Comments
Hey,
Is the material available somewhere so we can study it without the official course?
Thx
Edit: No, the material is not publicly available
Hey,
Is the material available somewhere so we can study it without the official course?
Thx
Edit: No, the material is not publicly available
If someone doesn't have much prior ML experience, can they still be a TA, assuming they have a month to dedicate to learning the curriculum before the program starts?
If yes, would the TA's learning during that month be self-guided? Or would it take place in a structure/environment similar to the one the students will experience?
It is possible but unlikely that such a person would be a TA. Someone with little prior ML experience would be a better fit as a participant.
This sounds really exciting!
I'm a bit unclear on the below point:
I think that MLAB is a good use of time for many people who don’t plan to do technical alignment research long term but who intend to do theoretical alignment research or work on other things where being knowledgeable about ML techniques is useful.
Do you mean you don't think MLAB would be a good use of time for people who do "plan to do technical alignment research long term"?
We intended that sentence to be read as: "In addition to people who plan on doing technical alignment, MLAB can be valuable to other sorts of people (e.g. theoretical researchers)".


Redwood Research is running another iteration of MLAB, our bootcamp aimed at helping people who are interested in AI alignment learn about machine learning, with a focus on ML skills and concepts that are relevant to doing the kinds of alignment research that we think seem most leveraged for reducing AI x-risk. We co-organized the last iteration of the bootcamp with Lightcone in January, and there were 28 participants. The program was rated highly (see below for more), and several participants are now working full-time on alignment. We expect to start on Aug 15 but might push it back or forward by a week depending on applicant availability.
Apply here by May 27.
We’re expecting to have space for about 40 participants. We’ll pay for housing, travel, and food, as well as salaries for the TAs. We will help you get visas to travel to the US for the bootcamp.
We’re now accepting applications for participants and TAs. TAs are expected to either know this material already or have a month free before MLAB to study all the content.
Last time the schedule was roughly the following:
This time, we’ll probably have more systematic transformer interpretability content, because we’ve spent a lot of time since MLAB doing our own transformer interpretability research and have a bunch more opinions now. We might also have more systematic content on various relevant math. I’m also hoping that we’ll be able to cover content more efficiently as a result of experience gained from running the program the first time.
Past participants report that MLAB was time-consuming; we strongly recommend against trying to juggle other commitments concurrently. About 8 hours a day, 5 or 6 (if you participate in the optional day) days a week will be spent on pair programming, in addition to daily lectures and readings. There is a lot of content packed into each day; not everyone will finish every part of the curriculum. We aim to create a learning environment that is focused but not frantic; we’d rather have you understand the material deeply than finish 100% of the day’s content.
The program is aimed at people who are already strong programmers who are comfortable with about one year’s worth of university level applied math (e.g. you should know what eigenvalues and eigenvectors of a matrix are, and you should know basic vector calculus; in this course you’ll have to think about Jacobian matrices and make heavy use of tensor diagram notation, so you should be able to pick up both of those pretty fast).
We expect that about half the attendees will be current students (either undergrad or grad students) and half will be professionals.
If you applied to the first cohort and were not accepted, consider applying again. We had many more applicants than spots last time.
Last time, we ended up hiring three people who attended MLAB as participants (as well as giving another person an offer that they turned down for a non-alignment EA job), and hired three people who had worked as TAs. Note that about ⅔ of attendees last time were students who were unavailable for immediate employment.
My guess is that MLAB is a pretty great opportunity for people who want to become more familiar with the concepts and practical details related to ML; I think that MLAB is a good use of time for many people who don’t plan to do technical alignment research long term but who intend to do theoretical alignment research or work on other things where being knowledgeable about ML techniques is useful.
TA-ing MLAB is a good opportunity for people with more prior knowledge of this material to connect with Redwood Research and the broader Bay Area alignment community, reinforce their understanding of the curriculum material, and movement-build by teaching others. It also pays competitively.
