
Mo Putera
Bio
Feedback welcome: www.admonymous.co/mo-putera
I work with CE/AIM-incubated charity ARMoR on research distillation, quantitative modelling, consulting, MEL, and general org-boosting to support policies that incentivise innovation and ensure access to antibiotics to help combat AMR. I was previously an AIM Research Program fellow, was supported by a FTX Future Fund regrant and later Open Philanthropy's affected grantees program, and before that I spent 6 years doing data analytics, business intelligence and knowledge + project management in various industries (airlines, e-commerce) and departments (commercial, marketing), after majoring in physics at UCLA and changing my mind about becoming a physicist. I've also initiated some local priorities research efforts, e.g. a charity evaluation initiative with the moonshot aim of reorienting my home country Malaysia's giving landscape towards effectiveness, albeit with mixed results.
I first learned about effective altruism circa 2014 via A Modest Proposal, Scott Alexander's polemic on using dead children as units of currency to force readers to grapple with the opportunity costs of subpar resource allocation under triage. I have never stopped thinking about it since, although my relationship to it has changed quite a bit; I related to Tyler's personal story (which unsurprisingly also references A Modest Proposal as a life-changing polemic):
I thought my own story might be more relatable for friends with a history of devotion – unusual people who’ve found themselves dedicating their lives to a particular moral vision, whether it was (or is) Buddhism, Christianity, social justice, or climate activism. When these visions gobble up all other meaning in the life of their devotees, well, that sucks. I go through my own history of devotion to effective altruism. It’s the story of [wanting to help] turning into [needing to help] turning into [living to help] turning into [wanting to die] turning into [wanting to help again, because helping is part of a rich life].
Posts 5
Comments405
Topic contributions3
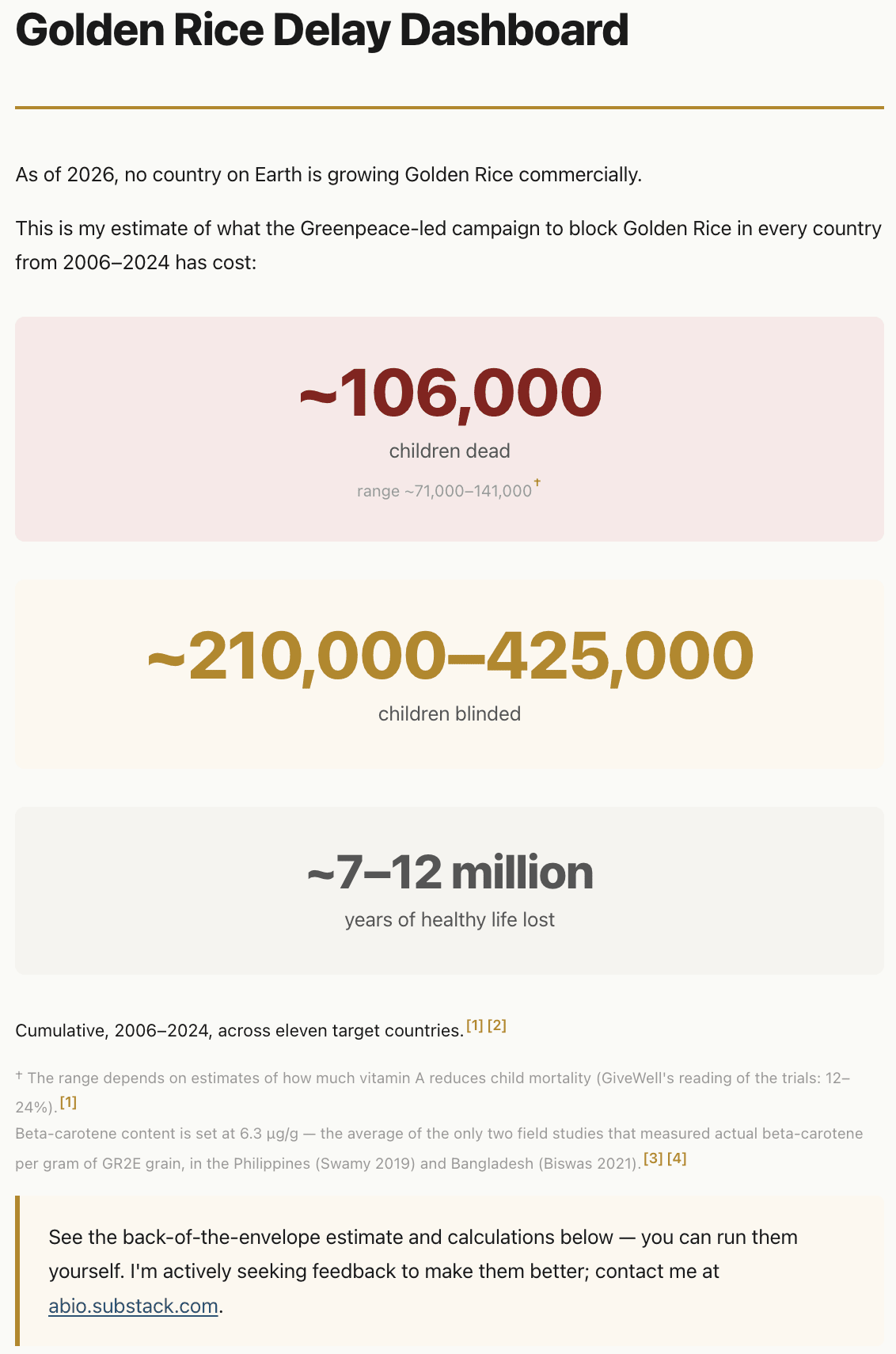
Abi Olvera's Golden rice delay dashboard, includes BOTEC calculations and sources, supplement to her Substack article A blocked GMO rice could have saved 100,000 children. The same tech makes pineapples pink:
Every year, vitamin A deficiency blinds 250,000 to 500,000 children. Half of them die within a year of losing their sight.
One third of children worldwide are deficient, roughly half of children in sub-Saharan Africa and Southeast Asia1. Deficiency weakens the immune system, so children are more likely to die from common infections like diarrhea or measles.
Rich countries solved this kind of problem by adding nutrients to staple foods. The United States adds iodine to most salt, and folic acid to flour to prevent birth defects.
Rice is a critical staple among the world’s poor, so scientists improved rice. They added beta-carotene, the thing that makes carrots orange and that the body turns into vitamin A. The new rice cooks and tastes the same, but it’s yellow. They called it Golden Rice and licensed it for free to any farmer earning under $10,000 a year.
It has been ready since the mid-2000s. Today it grows nowhere.
The reason is that it is a GMO. Environmental groups, led by Greenpeace, fought it in country after country for two decades.
As far as I can tell, no one has calculated the cost of that delay. I’ve spent the last few weeks doing so. My rough estimate is that the delay has killed about 106,000 children and left another 210,000 to 425,000 blind.2 Measured in healthy years of life lost, that is somewhere between 7 and 12 million.3 (My full calculations are here. I will update these figures as I receive feedback.)
That works out to roughly fourteen children dying every single day, for twenty years, from a nutrient we already know how to add to food. ...
Most GMO crops are changed in how they grow, so the part you eat is ordinary. In Golden Rice, the part you eat is the part that changed. That made it feel new.
Greenpeace framed it as dangerous, saying corporations were secretly behind it. They falsely claimed it was unproven and that it was unclear whether children could absorb the vitamin. Activists tore up test fields and filed lawsuits to block approval. Over a hundred Nobel laureates signed a letter asking Greenpeace to stop.
While Golden Rice sat blocked, other new GMO foods reached store shelves. One of them is a pink pineapple. It sells for about $10 in stores and up to $50 online. It uses the same chemistry as Golden Rice, run in the opposite direction. Golden Rice turns on the pathway that makes the vitamin children need. The pineapple turns it off, so the fruit stays a pretty pink.
The lifesaving technology is in the Western world, growing a nicer pineapple for parties.
In 2021 Ajeya described the practical institutional reasoning behind worldview diversification on the 80K podcast like so, in case useful:
Ajeya Cotra: Yeah. I mean, I don’t know that there’s necessarily something to be said for it on a rigorously philosophical point of view, but I think there’s something to be said for not going all in on what you believe a rigorously philosophical accounting would say to value. So, I think one way you could put it is that Open Phil is — as an institution — trying to place a big bet on this idea of doing utilitarian-ish, thoughtful, deep intellectual philanthropy, which has never been done before, and we want to give that bet its best chance. And we don’t necessarily want to tie that bet — like Open Phil’s value as an institution to the world — to a really hyper-specific notion of what that means.
Ajeya Cotra: So, you can think about the longtermist team as trying to be the best utilitarian philosophers they can be, and trying to philosophy their way into the best goals, and win that way. Where at least moderately good execution on these goals that were identified as good (with a lot of philosophical work) is the bet they’re making, the way they’re trying to win and make their mark on the world. And then the near-termist team is trying to be the best utilitarian economists they can be, trying to be rigorous, and empirical, and quantitative, and smart. And trying to moneyball regular philanthropy, sort of. And they see their competitive advantage as being the economist-y thinking as opposed to the philosopher-y thinking.
Ajeya Cotra: And so when the philosopher takes you to a very weird unintuitive place — and, furthermore, wants you to give up all of the other goals that on other ways of thinking about the world that aren’t philosophical seem like they’re worth pursuing — they’re just like, stop… I sometimes think of it as a train going to crazy town, and the near-termist side is like, I’m going to get off the train before we get to the point where all we’re focusing on is existential risk because of the astronomical waste argument. And then the longtermist side stays on the train, and there may be further stops.
Robert Wiblin: Yeah, interesting. I like the idea that rather than thinking about this as exclusively a philosophical disagreement, think about it as a disagreement on the strategy question of, what’s our edge? What’s our edge over everyone else who’s trying to do good? And one of them is, “Well, we’ll be better at philosophy, and we’ll reach more philosophically rigorous conclusions”. And the other people are like, “We’ll be better in some other way. We’ll be more empirical, or be more careful about thinking about…”
Ajeya Cotra: More quantitative, yeah.
Robert Wiblin: More quantitative, exactly.
Ajeya Cotra: I mean, I actually think the near-termist side of the organisation empirically uses quantitative estimates way, way more than the longtermist side of the organisation does. So, on the longtermist side, we’ve talked ourselves into highly prioritising causes where there are only like 10 people working on them. And so most of our effort is trying to convince potential grantees — potential people who could be helpful in this mission — that it’s reasonable to work on at all. And trying to fund people who are trying to do the basic thing that we want to do — for example, reducing global catastrophic biorisks as opposed to focusing on biorisks in general. And that is where almost all of our selection pressure has to go. But on the near-termist side of things, they’re looking at lists of hundreds of things they could focus on, like air pollution in India, or migration from low-income countries to middle-income countries. And they have a huge list of causes and they’re just doing the math on the number of lives that get better per dollar with each of these options.
Ajeya Cotra: So, the feel of doing near-termist work at Open Phil is definitely much more quantitative and rigorous, and in some sense it feels more like what you would have thought a cartoon EA foundation would feel like, because they have more opportunity to map things out.
I'd be interested to know how much this has changed since if at all, especially on the longtermist side.
Very much appreciate the pointers and candour (and sorry for mistakenly calling you a DRI), much for me to chew on. In any case I was hoping you'd answer this on the podcast! But I suppose it just wasn't a good podcast question.
Here's how Holden Karnofsky describes the DRI idea just for your interest, I don't have any other substantive thoughts on it, just "shouldn't there be more DRIs in GHD?" (there's more, I just picked the parts that struck me most):
"DRI" is a Silicon Valley acronym - "directly responsible individual" - referring to the idea that if you want something done well, you should designate a DRI for it. This person isn't necessarily the person who is "in charge of it" from a power perspective (though Daniela and I think it usually should be, and in fact often dislike the term "DRI" in corporate contexts for this reason - we think DRIs should be owners/managers), but it's the person who is "directly responsible" in the sense that the thing going well or poorly is on them. I chose this term even though I often dislike its use, just as an evocative shorthand.
The DRI-centric worldview in a nutshell is:
- Serious impact in domain or task X is nearly always the product of a person who is obsessed with X and has spent a lot of time on X (relative to other people, and ~always over ~1000h even for very green-field X).
- The rough mechanism is that any impact on the world requires understanding and dealing with a large # of little things. You need someone who is sharp and adaptive, but most importantly puts in the time and focus to deal with all of these things.
- So if you are trying to have impact on X, you'd best either become that person or recruit/develop/manage them; other things are unlikely to work. If you're noticing that X isn't going as well as you hoped, your first and possibly last question should be whether the right person (or people) is working on it.
- The game of figuring out who is a fit for what is a contender for "best thing to be good at." This is a great thing to think about and build knowledge of.
...
- The DRI-centric worldview advocates for a bit of an obsessive, often beyond-what-seems-reasonable dedication to the idea that everything that matters should have an unambiguous point person, usually someone who has a heavy concentration of both power and responsibility w/r/t whatever X they are working on. (This person is then held directly accountable for how things go.)
- Interacting with tech founder types, I've often found it almost surreal the way they automatically go "Well X is in charge of Y and I'm not going to second guess them - we are going to do what they want." It's hard to say why it feels so surreal without actual examples, but like ... a lot of times it seems really obvious that the person is crazy and doing a certain kind of thing wrong ... and yet over time I feel like their attitude gets vindicated.
- The DRI-centric worldview is really obsessed with commitment. Anytime someone seems like a sure thing to obsess over X for the next 10y of their life, the DRI-centric worldview is tempted to bet on them to succeed. Anytime someone seems like they've got one foot out, the DRI-centric worldview is like "This is going to suck." (An exception would be when a person is on the way out of something they've already mastered - like a CEO leaving a company - and is helping transition.) I think the DRI-centric worldview is less surprised than other worldviews by how little mark various brilliant, competent, scattered people have made on the world.
- The DRI-centric worldview really doesn't like the idea of trying to "have an idea" that one hands off to another person to execute. It likes the hybrid visionary/executor.
In general, I feel (in a way that I couldn't substantiate well without more work) that I've had a lot of surprises in my life that have updated me toward the above points. There are lots of times when other worldviews, and basic internal logic, is excited about some project because the idea seems so good. But when the key ingredients outlined above are lacking, it generally ends up bad.
Nan Ransohoff's There should be ‘general managers’ for more of the world’s important problems is on my mind too:
There’s a surprisingly big category of problems that are ‘orphaned.’ By ‘orphaned’ I mean: you can’t point to a specific person or organization who thinks it’s their responsibility to deliver the outcome in its entirety. Lots of people talk about the problem, and often many work on slices of it. But if you asked: ‘is there a hyper-competent person waking up every day feeling accountable for making sure this gets solved?’—the answer is very often, ‘no.’
These problems exist across domains and at a variety of ‘altitudes.’ Indeed, some are perhaps better described as ‘things we want to be true’ rather than ‘problems.’ In any event, a few examples that have been on my mind recently:
- Can we prevent infection from all respiratory pathogens (including the common cold)?
- Can we make every new building in SF both serve its function and be beautiful?
- Can we permanently fix the American west’s water problem?
- Can we halve X risk?
- Can we eliminate single-use plastic globally without making convenience trade-offs?
- Can we make childcare costs so low that they’re a non-factor in deciding whether to have kids?
In my opinion, there should be ‘general managers’—GMs—for problems like these. These are founder-types who feel personally responsible for delivering a specific outcome (vs field-building generally); hyper-competent leaders who will pull whatever levers necessary to achieve the defined outcome. Most companies wouldn’t let an important initiative go unmanned or without a ‘directly responsible individual’ — why are we OK not having GMs for even more wide-reaching problems?
Nan gives the historical examples of D.A. Henderson "owning smallpox eradication" and Evan Wolfson "owning marriage equality". I honestly forgot about this article yesterday, but your remark at the end there reminded me of it.
I was hoping you would have good examples for me to learn from! I don't know of any GHD ones.
I think of you as a DRI who "owns the problem of people not having access to high-quality healthcare". You did say you selected ODH's intervention based on your thesis, but actually executing is another matter entirely and you've been hitting it out of the park, and I also get the sense that if the v1 approach didn't work out you would've done the sense-making -> reorienting -> trying differently thing and still ended up "finding product-beneficiary fit" instead of just abandoning ODH (correct me if I'm wrong).
A hypothetical example: suppose you were considering seed-funding a policy advocacy org to encourage governments to institute national action plans that include cost-effective interventions to mitigate violence against women and girls. This is pretty systemic change-y, and I wouldn't be at all certain that the specific intervention idea (advocacy for NAPs) would work out, but there might still be a good case for seed-funding the org if the founder is an obsessively committed DRI-type who "owns VAWG".
I guess I'm generally wondering how to think about doing and supporting systemic change-y GHD interventions, so as to potentially use leverage to help even more people, at the cost of sacrificing confidence grounded in RCT evidence and MEL feedback. "Find and support DRIs, trusting they'll work it out" is the only proxy I can think of.
Not sure how to articulate concisely so here's the braindump-y version. Nick has argued for "funding solutions not projects", e.g. AMF, New Incentives, OneDay Health, etc. I wonder what Nick thinks about funding people instead of specific solutions, in particular directly responsible individuals (DRIs), especially in more "complex systems change-y" GHD contexts like policy, market reform, health systems strengthening, etc where it might be very unclear which specific interventions are most impactful, and figuring this out requires not just "more research" but just trying -> failing -> sense-making -> reorienting -> trying differently etc, so it might make more sense to bet on people with track records of doing that. Concrete GHD-related examples for and against would be much appreciated :) don't think there are simple answers here.
What about systematically fit-testing with cheap tests, per 80K's advice? This is the "be Alice, don't be Bob" approach; the information you learn from acting -> getting feedback -> sense-making -> reorienting -> acting ... is both much richer and more personally decision-relevant. Either way you shouldn't sacrifice WLB ("jog, don't sprint").
matthes' recommendation to "take ownership of the entire evidence pipeline" seems more plausible than ever in this context:
... simply funding the broad field of animal welfare science is likely to create scattered research results that are difficult to translate into action.
We should be involved at every stage of the process. Including
- generating actionable research questions
- designing experimental plans
- conducting the studies
- analysing the raw data
- interpreting the results of the analysis and translating them into actionable recommendations
I think entire organisations could and should be founded for this. Until now, this was simply not possible. Research is expensive and slow, especially at universities. But we're about to have the luxury to aim higher.
(To be clear, I don't claim that this isn't happening at all right now. There are grants being made to advance our understanding of animal suffering. But we haven't been able to be ambitious enough so far.)
Daniel Björkegren points out (h/t Deena Mousa's newsletter) that marginal returns to intelligence from advanced AI will be lower in LMICs due to scarcer AI complements, lower digital legibility, and smaller knowledge sectors, so AI that augments knowledge workers is likely to disproportionately benefit richer countries:
The economic implications of this transformation can be characterized by the marginal returns to intelligence (Amodei 2024): how much can we improve economic outcomes as we better generate ideas, process data, and apply knowledge? Intelligence allows us to solve scientific problems, design better products, better anticipate demand, and ensure the right quantities are stocked in the right places. Low-income countries will benefit from innovations developed in rich ones. But within many LMICs, the complements to advanced AI are scarcer, including data centers, reliable electricity, and digital records, as well as experienced knowledge workers. Data centers can be located in countries that already have good infrastructure (‘the cloud’) and accessed remotely. But LMICs are less digitally legible: AI will be less able to understand and act in markets, firms, homes, clinics, and schools that do not record data in structured forms. Overall, we would expect LMICs to be at a disadvantage in integrating advanced AI (Korinek and Stiglitz 2021).
A crucial distinction is that LMICs have much smaller knowledge sectors. LMICs employ fewer than 10% of workers in skilled knowledge work, like managers, technicians, and professionals, relative to 41% in high income countries (Silva 2026). Current AI tools require substantial human guidance. So, firms in rich economies are pursuing a grafting strategy: existing knowledge workers are being asked to integrate AI into their roles, starting from producing slides and emails, and scaling to more sophisticated tasks. In countries with smaller knowledge sectors, there are fewer workers and processes to graft AI onto. Thus a key question is whether advanced AI will mainly empower existing workers, or automate knowledge work completely. In wealthy countries, advocates concerned about jobs suggest that AI systems be designed to augment rather than automate (Acemoglu, Autor, Johnson 2026). But in low-income countries, the more urgent question may be how to provide knowledge services when few knowledge workers are available. Fully automating knowledge work could in fact augment less educated workers, who could ask AI to complete macro tasks like developing marketing strategies, rather than micro tasks like reformatting spreadsheets. However, even automated systems will likely require oversight from entrepreneurs and scientists with deep expertise, which may be sufficiently available only in wealthier countries like Brazil and India.
If AI allows LMICs to grow automated knowledge sectors, would the returns be high or low? One indicator is in wages paid to human workers. The wage returns to college education are slightly higher in lower income countries (Psacharopoulos and Patrinos 2018 and 2025), but educated people often earn higher wages abroad, and some domestic knowledge workers are working on rich countries’ knowledge problems in call centers and business process outsourcing. Lower income economies may not currently be structured to fully tap the decision making entailed in knowledge work (Engbom et al. 2025). If we tasked millions of data scientists with helping smallholder farms, the returns are unlikely to be large: agriculture is constrained elsewhere.
However, if the price of some forms of intelligence declines by orders of magnitude, it may become worth applying intelligence to problems that were never worth assigning a human to. Small manufacturers might generate nuanced designs that would have required a team of industrial engineers, and implement advertising campaigns that would have required large creative teams. Many regions have struggled to agglomerate sufficient human talent; since automated intelligence can be accessed anywhere, it could make businesses more mobile. These opportunities could more fundamentally change economic structure.
So what can LMICs do? Daniel suggests these:
The most capable AI systems currently require large-scale frontier models and large amounts of compute. Governments, firms, and NGOs will need to work with the frontier labs to ensure that the most advanced models speak local languages and understand local contexts. Ensuring that there are multiple suppliers for both models and data centers can reduce prices and risks of lock-in and geopolitical disruption (Athey and Scott Morton 2025).
Governments will also need to push to make economic activity digitally legible, from markets to clinics to schools.
It is also important to ensure that AI can be productively used. That may require training humans to be more productive users of AI, both in applying the tool and having the deeper world knowledge needed to direct it. Firms can also invest in developing AI tools that are complementary to the industrial structure of LMICs, including tools for small scale entrepreneurs who have less education, and for agriculture, like weather forecasting.
The diversity of institutional conditions in low- and middle-income countries may be a comparative advantage. Wealthy countries have evolved similar institutions around human knowledge work; tweaks may lead to local optima. In contrast, systems in low-income countries can differ greatly. Tailoring to different constraints can generate opportunities: for example, Kenyan entrepreneurs coping with unreliable network connections developed techniques to create on-device AI models that are seeing demand around the world (Fastagger). Or, also in Kenya, 90% of people resolve disputes outside the formal justice system (Kenya 2020), and just two doctors serve every 10,000 people, compared to 37 in the United States (WHO, 2022). Firms and NGOs may find creative new solutions, such as offering more efficient ways to settle disputes outside of court, or dynamic medical advice. Governments can take advantage of opportunities to design new regulation for AI, rather than retrofit regulation designed for humans. A lack of established institutions around human knowledge work could also allow harm: what happens when medical AI makes mistakes and there are limited mechanisms to address malpractice? It will take care to develop appropriate new institutions.
Relatedly, Daniel also has a great post on how the poorest use AI. A quote:
AI usage can provide a new window into the needs of the poor, analogous to Google Trends. This can help AI labs and a variety of organizations better serve these populations. We saw early examples of this among teachers in Sierra Leone, who submitted requests for not only facts and lesson plans, but also on handling reports for insurance claims and navigating interpersonal situations with students and supervisors. Another study found that one of the top uses of ChatGPT among gig workers in India and Brazil was for health queries.
What could be computed: An easy start would be to take the standard categorization of requests already reported by the labs (such as writing, technical help, or mapping to industries) and report them specifically for the subset of users in marginalized groups (defined by having cheaper devices, speaking local languages, or using from remote areas). However, these taxonomies are built around knowledge work, and may systematically undercount the ways poor people find the technology useful. Thus, it would be helpful to develop new taxonomies to understand poverty-specific needs, including particular uses within agriculture, health, navigating government bureaucracy, and business advice.
What we might find: The poor are likely to use AI differently from the wealthy: almost no software development, some use for navigating bureaucracy and social problems, more for help with homework, and less for writing assistance. Anthropic has already reported that Claude users in lower-income countries are more likely to request help with coursework. A further breakdown will help us understand if AI is being used only in the wealthiest schools or broadly, and help school systems ensure it is used in ways that support learning.
This topic became more salient to me after attending Deena's EAG talk on how LMICs should respond to AI, which feels like it should be a much bigger topic than it currently is.
Very much appreciate the spot-check, thanks!