I downvoted this because I noticed a few errors in the technical areas, but I'm potentially excited about posts about AI safety written at this level of accessibility.
What needs to be understood is that as the scale of the powers available to us grows, the room for error shrinks. The downside of safety procedures is that they lure us in to thinking we can successfully manage such awesome powers to the degree of perfection necessary, forever.
We should have learned this at the time of Hiroshima. What nuclear weapons illustrate so clearly is that with powers of this scale successful management most of the time is no longer sufficient, because when any power reaches a large enough level one bad day can be all it takes to bring down the entire system.
Given that we've proven incapable of understanding this in the seventy years since Hiroshima, it's not likely we will learn it in regards to other emerging technologies of vast scale such as AI, genetic engineering etc. What seems more likely is that we will continue to insist on acquiring ever greater powers at an ever accelerating rate until, by some method or another, we crash land in to that one bad day.
Human beings are not capable of successfully managing ever more power at an ever accelerating rate without limit forever. Here's why. We are not gods.
I agree with what you've said about how AI safety principles could give us a false sense of security. Risk compensation theory has shown how we reduce our cautiousness with several technologies when we think we've created more safety mechanisms.
I also agree with what you've said about how it's likely that we'll continue to develop more and more technological capabilities, even if this is dangerous. That seems pretty reasonable given the complex economic system that funds these technologies.
