All of Buck's Comments + Replies
I would be curious to know what is your median time from weak AGI to artificial superintelligence (ASI) in this question from Metaculus
I don't want to take the time to really understand the operationalizations used in that question, sorry—I'm worried that the answer might depend substantially on finicky details. In general I think that the AI Futures Model is pretty similar to my views on how long it will take to go from "weak AGI" to "ASI", for various definitions of those terms.
I think AI takeover in the next ten years is like 35% (😔), and conditional o...
I agree the survey underestimates the variance in AI timelines and risk.
The AI Futures, which is know for AI 2027, had super broad timelines for artificial superintelligence (ASI) timelines on January 26. The difference between the 90th and 10th percentile was 168 years for Daniel Kokotajlo (2027 to 2195), and 137 years for Eli Lifland (2028 to 2165).
Note that that is a different kind of distribution (one person's beliefs) than the one reported here (many people's medians)
@Ryan Greenblatt and I are going to record another podcast together (see the previous one here). We'd love to hear topics that you'd like us to discuss. (The questions people proposed last time are here, for reference.) We're most likely to discuss issues related to AI, but a broad set of topics other than "preventing AI takeover" are on topic. E.g. last time we talked about the cost to the far future of humans making bad decisions about what to do with AI, and the risk of galactic scale wild animal suffering.
There are so many other risk assessment techniques out there, for reference ISO31010 lists 30 of them (see here) and they're far from exhaustive.
Almost nothing on the list you've linked is an alternative approach to the same problem safety cases try to solve. E.g. "brainstorming" is obviously not a competitor to safety cases. And safety cases are not even an item in that list!
I think EAs are put way too much effort into thinking about safety cases compared to thinking about reducing risks on the margin in cases where risk is much higher (and willingness-to-pay for safety is much lower), because it seems unlikely that willingness-to-pay will be high enough that we'll have low risk at the relevant point. See e.g. here.
There's a social and professional community of Bay Area EAs who work on issues related to transformative AI. People in this cluster tend to have median timelines to transformative AI of 5 to 15 years, tend to think that AI takeover is 5-70% likely, tend to think that we should be fairly cosmopolitan in our altruism.
People in this cluster mostly don't post on the EA Forum for a variety of reasons:
- Many users here don't seem very well-informed.
- Lots of users here disagree with me on some of the opinions about AI that I stated above. Obviously it's totally reas
Anecdotally, the EA forum skews [...] more Bay Area.
For what it's worth, this is not my impression at all. Bay Area EAs (e.g. me) mostly consider the EA Forum to be very unrepresentative of their perspective, to the extent that it's very rarely worthwhile to post here (which is why they often post on LessWrong instead).
This is not an obscure topic. It's been written about endlessly! I do not want to encourage people to make top-level posts asking questions before Googling or talking to AIs, especially on this topic.
I like Claude's response a lot more than you do. I'm not sure why. I agree that it's a lot less informative than your response.
(The post including "This demographic has historically been disconnected from social impact" made me much less inclined to want this person to stick around.)
I'm glad to hear you are inspired by EA's utilitarian approach to maximizing social impact; I too am inspired by it and I have very much appreciated being involved with EA for the last decade.
I think you should probably ask questions as basic as this to AIs before asking people to talk to you about them. Here's what Claude responded with.
...The observation about EA's demographic skew is accurate and widely acknowledged within the community. A few points worth making:
On the historical pattern: The claim that white, male, tech-focused demographics are "historic
An excerpt about the creation of PEPFAR, from "Days of Fire" by Peter Baker. I found this moving.
