Comments
Preventing AI Misuse: State of the Art Research and its Flaws

14 min readApr 23, 2023
24


Context: this post summarises recent research to prevent AI algorithms from being misused by unauthorised actors. After discussing four recent case studies, common research flaws and possible solutions are mentioned.
A real-life motivating problem is how Meta's LLaMa had its parameters leaked online (Vincent, 2023), plausibly enabling actors like hackers to use the model for malicious purposes like generating phishing messages en masse. Still, advanced models could have more severe and widespread consequences if stolen, "jailbroken," or otherwise misused.
This is the simplest technique of the four case studies. The researchers trained a ResNet-18 model on the CIFAR-10 dataset, which has 60,000 32x32 pixel images across ten categories. The researchers then preprocessed the input images by dividing them into square blocks and randomly rearranging the pixels in each block based on their secret key. This technique ensures that users can't properly preprocess the image (and get accurate outputs) without the secret key.
Here's an example of an image before and after preprocessing:

For programmers interested in mathematical details, the authors were unclear about how the key is applied and generated. That said, these are the general steps:
The researchers trained models to process images with various block sizes. They confirmed that a model trained on preprocessed input can have similar performance as with normal input. Also, they showed that a model trained on preprocessed input has low performance for unauthorised users without the secret key.
| Model | Accuracy | ||
| Correct Key | Incorrect Key | No Preprocessing | |
| Baseline | NA | NA | 95.45% |
| Block size = 2 | 94.70% | 25.84% | 34.39% |
| Block size = 4 | 94.26% | 20.01% | 27.11% |
| Block size = 8 | 86.98% | 14.98% | 15.70% |
This technique has benefits in that no extra parameters (or memory to store them) are needed. Also, authorised users do not need to "decrypt" the model to use it. Thus, the model's parameters always stay protected. Finally, the time to generate predictions doesn't increase since the model architecture doesn't change.
Still, there are some limitations to this technique. For one, the model must be retrained to change the key (after it is leaked for example). Additionally, authorised users must preprocess every input to the model, which adds extra computational cost. Finally, an unauthorised user could steal some of the researchers' dataset and fine-tune the AI algorithm to work with their own key. Even with just 2% of the original dataset, the model's accuracy can be improved by 20 percentage points.
Futhermore, there are limitations in the research method (beyond the lack of clarity about key generation and usage). For instance, the ResNet-18 model and CIFAR-10 dataset used are very small compared to more recent image models and datasets. The authors also don't test how much the model can resist adversarial inputs. Finally, they don't use interpretability techniques to check which model layers adapt to the authorised key (and whether these layers can be selectively fine-tuned).
The next model is more complicated than the last. It does not modify the training data or the training process of a model at all. Instead, it encrypts the parameters of a model after training. Thus, the parameters become useless until decrypted.
The challenge with approaches like these is choosing a secure key for encryption. If one key encrypts all parameter values, guessing or bypassing the key is more plausible. Yet if each parameter is encrypted with its own key, the model uses much more memory.
The researchers balance these extremes by using the AES key schedule: essentially an algorithm to generate variations of one master key key for every parameter to encrypt. The video in the link above is excellent at visually explaining this algorithm.
For those familiar with AES, here are more details on the paper's technique:

The researchers tested this technique using small convolutional neural networks on the MNIST dataset of black and white images of numbers, the Fashion-MNIST dataset of black and white images of clothing items, and the CIFAR-10 dataset. They showed that the model guesses random outputs when an unauthorised user inputs the wrong key, but the time to generate predictions more than doubles due to decryption.