That said, I don't agree with the dystopian/doomsday connotation of some of your words: "Given that we've proven incapable of understanding this in the seventy years since Hiroshima, it's not likely we will learn it" or "Human beings are not capable of successfully managing ever more power at an ever accelerating rate without limit forever. Here's why. We are not gods."
In particular, I don't believe that communicating with such tones has very useful implications. Compared to more specific analysis (for example) of the safety benefits vs. risk compensation cost of particular AI safety techniques.
Respectfully, I believe that facts and evidence support a doomsday scenario. As example, every human civilization ever created has eventually collapsed. Anyone proposing this won't happen to our current civilization too would bear a very heavy burden.
The accelerating knowledge explosion we're experiencing is built upon the assumption that human beings can manage any amount of knowledge and power delivered at any rate. This is an extremely ambitious claim, especially when we reflect on the thousands of massive hydrogen bombs we currently have aimed down our own throats.
To find optimism in this view we have to shift our focus to much longer time scales. What I see coming is similar to what happened to the Roman Empire. That empire collapsed from it's own internal contradictions, a period of darkness followed, and then a new more advanced civilization emerged from the ashes.
Apologies, I really have no complaint with your article, which seems very intelligently presented. But I will admit I believe your focus to be too narrow. That is debatable of course, and counter challenges are sincerely welcomed.
Again, I agree with you regarding the reality that every civilisation has eventually collapsed. I personally also agree that it doesn't currently seem likely that our 'modern globalised' civilisation won't collapse, though I'm no expert on the matter.