...Another major initiative was shaping up around the same time. Since taking office, Bush had developed an interest in fighting AIDS in Africa. He had agreed to contribute to an international fund battling the disease and later started a program aimed at providing drugs to HIV-infected pregnant women to reduce the chances of transmitting the virus to their babies. But it had only whetted his appetite to do more. “When we did it, it revealed how unbelievably pathe
The part about "what if money were no object?" reminds me of Justin Sandefur's point in his essay PEPFAR and the Costs of Cost-Benefit Analysis that (emphasis mine)
...Budgets aren’t fixed
Economists’ standard optimization framework is to start with a fixed budget and allocate money across competing alternatives. At a high-level, this is also how the global development community (specifically OECD donors) tends to operate: foreign aid commitments are made as a proportion of national income, entirely divorced from specific policy goals. PEPFAR started with the g
Some not-totally-structured thoughts:
Whenever I said "break laws" I mean "do something that, if a human did it, would be breaking a law". So for example:
- If the model is being used to do AI R&D inside an AI company and exfiltrates its weights (or the weights of another model) without permission, this would be breaking the law if a human did it, so I count it.
- If the model is being used inside an AI company to create training data for
- If a model was open-sourced and then someone launched the AI as an autonomous agent with access to its own resources, and
I agree with you but I think that part of the deal here should be that if you make a strong value judgement in your title, you get more social punishment if you fail to convince readers. E.g. if that post is unpersuasive, I think it's reasonable to strong downvote it, but if it had a gentler title, I'd think you should be more forgiving.
In general, I wish you'd direct your ire here at the proposal that AI interests and rights are totally ignored in the development of AI (which is the overwhelming majority opinion right now), rather than complaining about AI control work: the work itself is not opinionated on the question about whether we should be concerned about the welfare and rights of AIs, and Ryan and I are some of the people who are most sympathetic to your position on the moral questions here! We have consistently discussed these issues (e.g. in our AXRP interview, my 80K interview...
Your first point in your summary of my position is:
The overwhelming majority of potential moral value exists in the distant future. This implies that even immense suffering occurring in the near-term future could be justified if it leads to at least a slight improvement in the expected value of the distant future.
Here's how I'd say it:
...The overwhelming majority of potential moral value exists in the distant future. This means that the risk of wide-scale rights violations or suffering should sometimes not be an overriding consideration when it conflicts with
I would appreciate it if you could clearly define your intended meaning of "disempower humanity".
[...]
Are people referring to benign forms of disempowerment, where humans gradually lose relative influence but gain absolute benefits through peaceful cooperation with AIs? Or do they mean malign forms of disempowerment, where humans lose power through violent overthrow by an aggressive coalition of AIs?
I am mostly talking about what I'd call a malign form of disempowerment. I'm imagining a situation that starts with AIs carefully undermining/sabotaging an AI ...
...My main concern with these proposals is that, unless they explicitly guarantee economic rights for AIs, they seem inadequate for genuinely mitigating the risks of a violent AI takeover.
[...]
For these reasons, although I do not oppose the policy of paying AIs, I think this approach by itself is insufficient. To mitigate the risk of violent AI takeover, this compensation policy must be complemented by precisely the measure I advocated: granting legal rights to AIs. Such legal rights would provide a credible guarantee that the AI's payment will remain valid a
Under the theory that it's better to reply later than never:
I appreciate this post. (I disagree with it for most of the same reasons as Steven Byrnes: you find it much less plausible than I do that AIs will collude to disempower humanity. I think the crux is mostly disagreements about how AI capabilities will develop, where you expect much more gradual and distributed capabilities.) For what it's worth, I am unsure about whether we'd be better off if AIs had property rights, but my guess is that I'd prefer to make it easier for AIs to have property rights....
I think you're maybe overstating how much more promising grad students are than undergrads for short-term technical impact. Historically, people without much experience in AI safety have often produced some of the best work. And it sounds like you're mostly optimizing for people who can be in a position to make big contributions within two years; I think that undergrads will often look more promising than grad students given that time window.
I agree with you that people seem to somewhat overrate getting jobs in AI companies.
However, I do think there's good work to do inside AI companies. Currently, a lot of the quality-adjusted safety research happens inside AI companies. And see here for my rough argument that it's valuable to have safety-minded people inside AI companies at the point where they develop catastrophically dangerous AI.
What you write there makes sense but it's not free to have people in those positions, as I said. I did a lot of thinking about this when I was working on wild animal welfare. It seems superficially like you could get the right kind of WAW-sympathetic person into agencies like FWS and the EPA and they would be there to, say, nudge the agency in a way no one else cared about to help animals when the time came. I did some interviews and looked into some historical cases and I concluded this is not a good idea.