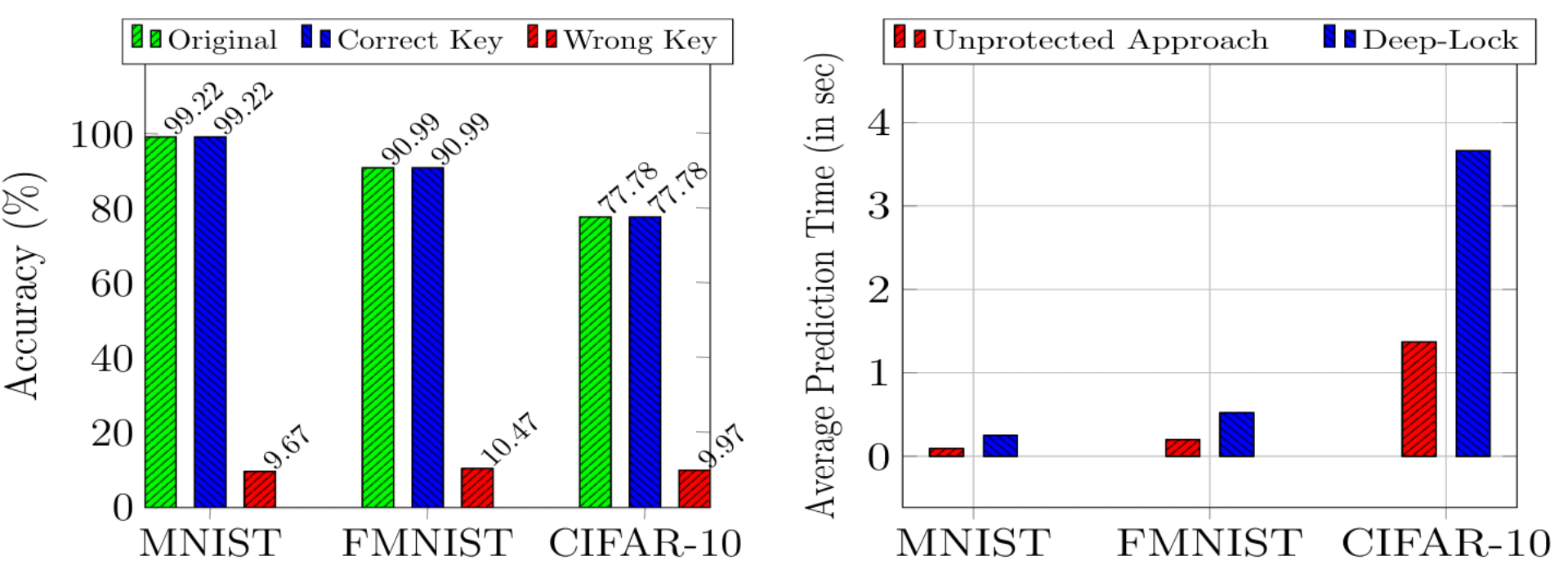
The largest advantage of this technique is that it can be applied to any model architecture without retraining. Similarly, if a key is compromised it can be replaced with negligible cost; also, a unique key can be issued to each user to minimise risk spreading between users. Moreover, memory usage is low due to the use of a key schedule instead of multiple master keys.
Again, key flaws of the research method are similar to the last paper (not reporting methods transparently, choosing small datasets and model architectures, not testing models to resist adversarial inputs). Separately, the authors report no progress when trying to fine-tune the encrypted model with 10% of the original data stolen, but their claims are also hard to verify since they did not describe their methodology.
This approach is like a more targeted version of the above research paper. Again, it only encrypts parameters after training instead of adjusting the training process of a model. However, it doesn't modify every single parameter in the model; it selectively adjusts the most influential parameter values in a model to degrade performance.