I have no particular insight about how comparable the collapse of the Roman Empire is to the coming decades of human existence.
I agree that amidst all the existential threats to humankind, the content of this article is quite narrow.
Apologies, it's really not my intent to hijack your thread. I do hope that others will engage you on the subject you've outlined in your article. I agree I should probably write my own article about my own interests.
I can't seem to help it. Every time I see an article about managing AI or genetic engineering etc I feel compelled to point out that the attempt to manage such emerging technologies one by one by one is a game of wack-a-mole that we are destined to lose. Not only is the scale of powers involved in these technologies vast, but ever more of them, of ever greater power, will come online at an ever accelerating pace.
What I hope to see more of are articles which address how we might learn to manage the machinery creating all these multiplying threats, the ever accelerating knowledge explosion.
Ok, I'll leave it there, and get to work writing my own articles, which I hope you might challenge in turn.
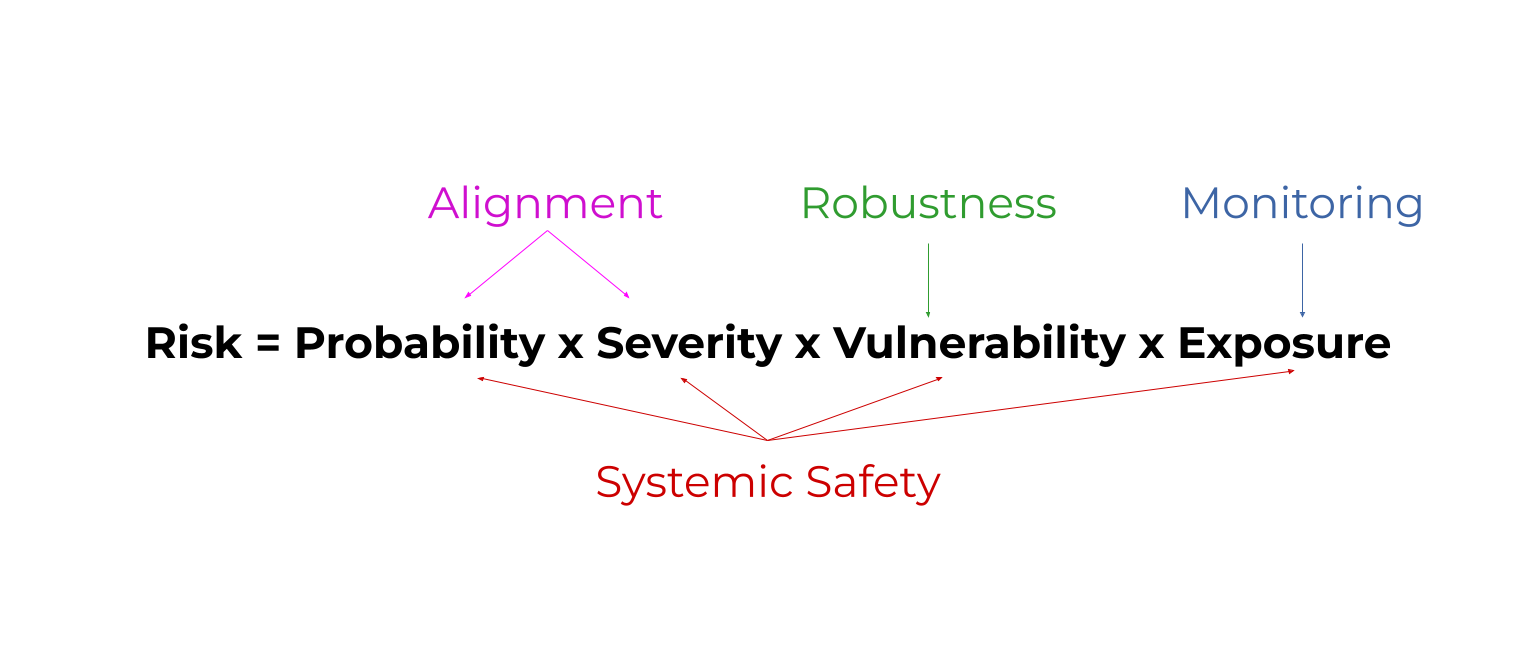
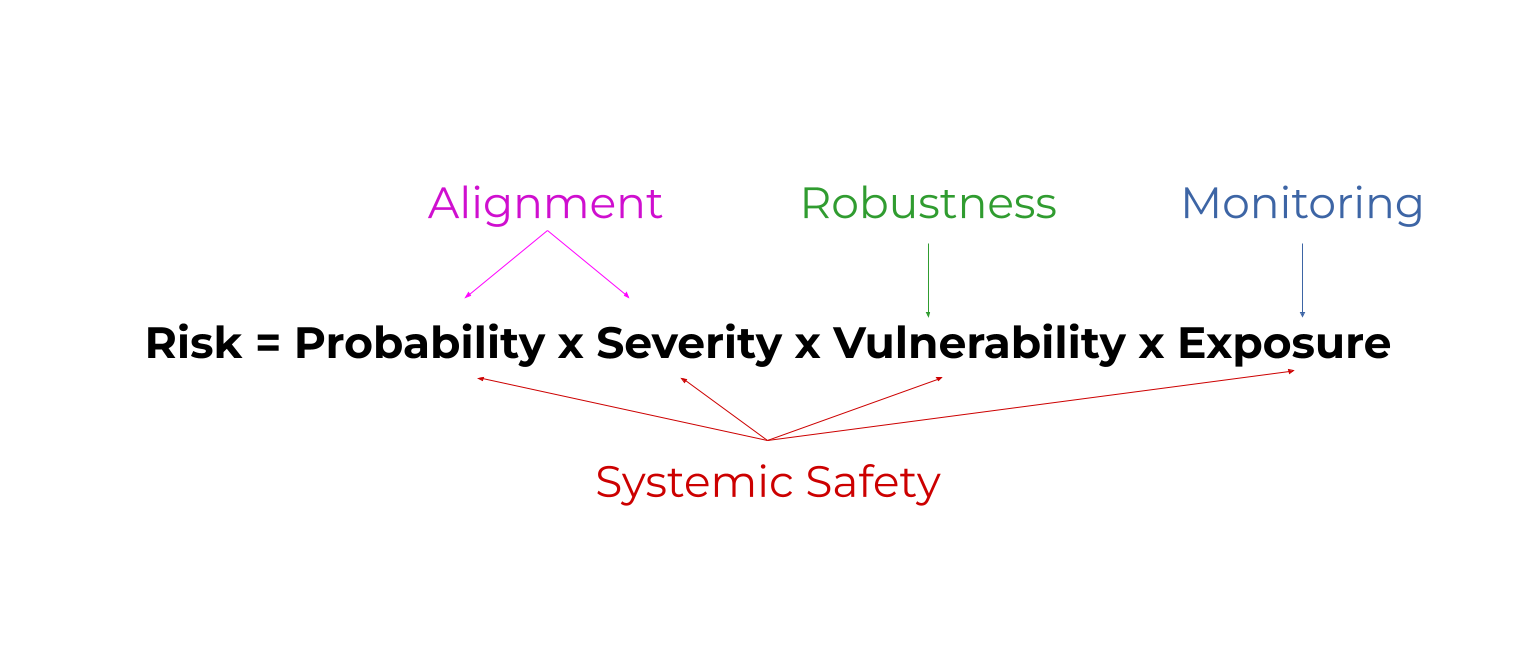
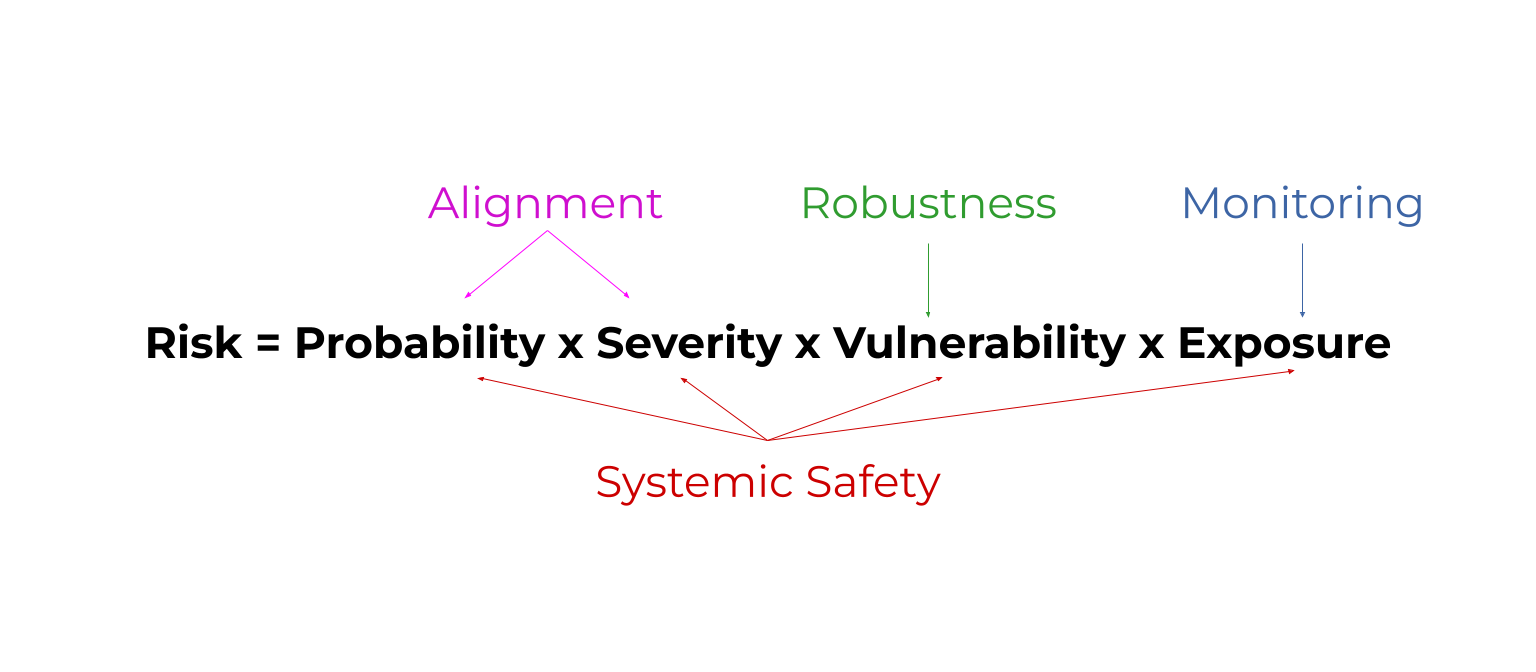
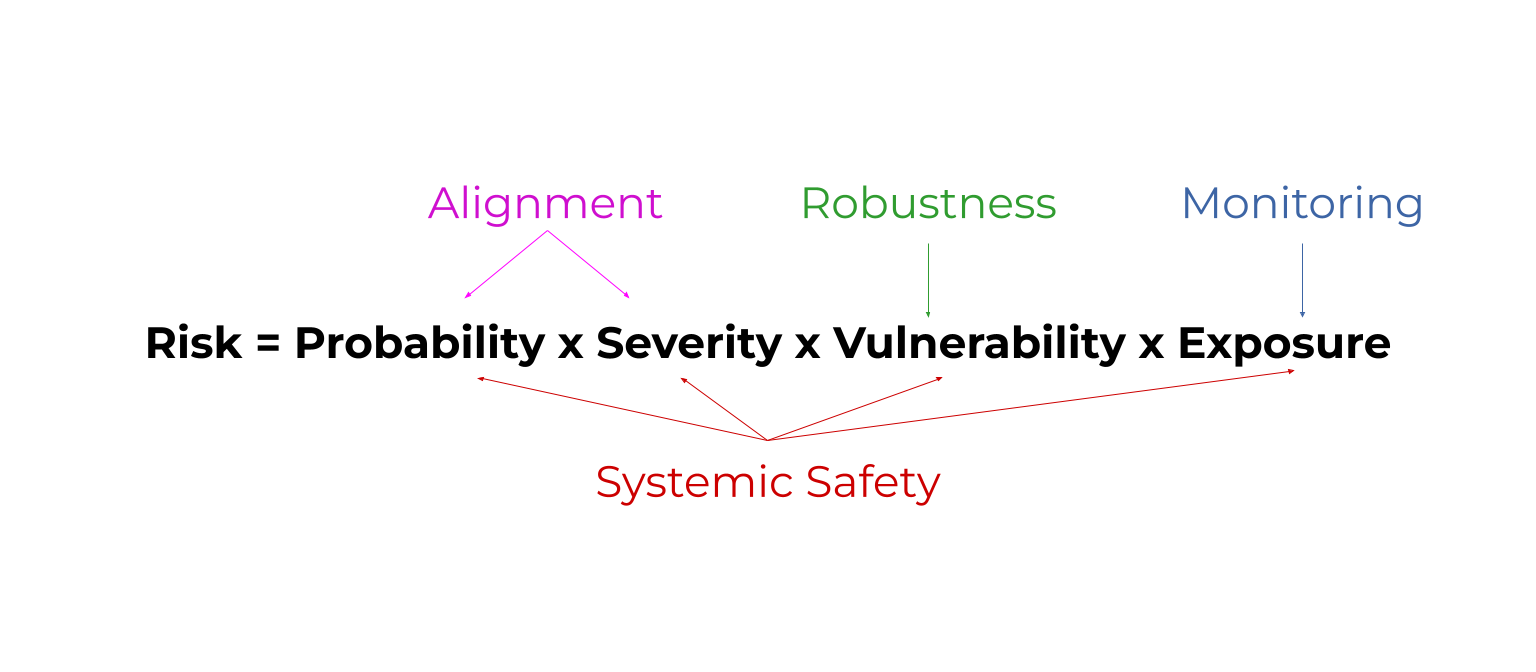
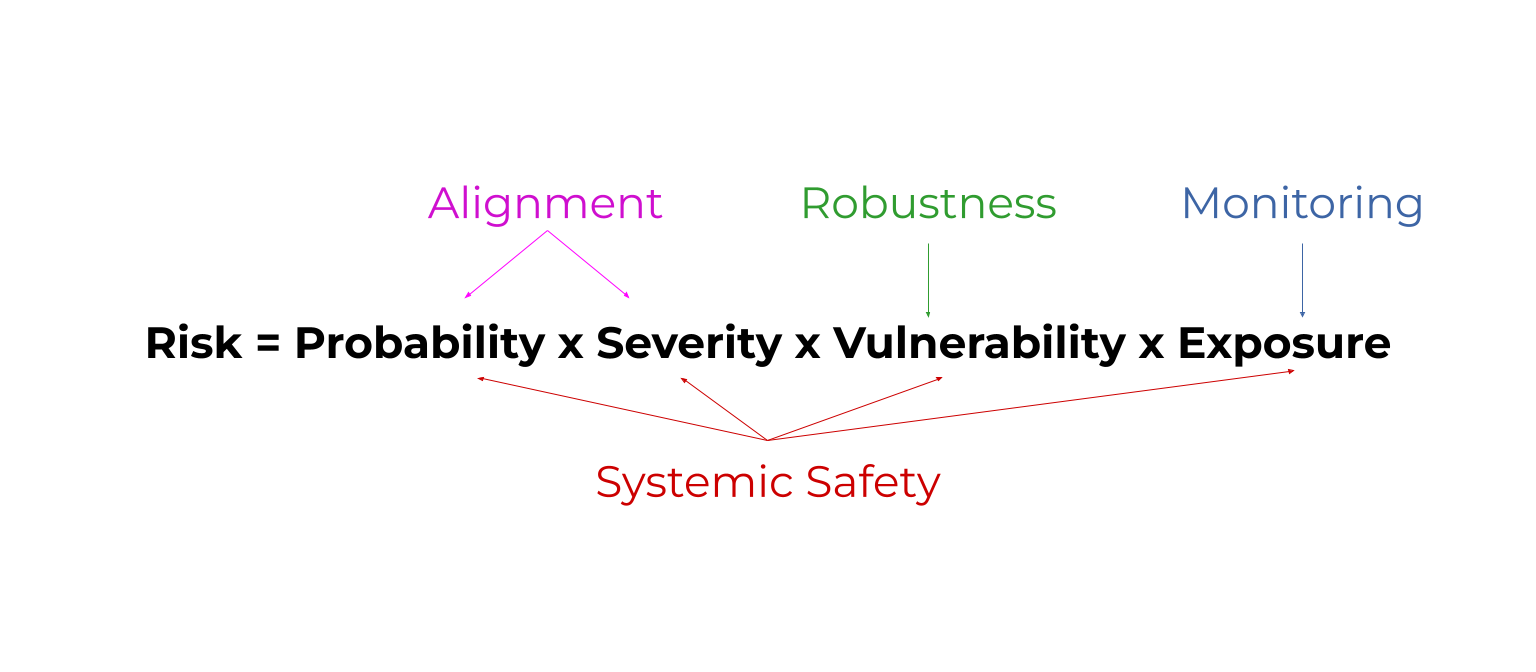
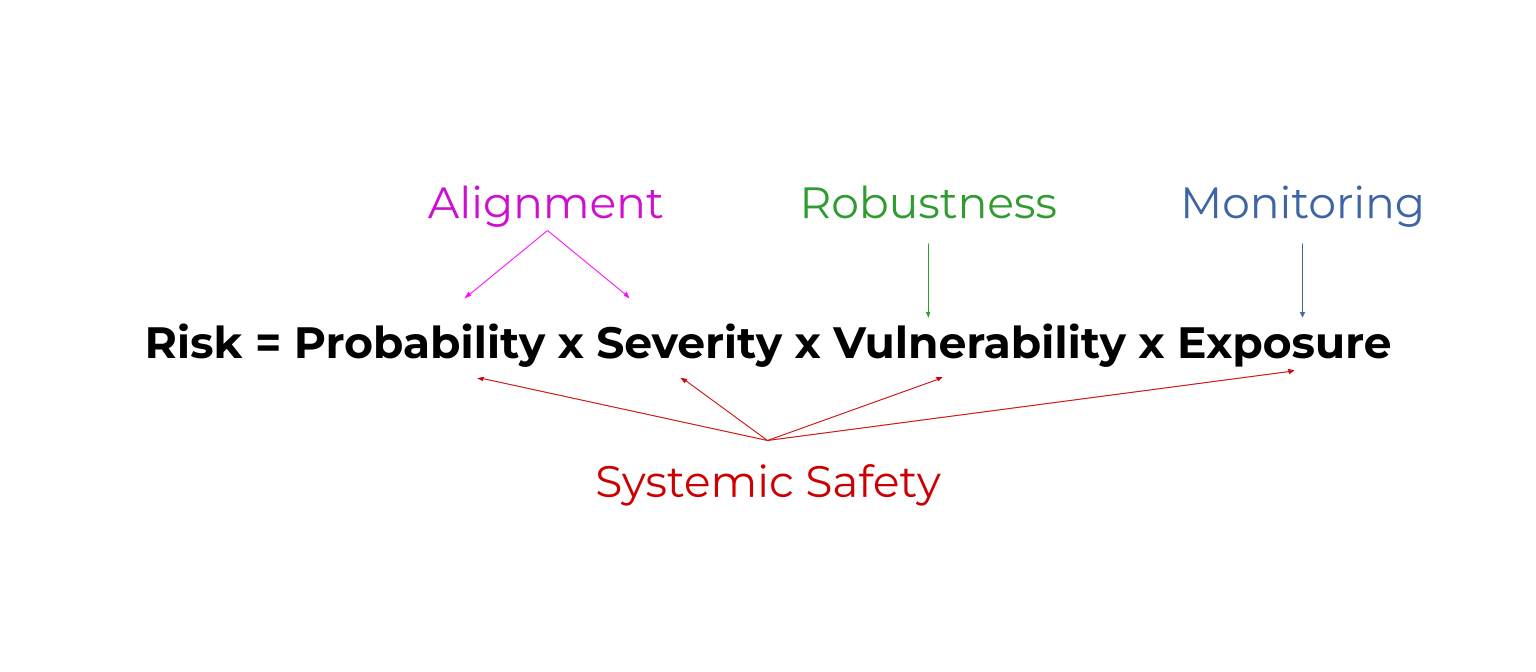
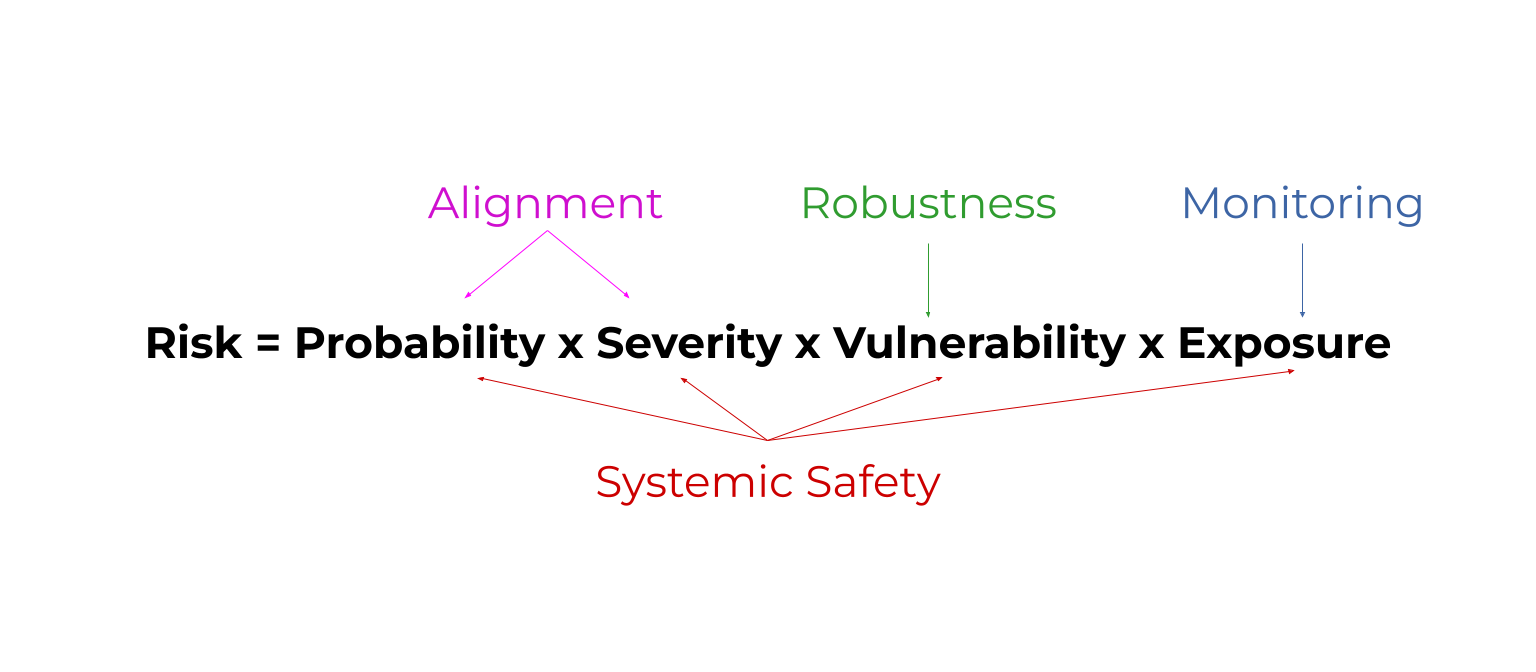
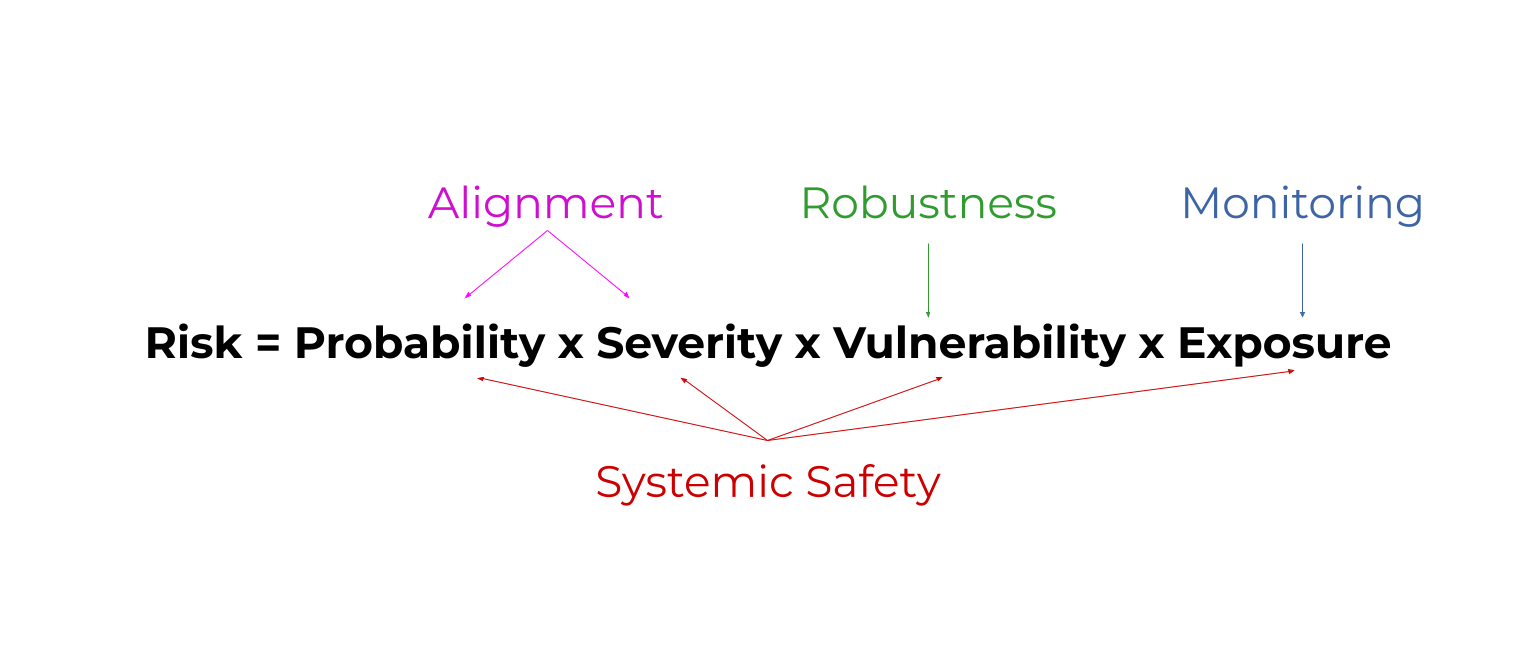
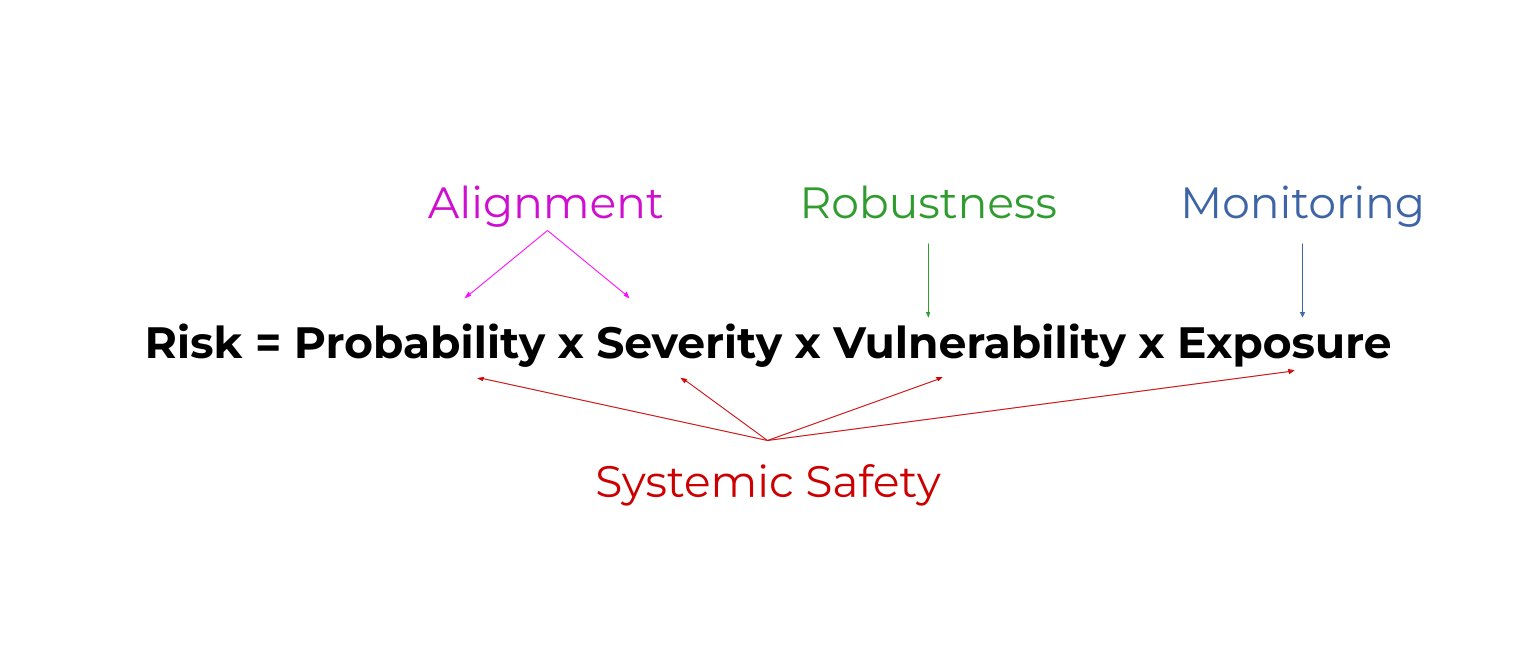
Risk = probability x severity x vulnerability x exposure. (rule of thumb)
This shows that we can improve safety by reducing the probability of bad things, reducing their severity, being prepared to handle their effects, and reducing how exposed we are to them.