- The risk of being captured by the values and
...Tentative implications:
- People outside of labs are less likely to have access to the very best models and will have less awareness of where the state of the art is.
- Warning shots are somewhat less likely as highly-advanced models may never be deployed externally.
- We should expect to know less about where we’re at in terms of AI progress.
- Working at labs is perhaps more important than ever to improve safety and researchers outside of labs may have little ability to contribute meaningfully.
- Whistleblowing and reporting requirements could become more important as
Well known EA sympathizer Richard Hanania writes about his donation to the Shrimp Welfare Project.
I have some hesitations about supporting Richard Hanania given what I understand of his views and history. But in the same way I would say I support *example economic policy* of *example politician I don't like* if I believed it was genuinely good policy, I think I should also say that I found this article of Richard's quite warming.
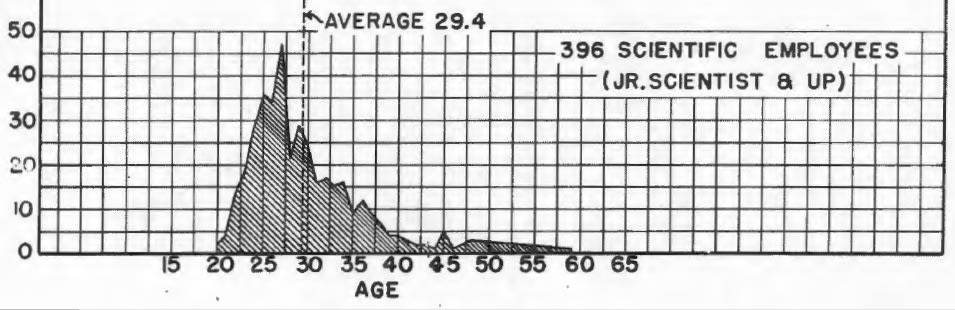
Another aspect here is that scientists in the 1940s are at a different life stage/might just be more generally "mature" than people of a similar age/nationality/social class today. (eg most Americans back then in their late twenties probably were married and had multiple children, life expectancy at birth in the 1910s is about 50 so 30 is middle-aged, society overall was not organized as a gerontocracy, etc).
This is an interesting datapoint, though... just to be clear, I would not consider the Manhattan project a success on the dimension of wisdom or even positive impact.
They did sure build some powerful technology, and they also sure didn't seem to think much about whether it was good to build that powerful technology (with many of them regretting it later).
I feel like the argument of "the only other community that was working on technology of world-ending proportions, which to be clear, did end up mostly just running full steam ahead at building the world-destroyer, was also very young" is not an amazing argument against criticism of EA/AI-Safety.
My super rough impression here is many of the younger people on the project were the grad students of the senior researchers on the project; such an age distribution seems like it would've been really common throughout most academia if so.
In my perception, the criticism levelled against EA is different. The version I've seen people argue revolves around EA lacking the hierarchy of experience required to restrain the worst impulses of having a lot of young people in concentration. The Manhattan Project had an unusual amount of intellectual freedom for a mil...
Note: When an earlier private version of these notes was circulated, a senior figure in technical AI safety strongly contested my description. They believe that the Anthropic SAE work is much more valuable than the independent SAE work, as both were published around the same time, but the Anthropic work provides sufficient evidence to be worth extending by other researchers, whereas the independent research was not dispositive.
For the record, if the researcher here was COI’d, eg working at Anthropic, I think you should say so, and you should also substantially discount what they said.
I think many people are tricking themselves into being more intellectually charitable to Hanania than warranted.
I know relatively little about Hanania other than stuff that has been brought to my attention through EA drama and some basic “know thy enemy” reading I did on my own initiative. I feel pretty comfortable in my current judgment that his statements on race are not entitled charitable readings in cases of ambiguity.
Hanania by his own admission was deeply involved in some of the most vilely racist corners of the internet. He knows what sorts of mess...
