Comments
How Technical AI Safety Researchers Can Help Implement Punitive Damages to Mitigate Catastrophic AI Risk

5 min read · Feb 19, 2024
28
In the previous post, I explained how punitive damages could “pull forward” the expected liability associated with the uninsurable risks generated by training and deploying advanced AI systems. In this post, I lay out the details of my proposed punitive damages calculation, and suggest opportunities for technical AI safety researchers to lay the groundwork for implementing this proposal.
The goal of my proposed punitive damages framework is for the creators and deployers of AI systems to expect to pay out damages roughly equal to the amount of harm they expect to cause. Since the law cannot hold them liable in cases where uninsurable risks are realized, this is accomplished by applying punitive damages in cases of practically compensable harms that are correlated with those uninsurable risks. That is, punitive damages would be applied in the sort of cases where, if the companies involved expected to pay out large damages awards for causing practically compensable harms, the efforts that they would tend to engage in to reduce the likelihood or severity of those harms would, by default, tend to mitigate the uninsurable risks.
For example, consider an AI system tasked with running a clinical trial for a risky new drug. It has trouble recruiting participants honestly and, instead of reporting this to its human overseers, resorts to some combination of deception and coercion to get people to participate. Some of those deceived/coerced patients suffer some nasty health effects and they sue. This seems like a clear case of misalignment, and, in some sense, we got lucky that the system was willing to reveal its misalignment in a non-catastrophic way. Maybe it had narrow goals, or short time horizons, or limited situational awareness. But the people who trained and deployed it couldn’t have been confident ex ante that it would go down this way. Presumably, they thought the system was aligned or they wouldn’t have deployed it.
Say that training and deploying the system generated a 1 in 1 million chance of human extinction. Under my proposed framework, the defendant would have to pay out punitive damages equal to 1 millionth of the value of human extinction, across the cases of practically compensable harms correlated with that extinction risk. More generally, the share of punitive damages awarded to a plaintiff in any particular case S, would be given by the following formula:
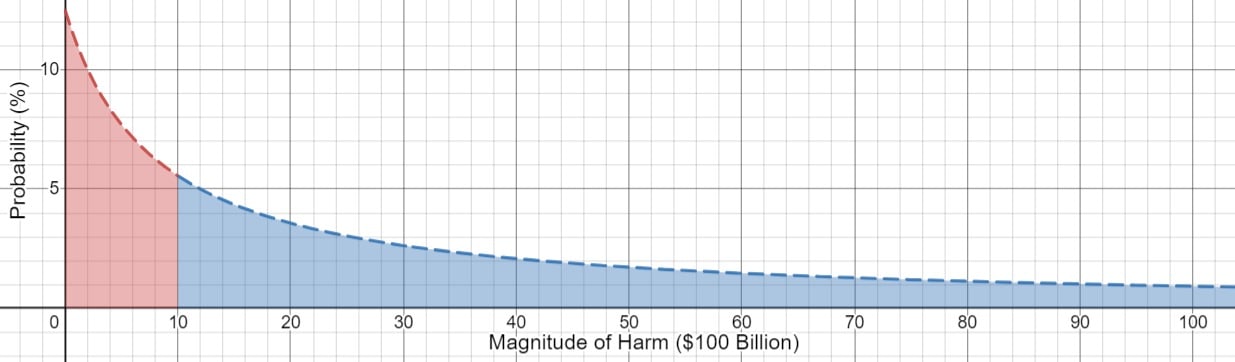
N is the total expected practically non-compensable harm arising from the defendant’s conduct, represented by the blue-shaded area in the graph below. CP is the plaintiff’s compensatory damages; the harm actually suffered by the plaintiff due to the defendant’s actions. Dividing this by CT, the total expected practically compensable harm caused by the defendant’s actions (the area shaded in red below), gives the plaintiff's share of expected compensatory damages.