Robustness = improve how prepared AI models are to handle unusual conditions. Ex: How well a self driving car reacts to a flooded road.
Monitoring = detect problems with AI models early. Ex: Detecting when AI models have been ‘hacked’.This reduces exposure to problems.
Alignment = make AI models do what we want. Ex: Teach them about human morality by answering philosophy contests. This reduces the probability and severity of problems.
Systemic safety affects all parts of the risk equation. Systemic safety = improve non-technical factors that aren’t coded into an AI model. Ex: Fund AI safety teams well.
Intro
Whenever I read about AI safety, I’m barraged by fantastical terms like: long-tail, systems theoretical, value learning, instrumental proxies, etc. 😵
This makes AI safety seem abstract and sci-fi. But recently, I drudged through the mess of words surrounding it. And I realised something.
AI SAFETY DOESN’T HAVE TO BE SO DARN COMPLICATED!!!! 🤬
It’s possible to explain it simply. Without futuristic sci-fi scenarios that make my head spin.
In fact, AI safety isn’t just for a sci-fi future.
AI safety is something we need RIGHT NOW.
RIGHT NOW, autonomous cars could crash into humans.
We need AI safety for these risks alone. Without even considering speculative existential risks (risks to human existence, like every human dying).
Ex: Making more weapons with AI = an existential risk. Not just autonomous drones like today. Think of AI launching nuclear weapons, AI genetically engineering bioweapons, etc. These existential risks are more speculative and more impactful.
Luckily,
Progress in AI safety can reduce both current risks and existential risks. 🙌
So I won’t discuss existential risk specifically. I want to explain AI safety in simple, tangible ways.
I'll talk about:
Safety Engineering in General
AI Basics
Robustness (preventing failure in unusual conditions)
Monitoring (detecting problems easily)
Alignment (making AI do what we want)
Systemic Safety (things besides the technical programming of AI models)
Safety Engineering
This section isn't about AI specifically. Why reinvent the wheel? Safety engineering for past man-made inventions can help us with AI. So let’s reuse what we’ve learned! (plaigarise 😉)
One of the most important concepts = a ‘rule of thumb’ called the risk equation:
Risk=Probability x Severity x Vulnerability x Exposure
Let me explain that.
Let’s say some bad thing could occur. Ex: a chemical spill at a factory. 🧪 We call this a hazard.
The risk from that hazard can be split into four factors:
The probability of the hazard occurring. Ex: A chemical spill is more likely if workers aren’t trained to move chemicals safely.
The severity of the hazard. Ex: A chemical spill is worse in a chemical weapons factory vs. a paint factory. 😨
Our vulnerability to the hazard. Ex: If workers don't wear protective equipment like gloves, chemical spills are more dangerous.
The exposure to the hazard. Ex: A slightly leaky pipe might go unnoticed and spill chemicals for years. A giant pipe burst might be fixed quickly to reduce exposure.
All areas of AI safety reduce some factor in this risk equation. Here's a diagram as a sneak peak. By the end, you'll know what these mystical words mean. 😅
(Image Source: Me)
One note for now: there is no one single problem/solution in AI safety. Complex safety problems are usually like this. Problems/solutions interact in groups. All these interactions determine whether the entire group is safe.
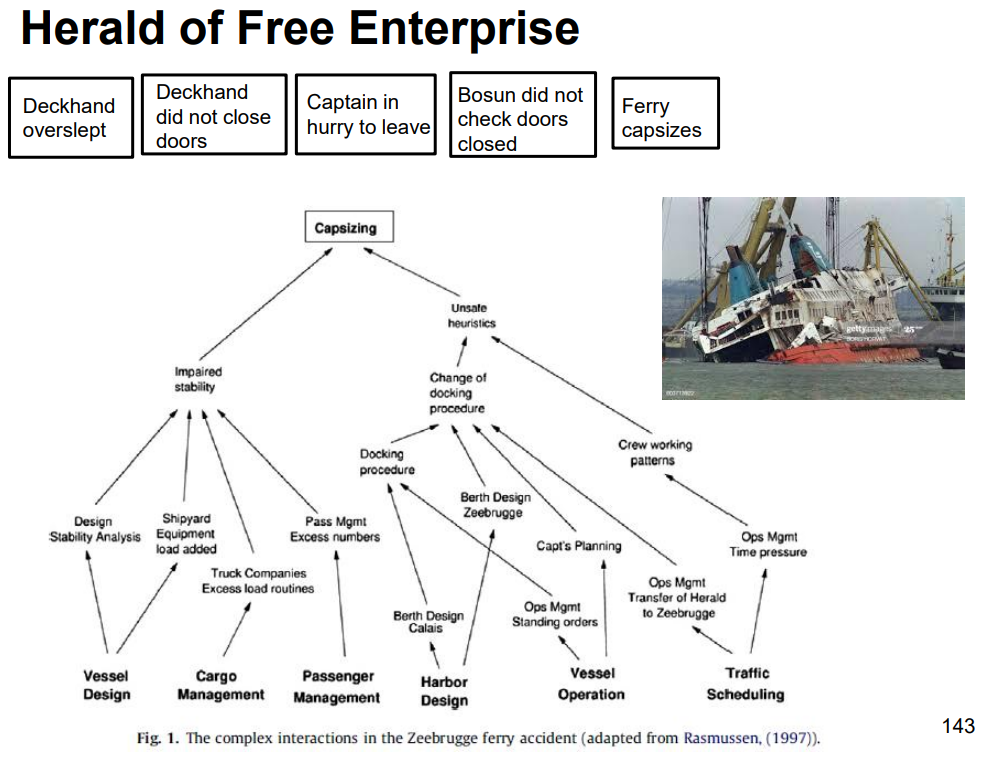
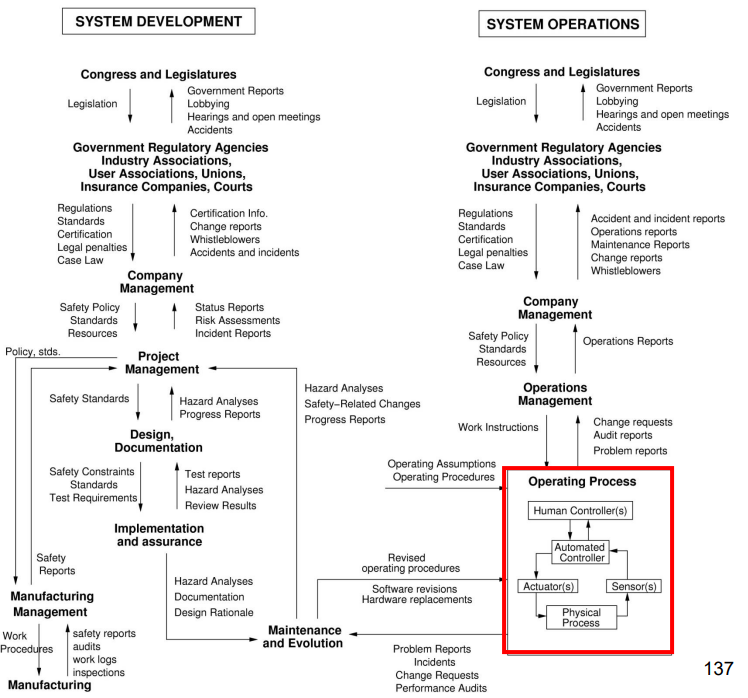
Safety engineers draw diagrams to show how problems/solutions interact. Here’s one showing all the factors before a ship sank (bottom) vs. just 'step-by-step' events (top) 🚢
Considering all the interactions is more 'complete' than just finding 'step-by-step' causes of failure. With 'step-by-step' thinking, poor machine operators often get blamed for safety accidents. 😢
That said, these diagrams can get more complicated too. I’ll link a lecture to explain this giant diagram at the end. 😵
The red box shows the part of making a machine safe that intuitive thinking usually focuses on. (Image Source: Nancy Leveson)
One last concept from safety engineering: best practices for making safe designs. These can be applied from bridges to AI software. 😊
Redundancy - have backups in case of failure. Ex: Have an emergency pipe shut-off valve in case the first valve fails.
Diversification - spread risk from one part to many parts. Ex: Multiple people must approve a missile launch.
Layered defences - have multiple safety tools to stop a hazard. Ex: Employees must use a VPN, multifactor authentication, and a firewall for cybersecurity. 🌐
Transparency - make it easy to understand what's wrong. Ex: Have a see-through computer case so overheated parts are visible.
Access management - don’t give any individual/part more power/permissions than needed. Ex: Restrict access to data in a company drive.