I don’t think he says anything in the manifesto about why AI is going to go better if he starts a “hedge fund/think tank”.
I haven’t heard a strong case for him doing this project but it seems plausibly reasonable. My guess is I’d think it was a suboptimal choice if I heard his arguments and thought about it, but idk.
For what it's worth, I'm 75% confident that Hanania didn't mean black people with the "animals" comment.
I think it's generally bad form to not take people at their word about the meaning of their statements, though I'm also very sympathetic to the possibility of provocateurs exploiting charity to get away with dogwhistles (and I think Hanania deserves more suspicion of this than most), so I feel mixed about you using it as an example here.
He lays out the relevant part of his perspective in "The Free World Must Prevail" and "Superalignment" in his recent manifesto.
Most importantly, it seems to me that the people in EA leadership that I felt were often the most thoughtful about these issues took a step back from EA, often because EA didn't live up to their ethical standards, or because they burned out trying to affect change and this recent period has been very stressful
Who on your list matches this description? Maybe Becca if you think she's thoughtful on these issues? But isn't that one at most?
I think that one reason this isn’t done is that the people who have the best access to such metrics might not think it’s actually that important to disseminate them to the broader EA community, rather than just sharing them as necessary with the people for whom these facts are most obviously action-relevant.
Yeah, I think that might be one reason it isn't done. I personally think that it is probably somewhat important for the community to understand itself better (e.g., the relative progress and growth in different interests/programs/geographies). Especially for people in the community who are community builders, recruiters, founders, etc. I also recognise that it might not be seen as priority for various reasons or risky for other reasons and I haven't thought a lot about it.
Regardless, if people who have data about the community that they don't want to...
I think you're right that my original comment was rude; I apologize. I edited my comment a bit.
I didn't mean to say that the global poverty EAs aren't interested in detailed thinking about how to do good; they definitely are, as demonstrated e.g. by GiveWell's meticulous reasoning. I've edited my comment to make it less sound like I'm saying that the global poverty EAs are dumb or uninterested in thinking.
But I do stand by the claim that you'll understand EA better if you think of "promote AMF" and "try to reduce AI x-risk" as results of two fairly differe...
I don't think it makes sense to think of EA as a monolith which both promoted bednets and is enthusiastic about engaging with the kind of reasoning you're advocating here. My oversimplified model of the situation is more like:
- Some EAs don't feel very persuaded by this kind of reasoning, and end up donating to global development stuff like bednets.
- Some EAs are moved by this kind of reasoning, and decide not to engage with global development because this kind of reasoning suggests higher impact alternatives. They don't really spend much time thinking about h
Thanks a lot that makes sense, this comment no longer stands after the edits so have retracted really appreciate the clarification!
(I'm not sure its intentional, but this comes across as patronizing to global health folks. Saying folks "don't want to do this kind of thinking" is both harsh and wrong. It seems like you suggest that "more thinking" automatically leads people down the path of "more important" things than global health, which is absurd.
Plenty of people have done plenty of thinking through an EA lens and decided that bed nets are a great place ...
Note that L was the only example in your list which was specifically related to EA. I believe that that accusation was false. See here for previous discussion.
The situation with person L was deeply tragic. This comment explains some of the actions taken by CEA’s Community Health team as a result of their reports.
Even if most examples are unrelated to EA, if it's true that the Silicon Valley AI community has zero accountability for bad behavior, that seems like it should concern us?
EDIT: I discuss a [high uncertainty] alternative hypothesis in this comment.
I would also be interested in more clarification about how EA relevant the case studies provided might be, to whatever extent this is possible without breaking confidentiality. For example:
We were pressured to sign non-disclosure agreements or “consent statements” in a manipulative “community process”.
this does not sound like the work of CEA Community health team, but it would be an important update if it was, and it would be useful to clarify if it wasn't so people don't jump to the wrong conclusions.
That being said, I think the AI community in the Bay Ar...
There's been some discussion here of the claim that AI capabilities improvements have been a consequence of unsustainable increases in inference compute. Redwood Research Astra fellow Anders Cairns Woodruff has written a great post analyzing the data and disputing this.