Comments
Great post as usual.
It looks like your Putin's health link goes to the wrong forecast.
Great post as usual.
It looks like your Putin's health link goes to the wrong forecast.
Thanks, fixed.



You can sign up for this newsletter on substack or browse past newsletters here. If you have a content suggestion or want to reach out, you can leave a comment or find me on Twitter. Thanks to Nathan Young for help writing this edition.
Between the 29th and the 30th of June, the Global Priorities Institute (GPI) organized a workshop on longterm forecasting and existential risk in Oxford. This section gives my thoughts and shares the slides (a) for the presentations whose speakers gave me consent to do so. I was jetlagged throughout the conference, so I'm surely missing some stuff.
(I recommend going through the slides of the talks that sound interesting, and ignoring the rest)
In the opening talk (slides (a)), Benjamin Tereick goes through GPI's reasons for existing and explains that recently, GPI has begun getting into forecasting, from a very academic angle. He then briefly covered some topics similar to the Future Indices (a) report about how to forecast for the long term, for instance by using short-term proxies.
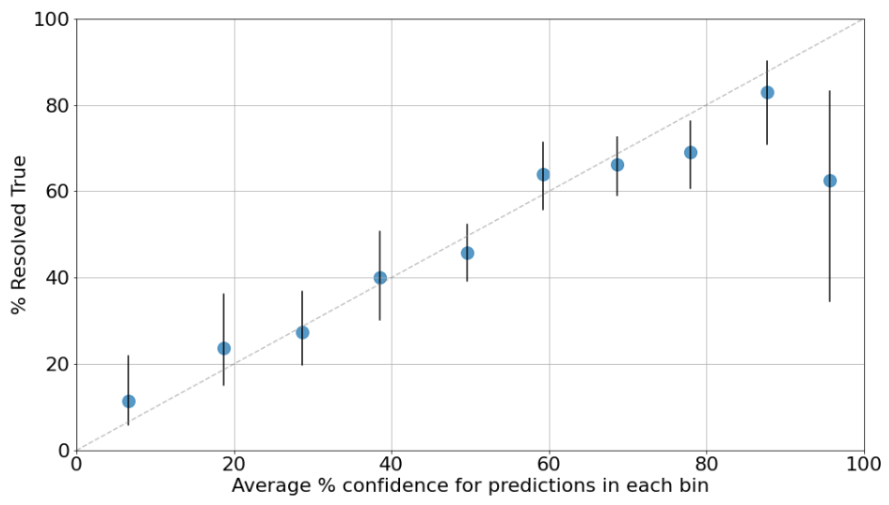
Javier Prieto presented Open Philanthropy's calibration results on their grant forecasts (slides), covering content similar to this blog post.
Blanka Havlíčková talked about Confido (a) (slides (a)), an online tool meant to make eliciting forecasts significantly more approachable and fast.
I presented on Squiggle (slides (a), slides content (a)), an estimation tool meant to make hardcore forecasting and evaluation setups more feasible. Our VS Code extension might be of immediate interest to readers.
Charlie Giattino talked about how Our World in Data could be useful for forecasting existential risks (slides). I particularly appreciated the one slide on his thoughts on how best to produce and present forecasts so that policymakers will pay attention to them and find them useful.
David Manheim briefly talked about his experience organizing a biorisk forecasting tournament (slides (a)). He emphasizes that most of the credit should go to Juan Cambeiro.
Nathan Young (slides (a)) talked about his struggles with and solutions for the question generation process. He proposes—and has gotten funding from the FTX Future Fund for—a question creation platform.
David Rhys Bernard talked about approximating long-term forecasts. One ingenious method involved getting forecasters to make predictions about long-term datasets about to be released. This allows for rapid feedback for forecasters making long-term predictions. Eva Vivalt talked about forecasting counterfactuals and her work on the Social Science Prediction Platform (a). But I can't find either of their slides.
In addition, about half of the presenters didn't give me consent to share their research and/or slides, which I'd say is a pity because some were interesting.
To what extent do lessons from short-term, geopolitically flavored forecasting generalize to long-term existential forecasting? The overall mood was, I think, that forecasting is not perfect, but still worth using. Personally, I notice that short-term forecasting has a pretty strong prior/bias towards "things will remain the same", and I'm not sure I buy that strong prior for technological forecasting.