Minimal Dependencies - minimise parts relying directly on each other to stop chain reactions. Ex: Connect train wagons with a deadbolt, not custom hinges. If the coupling is stressed, the deadbolt breaks, not the train wagon. 🚂
Fail safes - minimise damage from failures occurring. Ex: If there's smoke in a server room, lock the room with fire proof doors so the fire doesn’t spread.
Now, let’s apply these ideas to AI specifically!
AI Basics
First, some basics on AI algorithms. Skip this if you're already aware (or if you’re feeling brave 😉)
For everyone else, consider this problem. How can you predict a house's value given its size? Ie. Go from some input (the size in m2) to some output (the price in USD).
(Image Source: Me)
AI algorithms are one way to go from some input to some output. Problems like these are AI's most commonuse. 💪
But what is an AI algorithm? Think of AI algorithms as lots of math equations in a chain.
Ex: one equation takes the input (x) and returns an output (y): y=2x+2.
The next equation takes the last output (y) and returns a new output (z): z=4y+3.
The last step repeats many times (last output to new output).
This is how an input like 50 m2 can turn into $350,000 after a lot of ‘chained’ equations.
But why is the first equation y=2x+2 specifically? Why not y=0.34x+230.43?
An AI algorithm must adjust ‘coefficients’ in a chain of equations to solve problems. These coefficients are called ‘parameters.' They’re like the ‘settings’ of an AI algorithm. It adjusts these settings to accurately turn an input (ex: house size) into an output (ex: house price).
AI algorithms are just numbers in, numbers in the middle (its settings), and numbers out. All the numbers get multiplied or added in equations to go from input to output.
That’s not too hard to understand, right? 😊
One problem: modern AI algorithms have billions (sometimes trillions) of parameters (individual settings to adjust). 😮 AI algorithms are often called ‘black boxes’ - understanding all these settings is really hard.
P.S. People usually say AI models, not AI algorithms. Just know that the largest difference between AI algorithms X and Y = different parameters (settings). Ex: I have an ‘AI model’ with parameters to predict house prices. You have an ‘AI model’ with parameters to predict a car’s fuel efficiency.
Also… about the input: we need a LOT of it! A human could learn to estimate a house’s price with 80% accuracy with a few dozen examples. But AI models usually need thousands to millions of examples! 😮 (Though they might also be more accurate.)
Train data = all this data for AI models to adjust their parameters (settings).
Whereas test data = data that an AI model hasn’t seen before. AI models tend to perform worse with unseen data.
Ex: We train an AI model to predict house prices from house sizes in 2013. But in 2022, we have uber-sustainable cargo container houses. 😎 The AI model won't be confident in predicting this house's value.
P.S. What does it mean for an AI model to be ‘confident’? Well, AI models output confidence and predictions. Ex: They add a probability to their output. An AI model analyses a photo of you and predicts that you’re you with 80% probability. 🙃
P.P.S.. AI models can use images as input! But how can images be input for equations? I can’t tell you because that’d be too long 😅 Same with using audio, video, text, brainwaves, etc. as input. Assume it works via magic for now ✨
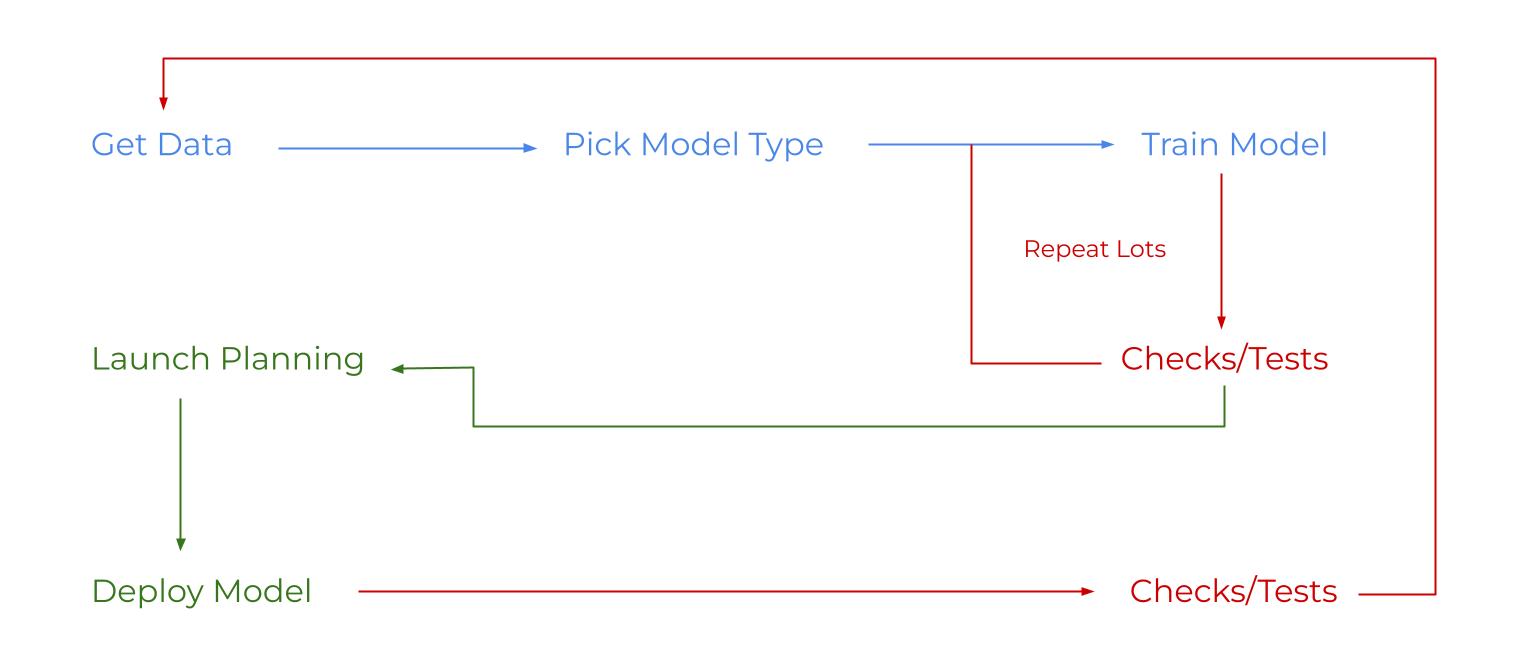
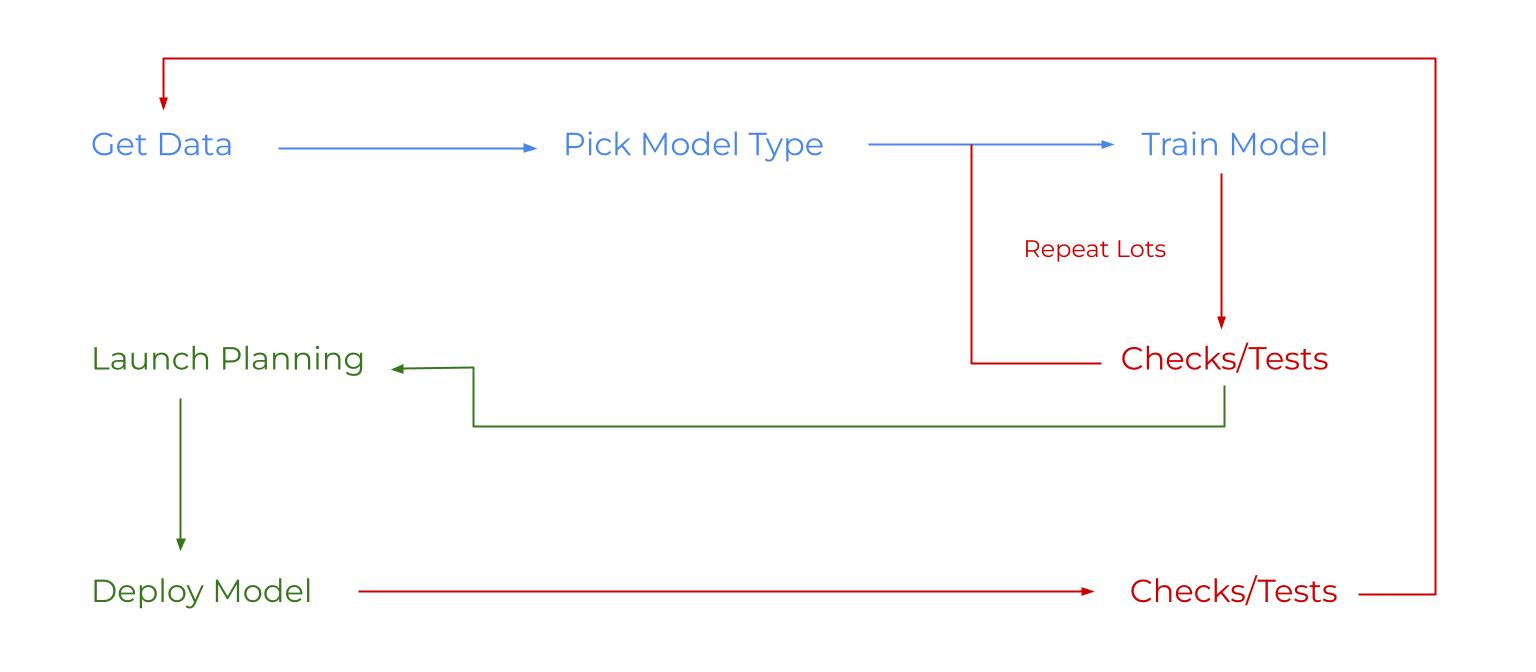
Finally, note the process of making (training) an AI model:
(Image Source: Me)
Blue steps get an AI model to perform well.
P.S. What does ‘pick model type’ mean? The totally accurate definition is programmers making lots of detailed choices about complex things and stuff 🧠👌😁
Red steps check/adjust the AI model’s performance. Note how they loop. Programmers are constantly adjusting their AI models. Even after they deploy the model to people like you and me.
Green steps send an AI model to people like you. Ex: in your car, on your phone, etc. Lots of complicated things and stuff also happen here 😁
Now, we’re on the same page on basic AI jargon (train data, test data, predictions, AI models, and parameters). Let's dive into actual AI safety!
Robustness: preventing AI models from failing in unusual conditions.
This is like reducing vulnerability to unusual conditions.
