Comments
Prior knowledge elicitation: The past, present, and future [review paper 2023]

Cost-effectiveness estimates typically use a Bayesian modeling approach: make informed guesses about some key variables and use them to compute costs and effects assuming a causal model. In EA we seem to be influenced quite a bit by the science of forecasting when making these informed guesses, and also influenced (to a lesser extent) by the literature of risk analysis and Bayesian modeling. This paper came up in my search for more information about designing better modeling environments and practices.
Below, I'm pasting some key quotes and figures from the paper.
[emphasis mine]
Specification of the prior distribution for a Bayesian model is a central part of the Bayesian workflow for data analysis, but it is often difficult even for statistical experts. In principle, prior elicitation transforms domain knowledge of various kinds into well-defined prior distributions, and offers a solution to the prior specification problem. In practice, however, we are still fairly far from having usable prior elicitation tools that could significantly influence the way we build probabilistic models in academia and industry. We lack elicitation methods that integrate well into the Bayesian workflow and perform elicitation efficiently in terms of costs of time and effort. We even lack a comprehensive theoretical framework for understanding different facets of the prior elicitation problem.
Why are we not widely using prior elicitation? We analyse the state of the art by identifying a range of key aspects of prior knowledge elicitation, from properties of the modelling task and the nature of the priors to the form of interaction with the expert. The existing prior elicitation literature is reviewed and categorized in these terms. This allows recognizing under-studied directions in prior elicitation research, finally leading to a proposal of several new avenues to improve prior elicitation methodology.
As briefly mentioned in the Introduction, we believe the reasons for limited use of prior elicitation are multifaceted and highly interconnected. We believe the three primary reasons, all of approximately equal importance, are:
- Technical: We do not know how to design accurate, computationally efficient, and general methods for eliciting priors for arbitrary models.
- Practical: We lack good tools for elicitation that would integrate seamlessly to the modelling workflow, and the cost of evaluating elicitation methods is high.
- Societal: We lack convincing examples of prior elicitation success stories, needed for attracting more researchers and resources.
The authors suggest to break down the relevant aspects of prior elicitation into the following seven dimensions:
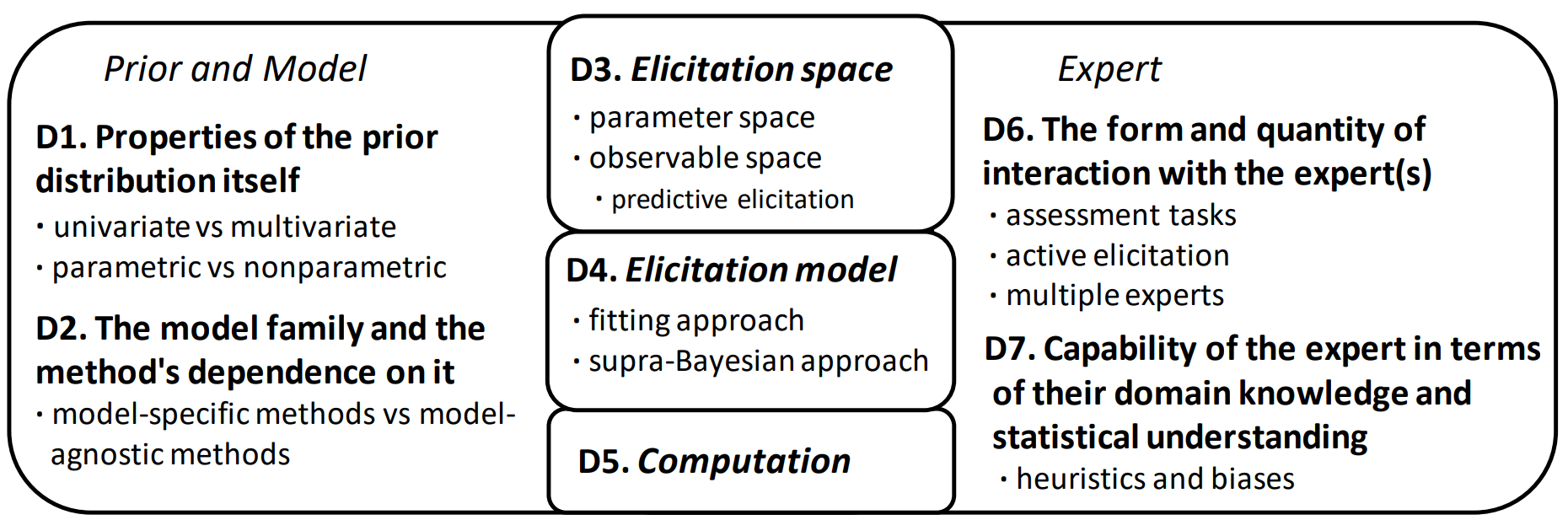
- We need to focus on elicitation matters that answer to the needs of practical modelling workflow. Compared to past research, the efforts should be re-directed more towards (a) elicitation methods that are agnostic of the model and prior, (b) elicitation strategies (e.g. active elicitation) that are efficient from the perspective of the modeller and compatible with iterative model-building, and (c) formulations that make elicitation of multivariate priors easier, for instance by designing hierarchical priors that are simpler to elicit.
- We need better open software that integrates seamlessly into the current modelling workflow, and that is sufficiently modular so that new elicitation algorithms can be quickly taken into use and evaluated in concrete modelling cases. The elements not specific to elicitation algorithms (e.g. visualization of the priors, the language used for specifying the models and desired prior families) should be implemented using existing libraries whenever possible, and the tools should be open source.
- We need cost-efficient and well-targeted evaluation techniques for supporting development of new methods and validating their relative quality and value in practical tasks. In ideal case, we would like to see a testbed for prior elicitation techniques that enable easy evaluation of alternative methods in varying situations with feasible experimentation cost, as well as practical ways of collecting information about efficiency of elicitation methods in real use cases.
- We need spearhead examples that clearly demonstrate the value of prior elicitation in applications of societal interest to increase enthusiasm beyond the current niche. These examples need to be ones where use of subjective prior knowledge is useful without a doubt and additionally prior elicitation either improves the value of the model over carefully crafted priors or results in clear cost reductions or improved robustness via a more efficient process (e.g. for cases where the priors need to be specified repeatedly or for several parallel cases).

Seems like this was first published in 2021 but revised in 2023