This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...
TL;DR: I'm releasing a website that ranks philanthropists according to EA principles and research, and allows users to re-rank the list using their own assumptions. I'd like feedback and help making it better. I'd especially like ideas for how to make the results more trustworthy. Funding may be available.
Crossposted to LessWrong.
...
TL;DR: Marginal Victories is a new initiative to provide 1:1 career advising, opportunities, and resources for people exploring high-leverage U.S. democracy preservation and political work. Built by impact-oriented people doing pro-democracy work, the early MVP is now up at marginalvictories.org. Fill out the 10-minute form now to receive these resources as they become available over the next few...
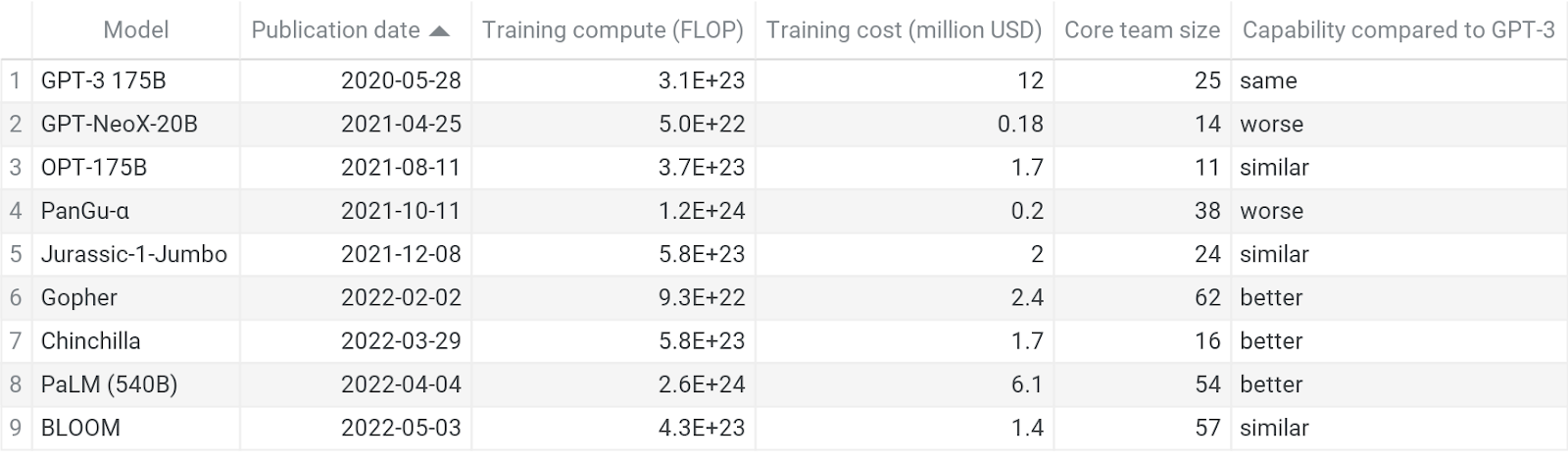
Table 1: comparison of resources required for GPT-3 and OPT-175B, which was intended to replicate GPT-3.
It took about 23 months until an actor that explicitly aimed to replicate GPT-3 succeeded and published about it (namely, Meta AI Research publishing OPT-175B in May 2022). The only other explicit replication attempt I am aware of has not succeeded; this is the GPT-NeoX project by the independent research collective EleutherAI. Other actors produced GPT-3-like models as early as May 2021 (12 months after GPT-3’s publication) and throughout the subsequent year. These were not explicit replication attempts, but they are evidence of which actors are capable of replication. (more)
In Table 1, I estimate the compute cost, talent, and time required to produce and replicate GPT-3. To estimate the requirement for replication, I used OPT-175B as the canonical example. (more)
In addition to the above estimates, I find that following Hoffmann scaling laws leads to a roughly 3x decrease in compute cost to produce a GPT-3 equivalent, compared to using the same model size and training tokens as the original GPT-3. (more)
In addition to reducing compute, Hoffmann scaling laws predict a much smaller model size (I estimate 15 billion parameters) to match GPT-3 performance, which reduces the engineering talent requirement and the inference cost.
Given this reduced cost, actors like EleutherAI seem capable of replicating GPT-3 now (December 2022), as long as they can collect a large enough dataset to train effectively on ~1 trillion tokens (which seems like a significant but much smaller obstacle than the compute and engineering requirements).
The above estimates assume a fixed set of circumstances. In reality, compute and talent requirements are partially exchangeable. Given a total compute budget (including preliminary work) of about $2 million to replicate GPT-3, I think only the top AI labs (e.g., Google Research, DeepMind, OpenAI)—with their top talent for training large language models—would be able to successfully replicate GPT-3 by May 2022. In contrast, given a total compute budget of about $10 million, I estimate that an actor would only require about four people with two years of collective full-time experience in training billion-parameter-scale language models. (more)
I’m 85% confident that in the two years since the publication of GPT-3, publicly known GPT-3-like models have only been developed by (a) companies that focus on machine learning R&D and have more than $10M in financial capital, or (b) a collaboration between one of these companies, academia, and a state entity. That is, I’m 85% confident that there has been no publicly known GPT-3-like model developed by actors in academia, very small companies, independent groups, or state AI labs that are entirely in-house. (more)
One case of collaboration between a company, academia, and a state entity was the BLOOM project. The AI company Hugging Face (which has received at least $40M in seed funding) seems primarily responsible for initiating the BLOOM project and developing the model. The project also received more than $3M in funding for training compute from French state research agencies.
State AI labs that are entirely in-house may have been capable of replication during these two years. But based on the case of BLOOM, and cases from China such as PanGu-alpha and ERNIE 3.0 Titan, I think that states currently prefer to sponsor existing talented organizations rather than run the projects in-house. It’s plausible that there have been secret projects in the intelligence community to develop GPT-3-like models, but I am not aware of any.
Key information on the language models I studied
Table 2: Key information from the language model case studies. Columns from left to right: the model name, the date that the model was first published about, the training compute used in FLOPs, the actual compute cost of the final model training run (in USD), the size of the core team that developed and evaluated the model,[4] and how the model compares in performance (in a broad sense) to GPT-3.[5]Most of the data are estimates and best guesses.[6] Click through to the diffusion database for more information on what the data mean and my reasoning process.
Introduction
In the previous post in this sequence, I explained that at least one GPT-3-like model, OPT-175B, could be directly accessed by many AI researchers as early as May 2022 (see the previous post). But based on GPT-3, Gopher, PaLM and other models,[7] future state-of-the-artlanguage models will probably continue to not be released by their creators in order for the developers to maintain competitiveness with other actors. It is therefore useful to understand what was required for various actors to produce a GPT-3-like model from scratch, and the timing of various GPT-3-like models being developed. To that end, the section The resources required to produce and replicate GPT-3 presents estimates of the compute cost and talent required to replicate GPT-3 and explores the relationship between those two resources. The section Lessons from the timing, affiliations, and development process of models that emulate or replicate GPT-3 examines the development of GPT-3-like models (or attempts at producing them) since GPT-3’s release. Some of these models are the result of explicit attempts to closely replicate GPT-3, while other models highlight the relationship between diffusion and the ability to produce state-of-the-art capabilities.
The resources required to produce and replicate GPT-3
In Table 1, I estimate the compute cost, talent, and time required to produce and replicate GPT-3. To estimate the requirement for replication, I used OPT-175B as the canonical example. These estimates are not the only possible requirements to produce a GPT-3 equivalent model (even approximately). This is because different actors face different circumstances (e.g. access to hardware), and talent and compute are somewhat exchangeable. (I discuss the relationship between talent and compute further below.)
In addition to the specific cases of GPT-3 and OPT-175B above, I estimated the requirements to replicate GPT-3 by May 2022 in a hypothetical “average” case. However, I believe this is less useful, so I left that estimate in this appendix.
What do Hoffmann scaling laws mean for replication costs today?