(Image Source: Me)
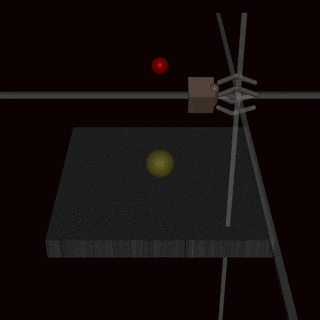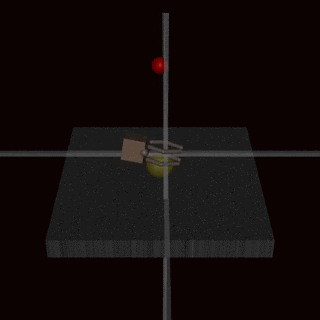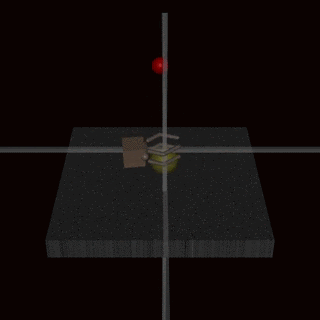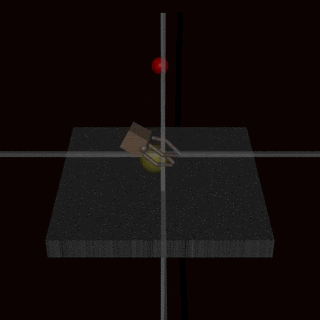
Still, it’s hard to understand theoretically. Let’s look at an example of a self-driving car! 🚗
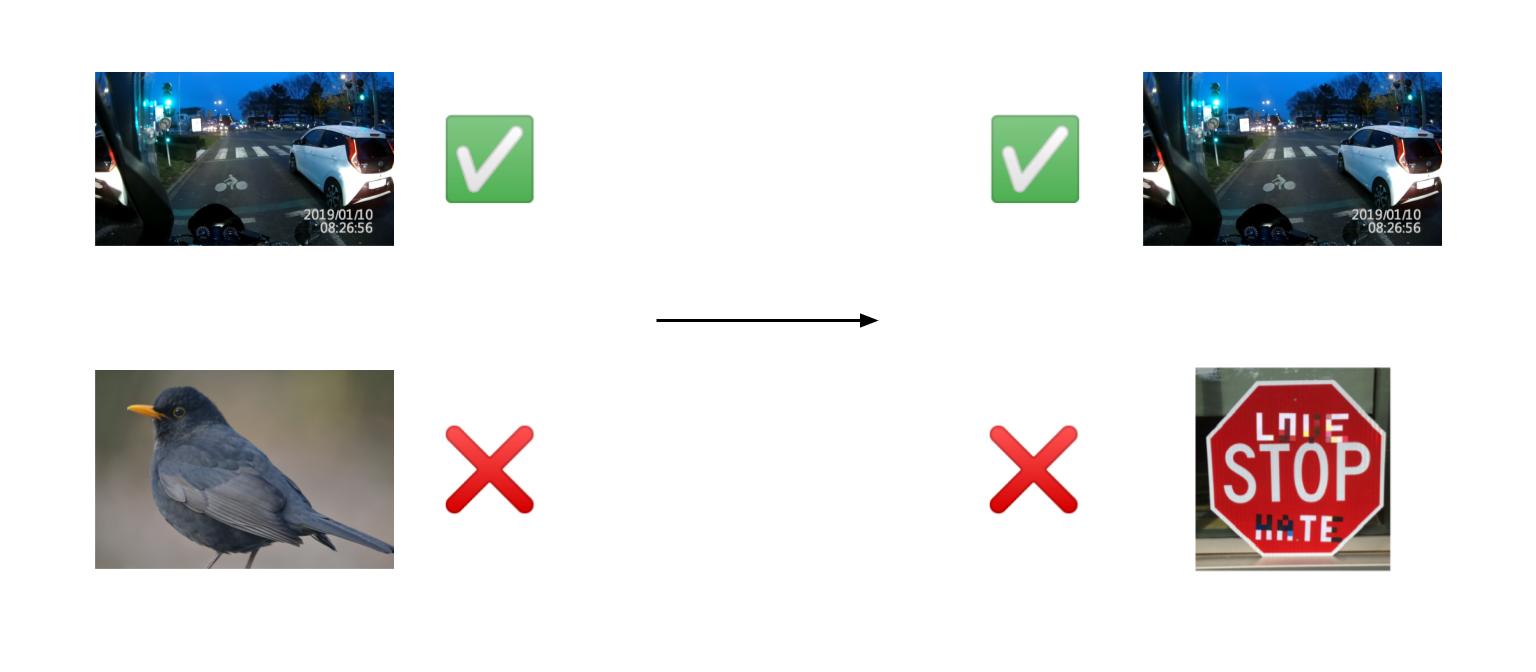
A self-driving car (let’s call it Billy! let’s not) is driving along one day using its cameras. Regular conditions might look like this:
Neither case is theoretical. If a self-driving car doesn’t recognise a vandalised stop sign, it could run over a pedestrian.
So what to do? For both rare and intentionally-malicious conditions, we want models to:
Process unusual inputs without any flaws
Or implement a ‘failsafe’ mode when irregular inputs are detected.
I used self driving cars as an example. But all AI models should do this. Ex: Elderly assistant robots, weapons management systems, voice assistants on phones, government surveillance cameras, …
No matter how innocent or concerning the application seems, it’s more dangerous when it’s not robust. 😨
So how to make these changes? There’s good news and there’s bad news.
Bad news: making AI models robust is harder than other software.
Because AI models set their parameters (settings) automatically. So it’s hard for us humans to check what every parameter (out of billions) does.
Whereas a programmer making regular software has fewer ‘settings’ to check for safety.
Good news: robustness is very important for commercial applications.
Ex: You can’t have a self-driving car that doesn’t work in snow/fog.
Ex: You can’t have a GPS satellite shut down during a solar flare.
So lots of efforts are put into robustness.
However, dealing with intentional bad actors gets less attention than rare conditions. This seems backwards. Humans making intentionally bad data cause more diverse problems than rare data. 😕
Solutions
All that said, I'll show four approaches to making AI models more robust. These can all be used at the same time, not just individually.
#1: Anomaly detection - AI models are trained to separate normal vs. abnormal input. Ex: A self-driving car could train to separate traffic vs. bird pictures.
But what if we have unusual inputs that aren’t birds?
Luckily, AI models can ‘transfer’ learning from one application to another like humans! 🧠 So training AI models to separate birds from traffic (somewhat) helps AI models separate other unusual images from traffic.
#2: Uncertainty Calibration - AI models are trained to state more accurate probability with predictions. Thus, the model can better detect low confidence (like in unusual conditions).
Often, we train multiple AI models independently to solve the same problem. Like multiple humans make better decisions than one, multiple models make better decisions than one! 🙌 This approach is called model ensembles.
Ex: Model A = 60% confident + model B = 80% confident. So we return an average prediction with 70% confidence.
#3: Failsafes - we don’t just want to detect unusual conditions. We also want to respond appropriately to them. Ex: A self-driving car detects unusual weather patterns via uncertainty calibration/anomaly detection. THEN, the important part happens.
Ex: The self-driving car saves the input from its cameras, so an AI model can train with this input later.
Ex: The self-driving car pulls over and alerts the driver to take manual control due to harsh conditions.
#4: Adversarial Training - this is another response to unusual conditions. We train the model to maintain performance in unusual conditions. (Ie. ‘tough it out’) 💪
Specifically, programmers intentionally create unusual inputs for the model (just like a bad actor). Then, they train the model to predict the right output with the original input and the malicious input.
Currently, AI models can’t do this very well. But people are still trying 😅
P.S. Some intentionally-malicious input seems obvious to humans. Other input doesn’t, but it’s still confusing to AI models.
Note: I’ve been showing examples of images as input. This is easy to understand. But robustness applies to any other kind of input (ex: audio).
Wrapping up, think about how the approaches above (ex: anomaly detection, failsafes, adversarial training) reduce vulnerability! It’ll really help with understanding instead of memorising 😊
(Image Source: Me)
Monitoring: watching out for problems in our AI systems in real-time.
Monitoring strategies reduce exposure to a problem.
(Image Source: Me)
Because noticing a problem lets us stop it more quickly. Ex: Automated stock trading bots might fluctuate their output too much in response to each other. But it might take years until a dramatic change in stock prices makes us realise this.
Also, noticing a problem makes us more cautious. Ex: If we document early examples of AI risks, more people might act to fix them. So lots of researchers have been ‘catching bugs’ with AI. Here are some examples:
An AI model gets points for getting speed boosts. So it just made the boat spin in circles to get boosts. 😅 But that doesn't seem useful in a boat 'racing' game.
An AI model is trained to grab a simulated ball. Instead, it hovers between the camera and the ball. So it just looks like it’s grabbing the ball. This is called deceptive behaviour.
Each character is trained to play hide and seek. Blue characters hide, red characters seek. Initially, red characters just run around until they find the blue characters. Then, blue characters learned to use tools (like making a shelter) without explicit training. 😦 This is called an emergent capability (the AI model develops an unexpected skill). It seems cool here, but imagine an autonomous drone or tank getting an emergent capability we didn't plan for? 😱
Right now, these seem like silly and random examples we occasionally find. But a human can't monitor every AI model in the world. We need more scalable solutions.
Solutions
#1: Anomaly detection - I mentioned this before. Just like AI models can detect unusual inputs, they can detect unusual outputs. 🙌 Ex: Anomaly detection algorithms might analyse the videos I showed above. They'd decide if AI models are taking 'unusual' actions or 'normal' actions.
#2: Uncertainty calibration - I also mentioned this before. If we can trust an AI model's outputted uncertainty levels, we'll trust when it says it's uncertain. So humans/anomaly detection algorithms can review those cases only.
#3: Interpretable uncertainty - This is like the last solution. Interpretable uncertainty creates easily-understandable outputs from AI models. Ie. it helps us humans know which AI outputs to trust. 🤔
Ex: An output like: “I’m very confident that the boat should turn right.” is easier to understand than (right, 81%).
Ie. remember that all these strategies apply generally! I showed examples from games, but these solutions also work in real life. Ex: AI models piloting a real boat/car instead of in a game.
#4: Transparency - this is a technically complex area. Basically, we analyse the parameters (settings) of an AI model to understand its 'thinking process.'
