Standard expected utility theory (EUT) assumes moral certainty, but also embeds epistemic/ontological uncertainty about the state of the world that may occur as a result of our actions. Harsanyi expected utility theory (HEUT) allows us to assign probabilities to our potential moral viewpoints, and thus gives us a mechanism by which to handle moral uncertainty.
Unfortunately, there are several problems with EUT and HEUT. First, the St. Petersburg paradox shows that unbounded utility valuations can justify almost any action, even if the probability of a good outcome is almost zero. For example, a banker may be in a situation where the probability of a bank run is nearly one, but because potential returns of being overleveraged in a near zero probability world are so high, the banker may foolishly still choose to be overleveraged to maximize expected utility. Second, diminishing returns typically force us to produce or consume more in order to realize the same amounts of utility; this is usually a recipe for us to consume and produce in unsustainable ways. Third, as Herbert Simon noted, optimizing expected utility is often computationally intractable.
A response of early effective altruism research to these problems was maxipok (i.e., maximizing probabilities of an okay outcome). Under this construct, constraints of an okay outcome are identified, a probability of satisfying those constraints is assigned to each action, and the action that maximizes the probability of satisfying the constraints is adopted.
The problem with maxipok is that it assumes moral certainty about the constraints of what constitutes an okay outcome. For example, if we believe a trolley problem is inevitable, one might infer it is an okay outcome for someone to die, given its unavoidability. On the other hand, if a trolley problem is avoidable, one may infer that someone dying is not okay. Thus in that overall scenario, what constitutes an okay outcome is contingent on what probabilities we assign to the inevitability of a trolley problem.