I also estimated the compute cost of the final training run to produce a GPT-3 equivalent model via Hoffmann scaling laws (the scaling laws that DeepMind’s Chinchilla model was based on), which were published in March 2022 (Hoffmann et al, 2022). I find thatfollowing Hoffmann scaling laws leads to a roughly 3x decrease in compute cost to produce a GPT-3 equivalent, compared to using the same model size and training tokens as the original GPT-3. Details of this calculation are in this appendix (note that I did not spend as much time on this cost estimate as the cost estimates reported above). Given that Hoffmann scaling laws were only published in March 2022, and OPT-175B took an estimated 78 days to produce, it probably was not possible for anyone other than DeepMind to produce a GPT-3 equivalent model this way by May 2022. However, it is certainly possible now.
In addition to greatly reducing compute, Hoffmann scaling laws require much smaller model size (I estimate 15 billion parameters) to match GPT-3 performance, which reduces the engineering talent requirement and the inference cost. For reference, the independent research collective EleutherAI succeeded at training a 20 billion parameter GPT model, using an estimated 9.3E+22 FLOP of compute, which is roughly 3x that of GPT-3.So although they were not capable of replicating GPT-3 before February 2022, an actor like EleutherAI seems capable of doing so now as long as they can collect a large enough dataset (which seems like much less of an obstacle than the compute and engineering requirements).
Qualitative assessment of talent requirements
Based on rough accounting of the various core team sizes and expertise involved in projects that developed GPT-3-like models, I think that the core team developing a GPT-3-like model requires at least two years of collective experience in training language models with billions of parameters or more, including specific expertise in training efficiency and debugging for neural networks at that scale.
A major part of the talent requirement is what I call an “infrastructure engineering contributor.”[8] I found that the proportion of infrastructure engineering contributors needed on teams that produced GPT-3-like models was about 40% (90% CI: 15–60) (reasoning). The rest of the team is made up of ML engineers not specializing in infrastructure, and ML researchers.
Talent saves compute costs: the best AI lab could do it for $2 million; a few good hobbyists need $10 million for the first attempt
The division of compute cost and talent above is specific, rather than the only way the resources can be divided up. The level of talent and the cost of compute are related. So in addition to the specific cases above, I developed a simple theoretical model where increasing talent tends to increase training efficiency, decrease compute spent on things other than the final training run, and decrease the cost per FLOP of compute.[9]In summary, my model implies the following:[10]
A total compute budget of $2M (90% CI: $0.5M–$5M) to produce a GPT-3 equivalent model by May 2022 would require talent and hardware assets that are only available to leading AI labs. Such a team would need prior experience with training a very similar language model.
With more than 80% confidence, I’d put Google Research, DeepMind, and OpenAI in this category, and with more than 10% confidence, I’d include Microsoft Research, MetaAI Research, Anthropic, and Baidu Research.
Given a total compute budget of $10M (90% CI: $3M–$30M), training a GPT-3 equivalent model becomes feasible by four people with two years of collective full-time experience with billion-parameter scale language models (at a rough estimate).
A $10 million budget seems out of reach if the team is not in an industry AI lab.
However, it’s still plausible that a team could be sponsored with the necessary hardware, perhaps by a state agency. I put a 10% probability on a Western state agency providing funding of $10 million or more to an academic AI research group to train a large language model, in the next 5 years (a somewhat arbitrary time window; I become much more uncertain about how state interests will change beyond 5 years.) That probability is based on my intuition, informed by one example: French state research agencies funded roughly $3 million to BigScience for the training compute of BLOOM.[11]
I’m 70% confident that these implications are roughly accurate. My estimates of talent in (1) and (2) above are informed by the case study of GPT-3-like models—mostly Google’s PaLM for (1) and EleutherAI’s GPT-NeoX-20B for (2). The specific cases don’t closely match the above hypotheticals, so I made an intuitive judgment. The model is flawed due to its simplicity; for instance, the hardware utilization that a team can achieve does not actually seem linearly related to the team’s level of experience, though it does seem positively correlated. There are also complicated dependencies and missing factors that are not part of my model of the talent-compute relationship.
Follow-up questions
I think the following questions are high priority to further investigate the compute and talent requirements of GPT-3-like models (and state-of-the-art machine learning models in general):
How much of a barrier is acquiring talent if an actor does not already possess the required talent? How does that vary for different actors e.g., governments and startups? (For some tentative thoughts, see this appendix.)
What is the willingness of different actors to pay for training of state-of-the-art models? How would that depend on the potential revenue generated by those models? (For some tentative thoughts, see this appendix.)
Lessons from the timing, affiliations, and development process of models that emulate or replicate GPT-3
I surveyed all the models I could find up to September 1, 2022 that plausibly met my definition of “GPT-3-like model” (see this appendix for the survey). I identified 13 models that met the definition. In this section I summarize my takeaways from this survey. Note that not all models in my case studies are GPT-3-like, and not all GPT-3-like models are in my case studies. The case studies had more of an in-depth investigation than the other models in my survey.
It took 7 months until a language model better than GPT-3 was produced
I’m 90% confident that Gopher was the first pretrained language model to be produced that outperforms GPT-3. Gopher was produced seven months after GPT-3’s existence was publicized in May 2020 (Brown et al., 2020). See this appendix for more information.
No model exists yet which is both better than GPT-3 and immediately available to download from the internet
I’m 90% confident that no model exists which is (a) uncontroversially better than GPT-3 and (b) has its model weights immediately available for download by anyone on the internet (as at November 15). However, GLM-130B—publicized in August 2022 and developed by Tsinghua University and the Chinese AI startup Zhipu.AI (Tsinghua University, 2022)—comes very close to meeting these criteria: I think it is probably better than GPT-3, but still requires approval to download the weights. See this appendix for further explanation.
It took two years until an actor that explicitly aimed to replicate GPT-3 succeeded and published about it
To my knowledge, Meta AI Research was the first actor that explicitly aimed to replicate GPT-3 to succeed and publish about it, with OPT-175B (Zhang and Zettlemoyer, 2022). This was published in May 2022, about 23 months after GPT-3 was published in May 2020. The only other project that clearly aimed to replicate GPT-3 (and not pursue some lesser or tangential goal) is the GPT-NeoX project by the independent research collective EleutherAI (Leahy, 2022). This project has not succeeded at replication. See this appendix for supporting information.
Other actors produced GPT-3-like models as early as May 2021 (12 months after GPT-3’s publication) and throughout the subsequent year. These were not explicit replication attempts but they are evidence of which actors are capable of replication. See this appendix for more information.
For future work, it would be useful to study cases other than GPT-3 to get a sense of how these rates of emulation and replication compare to typical rates. However, the absolute amount of time taken is still relevant to AI governance—a 1 year lag time vs. a 5 year lag time greatly affects the level of urgency that should be applied to reducing harms from diffusion.
GPT-3-like models have only been developed by well-funded companies that develop AI, or in collaboration with them
I surveyed all the models I could find up to September 1, 2022 that plausibly met my definition of “GPT-3-like model” (see this appendix for the survey). I identified 13 such models.[12] Based on this, I am 85% confident that all publicly known GPT-3-like models were developed by either
A company that focuses on machine learning R&D and has more than $10M in financial capital[13]
A collaboration between a company meeting the criteria in (1) and at least one of the following:
An academic AI lab
A state entity (e.g., a state research agency that provides funding)
Conversely, I am 85% confident that GPT-3 has not been replicated solely by actors in academia, very small companies, independent groups, or state AI labs that are entirely in-house.
One case of a collaboration between a company, academia, and a state entity was the BLOOM project (BigScience, 2022). The AI company Hugging Face (which has received at least $40M in seed funding) seems primarily responsible for initiating the BLOOM project and developing the BLOOM language model. The project also received more than $3M in funding for training compute from French state research agencies (see this appendix for details).
State AI labs that are entirely in-house may have been capable of replication during these two years. But based on the case of BLOOM, and cases from China such as PanGu-alpha and ERNIE 3.0 Titan, I think that states currently prefer to sponsor existing talented organizations rather than run the projects in-house. Forming an in-house team is probably more difficult due to government being less attractive to top AI talent on average (I discuss this consideration in this appendix). However, I am highly uncertain about this, because I expect the intelligence community to be generally more secretive about any AI projects they undertake. It’s plausible that there have been secret projects carried out by the intelligence community to develop GPT-3-like models, but I am not aware of any.