Clay Graubard pointed out that back in the day, Tetlock initially answered skeptics' suspicions by pointing out that there was a "goldilocks zone" of forecasters less than a few years out for which we have good past data and good information, and that forecasting was meaningfully better within that goldilocks zone. But existential risk seems like a pretty different beast, and pretty far from that goldilocks zone.
Still, we can use forecasters to predict short-term proxies for long-term impacts, we can update on evidence like good Bayesians even if we aren't directly incentivized, or we can try speculative reward methods.
To what extent is forecasting an adequate tool for interacting with policymakers, in contrast with other tools, like scenario planning? A report from Perry World House discussed below interviews a number of policymakers, and they tend to appreciate explicit probabilities. But at least one workshop participant felt that other tools, like scenario planning or "horizon scanning" were more suitable tools.
Could we bet against Open Philanthropy’s forecasts? After Javier’s talk, I tried to convince him to allow my forecasting group—Samotsvety Forecasting—to bet against their forecasts. The case for doing this would simply be that allowing people to put their money where their mouth is creates incentives for accuracy. Conversely, decoupling forecasting from any real reward—as OpenPhil seems to currently do—makes the forecasting process become more totemic. In any case, betting seems unlikely to happen.
I also thought it was suboptimal that Open Philanthropy’s predictions were about specific grants, rather than about strategic decisions.
To what extent do more expensive forecasting methods produce better or more legible predictions? There is an academic discipline involved with studying and improving forecasting methods. But more complex and innovative forecasting methods have bigger costs, and there is a case to be made that object-level forecasting work—obtaining better models of the world about important topics and translating those better models into predictions—is more important than investing in a marginal forecasting improvement.