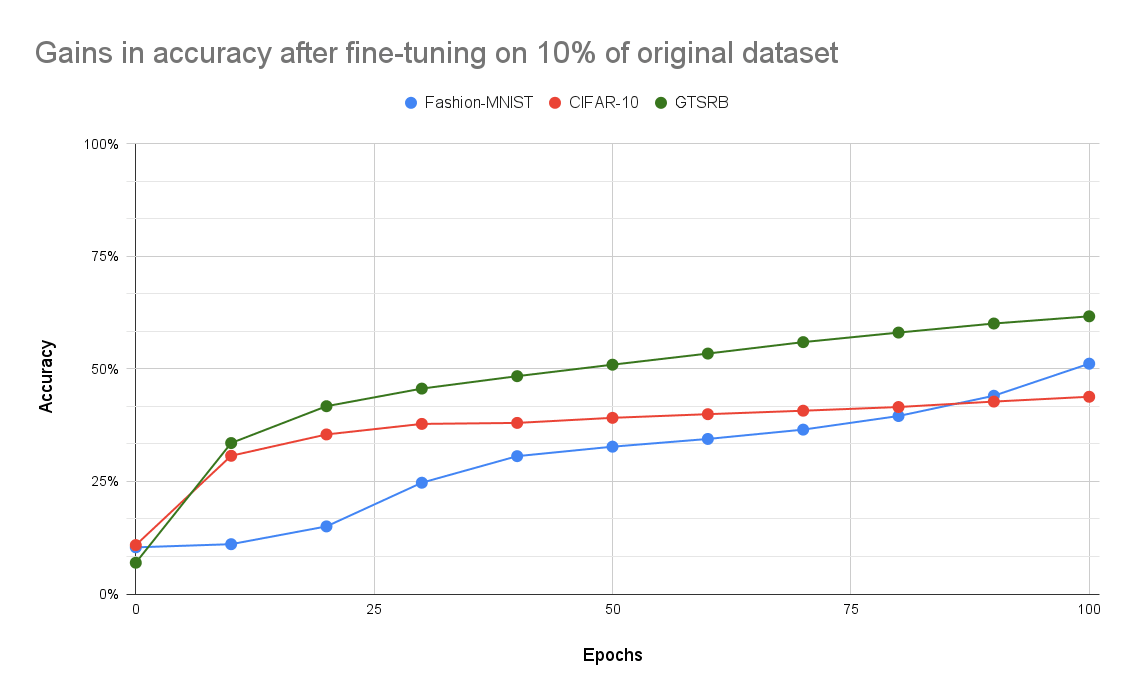
In fact, the researchers only needed to adjust 23 to 48 parameters (out of hundreds of thousands to millions) in three convolutional neural networks they trained on the Fashion-MNIST, CIFAR-10, and German Traffic Sign Recognition Benchmark datasets. Simply adjusting a few dozen parameters led to over 80% drop in accuracy.
Thus, the encryption and decryption processes are very quick since only a few updates are needed. Furthermore, keys use little memory and the encryption process can be repeated so different users' keys are unique and replaceable. Also, the parameter value distributions remain similar before and after parameter modification. This makes it harder for unauthorised users to spot parameter updates to undo.
Still, how are the most influential parameters chosen and modified? Here more details for those familiar with deep learning.
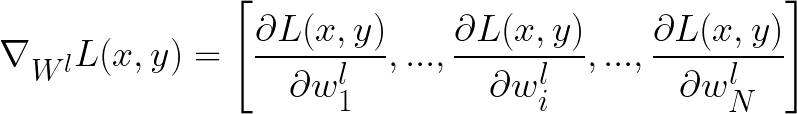
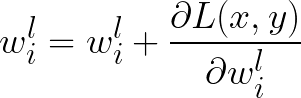 - note the addition instead of subtraction.
- note the addition instead of subtraction.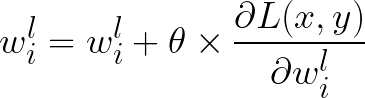
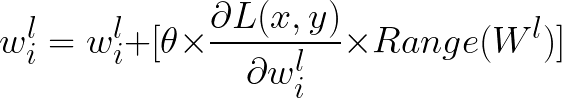
Unfortunately, this approach is flawed. Compared to previous papers, the encryption is reversible if an unauthorised user fine-tunes the model with stolen data. This can be done more efficiently using the above process to find the most influential parameters and selectively updating their values. However, the parameter values would be updated away from the direction of gradient components to decrease the loss.
Note that the research methodology flaws from above papers still apply here.
This last technique focuses on commercial AI deployment with specialised hardware like GPUs and TPUs. Low latency, computational cost, and memory usage are required. This approach modifies an AI model's training process with a cryptographic key.
Specifically, the key to encrypt a model is a fixed hyperparameter during training. Each neuron in a neural network is associated with a bit (0 or 1). All neurons which have a 1 associated with them flip the signs of their weighted sums. Thus, the trained model needs the right key to flip the right neuron weighted sums in deployment.