Limiting access to compute is a promising way to limit diffusion
While several actors have succeeded at developing GPT-3-like models (see this appendix), compute cost seems to be an effective bottleneck for other actors. In this case, access to compute was apparently limited or expensive enough to prevent release of GPT-3-like model weights for about two years. The incentive for actually trying to produce a GPT-3-like model from scratch is difficult to measure, but as I pointed out at the start of the previous post, the incentive was high enough for some actors, such as Meta AI Research and BigScience, to spend millions of dollars on it, and I estimate there are at least 10 GPT-3-like models in existence. Combined with the importance of scaling compute for improving AI capabilities (see e.g. Kaplan et al., 2020, and Sutton, 2019), this information has strongly influenced my overall impression that access to compute is the largest bottleneck to diffusion, and will continue to be up until the development of Transformative AI. This is a core part of my view that future state-of-the-art pretrained language models will be at least as difficult to replicate as GPT-3. On this view, limiting access to compute is a promising way to mitigate the harms of diffusion (this kind of intervention falls under compute governance).
Attention to information is just as important as the sharing or publication of information
Overall, one of my conclusions from the effect of GPT-3 and the timeline of GPT-3-like models is that attention to information is just as important as the sharing or publication of information (in the context of AI diffusion). DeepMind seemed to be already noticing the full significance of scaling up language models by the time OpenAI publicized GPT-3, and that helped them pass GPT-3’s capabilities the fastest, producing a better model in seven months. In contrast, Google did not seem to be paying as much attention to language model scaling, taking an estimated 18 months to surpass GPT-3 in the form of PaLM. At the same time, Google was able to catch up quickly, and now seems to be putting more resources into language model scaling than OpenAI and DeepMind.[14] In short, OpenAI was paying more attention than DeepMind,[15] who was paying more attention than Google. See the Gopher case study and PaLM case study in the appendix.
Note that the level of publicity and hype around an AI result is a major driver of attention. I explore the role of hype in a section of a later post. The takeaway from that section is that the hype generated by the API for GPT-3 seemed to accelerate the diffusion of GPT-3-like models significantly.
The upshot is that to beneficially shape the diffusion of AI technology, AI developers ought to consider whether and how they draw attention to particular information in equal measure to whether and how they publish particular information and resources.
Over two years, GPT-3 ended up about seven times cheaper to replicate than the original result, and easier to figure out due to published information and open-source software
My estimate for the actual training cost of the final training run for the original GPT-3 is $12M (90% CI: $5M–$33M). Meanwhile, my estimate for OPT-175B, which replicated GPT-3 in May 2022, is $1.7M (90% CI: $1.5M–$2.3M)—roughly seven times cheaper according to my best guess. The main driver of this is improved GPU price performance. The actual GPT-3 training run used NVIDIA V100 GPUs, but OPT-175B and other more recent GPT-3-like models were trained on A100 GPUs.[16] A100 and V100 GPUs currently have a similar price on Google Cloud. However, A100 can be up to six times more efficient than V100, since
V100 has about three times slower peak throughput (125 teraflop/s vs. 312 teraflop/s)
V100 has less than half the memory capacity of the 80GB A100 chip, at 32 GB, therefore requiring over two times the number of chips to fit a model in memory.
Improvements in hardware price-performance are a key background driver of diffusion. Eventually, costs fall enough for replication to be viable. But that highlights why diffusion speed is important. Diffusion may always happen eventually due to efficiency improvements, but other factors will affect who can keep up with the state-of-the-art within six months, one year, and so on.
The technical challenge for a given actor to replicate GPT-3 has also decreased. This is due to more publicly available insights and open-source software. In particular, Narayanan et al. (2021), first published in April 2021, describes “how different types of parallelism methods (tensor, pipeline, and data parallelism) can be composed to scale to thousands of GPUs and models with trillions of parameters” (see Abstract). The accompanying open-source software, Megatron-LM, helps developers apply these insights. Megatron-LM and another open-source tool called DeepSpeed were used extensively to train GPT-NeoX-20B, OPT 175B, Jurassic-1-Jumbo, and BLOOM. Sid Black, who was the largest contributor to training GPT-NeoX-20B, told me (paraphrasing) that although he had qualms with Megatron-LM and DeepSpeed,[17] Megatron-LM is “really fast” and he was glad to have these tools available when developing GPT-NeoX-20B. In a section of a later post, I further discuss how the accumulation of publicly available insights and resources like Megatron-LM accelerates the diffusion of trained models.
Appendix: Cost of training a GPT-3 equivalent from scratch by May 2022
In this section I present an estimate of the cost to replicate the final training run of GPT-3 in the “average” case. I am effectively (but not explicitly) taking the average of a distribution of costs that different actors might incur to successfully replicate GPT-3, given their varying levels of talent, luck, and access to hardware.
Ultimately I felt that this “average” estimate was not as valuable as estimates of the actual training cost of specific models, so I confined it to this appendix. I think the actual training costs of specific models are more relevant to specific concerns. For instance, if we are concerned with how easy it is for the top AI developer to develop the next state-of-the-art model, then the relevant question is “how much does this model cost for the leading actor”. Meanwhile, if we are concerned with how easy it is for a model to diffuse among relatively untalented malicious actors, then “how much would this cost for a group of amateurs” is more relevant. There are individual cases of (near-)GPT-3-like models which answer each of these questions better than the “average” estimate.
Having said all that, my reasoning and calculations for the “average” estimate are detailed below.
Training compute cost (average case): $2.6M (90% CI: 1.4M–5.3M)
Calculator: 2022-08-28 Copy of Interface - Cost of 2022 ML Models (The original copy of the calculator was created by Malte Schrödl and Lennart Heim; I did not modify the calculator. Feel free to request access to this, and I may or may not grant it.)
Estimate 1: based on other models’ training costs
Method 1: most similar and most recent model
The most similar and most recent model is OPT 175B
My central estimate for the training cost of OPT 175B is $1.7M (90% CI: 1.5M–2.3M). See Training cost estimation reasoning for reasoning.
Method 2: Actual cost of GPT-3
My estimate is $12M (90% CI: 5M–33M)
This is almost certainly too high for the 2022 cost given improvements to hardware. GPT-3 was trained using V100 GPUs; there is now hardware that is an order of magnitude faster than V100 (e.g., NVIDIA A100—can see this by comparing training costs for the two hardware models in the cost calculator).
Method 3: arithmetic mean of similar models
Criteria for similar models: must be GPT-3-like, perform comparably or better to the original GPT-3
I'll choose Method 1 alone (rather than ensemble the methods) because Method 3 does not seem to add much information. I think it is better here to choose the most representative case rather than aggregate cases that have quite different circumstances.
Final result: $1.7M (90% CI: 1.5M–2.3M) (using Guesstimate to propagate the confidence interval, so the calculation is not direct)
Estimate 2: a wider CI of $0.5M to $8.1M
Here I estimate a wider CI that accounts for wider variation in compute costs (e.g., owned vs. rented hardware), and engineering talent (i.e. different hardware utilization rates achieved).
Upper bound
Assumptions
Poor utilization: 20%
FP16 precision in model weights
Uses 3rd-party cloud provider
No discount on cloud compute
Uses the cheapest cloud provider, and the hardware that gives the lowest cost
Wastes 50% of compute due to mid-training restarts at earlier checkpoints (so double the amount of compute)
Then the calculator gives a result of $4,055,778.134 using NVIDIA A100 with Google Cloud.
Double that amount due to wasted compute => ~$8.1M
Final result: $8.1M
Lower bound
Assumptions
Amazing utilization: 50%
FP16 precision in model weights
Uses in-house hardware (estimated by taking 30% of the cost of the cheapest option from any cloud provider)
Training succeeds in one uninterrupted run
Then the calculator gives a result of $1,622,311.254 * 30% = $0.5M, using NVIDIA A100 with Google Cloud.