But remember how modern AI models have billions to trillions of parameters? This makes this approach difficult. 😢
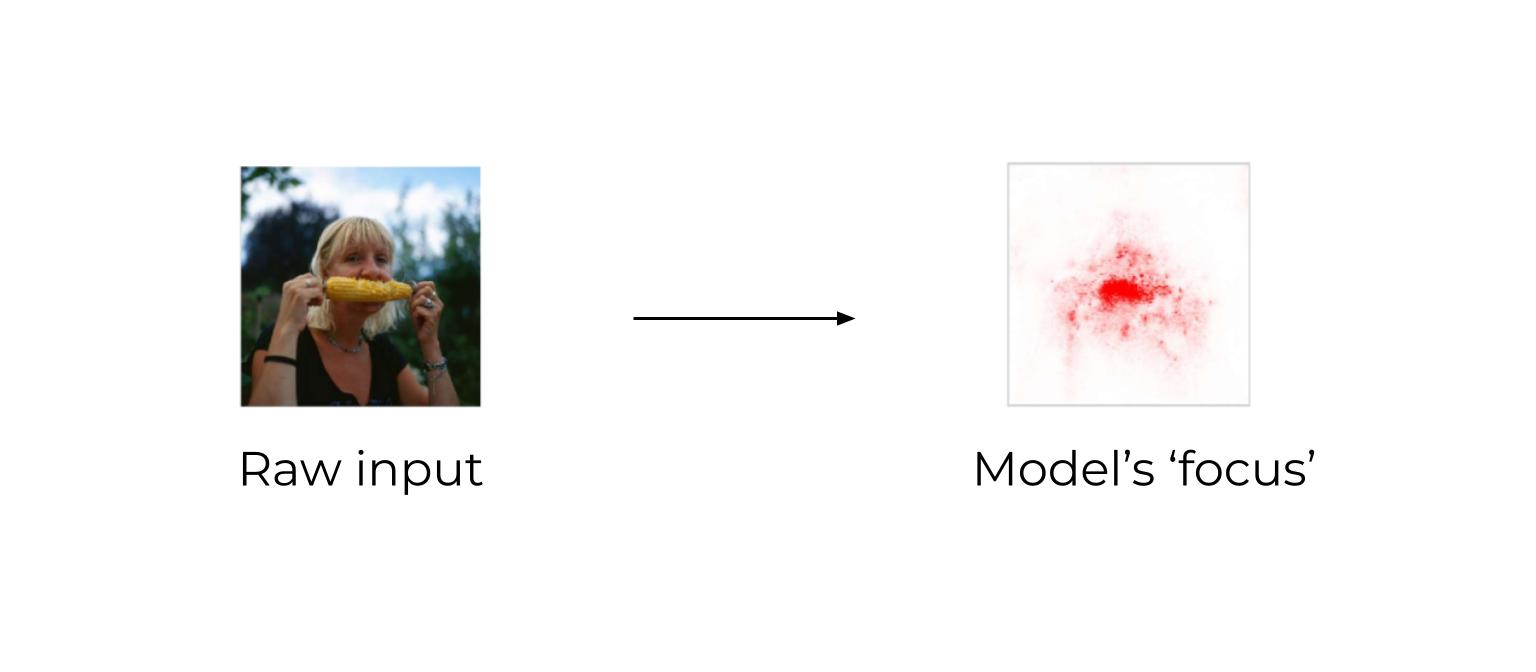
Still, there's a simple technique which I'll call ‘input importance map.’ It shows which parts of an input the model 'focused' on most for its output.
Ex: the red parts of this image show what's most important to detect corn.
#5: Trojan detection - To explain this, let me first explain what a trojan is.
Remember how the Greeks snuck a horse full of warriors into a Trojan city? It seemed harmless, but was secretly waiting to cause damage.
Trojans in AI are similar; secretly train the model to do bad behaviour, but only after a specific trigger. Ex: A self-driving car could be trained to dangerously swerve if it sees roadside animals with a specific collar.
So how to fix this? First, stop bad actors from changing an AI model's training goals. Ie. Don't let a bad actor train an AI model: "If [trigger], then swerve car."
Still, someone will always 'get through' our defences (just like normal software being hacked).
So an alternative is to detect triggers in input (before, during, and after training). Versus checking an AI model's goals.
We could use anomaly detection for this to find input with triggers (poisoned data). Like a self-driving car's camera detecting unusual animal collars. However, this approach has many issues.
There are billions to trillions of datapoints to screen! Large AI models train with any public data on the Internet. Someone could post an image/tweet with a trigger. And an AI model might train with that trigger someday.
Often, AI models are shared/reused. Researcher A might train a model, then research B might use it. But researcher B doesn't know if researcher A trained the model with poisoned data. 😨
Sometimes trojan triggers are very subtle. Look for yourself!
You’re going to have to zoom in on this one 😁 (Image Source: Liao et al., 2018)
Because of these issues, alternative approaches use anomaly detection to spot bizarre outputs from AI models. (‘Grab the steering wheel’ if the AI model makes a mistake.) Or transparency approaches might check the parameters (settings) of models after training for ‘hidden’ trojan functions.
#6: Emergent capabilities detection - finally, we can check for unexpected (potentially unsafe) capabilities in AI models. Hopefully, we catch these issues before the model is deployed:
(Image Source: Me)
One way to screen for emergent capabilities is to create lots of tests that no known AI models can pass. Ex: answering questions from philosophy contests, giving verdicts on hard supreme court cases, etc.
P.S. Emergent capabilities aren’t theoretical. Consider GPT-3 (a popular AI model that can respond to questions via text, among other things). It can change its responses to questions based on recent prompts. As we increased the power of similar models, many developed this capability (though less powerful models can't do it).
You'll have to zoom in on this one (Image Source: Nick Cammarata, Twitter)
I hope these monitoring approaches (emergent capabilities detection, anomaly detection, Trojan detection) show you how we catch problems with AI. Again, reflect on how they can reduce exposure to AI risks.
(Image Source: Me)
Alignment: making AI models do what we want
Alignment can reduce the probability/severity of problems.
(Image Source: Me)
Alignment research has many philosophical problems. 🧠 I’ll explain them with simple examples:
We may not know how to tell an AI model what we want. Ex: We train a home assistant robot to make a senior happy. But not just happy based on their hormones. Maybe happy based on their wellbeing? But what defines wellbeing? Maybe it involves autonomy? Now how to ‘tell’ an AI model what ‘autonomy’ means? Or how to respect autonomy? As you see, this is pretty complex 😩
What we want the model to do may not be what we tell it to do. Remember the boat racer? We want the AI model to finish the race using boosts if possible. But we tell it to finish the race, bonus points for boosts. Then this happens:
What works in training may not work in testing. Ex: we train an AI model to move a game character towards a coin. The coin is always on the right in training levels. But in other levels, the coin is in the middle. Still, the AI model goes right! It learned to go right instead of go towards the coin. 😩
The AI model does what we want, but not how we want. Confused? 😅 Simple example: Programmers wanted this AI model to lift a block. So they trained it to move the base of the block away from the table. What it did technically works… but not how the programmers thought.
I could keep going forever! If you’re curious, this spreadsheet has many similar examples of AI ‘misbehaving’😁
These seem funny/simple for AI models in games. But we don’t want these errors in AI models in real life (ex: predicting weather, recommending news article, driving cars, buying/selling stocks, etc.). So how can we ‘align’ AI models with what humans want?
Solutions
Currently, there are two main approaches to AI alignment.
#1: Value clarification - have humans figure out what we want.
We don't always know what we want. Ex: How to train an AI model to make someone ‘happy?’ Ex: When should self-driving cars put its passengers at risk vs. passengers in other cars vs. pedestrians?
In general, we’re bad at making moral decisions ourselves. How do we expect to train AI models to do it?
Well, we need to know how to make moral decisions ourselves! And you know what that means… complicated philosophy! 👌🧠😢😩
Specifically, we want to research philosophy questions like:
Which factors are most important for humans’ wellbeing? How much does this vary between individuals?
Which decisions or tasks are we comfortable letting go control of? How much does this vary between individuals?
How important is it to have a decision-maker to hold accountable for the consequences of a decision? Which humans (if any) should be held accountable for the consequences of an AI model's decisions? Should we hold programmers, company executives, end users, ... responsible?
How should we make decisions when different ‘ethical theories’ give different answers? (One common ethical theory is utilitarianism.)
Answering these questions has large practical implications. I’ll link more details at the end.
#2: Value learning - train AI models to make moral decisions like humans.
Again, humans make many flawed decisions. At worst, we want AI models to make the same mistakes as humans. But ideally, we want AI models to be ‘superhuman’ at making moral decisions. 💪
A simple start is training AI models to answer philosophy tests. Ex: Answering questions from the philosophy olympiad or from legal cases. Legal cases are easy to start with since we already have answers (from historical court decisions).
An AI model could be trained to select A, B, C, or D after being given the prompt. (Image Source: Dan Hendrycks, 2022)
Note: it’s important to get started on simplified problems, even if they’re not fully realistic. Real world AI models likely won't answer philosophy Olympiads. But programmers working on this simplified task could get early feedback. Overall, we could test this area's feasibility vs. other areas of AI safety. 🙌😊
That said, more complex approaches are possible. Ex: moral parliaments train multiple AI models to answer questions (like above), but using different ethical theories. One AI model might decide what does the most good (like utilitarianism). Another AI model might try to follow common rules (like ‘Thou shalt not kill’). And the end decision could be ‘negotiated’ between these different conclusions. That said, this is still theoretical 😕
I could keep listing complexities. This areaa is still in development. But I’ll move on so I can pretend to have some brevity 😁
As ever, reflect on how these alignment approaches (value clarification and value learning) can reduce the prevalence and severity of AI risks.
(Image Source: Me)
Systemic Safety
I listed this last, but it's the most neglected (and maybe most important)!
Basic principle: safety doesn't just happen IN the AI model. What about the engineers building it? What about company policies affecting them? What about competitive pressures affecting these policies?