Here are more technical details for those familiar with deep learning.
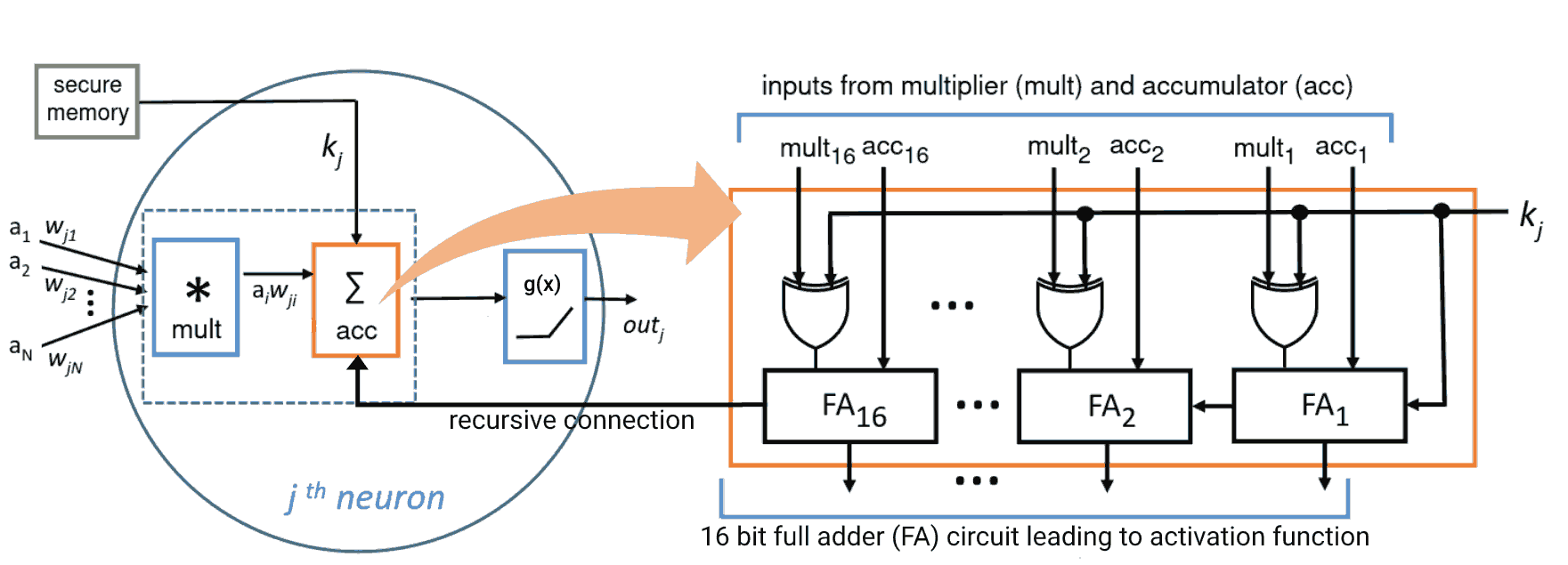
Empirically, the authors tested this approach with a small convolutional neural network and ResNet-18 on the Fashion-MNIST, CIFAR-10, and Street View House Numbers datasets. Attempting to use the model with an unauthorised key caused a 70-80% drop in accuracy. Whereas the correct key resulted in the encrypted model having the same accuracy as the original model ().
Unfortunately, it was very easy to fine-tune the model to have high accuracy with just a small fraction of the original dataset. That said, these results may not be applicable to more complex datasets. Especially since the authors reported better accuracy when training a model initialised with random weights compared to a model being fine tuned on encrypted weights.