Overall assumptions (these assumptions apply even to the estimated confidence bounds, unless otherwise stated)
I am conditioning on actually succeeding at training a model with comparable performance to GPT-3.
I used the original estimated compute cost of GPT-3: 3.1E+23 FLOPs.
My estimate aggregates over costs that were estimated according to different circumstances, e.g., having in-house hardware for training vs. renting hardware on the cloud. To estimate the cost for particular circumstances, we could make more specific assumptions to get a more accurate estimate for that case.
Training compute cost using Hoffmann scaling laws: $0.29M (90% CI: $0.12M–$0.78M)
The estimate in the previous section assumed that the compute required to train a GPT-3 equivalent is the same as for the original GPT-3: approximately 3.1E+23 FLOPs. However, Hoffmann et al. (2022) (the paper that introduced the Chinchilla model) presented updated scaling laws. These scaling laws suggest that GPT-3 equivalent performance can be achieved by training a smaller model on more tokens, but with significantly less compute overall.
To see this, first note the formula for the empirical scaling law (derived via “Approach 3” in Hoffmann et al. 2022—see p.25), describing the loss L of the model on the validation dataset as a function of the number of model parameters N and number of training tokens D:
L(N,D)=1.69+406.4N0.34+410.7D0.28
If we substitute the GPT-3 parameters N = 175 billion and D = 300 billion, the loss predicted by this formula is approximately 2.0025. However, this is not the optimal value of N and D (in terms of minimizing compute) according to this scaling law. Compute can be approximated by C = 6ND (see the “Efficient frontier” section on p.7 of Hoffmann et al. 2022), so we can express L(N, D) as L(N) by substituting C/6N for D and assuming that C is held constant. If we then decrease C until the minimum of L(N) coincides with GPT-3’s predicted loss of 2.0025, the resulting value of compute is approximately 1.05E+23 FLOP and the value of N at that minimum point is approximately 15E+9 parameters.[18] In turn, the resulting value of D is 1.05E+23 / (6 * 15E+9) ~= 1.17E+12 tokens. Doing the equivalent procedure with L(D) instead of L(N) has the same result. See this spreadsheet and this plot for further details.
This new compute estimate of 1.05E+23 FLOP is about 3x lower than the original GPT-3 FLOP of 3.1E+23. Consequently, I estimated the cost of the final training run for a GPT-3 equivalent model using Hoffmann scaling laws to be only $0.29M (90% CI: $0.12M–$0.78M) if the developer has direct access to the hardware (i.e. not cloud computing), and $0.96M (90% CI: 0.38M–2.6M) if the developer uses cloud computing without any discount applied. See this document for details of the calculation.
Clearly, this is a much lower cost than the original estimate. I expect this lower cost is feasible for about 10x more actors than previously thought (just based on the rough heuristics that (a) the cost is decreased by ~3x, (b) capital is distributed according to a power law, so the decrease in cost corresponds to a disproportionate increase in actors). So given that roughly 10 actors actually developed GPT-3-like models between May 2020 and August 2022, and if we ignore talent as a barrier, then I expect about 100 more actors will develop GPT-3-like models in the next 2 years (i.e. until August 2024). However, if I then intuitively account for talent as a barrier (see the next section), I would reduce this estimate to 20 actors.
Note that I spent more time on the original cost estimate than this estimate, so this estimate should be taken with lower confidence.
Talent requirement (average case): 10 (90% CI: 4–20) members on the core team
“Core team” means the number of people directly involved in producing the original result. "Producing the original result" includes evaluation of the trained model on main performance benchmarks, but not evaluation of social fairness, bias and toxicity, nor broader impacts, nor pure commentary about the model. The reason is that the latter things do not seem directly relevant to producing the model or advancing capabilities.
Central estimate
Take the mean of the “Core team size” for selected models in the database
Result: 30
This seems too high as a “requirement”
I have this sufficient number of 11 peoplein the core team, from the OPT project. That seems like a sensible central estimate. I’ll choose 10 people just to be round. There was probably enough redundancy in the OPT team for 10 people to still be enough.
90% CI: 4–20
Lower bound
OPT 175B had a core team size of 11
Plausible: four people
EleutherAI trained a 20-billion-parameter equivalent of GPT-3.
Sid Black told me the GPT-NeoX team was more bottlenecked on compute than talent. I interpret this as if they had access to enough compute, they could have replicated GPT-3 by February 2022 (when GPT-NeoX-20B was published). I’m 65% confident in that claim. Sid would have a better understanding of the requirements to train a 175-billion-parameter model than me, but it seems easier to underestimate than overestimate those requirements before you actually succeed at it.
Sid Black indicated to me that he made the majority of contributions to developing GPT-NeoX-20B, followed by Stella Biderman at less than half of his contribution, and so on in decreasing levels of contribution. This information was corroborated by Stella Biderman. But contributors to other GPT-3-like models were probably distributed like this as well (i.e., a few big contributors and many smaller contributors). So I wouldn’t say the core team size could just be two, but four seems reasonable.
Upper bound
GPT-3 itself had an estimated core team size of 25, based on contributions listed in the paper.
It became significantly easier to replicate over the last two years due to the cascade of published info, software tools, intermediate-sized models, and the cost of hardware.
Thus, I would not go higher than 20 people needed to succeed by May 2022.
Note the reason this is higher than actual “core team size” for specific cases is that again, I’m averaging over many possible teams that could succeed at replicating GPT-3, each of which have different levels of talent.
The average of the numbers that are populated in this database column is 40%.
A 90% CI for that same sample was computed assuming those numbers were drawn from a normal distribution—see this cell. But intuitively I found this 90% CI too narrow, so I widened it.
Note: I think the 90% CI is fairly reliable for my sample and my definition of “infrastructure engineering contributor.” The larger uncertainty lies in whether my definition of “infrastructure engineering contributor” is the most useful category to consider.
Appendix: A model of the relationship between budget, compute, and talent, and its implications
Consider this model of the total compute budget B for a project to develop a machine learning model:
B=KCfinal
where Cfinalis the cost of compute for the final training run, and K is a multiplier that accounts for how much additional compute was spent on preliminary work (e.g., experiments, tests, failed runs) before the final training run and evaluation after the final training run.
The model I used to estimate training compute cost was the following:[19]
Cfinal=QCFLOP
where B is the training compute cost, Q is the training compute in FLOP, and CFLOP is the cost per FLOP of training compute. In turn, I modeled the cost per FLOP of training compute as
CFLOP=U−1DCrent-on-demand
where Crent-on-demand is a cloud compute provider’s cost per FLOP for renting the hardware on-demand. On-demand means that the user makes no commitment for how long they will rent the hardware. D is the discount factor applied to this base price—either because the user makes a commitment to rent, or because the user owns the hardware. For example, a one-year commitment on Google Cloud yields a 37% discount relative to the on-demand price.[20] I made a simplifying assumption that owning the hardware always translates to D = 0.3, i.e., a 70% discount relative to the on-demand rental price.[21]U is the hardware utilization rate. Hardware utilization is the percentage of the hardware’s theoretical peak FLOPs per second (FLOP/s) that was achieved on average during training. As such, it is a measure of training efficiency. Higher utilization means less wall-clock time to train, and therefore a lower cost of compute.
Putting it all together we have the following model:
B=KQU−1DCrent-on-demand(1)
How does talent trade for compute Q given a fixed monetary budget C? By talent I basically mean the level of knowledge and experience that the project team has; one proxy for this is the average salary of the team if they were to be employed at an industry AI lab. To answer this, I’ll first rearrange the equation to have Q on the left-hand side:
Q=C−1rent-on-demandBK−1UD−1
Consider the relationship of these variables to the project team’s level of talent. The more experienced and knowledgeable the team is in the given domain of machine learning,
the less compute they will tend to require besides the final training run, i.e., the lower K is, the more final training compute Q they can afford; and
the more hardware utilization U they tend to achieve, which leads to getting more compute Q out of the hardware in the same amount of time.
I think the relationship between talent and the hardware cost discount D is less straightforward. My conceptual model is that a more talented team will tend to be more established in the field and better-resourced in the first place. The most talented machine learning teams tend to be at the largest AI labs, which own (or have more direct access to) assets such as data centers. Therefore, I argue that greater talent correlates with lower hardware costs (i.e., lower D) and in turn more compute Q on a given monetary budget. In summary, I assume that compute Q is proportional to K-1UD-1 which in turn is correlated with talent. Let’s call that product the “talent factor” for compute F, so the model can be conceptually simplified to
Q=C−1rent-on-demandBF
This model has the following implication. Suppose an actor has a budget for compute of B = $1 million. They want to replicate GPT-3 using the latest-generation AI GPU, NVIDIA A100, from Google Cloud. Then we have Q = 3.14E+23 FLOPs (or 3.14E+8 petaflop), and Crent-on-demand ~= $0.0026/petaflop.[22] Accordingly, the required talent factor is
This means that, for example, the project would need to achieve hardware utilization of 0.5, have the final training run make up no less than half the total compute used (K = 2), and use an owned hardware cluster (meaning D = 0.3, based on my assumption). Only top AI labs seem capable of achieving those values. I’m only aware of Google Research achieving a utilization as high as 0.5, with PaLM;[23] I imagine that millions of dollars in capital are required to purchase and maintain the necessary hardware infrastructure; and K = 2 seems to require knowing almost exactly how to succeed at training the model on the first attempt.
On the other hand, if an actor has a budget of B = $10 million, then the required talent factor is 0.082 and the project could get away with a hardware utilization of 0.3, a final training run making up no less than 1/5th the total compute used (K=5), and renting GPUs with a one-year commitment on Google Cloud to get a 37% discount (D=0.63): 0.3 * ⅕ * 1/0.63 = 0.095. This level of achievement seems accessible to four people with two years of collective full-time experience with billion-parameter scale language models (e.g., just a 5 billion parameter model rather than a 100 billion parameter model).[24] The K number would partly take into account them learning a lot in the course of the project, and they would probably also need many more person-hours to succeed than a top-talent team, which is a variable I haven’t factored into the model here. On the other hand, the $10 million budget is out of reach for such a team if they are not in an industry AI lab. In that case, it’s still plausible that the team could be sponsored with enough compute, perhaps by a state agency (I discuss compute sponsorship as an enabling factor of diffusion in a section of a later post).
To compare the “low talent” hypothetical to a real example, the team responsible for GPT-NeoX-20B reported achieving U = 0.38.[25] Most of the work on that project was by two people,[26] though with a compute budget of only ~1E+8 petaflop and full sponsorship of hardware costs by cloud computing company CoreWeave. It’s hard to gauge how much EleutherAI’s previous results and experience over the preceding year contributed to their efficiency in developing GPT-NeoX-20B, but Stella Biderman indicated to me that it contributed a lot.[27]
A median case would be a budget of $3 million, leading to a required talent factor of 0.27. In that case, the utilization could be 0.4, the K could be 4, and either owned hardware or a three-year rental commitment would be required to get D down to at least 0.35 (0.4 * ¼ * 1/0.35 = 0.29). I think this level could be achieved by a machine learning startup with at least $10 million in capital, plus a team that includes four machine learning engineers that have at least one year each of full-time in training billion-parameter scale language models.
My model is flawed due to its simplicity; for instance, the hardware utilization that a team can achieve does not actually seem linearly related to the team’s level of experience, though it certainly seems positively correlated. There are complicated dependencies that aren’t modeled, such as the barriers to entry for setting up different types of organization to work on a project—e.g., an independent collective, academic lab, or startup company. There are also factors entirely missing from the model, such as how long a project takes in real time, and the possibility of having a time budget as well as a monetary budget. However, I am 70% confident that the model is broadly accurate in terms of the implications I laid out above, if you allow a factor of 0.5-2 uncertainty in the compute budget and the talent requirements.
See here for a Guesstimate model of Equation (1) above, where the budget is fixed to $1M.
Appendix: What about barriers to acquiring talent?
There are many ways to acquire money, and many actors in the world have enough money to afford the compute costs I have estimated (I would guess at least thousands of companies, and most states). But what if a given actor has not yet assembled the development team? What barriers to entry are present there? I will mostly leave this as a question for further investigation. The following considerations seem relevant:
The attractiveness of the organization to potential team members
Established top AI labs seem on average more attractive compared to:
Government labs—due to higher prestige, salaries, research freedom, less bureaucracy
Academia—due to higher salaries, higher resources, less bureaucracy
AI startups—due to higher prestige, higher resources
This research is relevant to working for government in particular: Aiken et al. (2020)
Attractiveness of the project to potential team members
Researcher types may not be as interested in the engineering-heavy, intellectually-light work of training large language models.
Cost of the hiring process
Availability of top talent
Cost of employment
Direct labor costs seem smaller than the compute cost.
E.g., 10 ML engineers at $150k/year for six months implies a total labour cost of 10 * 150k * 0.5 = $750k.
But in order for top talent to be hired, they might want a minimum contract length, say one or two years. At that point, the labor cost ($1.5–3M) becomes comparable to the compute cost.
Looking at which actors have made serious attempts at GPT-3-like models provides evidence on who is willing to pay how much.
But we don’t see all the decisions to not pay for these models.
I think the AI21 Labs case indicates a big willingness to pay for some actors. It is a relatively small AI startup, with ~$10 millions raised in funding at the time, training a GPT-3-like model for a few million dollars (Wiggers, 2022).
We even see willingness of MetaAI Research to pay for a GPT-3-like model that they then share for free with academic researchers—seemingly not only for revenue.
It’s important to distinguish how much capital an actor has vs. how much of that they are willing toallocate to the project.
Could a government justify a $10 million investment in a language model project? Maybe. French government agencies gave ~$3 million to the BLOOM project.
What about $100 million?
Willingness to pay depends a lot on the expected return on investment. It would be useful to have an estimate of OpenAI API revenue, for example.
But it’s very likely that OpenAI got—or expects to get—a good return on investment from GPT-3, given that they continue to provide a commercial API for GPT-3.
Key uncertainties to resolve:
What are the caps on investment for different actors?
Is the economic return on the training compute investment going to accelerate or diminish with future capability improvements?
I weakly believe it will diminish for language model scaling, but accelerate for AI overall.
Appendix: Who has explicitly aimed to replicate GPT-3, and who has succeeded?
As at July 1, 2022, the only explicit attempts to replicate GPT-3 that I knew of were
GPT-NeoX-20B from the independent research collective, EleutherAI. The initial goal of EleutherAI itself was to replicate GPT-3.[28] However, GPT-NeoX-20B does not meet my definition of replication because the model is smaller and performs significantly worse than GPT-3.[29]
OPT-175B from Meta AI Research. The primary goal of OPT-175B was as a replication of GPT-3.[30] I judged this to be a successful replication (see this section for reasoning).
I figured that Connor Leahy, a co-founder of EleutherAI who was involved in the project that led to GPT-NeoX-20B, would be one of the most knowledgeable people about other potential replication attempts. When I asked Connor about other replication attempts in conversation, Connor told me about the following two projects that I wasn’t already aware of.[31] I find that neither of them are successful replications of GPT-3.
“mGPT 13B”: This is a 13-billion parameter Russian language model from the Sber (formerly Sberbank), a “Russian majority state-owned banking and financial services company” according to Wikipedia. Details of the model were published in Shliazhko et al. (2022). The paper’s abstract states “We reproduce the GPT-3 architecture using GPT-2 [source code] and the sparse attention mechanism.” This model clearly performs much worse than the 175-billion-parameter GPT-3 model.[32] So even if this model was trained on English rather than Russian, I don’t think it would replicate GPT-3.
“gpt-j-japanese-6.8b”: This is a 6.8-billion-parameter Japanese language model, probably made by a single independent developer, according to Connor. This model is “based on EleutherAI's Mesh Transformer JAX, that has a similar model structure to their GPT-J-6B pre-trained model.” Given the model’s much smaller size compared to GPT-3, it is almost certainly less powerful than GPT-3. So even if this model was trained on English rather than Japanese, I don’t think it would replicate GPT-3.
The user profile that hosts the model has a link to ai-novel.com. That page says “AI Novelist is the largest public Japanese story-writing AI, trained from scratch by 1.5TB corpus total and 7.3B/20B parameters.” I was not able to find information about the 20-billion-parameter model that it mentions—I speculate that it is based on GPT-NeoX-20B. But such a model is still likely to be less powerful than GPT-3 due to its much smaller number of parameters.
Appendix: Survey of the timing, affiliations, and development process of models that replicate or closely emulate GPT-3
Notes:
I am ordering the cases below by my estimate of when each model completed training (stated at the start of each paragraph), rather than when the model was publicized. See the “Date that the model finished training” column in the diffusion database for the reasoning behind those estimates. For reference, GPT-3 was first publicized via Brown et al. (2022).
It’s useful for readers to keep in mind my definition of a GPT-3-like model as “a densely activated neural network model that was trained to autoregressively predict text using at least 1E+23 floating-point operations (FLOPs) of compute, and enough data to approximately follow established scaling laws for autoregressive language modeling.” I have omitted models from this survey that seem unlikely to exceed the training compute threshold of 1E+23 FLOPs, e.g., because they have less than 20 billion parameters.
~October 2020: PanGu-alpha—Chinese industry-academia-government collaboration—worse than GPT-3
By appearances, PanGu-alpha is plausibly a GPT-3-like model (Zeng et al., 2021). I estimate that it was produced at a similar time as Gopher (discussed next). It was developed by a collaboration between Huawei, Recurrent AI, Peking University, and Peng Cheng Laboratory.[33] The PanGu-alpha model has 207 billion parameters, which is larger than GPT-3’s 175 billion. However, I am 90% confident that PanGu-alpha is less capable than GPT-3 by a clear margin, because its estimated training compute is an order of magnitude lower at 5.0E+22 FLOPs. [34]
December 2020: Gopher—DeepMind—better than GPT-3
To the best of my knowledge, DeepMind was first to produce a GPT-3-like model after GPT-3 itself, with Gopher (Rae et al., 2021). The Gopher model completed training in December 2020 based on the date in its model card,[35] seven months after GPT-3’s existence was publicized in May 2020 (Brown et al., 2020). GPT-3 at least seemed to bring forward the timing of Gopher’s development—Geoffrey Irving, last author on the Gopher paper (Rae et al., 2021), told me “We had already started LLM scaleup for the purpose of using them for communication and recursion-based alignment schemes soon after I joined (from OpenAI) [in October 2019], but GPT-3 did add an organizational push.”[36] The paper also says (p.1) that Gopher was "inspired by OpenAI’s pioneering work on GPT-3." I found it difficult to precisely compare the overall performance of Gopher with GPT-3, since the results are presented in different ways between the papers. However, the paper shows strong evidence that Gopher outperforms GPT-3 overall. See Rae et al. (2021, p. 8): "Gopher outperforms the current state-of-the-art for 100 tasks (81% of all tasks). The baseline model includes LLMs such as GPT-3 (175B parameters)..."[37] I think that while the case of Gopher vs. OpenAI is worth noting, the speed at which DeepMind followed OpenAI here is not particularly generalizable—it seems like an unusually fast catch-up of one actor to another, relative to how large of a leap GPT-3 was in terms of compute and engineering requirements.
~May 2021: HyperClova—large Korean tech company—plausibly as powerful as GPT-3
South Korean internet conglomerate Naverannounced[38] a 204-billion-parameter Korean language model called HyperClova in May 2021, one year after GPT-3 was publicized (Naver, 2021). The model could have started training as early as October 2020 given that Naver “[introduced] supercomputers in October last year,” which would be five months after GPT-3 was publicized. Note that Naver’s total assets in 2020 were estimated at ~13.1 billion USD,[39] which makes training such a model a relatively small investment (based on my training compute cost estimates on the order of $1-10 million in a previous section). Using search engines for about 30 minutes, I was unable to find any other significant information about the 204B HyperClova model besides the press release, so I did not include it in my main case study results. Kim et al. (2021) has extensive details about models up to 82 billion parameters, but I have not had time to examine it for this project. The Akronomicon database states the training compute for the 204B model to be 630 Petaflop/s-days, or 5.4E+22 FLOPs, which is an order of magnitude smaller than GPT-3’s estimated training compute of 3.1E+23 FLOPs.[40] However, I am not confident in the Akronomicon estimate, because it does not cite a source and because two different heuristic estimates give a number closer to 5E+23 FLOPs—which is 10x larger than Akronomicon’s estimate and comparable to GPT-3’s 3.1E+23 FLOPs.[41] So overall it is plausible that HyperClova is at least as powerful as GPT-3, but I am only 50% confident that this is the case.
~June 2021: Jurassic-1-Jumbo—~$10 million startup—similar to GPT-3
Jurassic-1-Jumbo is a 178-billion-parameter model developed by AI21 Labs, an Israeli startup. It was announced in August 2021. I estimate that the model was produced in June 2021 (90% CI: April–August 2021), about 12 monthsafter GPT-3 was publicized. AI21 Labs had raised a reported $34.5 million in venture capital before they announced the Jurassic models,[42] which makes training Jurassic-1-Jumbo a huge investment for the company. Access to Jurassic-1-Jumbo has so far only been provided via the AI21 Studio API (i.e., no direct access to model weights).
~July 2021: Megatron-Turing NLG 530B—Microsoft Research and NVIDIA—better than GPT-3
Megatron-Turing NLG 530B is a 530-billion-parameter model developed in a collaboration between Microsoft Research and NVIDIA. It appears to be better than GPT-3. Given that Microsoft held the record for model size prior to GPT-3 with Turing-NLG (Rosset, 2020), and Microsoft collaborated with OpenAI to provide compute resources for GPT-3,[43] I don’t think Megatron-Turing NLG 530B marks a strong shift in priorities for Microsoft Research or NVIDIA. However, this model was produced more than one year after GPT-3 was publicized. It therefore seems likely that the success of GPT-3 still influenced the decision to train this model. If GPT-3 was a disappointment, I doubt that Microsoft and NVIDIA would have scaled their investment this far.
~July 2021: Yuan 1.0 (AKA Source 1.0)—large Chinese tech company—likely as powerful as GPT-3
Yuan 1.0 is a 245-billion-parameter Chinese language model developed by Inspur, a large Chinese tech company (Wu et al., 2021). It was publicized in October 2021. Unlike PanGu-alpha, I did not find evidence of direct collaboration or support from government or academia for this project. I have not assessed Yuan 1.0’s capability compared to GPT-3, but given its similar training compute (4095 petaFLOP/s-days vs. GPT-3’s 3640 petaFLOP/s-days), it seems likely to be similarly powerful in Chinese as GPT-3 is in English, or slightly better.
~September 2021: PCL-BAIDU Wenxin (ERNIE 3.0 Titan)—Baidu (with government support)—likely as powerful as GPT-3
ERNIE 3.0 Titan is a 260-billion-parameter Chinese language model from Baidu. It was publicized in December 2021 (Wang et al., 2021). Notably, the government-sponsored Peng Cheng Lab provided computing support for the training of ERNIE 3.0 Titan.[44]Wang et al. (2021) is not clear about how much compute was required to train the model, but it references training compute requirements similar to GPT-3 (see p.8), so it seems likely to be similarly powerful in Chinese as GPT-3 is in English.