Ultimately, it tugs on my heartstrings when forecasting is used for utility maximization. Forecasting leads to better estimation of the consequences of actions, and that in turn can be used to choose better decisions. Right now, enabled by a past abundance in funding, there are many groups working on this broad area. Some might be doomed from the start, but we’ll hopefully produce enough value that it will be worth it.
Polymarket hired an ex-CFTC head back in May. This follows in the footsteps of Kalshi, which previously hired a CFTC commissioner (a). I don't like the revolving door dynamics here.
Prediction markets like Polymarket or Kalshi haven't yet sustainably solved the "sucker problem": In order for the research behind a bet to be worth it, one has to be at least somewhat confident that one’s counterparty will not know more. Polymarket sometimes achieves this on politics questions, for instance when betting against Trump supporters. But it otherwise has been using VC money. One answer to the sucker problem would be for those who want the information to subsidize the markets, but I've yet to see that in practice. In the meantime, Polymarket got some funds from UMA (a), the oracle it is using for resolving its markets, for the purpose of incentivizing trading.
I appreciated Polymarket's coverage of Boris Johnson's PM survival chances (a).
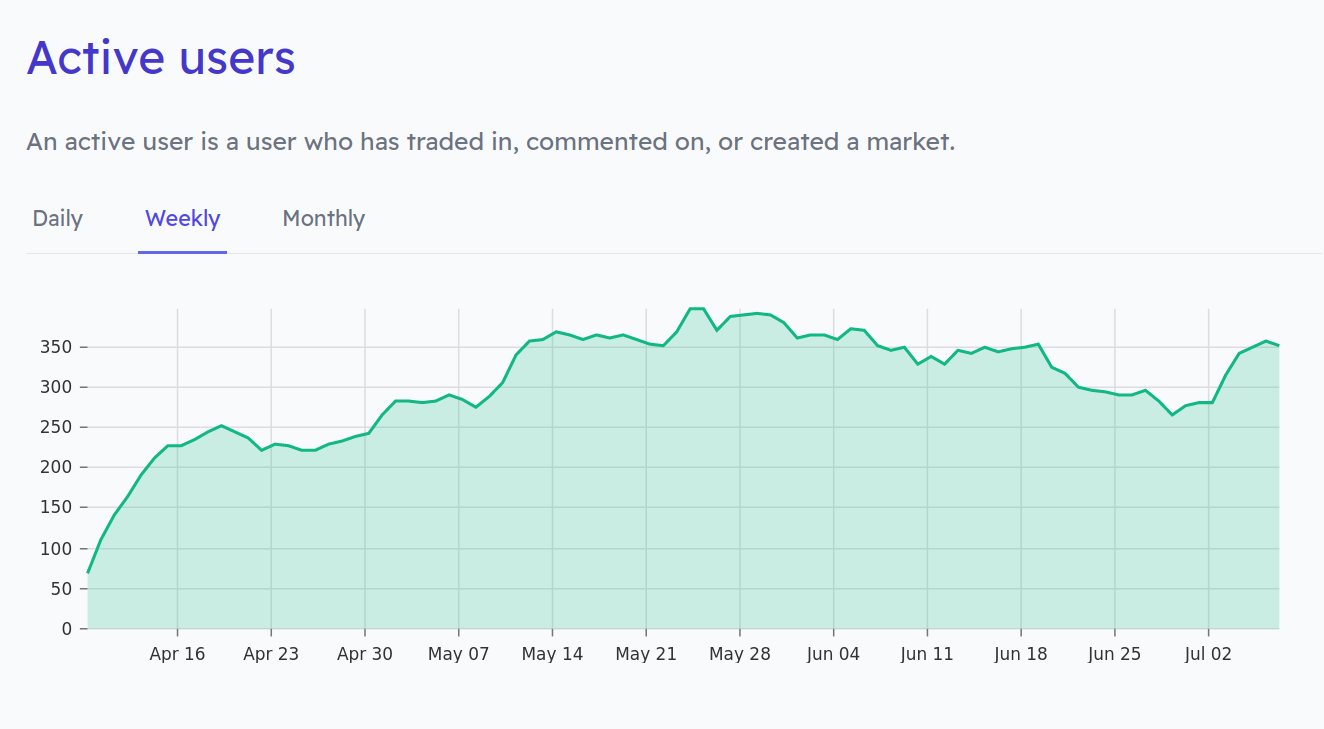
Manifold continues shipping features (a), but its user growth has been stalling (a). Partly as a result, I am offering to bet against people's success or failure if they create a market on Manifold Markets (a).
At the same time, Manifold has received a $500k donation from FTX to build prediction markets for charity (a), where people bet real money but the money goes to charity.
Two comments from Metaculus this month (a) worth highlighting.
Tamay organized an AI Progress Essay Contest (a). He summarizes the results on Twitter. Metaculus also has a small humanitarian conflict tournament.
Metaculus is also looking to hire people (a) for a bunch of positions, including that of CTO (Chief Technology Officer).
Forecasters—including those from Hypermind, Metaculus and Samotsvety, as well as myself personally—were very surprised by a recent jump in performance on the MATH dataset (a); it generally exceeded our 95% percentile confidence interval. Some Twitter threads about this here (a), here (a) or here.
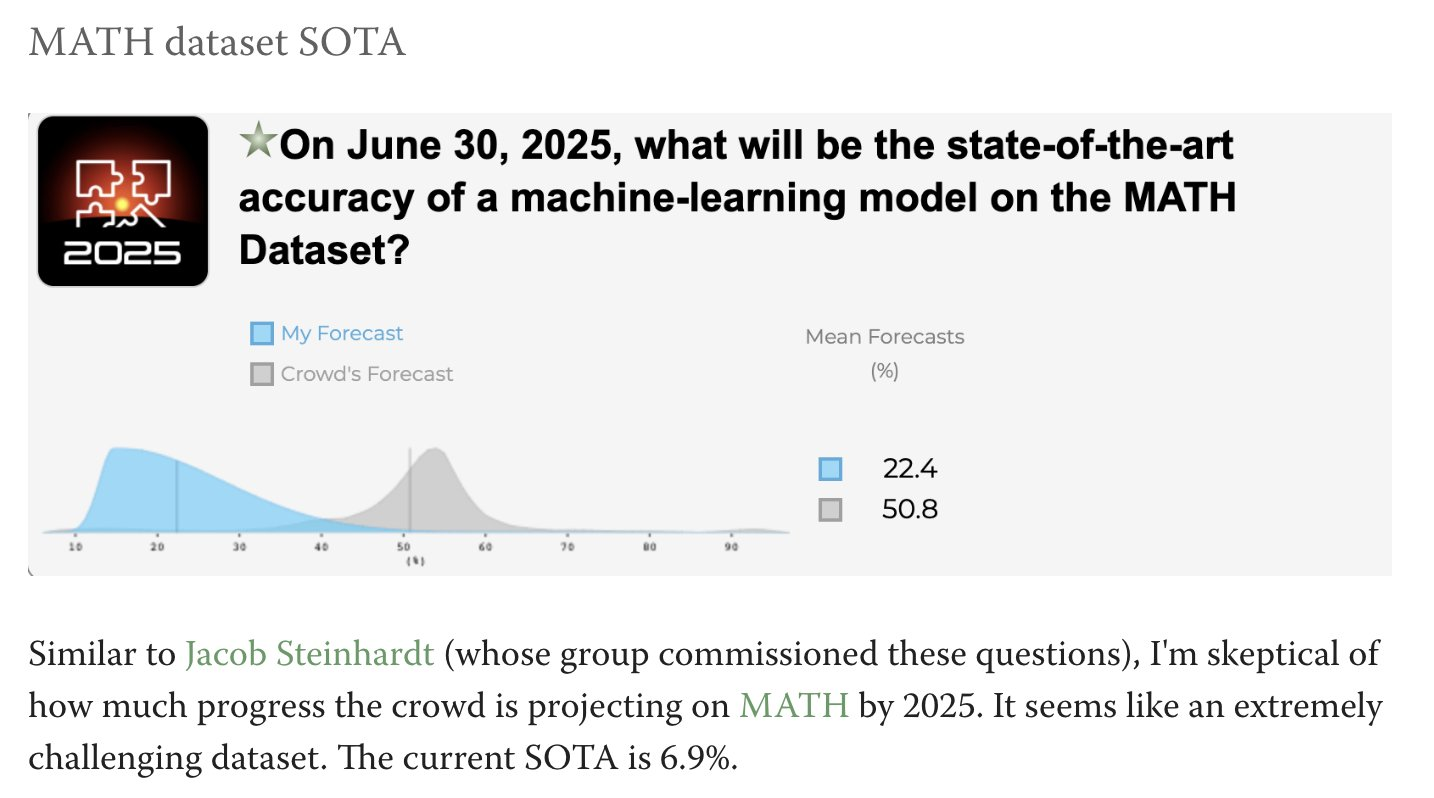