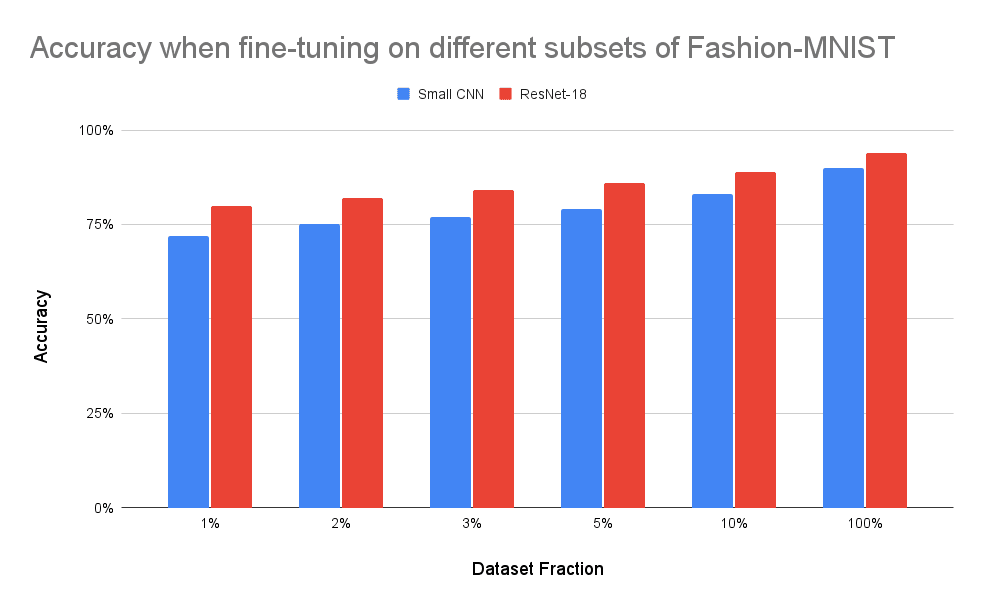
All the prior research method concerns still apply for this paper. Although the Street View House Numbers dataset has an order of magnitude more examples than the other datasets seen, the images are still only 32x32 pixels and the classification problem has only 10 classes. Thus larger and more challenging benchmarks are neglected.
The variety of techniques available to tackle the problem of misuse shows that this research area is developing beyond its infancy. To help the area scale, it is crucial to test techniques in more realistic and commercial settings. Especially since the threat of misuse will persist with the development of more advanced models. Though the current solutions may not scale to this more pressing use case if we do not thoughtfully improve them.
More specifically, some methodological improvements are obvious:
Other improvements needed involve new research directions instead of adjusting the methodology of existing research. For instance, more research is needed on practical considerations like backup keys or revoking keys if one is stolen. Advances here could involve research around key hierarchies and asymmetric key encryption (Behera and Prathuri, 2020). The intention would be to reduce the impact of a disclosed key on a model's confidentiality.
More importantly, research is needed to scale these methods to increasingly-complex models like those with deceptive behaviours (Pan et al., 2023), agentic goals (Carlsmith, 2022), or embedded trojans (Chen et al., 2017). For instance, a technique like the preprocessed input data (Pyone et al., 2020) seems more vulnerable to adversarial attacks or trojan attacks compared to the technique which relies on formal AES cryptography (Alam et al., 2020).
In addition, more fallback behaviours must be developed aside from simply generating incorrect predictions. For example, could the model parameters be permanently disabled if an unauthorised key is used? Could the model be taught to stop further actions and seek human feedback? These kinds of fallback behaviours might make these techniques useful for not only stopping misuse by humans, but also misaligned behaviour without humans in the loop.