MLAB was well received:
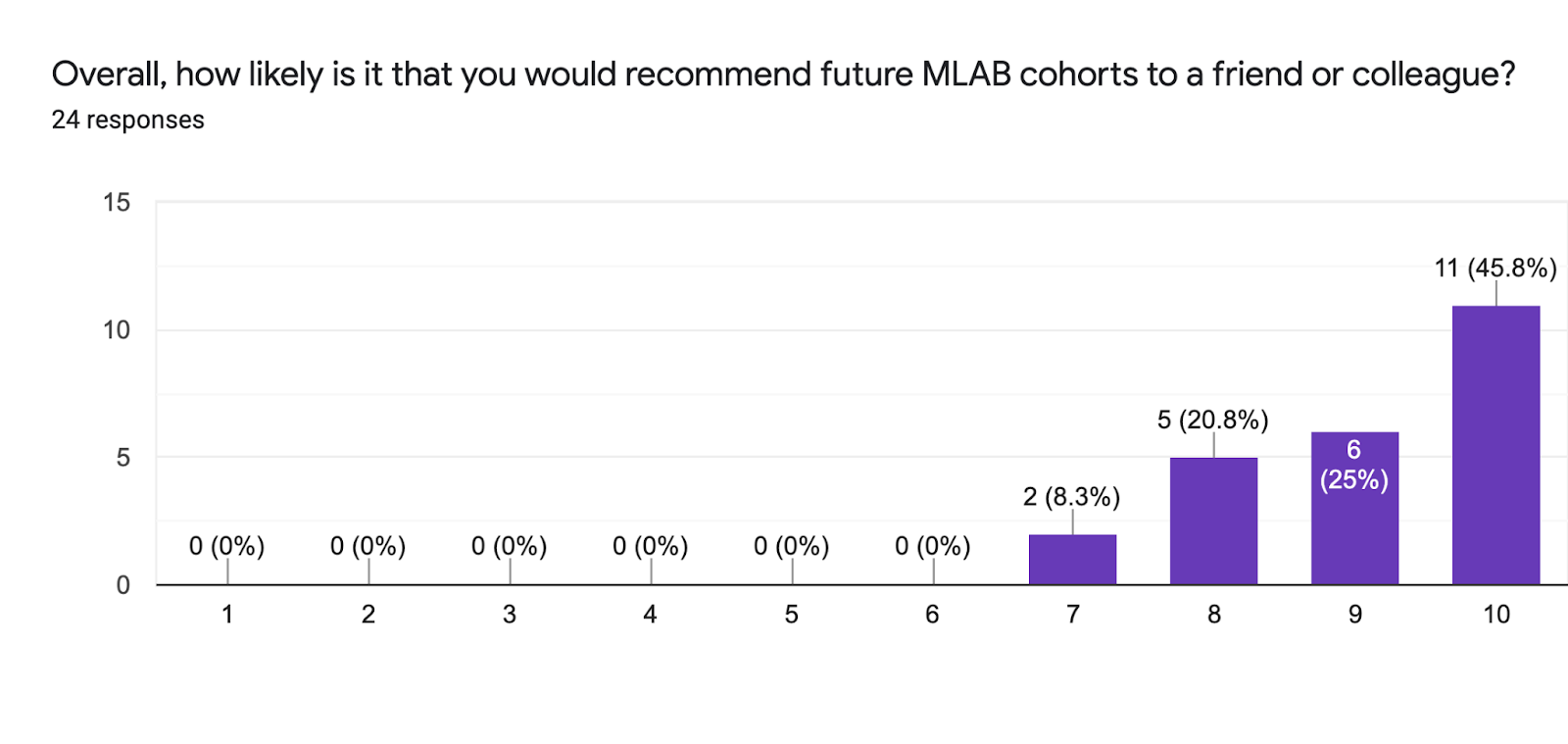
When we asked participants what they were surprised by, major themes were:
The bootcamp takes place at Constellation, a shared office space in Berkeley for people working on longtermist projects. People from several longtermist organizations often work from the space, including people from Open Philanthropy, MIRI, Redwood Research, the Alignment Research Center, and more.
As a participant, you’d attend semi-regular communal lunches and events at Constellation and have a great opportunity to make friends and connections.
If you join the bootcamp, we’ll pay for travel to Berkeley (for both US and international participants), housing and food.
Maybe! We encourage you to submit an application even if you can’t make those dates, and it is very much on the table to run future bootcamps like these if there’s an interest and the first one goes well.
It’s way more focused on learning by implementing small things based on a carefully constructed curriculum, rather than e.g. reading papers or trying to replicate whole papers at once. This difference in focus is mostly because I (Buck) believe that focusing first on these skills makes it much faster to learn, because you get way faster feedback loops. It’s also probably partially due to some of my beliefs about how to do ML research which are slightly unusual among ML people (though many of the ML people I’ve talked to mostly agree with me).
In Buck’s opinion not that different.
You fill out the form and then do some online tests then talk to one of us.
I (Buck) would guess that it’s pretty robust to being experienced. I personally feel like I learned some details I’m glad to know from preparing the curriculum, and I’d appreciate having an opportunity to drill a bunch of the skills taught. If you read the curriculum listed above and your response is “yawn, I already know all these things or don’t care about knowing them”, then probably you don’t want to do this bootcamp. I personally enjoyed App Academy quite a lot despite being more experienced than the other students. As I noted above, many people mentioned in the final survey that they were worried that they had too much background and were pleasantly surprised by the extent to which the content was useful anyway.
Yes.
Feel free to apply, but the selection process will strongly favour participants who want to work on AI alignment or other parts of effective altruism.
This overlaps with MLSS by a single week; you’re able to skip that last week of MLSS if necessary, which means that you can do both. You’ll have to sort out other conflicts yourself.
You can apply here. Feel free to send questions to Max Nadeau at [email protected]. Applications close on May 27.
As a fellow graduate of App Academy, I can certainly speak to and strongly recommend the full-time immersive workshop approach to learning a huge amount in a short time. That said, like many people I personally don't have the free time to focus on it full-time just yet. Any chance the curriculum (github repo?) could be made available for asynchronous solo progress?
I'm thinking of organizing an unofficial version of this in Finland. So this would be nice for sure :)