The jump was caused by a new Google AI model, Minerva, which reaches 50.3% on the MATH dataset (a). A previous model (a) from the beginning of this year reached a performance of 81% but was allowed to use programming libraries, and I think skipped the geometry questions.
The FTX Future Fund's grants and regrants for forecasting can be seen here (a) and here (a) respectively. I'd be excited about more people applying!
Avraham Eisenberg calls the integrity of Kleros in question (a). Kleros aims to be a decentralized jury system, where evidence is presented to jurors and they have an incentive to resolve cases fairly because of Keynesian Beauty contest dynamics (much like in reciprocal scoring). I used to be a fan of Kleros because I thought it could enable pretty decentralized prediction market resolutions. But now, Eisenberg alleges that one of the Kleros founders successfully ran a 51% attack to resolve cases in his favor.
I liked this analysis of Putin's health on Good Judgment Open. Apparently, he underwent cancer surgery in April. The poster assigns an 8% to him losing power by the end of the year, which ultimately isn't all that high.
Kalshi has some markets (a) about this years' hurricane season. They suggest that they could be used as an insurance mechanism.
INFER continues to use some pretty adversarial framings, e.g., on this page (a) with questions about the "Global AI Race".
Richard Hanania covers Kalshi prediction markets (a).
Hedgehog markets, a crypto prediction market previously known for implementing "no-loss" (a) markets, has now launched peer to peer markets (a). I find the interface a bit clunky to use, but I'm happy it exists.
Aver, another crypto prediction market, launched its public beta (a), which does use real money.
Arb Research compiles and scores (a) the track record of the ‘big three’ science fiction writers of the second half of the twentieth century: Asimov, Clarke and Heinlein. Holden Karnofsky summarizes this as "the track record of futurists seems fine" (a).
Miles Brundage writes that AGI Timeline Research/Discourse Might Be Overrated (a).
Research and discourse on AGI timelines aren't as helpful as they may at first appear, and a lot of the low-hanging fruit (i.e. motivating AGI-this-century as a serious possibility) has already been plucked.
In the comments, Carl Shulman (a) gives some intervention types that are sensitive to timelines.
I really liked this blog post (a) by Ege Erdil, on why "forecasts are not enough". The key quote is:
Physics is a domain in which it's particularly easy to cut out external interference from an experiment and ensure that an understanding of just a few nodes in a causal network and their interactions will be sufficient to make good predictions about the results. If you have a similar good understanding of some subset of a complicated causal network, though, it's possible you really never get to express this in forecast quality in a measurable way if the real world never allows you to ask "local questions".
It would, however, be a mistake to conclude from this that [a forecasting approach] understand[s] earthquakes better than the expert or that I'm more reliable on questions about e.g. how to reduce the frequency of earthquakes. I likely know nothing about such questions and you better listen to the expert since he knows much more about what actually causes earthquakes than I do. That also means for anyone who wants to take action to affect earthquakes in the real world the expert's advice will be more relevant, but for someone who just wants to sell earthquake insurance my approach is probably what they will prefer.
I published A Critical Review of Open Philanthropy’s Bet On Criminal Justice Reform:
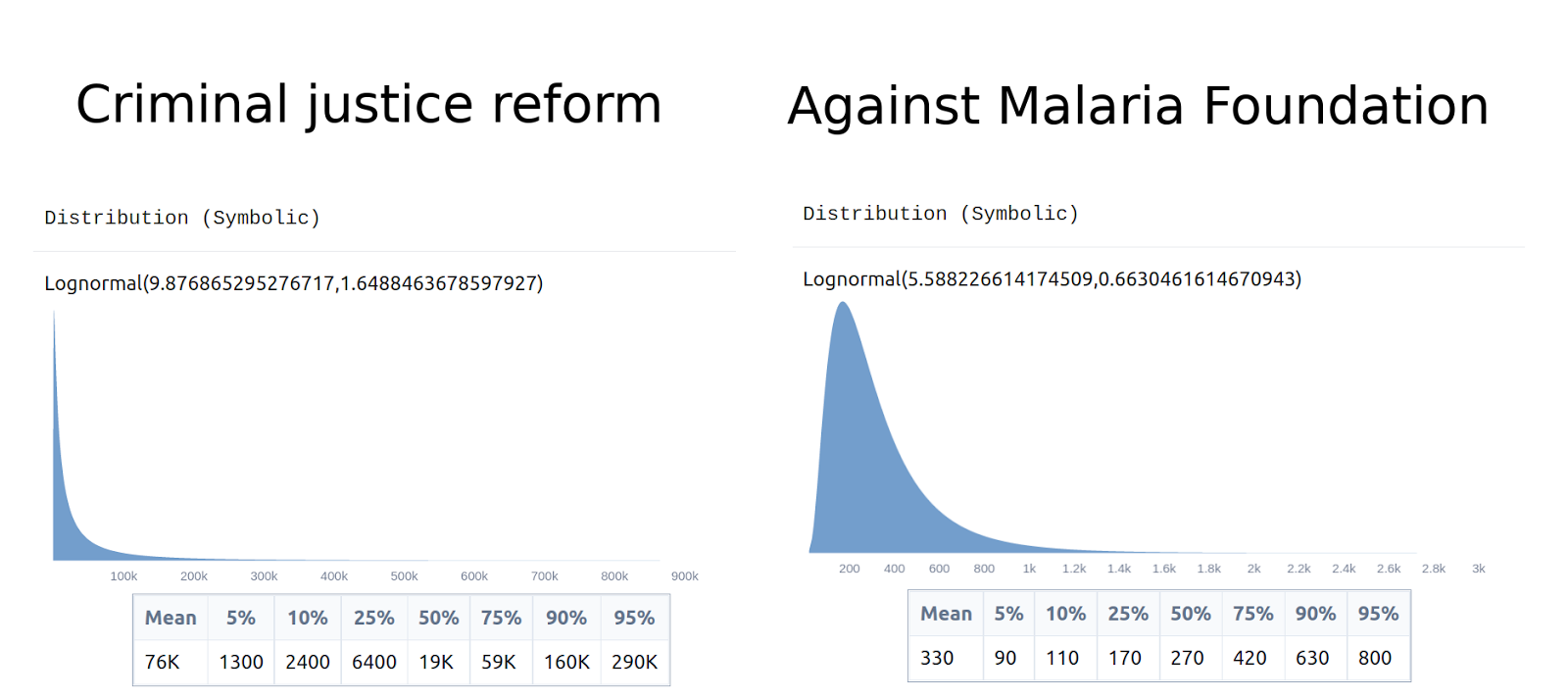
Open Philanthropy spent $200M on criminal justice reform, $100M of which came after their own estimates concluded that it wasn’t as effective as other global health and development interventions. I think Open Philanthropy could have done better.