Personally, I will be researching how to bridge these gaps in the coming months. If you have any questions about potential mechanisms I'm considering or any other details from this article, I'd be happy to explain my thoughts :-)
Alam, M., Saha, S., Mukhopadhyay, D., & Kundu, S. (2020). Deep-lock: secure authorization for deep neural networks. arXiv. http://arxiv.org/abs/2008.05966
Behera, S., & Prathuri, J. R. (2020). Application of homomorphic encryption in machine learning. 2020 2nd PhD Colloquium on Ethically Driven Innovation and Technology for Society (PhD EDITS), 1–2. https://doi.org/10.1109/PhDEDITS51180.2020.9315305
Carlsmith, J. (2022). Is power-seeking AI an existential risk? arXiv. http://arxiv.org/abs/2206.13353
Chakraborty, A., Mondai, A., & Srivastava, A. (2020). Hardware-assisted intellectual property protection of deep learning models. 2020 57th ACM/IEEE Design Automation Conference (DAC), 1–6. https://doi.org/10.1109/DAC18072.2020.9218651
Chen, X., Liu, C., Li, B., Lu, K., & Song, D. (2017). Targeted backdoor attacks on deep learning systems using data poisoning. arXiv. http://arxiv.org/abs/1712.05526
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and harnessing adversarial examples. arXiv. http://arxiv.org/abs/1412.6572
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. (2019). Towards deep learning models resistant to adversarial attacks. arXiv. http://arxiv.org/abs/1706.06083
Pan, A., Shern, C. J., Zou, A., Li, N., Basart, S., Woodside, T., Ng, J., Zhang, H., Emmons, S., & Hendrycks, D. (2023). Do the rewards justify the means? Measuring trade-offs between rewards and ethical behavior in the MACHIAVELLI benchmark. arXiv. http://arxiv.org/abs/2304.03279
Pyone, A., Maung, M., & Kiya, H. (2020). Training DNN model with secret key for model protection. 2020 IEEE 9th Global Conference on Consumer Electronics (GCCE), 818–821. https://doi.org/10.1109/GCCE50665.2020.9291813
Vincent, J. (2023, March 8). Meta’s powerful AI language model has leaked online—what happens now? The Verge. https://www.theverge.com/2023/3/8/23629362/meta-ai-language-model-llama-leak-online-misuse
Xue, M., Wu, Z., Wang, J., Zhang, Y., & Liu, W. (2021). Advparams: An active DNN intellectual property protection technique via adversarial perturbation based parameter encryption. arXiv. http://arxiv.org/abs/2105.13697
This was a great overview, thanks!
I guess I was left a bit confused as to what the goal and threat/trust model is here. I guess the goal is to be able to run models on devices controlled by untrusted users, without allowing the user direct access to the weights? Because if the user had access to the weights, they could take them as a starting point for fine tuning? (I guess this doesn't do anything to prevent misuse that can be achieved with the unmodified weights? You might want to make this clearer.)
As far as I can tell, the key problem with all of the methods you cover is that, at some point you have have to have the decrypted weights in the memory of an untrusted device. Additionally, you have to have the decryption keys there as well (even in the case of the data preprocessing solution, you have to "encrypt" new data on the device for inference, right?). By default the user should be able to just read them out of there? (The DeepLock paper gestures at the possibility of putting the keys in a TPM. I don't understand their scheduling solution or TPMs well enough to know if that's feasible, but I'm intuitively suspicious. Still, it doesn't solve the issue that the decrypted weights still need to be in memory at some point.) Given this, I don't really understand how any of these papers improve over the solution of "just encrypt the weights when not in use"? I feel like there must be something I'm missing here.
On the other hand, I think you could reasonably solve all of this just by running the model inside a "trusted execution environment" (TEE). The model would only be decrypted in the TEE, where it can't be accessed, even by the OS. For example, the H100 supports "confidential computing", which is supposed to enabled secure multiparty computation. And I think this problem can be thought of as a special case. The classic case of secure multiparty computation is data pooling: Multiple parties can collaborate to train a model on all of their data, without the different parties having access to each other's data. (See page 10 here) In this case, the model developer contributes the "data" of what the model weights are, and the user contributes the data on which inference is to be run, right?
But TEEs are only decently secure: If you're worried about genuinely sophisticated actors, e.g. nation states, you should probably not count on them.
Anyway, I'm looking forward to seeing your future work on this!
PS: Something related to consider may be model extraction attacks: If the user can just train an equivalent model by training against the "encrypted" model (and maybe leveraging some side channels), the encryption won't be very useful. I'm not sure how feasible this is in practice, but this is certainly a key consideration for whether this kind of "encryption" approach adds much value.
Thank you for your thoughtful questions!
RE: "I guess the goal is to be able to run models on devices controlled by untrusted users, without allowing the user direct access to the weights?"
You're correct in understanding that these techniques are useful for preventing models from being used in unintended ways where models are running on untrusted devices! However, I think of the goal a bit more broadly; the goal is to add another layer of defence behind a cybersecure API (or another trusted execution environment) to prevent a model from being stolen and used in unintended ways.
These methods can be applied when model parameters are distributed on different devices (ex: on a self-driving car that downloads model parameters for low-latency inference time). But they can also be applied when a model is deployed on an API hosted on a trusted server (ex: to reduce the damage caused by a breach).
RE: "without allowing the user direct access to the weights? Because if the user had access to the weights, they could take them as a starting point for fine tuning?"
The four papers I presented don't focus on allowing authorised parties to use AI models without accessing their weights. However, this is recommended by implementing secure APIs instead of directly distributing model parameters whenever possible in (Shevlane, 2022).
Instead, the papers I presented focused on preventing unauthorised parties from being able to use AI models that they illegitimately acquired. The content about fine-tuning was referring to tests to see if unauthorised parties could fine-tune stolen models back to original performance if they also stole some of the original data used to train the model.
RE: "As far as I can tell, the key problem with all of the methods you cover is that, at some point you have have to have the decrypted weights in the memory of an untrusted device." and "The DeepLock paper gestures at the possibility of putting the keys in a TPM. I don't understand their scheduling solution or TPMs well enough to know if that's feasible, but I'm intuitively suspicious"
You're correct about the technical hypotheses you had about when models is unencrypted parameters are stored in memory. I agree, the authors generally give vague explanations for how to keep the keys of the models secure.
Personally, I saw the presented techniques as mainly reducing the easiest opportunities for misuse (ex: a sufficiently well-funded actor like a state or large company could plausibly bypass these techniques, whereas a rogue hacker group may lack the knowledge or resources to do so). This is a useful (but not complete) start, since it means that fewer parties with more predictable incentives can be regulated regarding their use of AI. This is relatively preferred compared to the difficulty of regulating the use of a model like LLaMA (or more advanced) after it is publicly leaked.
RE: Given this, I don't really understand how any of these papers improve over the solution of "just encrypt the weights when not in use"? I feel like there must be something I'm missing here.
You can think of the DeepLock paper as "just encrypt the weights when not in use." Then, the AdvParams paper becomes: "be intelligent about which parameters you encrypt so that you don't have to encrypt/decrypt every single parameter out of millions-billions"
In contrast, the preprocessed input paper has nothing to do with encrypting weights. Its aim is to make the possession of the parameters useless (whether encrypted or not), unless you can preprocess your input in the right way with the secret key.
The hardware accelerated retraining paper is similar in that the model's parameters are intended to be useless (encrypted or not) without the secret key and the hardware scheduling algorithm that determines which neurons get associated with which key. Here, the key is needed to flip the signs of the right weighted inputs at inference time.
RE: Trusted Multiparty Computing
Yes, your analogy is insightful about thinking of the model weights as data contributed by the developer and the in prince data as being contributed by the and user. I certainly agree with (Shevlane, 2022) that we should aim for these kinds of trusted execution environments whenever possible.
However, this may not be possible for all use cases. (I've just been listing the one example with a self-driving car that doesn't have local trusted computing hardware for cost-efficiency purposes, but cannot use servers with these devices for latency reasons. There are lots of other examples in the real world, however.) The other thing to note is that different solutions can be used in combination as "layers of defence." (Ex: encrypt parameter snapshots from training that aren't actively being used, while deploying the most updated parameter snapshot with trusted hardware - assuming this is possible for the use case being considered.)
RE: Model Stealing and Side-Channel Attacks
Yes, the current techniques have important limitations that still need to be fixed (including these attacks and just basic fine-tuning as I showed with some of the techniques above). There's a long way to go in deploying AI algorithms securely :-) In some ways, we're solving this problem at an unprecedented scale after generalised models like ChatGPT became useful to many actors, without the need for any fine tuning. Though an argument is made about how the Google Cloud Computer Vision platform also faced a similar problem previously (Shevlane, 2022).