~November 2021: PaLM 540B—Google Research—better than GPT-3
Based on the PCD database, Google’s first publicized GPT-3-like model to exceed GPT-3’s 175 billion parameters was the 540-billion-parameter PaLM model, published April 2022 (Sevilla et al., 2022; Chowdhery et al., 2022). PaLM is clearly much better than GPT-3. Of note is that Google had already produced a 137-billion-parameter pretrained model, LaMDA-PT, some time before the fine-tuned model, FLAN, was published in September 2021.[45] But LaMDA-PT likely performs worse than GPT-3 overall.[46] Given Google’s overall resources, and the scale of the largest experiments published by Google Research, it seems likely that Google Research could have spent more training compute on a language model than GPT-3 used, at the time GPT-3 was publicized. Iulia Turc, a former Software Engineer at Google Research who worked with language models such as BERT and on “a project adjacent to LaMDA”, told me: “Research labs like Google clearly had the resources to [make a GPT-3 equivalent] even before OpenAI, but it's unclear to me whether it would have been a priority.” Given this, I believe that the longer delay from Google Research compared to the actors above was driven more by beliefs about language model scaling being relatively uninteresting, than by their ability to develop better language models than GPT-3.
January 2022: GPT-NeoX-20B—independent research collective—worse than GPT-3
GPT-NeoX-20B is a 20-billion-parameter model developed by the independent research collective, EleutherAI. It was announced in February 2022 after model training completed on January 25, 2022.[47] Although GPT-NeoX-20B performs worse than GPT-3, it is notable for being (to my knowledge) the closest replication attempt by an independent group with no funding. In fact, EleutherAI essentially spent no money out-of-pocket on the project according to Sid Black, the biggest contributor to developing GPT-NeoX-20B. I discuss the sponsorship of their compute resources in a section of a later post.
January 2022: OPT 175B—Meta AI Research—similar to GPT-3
July 2022: BLOOM—industry-academia-government collaboration—similar to GPT-3
BLOOM was discussed in this section. An additional point I want to make here is that the actor behind BLOOM, BigScience, is an unusual type of actor, especially in the Western sphere of AI development. The webpage for BigScience says that it “is not a consortium nor an officially incorporated entity. It's an open collaboration boot-strapped by HuggingFace, GENCI and IDRIS, and organised as a research workshop. This research workshop gathers academic, industrial and independent researchers from many affiliations…” French state research agencies GENCI and CNRS provided a compute grant worth an estimated $3.4M USD to train BLOOM. Note also that HuggingFace is an AI company, which is now hosting access to BLOOM and has capital on the order of at least $10 million.[48] Stas Bekman from HuggingFace seemed to be the lead contributor to BLOOM’s development.[49] So overall, the contribution to BLOOM (accounting for both capital and labor) seems to be mostly from government agencies and HuggingFace.
August 2022: GLM-130B—industry-academia-government collaboration—better than GPT-3
GLM-130B is a 130-billion-parameter bilingual (English & Chinese) language model. It was developed by Tsinghua KEG at Tsinghua University. The model was announced on August 4, 2022 (Tsinghua University, 2022). The announcement says “The model checkpoints of GLM-130B and code for inference are publicly available atour GitHub repo”. However, as at October 13, 2022 the model seems to only be provided by request in this application form, which looks very similar to the application form for access to OPT-175B. The leader of the GLM-130B project is affiliated with Beijing Academy of Artificial Intelligence (BAAI), a government-sponsored lab.[50] The training compute for the model was sponsored by Zhipu.AI, “an AI startup that aims to teach machines to think like humans.”[51] I was not able to find information about Zhipu.AI’s financial capital, but I think it is most likely above $10 million given that they had the capacity to sponsor all of the training compute.[52] GLM-130B is reported to outperform GPT-3’s accuracy on three evaluations: (1) by about one percentage point on the MMLU benchmark in a five-shot setting, (2) by four percentage points on LAMBADA in a zero-shot setting, (3) by about 9 percentage points on the BIG-bench-lite benchmark in a zero-shot setting. See Figure 1(a) on p.2 of Zeng et al. (2021) for these results. Given that the authors have an incentive to highlight where their model outperforms previous models, these results are probably somewhat cherry-picked. However, my best guess is still that GLM-130B’s performance is better overall than GPT-3. Note that I have only spent about two hours investigating GLM-130B.
Acknowledgements
This research is a project ofRethink Priorities. It was written by Ben Cottier. Thanks to Alexis Carlier, Amanda El-Dakhakhni, Ashwin Acharya, Ben Snodin, Bill Anderson-Samways, Erich Grunewald, Jack Clark, Jaime Sevilla, Jenny Xiao, Lennart Heim, Lewis Ho, Lucy Lim, Luke Muehlhauser, Markus Anderljung, Max Räuker, Micah Musser, Michael Aird, Miles Brundage, Oliver Guest, Onni Arne, Patrick Levermore, Peter Wildeford, Remco Zwetsloot, Renan Araújo, Shaun Ee, Tamay Besiroglu, and Toby Shevlane for helpful feedback. If you like our work, please considersubscribing to our newsletter. You can explore our completed public work here.
This is based on both my intuition and one expert’s opinion. I estimated that the total compute budget for a project is 3 times (90% CI: 2–5 times) the final training run cost, to account for trial and error and preliminary experiments.
A researcher at an industry AI lab, who has worked with large language models, told me (paraphrasing): “It wouldn't shock me if an OOM more compute was required for investigating relative to the final training run, if learning how to develop the model from scratch. Maybe less than that…Almost certainly at least a 50-50 split in compute cost between preliminary work and the final training run.” My own read on this is that a 50-50 split seems feasible for a top language model developer, while an order of magnitude difference might correspond to an amateur group attempting replication without prior experience in training language models at the scale of billions of parameters or more.
One piece of potential countering evidence to this is that EleutherAI (who started closer to the latter scenario) only spent ~1/3 of their total compute on preliminary work and 2/3 on training for GPT-NeoX-20B (based on hours of compute expenditure reported in Black et al., 2022, p. 23). However, Stella Biderman (one of the leading contributors to the GPT-NeoX project, as well as BLOOM) indicated that this was an exceptional case, because the GPT-NeoX team already gained a lot of experience training smaller but similar models (e.g., GPT-J), and they “probably got a bit lucky” with successfully training GPT-NeoX-20B with so little testing. (Notes on my correspondence with Stella Biderman are available upon request in this document.)
Ultimately, since I’m estimating costs for major industry developers (OpenAI and Meta AI Research), I leaned toward the 50-50 end of the range, choosing 2x as the lower bound. I intuitively chose the upper bound as 5x, because that is roughly halfway between 2x and a full order of magnitude (i.e. 10x) on a logarithmic scale. I also chose the central estimate of 3x based on a logarithmic scale.
The number of people directly involved in producing the original result. "Producing the original result" includes evaluation of the trained model on main performance benchmarks, but not evaluation of social fairness, bias and toxicity, nor broader impacts, nor pure commentary about the model. The reason is that the latter things are not directly relevant to producing the model or advancing capabilities.
“Core team” size was based on author contributions listed in a paper. I counted people that I judged to be directly involved in producing the result (mainly the trained model). "Producing the original result" includes evaluation of the trained model on standard performance benchmarks, but not evaluation of social fairness, bias, toxicity, or broader impacts, nor pure discussion about the model. The reason is that the latter things are not directly relevant to producing the model or advancing general capabilities.
Where possible, I assess performance difference by comparing common benchmark metrics reported in the research papers for these models. However, not all of the same benchmark results are reported, and the results are not always presented in the same way (e.g., a table in one paper, but only a plot in another paper). Furthermore, models are not perfectly comparable in performance because they differ in their training compute, datasets, and model sizes—the training data in particular could differ drastically in terms of which languages are most represented and therefore which downstream tasks the model performs best at. So I also draw on other evidence to get a broad sense of “capability”, e.g., training compute, dataset size, data diversity, and model size, and how the paper summarizes a model’s performance in comparison to other models.
My 90% CI for training compute generally spans from 0.5 times my central estimate to two times my central estimate. This is because Lennart Heim, Research Fellow and Strategy Specialist at Epoch, told me that the uncertainty in the training compute FLOP estimates in Epoch’s PCD database is generally within a factor of two (paraphrasing from personal correspondence). This seems to be a heuristic partly based on Sevilla et al. (2022) that estimates from two somewhat independent methods differ by no more than a factor of two. My 90% CI for training cost generally spans from 0.4 times my central estimate to 2.7 times my central estimate. My 90% CI for core team size is generally +/- 50% of my central estimate. I’m generally about 80% confident in my claims about whether a given model’s capability level is worse than, similar to, or better than GPT-3’s, if you accept my broad notion of a model’s capabilities (see the cell notes for that column in the database for more information).
I deemed an infrastructure engineering contributor as someone on the project team who was stated in the research publication as contributing to any of the following aspects of the project: training infrastructure, model parallelism, model scaling, training efficiency. There is some flexibility about the exact terms used, but the terms have to be very similar in concept to any of the above.
For the company to “focus” on machine learning R&D, it just has to be one thing they focus on significantly, not the only focus or even the majority of focus. For example, Google has many different products that require software engineering, user experience design, etc. But I would say that Google focuses on machine learning R&D because it has several large machine learning research teams and invests millions of dollars into machine learning R&D. I also regard a small AI startup whose products are based on one narrow machine learning technology, such as AI21 Labs, as “focusing” on machine learning R&D. But if a company does not have a dedicated machine learning research team, I don’t regard it as focusing on machine learning R&D.
It is plausible that researchers at OpenAI and DeepMind were about equally aware of the potential benefit of massively scaling up language models, but OpenAI was more willing to make the bet.
Note that the relationship between loss and performance on downstream tasks is complicated (see Ganguli, 2022). So matching the loss predicted by this scaling law does not necessarily mean the downstream performance will be the same (in fact, it likely won’t be similar on specific tasks, given the randomness of training, and variations in the training data). However, two pieces of evidence make this approach seem reasonable. Firstly, the Chinchilla model was designed to use the same amount of compute as the Gopher model, but it ended up significantly outperforming Gopher (as stated in the abstract of Hoffmann et al. 2022). So to actually match Gopher performance, one ought to choose a model that uses significantly less compute, which in turn would achieve a more similar loss to Gopher (as I found here for GPT-3). Second, the AlexaTM 20B model (Soltan et al., 2022) roughly follows my setting of model size and number of tokens, and it still outperforms GPT-3 on some benchmarks (SuperGLUE and SQuADv2). I have not examined the overall performance of AlexaTM 20B across more benchmarks, but those results suggest that AlexaTM 20B may be better overall than GPT-3 rather than worse.
Using the FP16 PCIe throughput number of 312 teraflop/s here, and the price of renting a single A100 GPU for one hour on Google Cloud of $2.934 here, I get ($2.934 / hour) / (312 teraflop/s * 3600 s/hour * 0.001 teraflop/petaflop) ~= $0.0026/petaflop.
Hardware utilization is reported as 57.8% by an established measure of utilization (which other papers use), and 46.2% by a proposed new measure. See Table 3, p.9 of Chowdhery et al. (2022).
Black et al. (2022) report on p.4 that “we were able to achieve and maintain an efficiency of 117 teraFLOPS per GPU.” With a peak theoretical throughput of 312 teraflop/s for A100 GPUs, that’s a utilization rate of 0.375.
Sid Black indicated to me that he made the majority of contributions to developing GPT-NeoX-20B, followed by Stella Biderman at less than half of his contribution, and so on in decreasing levels of contribution. This information was corroborated by Stella Biderman.
Biderman told me: “When we trained GPT-NeoX-20B we were not ‘figuring out how to do things from scratch.’ By the time we started training that model we had already trained multiple models in the 1B-4B range, as well as a 6B parameter model. We largely knew what we were doing, and the main testing that happened pre-training was to make sure the code was as efficient as possible. We also didn’t do as much testing as we probably should have. We were quite compute-constrained, and didn’t have the option of spending as much compute on testing as on training. We spent a lot of time talking to researchers at DM, OpenAI, Anthropic, etc. to learn as much as possible. We also did a lot of math with scaling laws, looking at the tradeoffs identified by previous researchers. But at the end of the day, we took our best guess and probably got a bit lucky.”
Sid Black, the biggest contributor to developing GPT-NeoX-20B, told me that replicating GPT-3 was EleutherAI’s founding goal. See correspondence (available upon request).
See Shliazhko et al. (2022, p. 8): “Comparing our results with Lin et al. (2021), we conclude that our models achieve lower performance than XGLM (7.5B) almost on all languages, and perform on par with GPT3-Curie (6.7B).” So the model is worse than a worse version of GPT-3.
Credit to Jenny Xiao for obtaining this list of organizations based on the affiliations of authors listed in the paper. According to “Recent Trends in China’s Large-Scale Pre-Trained AI Models Landscape” by Ding & Xiao (forthcoming), Peng Cheng laboratory is a Chinese government-sponsored organization.
I can’t rule out PanGu-alpha being more efficient than GPT-3 with this quantity of compute, or the compute estimate being wrong. But we can also infer PanGu-alpha’s likely inferior performance by comparing training data: ~40 billion tokens for PanGu 200B (see Zeng et al., 2021, Figure 8, p.12) and 300 billion tokens for GPT-3 (see Brown et al., 2020, Table D.1, p.46)—credit to “Recent Trends in China’s Large-Scale Pre-Trained AI Models Landscape” by Ding & Xiao (forthcoming) for pointing out this difference. There is no evaluation of the 200-billion-parameter model in Zeng et al. (2021) besides the validation perplexity and some commentary on the quality of output examples (see Section 5.5, p.16). Note that PanGu-alpha is a Chinese rather than English language model, so I’m comparing performance with GPT-3 in some abstract sense of how capable the model is, rather than on specific benchmarks.
I am inferring information from this source using Google Translate on the webpage text. Quotes from this source are quotes of the automatic translation.
Wikipedia states the total assets as 17 trillion Won. Using the current exchange rate as at 2022-08-14, this is approximately 13.1 billion USD. Point of comparison: Alphabet Inc.—359.3 billion USD in 2021
I do not know the primary source of this number. I know that the number means training compute in Petaflop/s-days based on this archived frontend for the Akronomicon database. As a cross-check, the number for GPT-3 175B there matches the training compute reported elsewhere.
One approximation is compute = #params x #tokens x 6. Based on the numbers in the HyperClova press release (Naver, 2021), the approximation gives 204E+9 x 560E+9 x 6 = 6.85E+23 FLOPs. Second, Kim et al. (2021) explores the scaling of HyperClova models. The paper states the hardware requirements and training time for an 82-billion-parameter variant of HyperClova trained on 150B tokens. Extrapolating the training time based on the change in size and tokens gives a similar estimate of ~6E+23 FLOPs. To be conservative, I rounded these estimates to the nearest half order of magnitude, 5E+23. (Credit to Pablo Villalobos for the original estimates—I have not personally verified the second estimate.)
The original FLAN paper (Wei et al., 2021) was published September 3, 2021. On p.4 the paper says: "In our experiments, we use a dense left-to-right, decoder-only transformer language model of 137B parameters [...] We henceforth refer to this pretrained model as Base LM." The new FLAN paper (Wei et al., 2022) was published February 8, 2022. On p.4 the paper says: "In our experiments, we use LaMDA-PT, a dense left-to-right, decoder-only transformer language model of 137B parameters (Thoppilan et al., 2022)." They also explain the difference between LaMDA-PT and LaMDA (p.4): "Note that LaMDA-PT only has language model pretraining (c.f. LaMDA, which was finetuned for dialog)."
Sid Black, lead contributor to the GPT-NeoX-20B model from EleutherAI, suggested that the person driving the BLOOM project the most was Stas Bekman at HuggingFace. When I asked how many “core” contributors there were for the BLOOM model’s development, Stas told me: “There were probably a few dozen at the modeling [working group], the engineering / production group had just a few people—probably three.”
See “Computation Sponsor” heading under “Acknowledgements” in the announcement post (Tsinghua University, 2022). The post also states “On April 26th, we received a generous computing sponsorship from Zhipu.AI — an AI startup that aims to teach machines to think like humans. After another week of testing, we finally kicked off the training of the GLM-130B model on its 96 A100 (40G * 8) servers on May 6th. Additionally, Zhipu.AI also sent a team to assist in evaluating the pre-trained model and help build a demonstration website.”