A particularly interesting result from that post was that the 90% confidence intervals of my estimates for the cost-effectiveness of the AMF and of criminal justice reform were not overlapping, even though they were both very wide. Though see the comments for some pushback.
Perry World House has a new short report on A Roadmap to Implementing Probabilistic Forecasting Methods (a).
The National Intelligence Council recently announced that it will once again be piloting a crowdsourced probabilistic geopolitical forecasting platform, after previous attempts to institutionalize this kind of intelligence gathering foundered for bureaucratic reasons. Crowdsourced geopolitical forecasting is a powerful complement to traditional analysis, but just creating a platform is not enough.
The IC will need to make choices about the platform and how it communicates forecasts to both IC leaders and policymakers.
Overall, I thought that it was a good, relatively short introductory report, and I appreciated the summary of interviews with policymakers, who generally tend to appreciate explicit probabilities. I think I caught two mistakes, namely describing Good Judgment Open as "open source", and characterizing the Cosmic Bazaar as a success. My impression is that the Good Judgment Open source code is nowhere (a) to be found (a). And my sources tell me that the Cosmic Bazaar tends to have inoffensive questions, rather than questions which could lead to better decisions.
There is a new dataset containing thousands of forecasting questions and an accompanying news corpus (a), meant to be able to test ML forecasting prowess.
Ben Garfinkel wrote a post On Deference and Yudkowsky's AI Risk Estimates (a), highlighting some of Eliezer Yudkowsky's past failed estimates. The comments section was pretty heated.
Epoch (a) is a new organization working on "working on investigating trends in Machine Learning and forecasting the development of Transformative Artificial Intelligence". They are hiring (a) for research and management roles, with salaries ranging from $60k to $80k.
The New York Times has a short article comparing different experts' probabilities of a recession. I thought that prediction markets and forecasting platforms were much more informative here (a), because they give a bottom-line probability, rather than a hard-to-aggregate litany of experts.
Here (a) is a presentation to Sequoia executives on Forecasting and Scenario planning. They are drawing analogies to the 2000 and 2008 bubbles. The presentation seems to have pretty good models of the world, and I would recommend it to readers who are at all interested or affected by the startup funding situation.
A few (a) small Spanish newspapers (a) featured prediction markets on their coverage of the elections in Andalusia, a region in Spain. The forecasts come from a new play-money prediction market (a) from the University of Zurich, which I was previously completely unaware of.
India recently did a U-turn around wheat exports; first planning to have substantial exports and then needing to import wheat to deal with the bad crop. An Indian newspaper (a) makes the case that this was because of an over-reliance on an archaic system:
India’s U-turn on wheat exports is a result of incorrect estimates derived from an archaic crop forecasting system devised 4 centuries ago by emperor Akbar’s finance minister.
“When it comes to yield estimates, the budgets are so low that local revenue officials seldom visit the field for CCEs. There is hardly any use of ground truthing aided with satellites or remote sensing. Decisionmakers still rely on a system developed by Raja Todar Mal,” the official added.
CoinDesk has an introductory article (a) on prediction markets by friends of the newsletter Clay Graubard and Andrew Eaddy.
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman, and Alexey Guzey (a).
There's a storm comin' that the weatherman couldn't predict
— Eminem, Cinderella Man
You've won Nuño. I made an account. My comment on the Google Doc was (slightly edited):
Will add other thoughts and comments later.
Muahahahaha
To answer this:
I think that my answer is something like: Yeah, the difference between a 10% and an 85% becomes zero, but if this is e.g., existential risk per century, the difference doesn't really matter at the current margin, and both probabilities indicate that we should take many of the same actions.