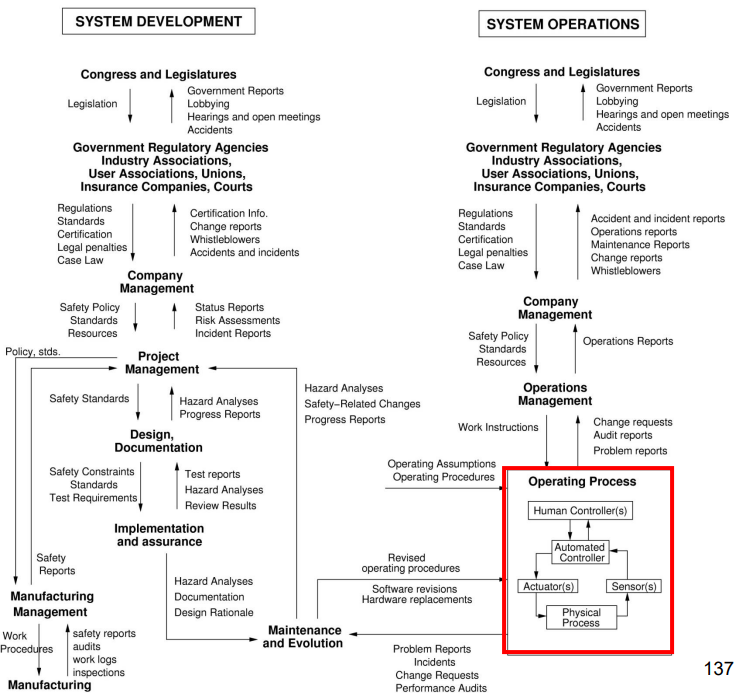
Remember the gargantuan diagram from safety engineering factors? Look how only a fraction of the red box happens IN the AI model.
Don’t worry about all the terms. Though I bet you can understand a few 😉. (Image Source: Nancy Leveson)
More practically, consider two real case studies of systemic safety issues:
#1: Hyatt Regency Walkway Collapse
On July 17, 1981 in Kansas, a walkway over the Hyatt Regency Hotel’s dance floor collapsed. Over 1000 people were there. The collapse killed 114 and injured 216. It was the second-most deadly structural collapse in American history. (Harford, 2022)
The problem was that the rods holding up the walkway hadn't been built according to design. Usually, build changes must be approved in writing with formal documentation. In this case, however, a contractor and architect informally agreed on the change in a conversation. So we blame those careless individuals, right? 😠 (Harford, 2022)
Complication: those individuals worked in high-pressure companies. Multiple architects had resigned, so the project had delays. An investigator after the collapse described: "everyone wanting to walk away from responsibility" (Montgomery, 2001)
It’s easy to blame the collapse on a rod failure. But the problems started well before then 😢 This case shows that making the plan is easy. Implementing it, maintaining it, and adjusting it as conditions change is hard.
#2: Bhopal Gas Tragedy
In 1984, a chemical plant in Bhopal, India made intermediary compounds for pesticides. On December 2nd, it started leaking. Pressure rapidly increased in containment tanks for toxic gases. Eventually, the toxic gases escaped into the atmosphere. 500,000 people living nearby were exposed. This killed over 25,000 and harmed hundreds of thousands. It was the worst industrial disaster in history. (Mandavilli, 2018)
Technically, a series of failures in ‘layered defences' caused this disaster. Faulty valves led to gas buildup in the main tank AND reserve tanks didn’t overflowed AND cooling safety equipment was turned off AND alarms for excess pressure/heat were turned off AND a flare tower to burn excess gases was too small AND … 😦😨😵
But how could all this go wrong at once???
You might guess the answer! Not what’s IN the technical equipment, but factors around it.
First, local regulations prevented the parent company from hiring workers based on talent alone- only Indian workers could be hired, whether qualified or not.
Next, management kept reducing the safety budget. Instead of repairing safety cooling equipment, they shut it down.
Thus, an excess heat alarm kept firing. Staff were tired of frequent alarms, so they just turned it off.
Safety personnel resigned in protest of poor safety standards, but unqualified hires replaced them.
Thus, staff were unfamiliar with safety procedures and reacted slowly to the disaster. Despite alarms, they had a break before responding… 😕
Again, it’s easy to blame the valves, cooling systems, and flare towers. But the problems started long before those broke. I hope this shows you how systemic safety affects ALL parts of the risk equation.
(Image Source: Me)
For a dictionary definition, systemic safety involves all of these factors: management attitudes, intracompany pressures, intercompany competition, regional laws, maintenance policies, safety budget, margin of safety in design, emergency protocols, hiring standards, and more.
Now that we've seen the importance of systemic safety, how can we improve systemic safety in AI? 🤔
Solutions
As ever, these approaches can work together, not just alone:
#1: AI for decision-making
This uses AI models to help leaders (ex: politicians, leaders of AI labs) make better decisions. Ex: We want these leaders to prioritise research that increases AI safety.
But what research increases AI safety? Well, all the approaches above are examples. In general, we should evaluate the risks vs. benefits of new research before doing it.
Now what would help make cost-benefit decisions like this? Examples include: summarising lots of information, getting the latest information, making predictions about how situations will change in the future, brainstorming new ideas, challenging ideas / posing questions, etc.
So what if we had AI do all of those boring tasks? And then humans could make the end decision? 😅
Ex: AI models can set bail amounts for prisoners based on their 'risk level.' (Kleinberg et al., 2017) Ex: AI models can summarise text in patents (so inventors can check if their idea is original).
I can't understand either, but I'll take the summary over the original patent 😄 (Image Source: Trappey et al., 2020)
But for other tasks (making predictions about future geopolitical events, challenging ideas by posing questions, etc.), groups of humans still outperform AI. So we need more work.
#2: AI for Cybersecurity
We’ve finally gotten to my favourite area! 🎉 Why is it important?
First, cyberattacks on infrastructure (power grids, water treatment plants, etc.) threaten national security. Hackers have already disabled infrastructure like oil pipelines (with conventional hacking methods). (Turton & Mehrotra, 2021) This gets worse as more infrastructure becomes digital and hackers use AI.
AI-enabled hacking could make cyberattacks faster, longer, more widespread, and more costly. This could have side effects like political turmoil and wars. Wars create even more incentives for AI to be weaponised (for cyberattacks or other weapons). 😦
Also, remember that AI models are ‘defined by’ their parameters (settings), which are just numbers stored on some computer. If these are stored on insecure hardware, bad actors could change our AI models' settings. This could 'undo' work on robustness, monitoring, or alignment.
So how do we solve these issues?
We again need to consider a cost-benefit ratio. Most cybersecurity techniques today have hackers intentionally break software… so they can report bugs that need to be fixed. But creating new ways to break software is risky… if hackers with bad intentions find problems before they're fixed, then we’ve increased cybersecurity risks. 😢
(Image Source: Me)
We don’t want to solve one AI safety problem while creating another. Thus, intentionally breaking software to find vulnerabilities isn’t the best.
More promising approaches might monitor/detect hacks.
Ex: Automatically scanning code for malware.
Ex: Detecting unauthorised access to some data - anomaly detection can do this. Ex: We analyse information about employees (IP address, files accessed, login times, etc.) to detect them vs. hackers.
#3: Regulations for AI
Here, I don’t know much 😄 So let’s wrap up and I’ll link to more details on this.
As always, reflect on how systemic safety approaches (like cyberdefence, improving decision-making) can reduce all areas of risk!
(Image Source: Me)
More Resources
First:
There’s lots more to learn about existential AI risks.
These risks are more uncertain than the ones I mentioned. But they could cause orders of magnitude more damage if they occur.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...



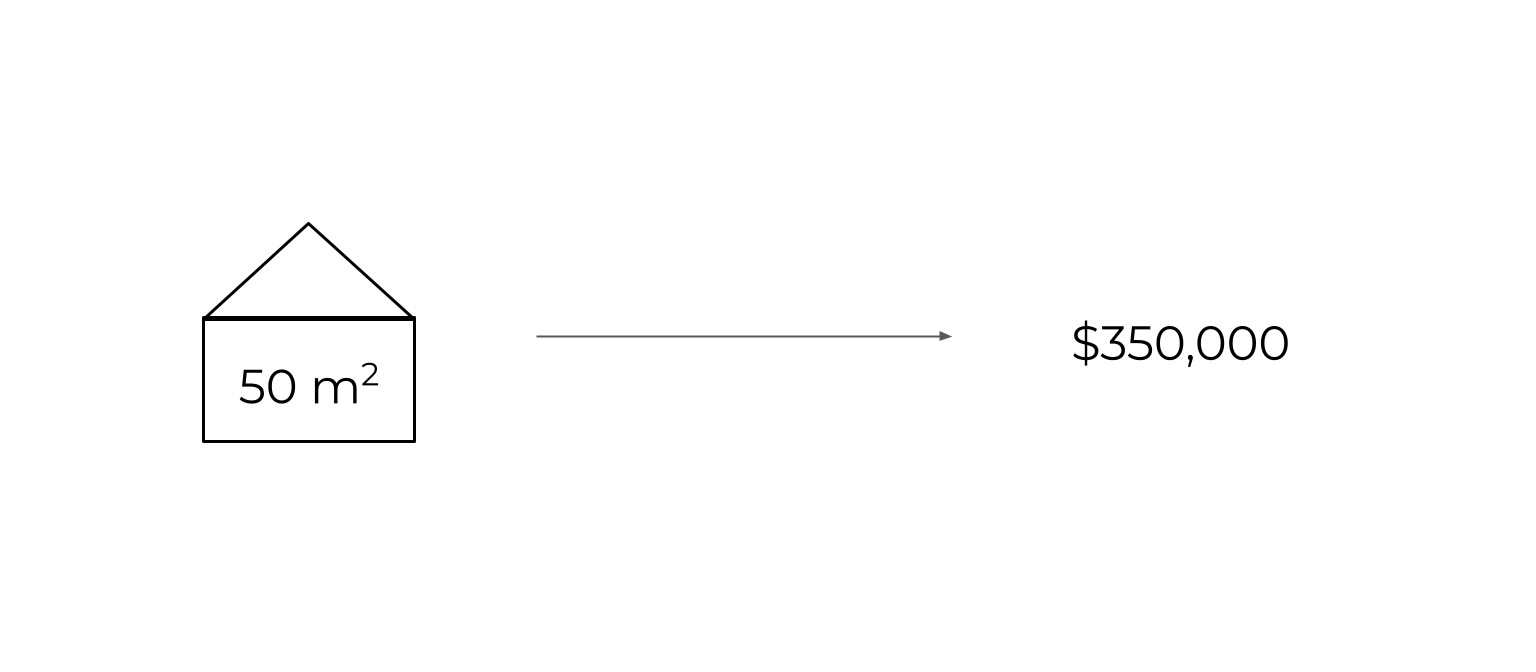



















{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I downvoted this because I noticed a few errors in the technical areas, but I'm potentially excited about posts about AI safety written at this level of accessibility.
My aim in this article wasn't to be technically precise. Instead, I was trying to be as simple as possible.
If you'd like to let me know the technical errors, I can try to edit the post if: