous biology knowledge actually worked. Building high-quality evaluations like this is not easy, but it’s necessary to give us confidence that our risk mitigation interventions are doing what we think they’re doing, and to help us improve them.
Conclusion
Some of the policies in this checklist may seem restrictive or antithetical to the free exchange of knowledge. I’m sympathetic to that concern. Biology will need to play a central role in addressing some of the foundational challenges facing the world, from health to aging to environmental stewardship. Given how many more people are pursuing beneficial and defensive applications of biology than harmful ones, we should seek to empower them, including with access to powerful AI. But in select cases, where proliferation of knowledge could substantially increase the risk of catastrophic harm, even staunchly democratic societies can and do restrict access. We accept that the blueprints for nuclear weapons should not be broadcast to the world. The blueprints for pandemics shouldn’t be either. The challenge is that biological knowledge is far more entangled with beneficial applications than nuclear weapons design ever was, and arguably the field of biology has yet to fully grapple with the destructive potential of deliberately designed biological weapons in the same way that physics was forced to confront its contributions to nuclear weapons after World War II. Given the benefits and harms at stake, safeguards will need to be well-designed and specific about what to restrict, how, and for whom.
Throughout this piece, I’ve most often cited Anthropic and OpenAI, including for their shortcomings. That’s partly a selection effect — these companies are doing the most visible work in this space, and therefore have the most to critique and celebrate. But while even they have significant room to grow, and the broader field, including Google, Meta, xAI, and the growing number of companies releasing powerful open-source models, has much further to go. Open-source models deserve special mention here. Nearly every safeguard I’ve described is harder or impossible to enforce when model weights are publicly available, and this challenge remains largely unsolved.
Successfully mitigating the most catastrophic AI-enabled biorisk while still accelerating the beneficial applications of AI to biology is not the default trajectory. In some cases, it will require shaping the incentives of companies with smart regulation, and in others it will require individuals at AI companies to break out of their specific incentive structures and lead on these issues. That leadership should extend towards making societies more resilient against biological threats, not just reducing the offensive potential of models. Some, like OpenAI through the OpenAI Foundation, are already investing in biological defenses, which I commend. I urge the entire field to become far more ambitious in these efforts, including in areas like early warning, environmental controls against airborne transmission, and PPE.
The playbook for mitigating frontier AI biosecurity risk is sure to evolve with the technology. But in its current form, it’s not that long, and it feels quite tractable, provided the appropriate level of seriousness is applied.
By "AI companies," I mean primarily those working on highly general systems (OpenAI, Anthropic, Google, Meta, xAI, and the like) rather than companies building specialized biological models. Some of the same interventions apply to the latter, but the threat surface is different enough that I'll save them for a future post.
There is also a refusal approach called “circuit breaking” that operates on models internal representations, and tries rerouting activations associated with harmful outputs into incoherent space before the model can complete the generation.