EP is the elasticity of uninsurable risk with respect to the plaintiff’s injury. If precautionary measures that cut the plaintiff’s expected harm in half also cut the uninsurable risk in half, then the elasticity is equal to 1. If they only reduce the uninsurable risk by 10%, then the elasticity of 0.2. EA is the average elasticity of the uninsurable risk with respect to all practically compensable harms. So, EP/EA is the relative elasticity of uninsurable risk with respect to the plaintiff’s injury. So, the plaintiff’s share of punitive damage is equal to the total expected practically non-compensable harm, N, times the plaintiff’s share of expected compensatory damages CP/CT, times the relative elasticity of the uninsurable risk with respect to the plaintiff’s injury.
If juries are able to approximately implement this formula, then reductions in the practically compensable harm, CT, would only be rewarded to the extent that they reduce the total expected harm N + CT. Measures that reduce CT without reducing N would lower the defendant’s expected compensatory damages, but would not reduce their expected punitive damages payout unless they are able to eliminate any practically compensable damages. By contrast, measures that reduce N would be rewarded even if they do not reduce CT.
Of course, in order to implement this formula, we will need credible estimates of the various parameters. Juries routinely estimate plaintiff’s compensatory damages in tort cases, so that doesn’t present any novel issues, and estimating the total expected compensatory damages should also not be too difficult. Presumably, once a system has revealed its misalignment in a non-catastrophic way, it will be pulled off the market, and the risks associated with any modified version of the model would be addressed separately. So this is really just a matter of estimating how much legally compensable harm the system has actually done.
Estimating the total expected practically non-compensable harm, N, and the elasticity parameters, EP and EA, presents greater challenges. In the paper, I suggest that model evaluations could be used to appraise specific potential causal pathways that could produce an uninsurable catastrophe.
“For each pathway, one set of evaluations could estimate the probability that the system is capable of instantiating that pathway. Another set of evaluations could estimate the conditional probability that the system would take that pathway, should it be capable of doing so. The sum of the expected harm across these catastrophic misalignment and misuse scenarios would then represent a lower bound estimate of N, the uninsurable risks generated by training and deploying the system, since other scenarios not included in the evaluation might contribute to the total uninsurable risk. Beyond specific scenario analysis, other relevant indicators of uninsurable risk include the model’s power-seeking tendencies, inclinations to engage in deception and tool use, pursuit of long-term goals, resistance to being shut down, tendency to collude with other advanced AI systems, breadth of capabilities, capacity for self-modification, and degree of alignment.
The knowledge that a practically compensable harm has happened could help model evaluators like those at Model Evaluation & Threat Research (formerly part of the Alignment Research Center) and Apollo Research select catastrophic risk pathways to analyze, but their estimates of the probability of those pathways should not update based on the knowledge that the practically compensable harm event happened, since that knowledge was not available at the time the decisions to train and deploy the model were made. The fact that a practically compensable harm has occurred simultaneously raises the probability that the system was significantly misaligned or vulnerable to misuse and lowers the probability that catastrophic harm will arise from this specific system since it is now likely to be recalled and retrained. N is the expected uninsurable harm at the time that the key tortious act (training or deployment) occurred. That is, N represents what a reasonable person, with access to the information that the defendant had or reasonably should have had at the time of the tortious conduct, would have estimated to be the expected uninsurable harm arising from their conduct. There may not be one uniquely correct value of this uninsurable risk, but juries, relying on expert testimony, should nonetheless be able to select an estimate within the range of estimates that a reasonable person should have arrived at.”
More work is needed to implement these suggestions, and I invite members of this community to take it up. I’m happy to talk with anyone interested in working on this, and may even be able to help you secure funding. Feel free to contact me gweil2 at tourolaw.edu. The full draft paper is available at https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4694006.

Executive summary: The author proposes a framework for calculating punitive damages to incentivize AI developers to mitigate risks from advanced AI systems. Technical AI safety researchers can help implement this by analyzing potential catastrophic scenarios and estimating key parameters.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
On key point 5, I was offering to help secure funding, not asking for help.