Success maximization is a mechanism by which to generalize maxipok for moral uncertainty. Let ai be an action i from the set of m actions A = {a1, a2, …, am}. Let sx be a definition of moral success, namely x, from S = {s1, s2, …, sn}. The probability π that i satisfies the constraints of sx is 0 ≤ πi(sx) ≤ 1. Let p(sx) be the estimated probability that x is the correct definition of moral success, where p(s1) + p(s2) + … + p(sn) = 1. Thus, the expected success of action i is 0 ≤ πi(s1)p(s1) + πi(s2)p(s2) + … + πi(sn)p(sn) ≤ 1. A success maximizing agent will choose an action aj є A such that πj(s1)p(s1) + πj(s2)p(s2) + … + πj(sn)p(sn) ≥πi(s1)p(s1) + πi(s2)p(s2) + … + πi(sn)p(sn) for all ai є A where i ≠ j.
Success maximization resolves many of the problems of von Neumann-Morgenstern and Harsanyi expected utility theories. First, because success valuations are bounded between 0 and 1, it is much less likely we will encounter St. Petersburg paradox situations where any action is justified by extremely high utility valuations despite near zero probabilities of occurrence. Second, unsustainable behaviors produced by chasing diminishing returns is much less likely in the world of maximizing probabilities of constraint satisfaction than it is in the world of maximizing unbounded expected utilities. Third, because probabilities of success are bounded between zero and one, terms of the linear combination (where p(sx) is relatively low) can often be ignored to make for quicker calculations, making calculations more tractable.
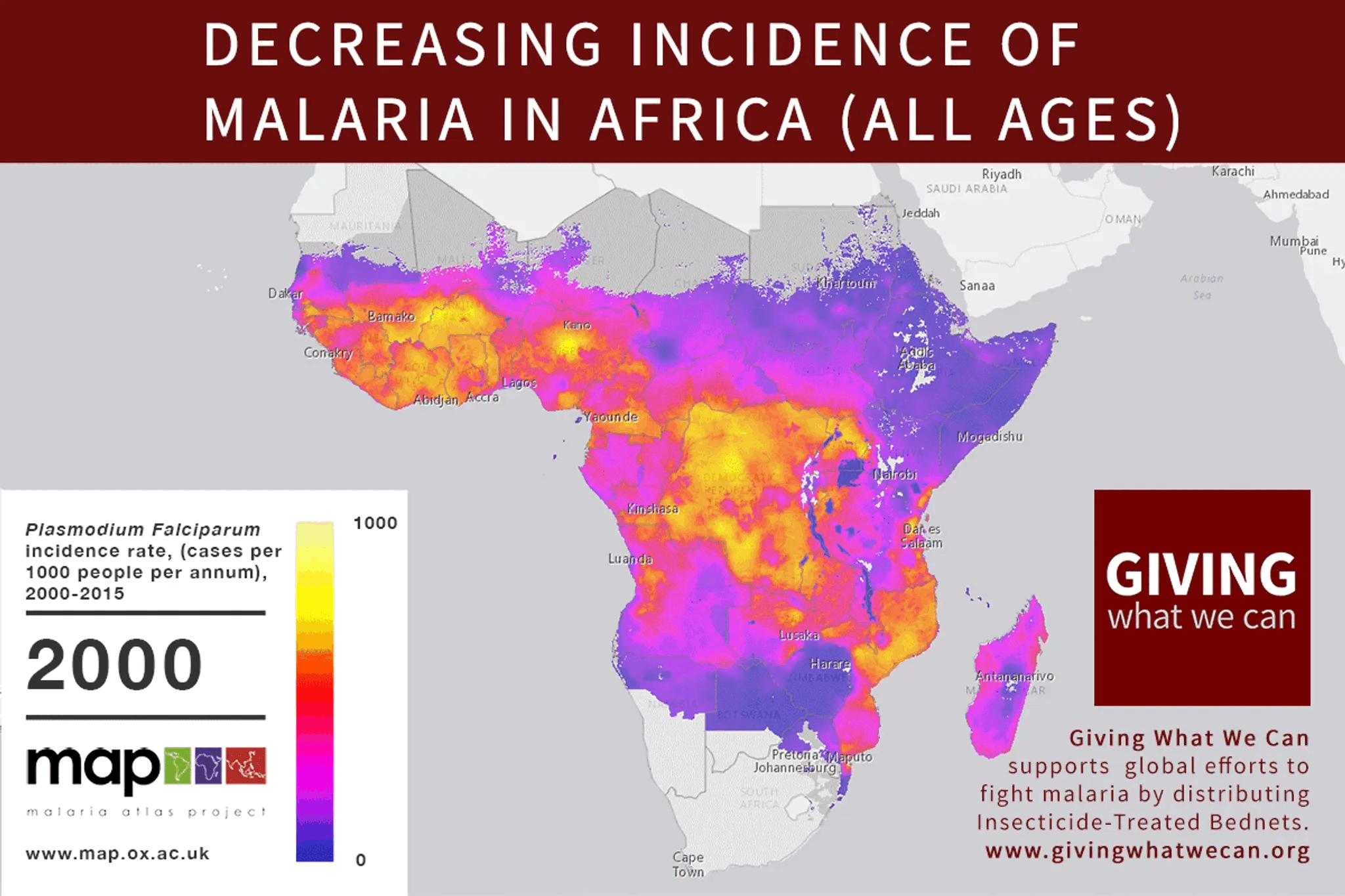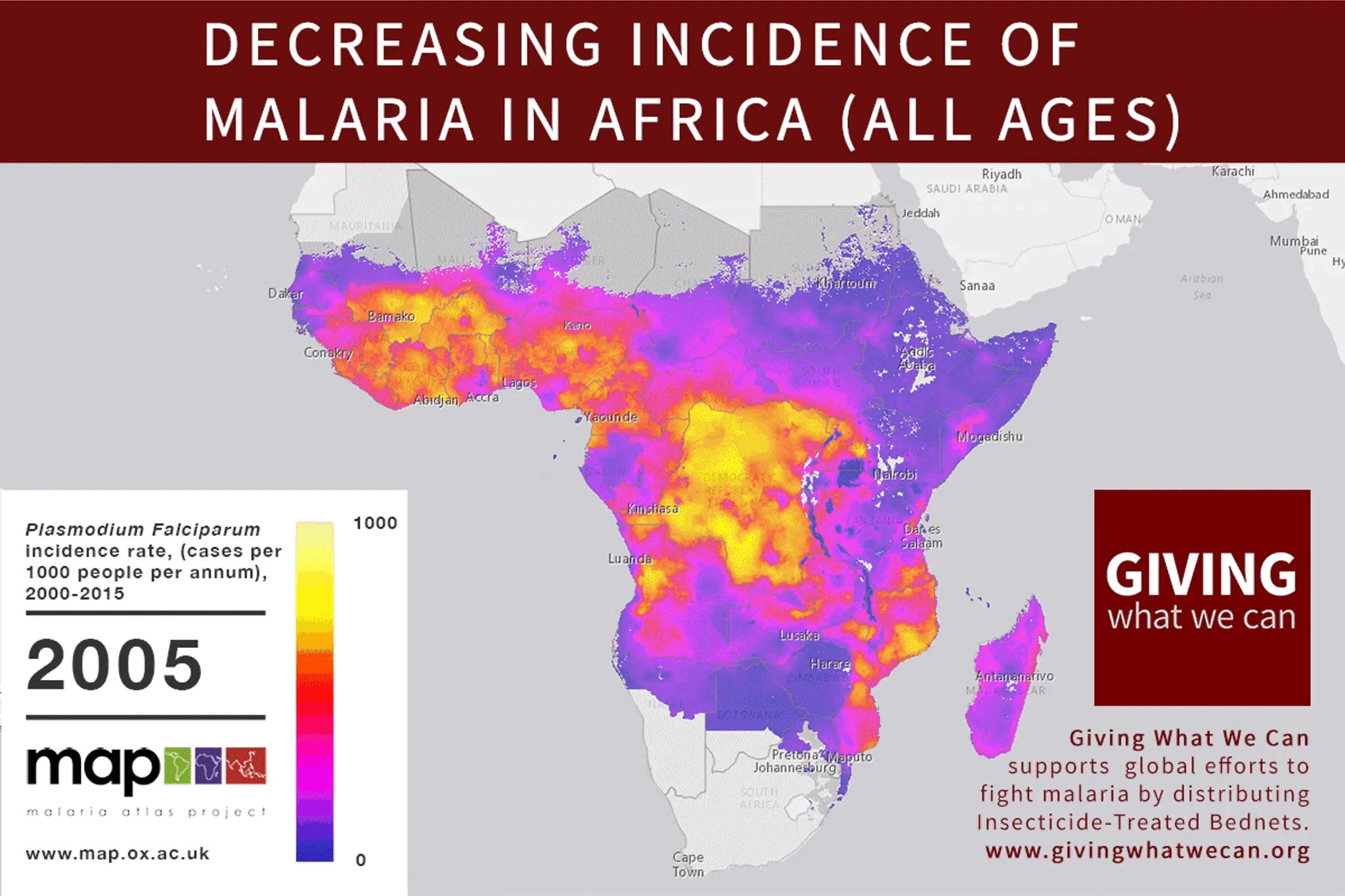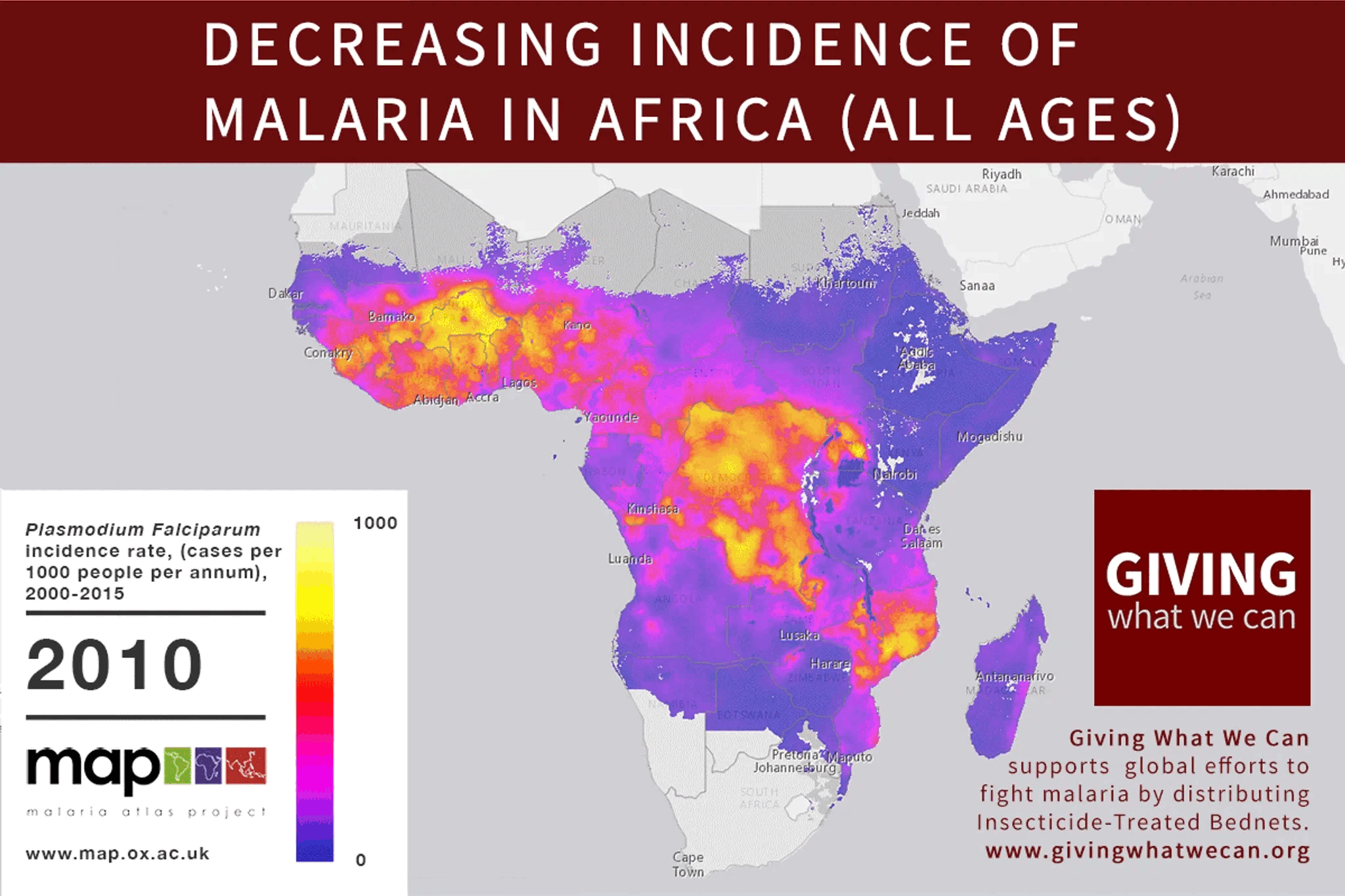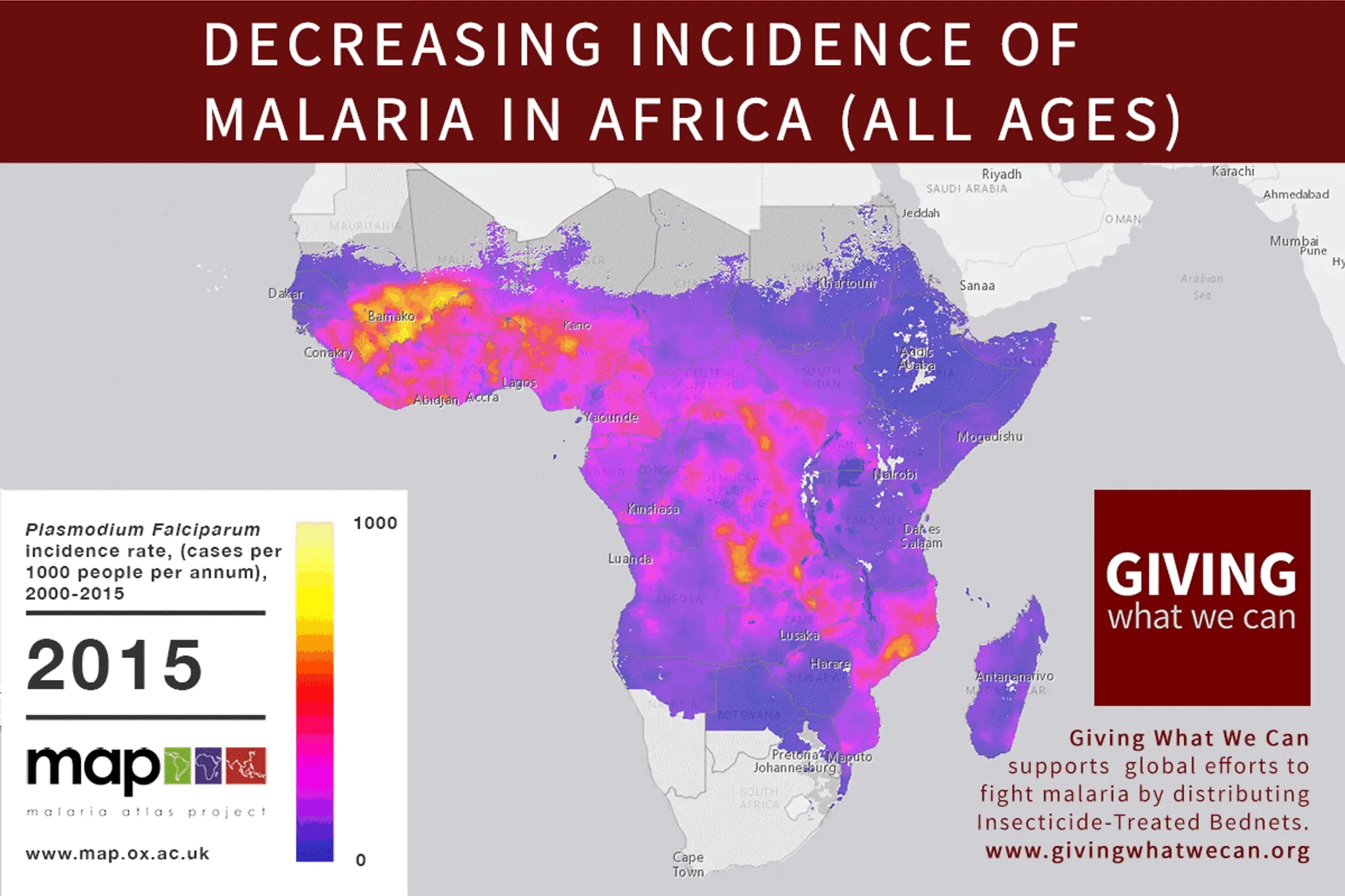

Inside-view, some possible tangles this model could run into: