calebp
Posts 33
Comments494
Topic contributions6
@EA Forum Team
I made a small edit and saw that my post was flagged for LM usage. The post (to me) doesn't sound very LM-generated - but I do find it more difficult to assess my own writing than other people's, so I ran it through pangram which seems to think it's 100% human generated.
From quickly skimming your LLM usage policy, it looks like you're also using Pangram, which is a bit confusing. Maybe you have a bug, or are using a different version to me? Or am I using Pangram incorrectly or suboptimally?

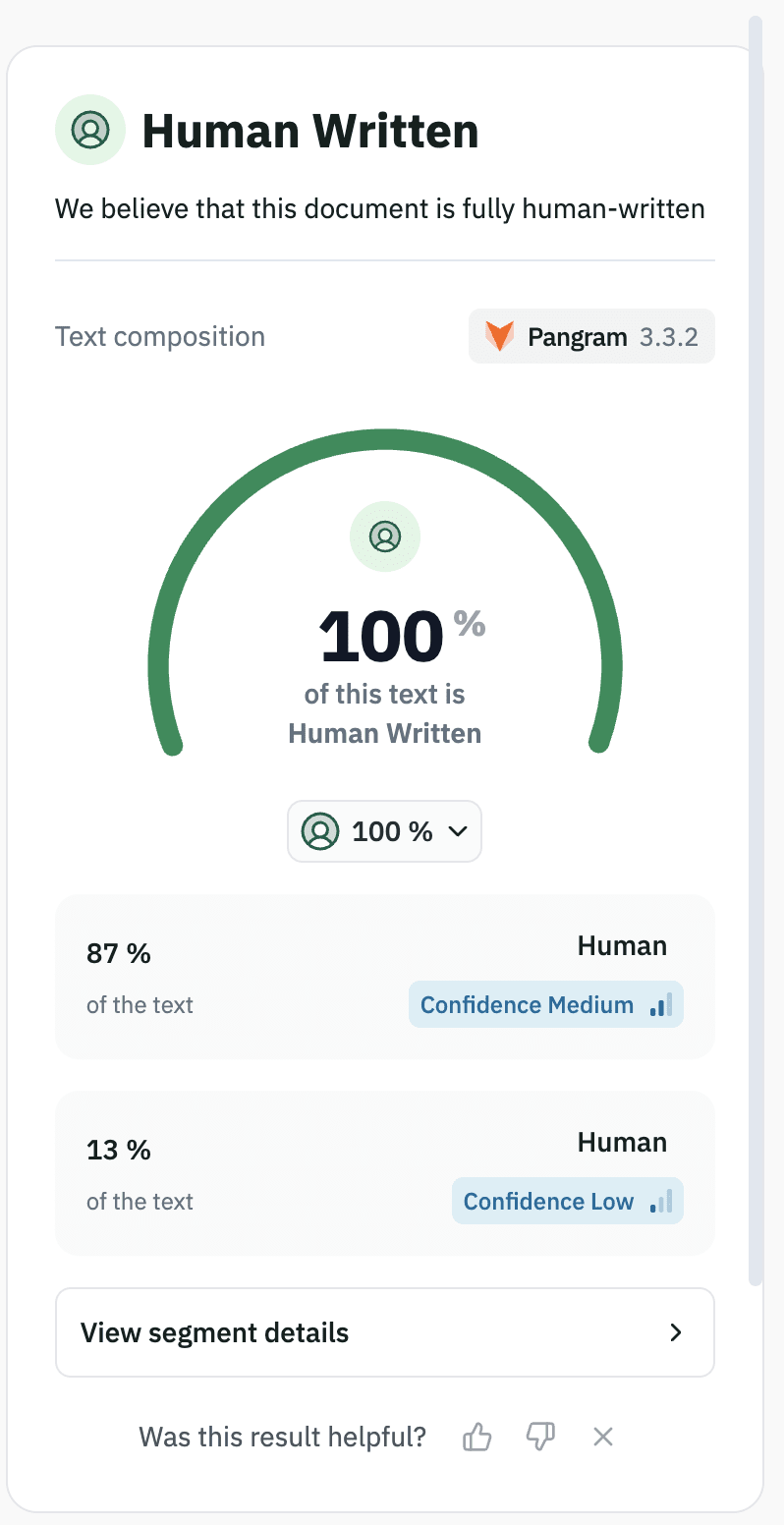
Ah yeah, that all makes sense.
I'm sorry that you're much happier for distancing yourself from EA - but I'm glad that you're much happier now!
> If I didn't have a pretty thorough view formed over years, base rate might also be the first thing I want to understand. I guess I'm just personally well past that
I relate to feeling this way about other topics. Normally, I just roll my eyes and don't really engage with online discussions, but for fwiw I appreciate you giving your thoughts here - it was, at the very least, helpful for me.
I like this comment; the events analogy, in particular, shifted some of my beliefs and gave me a useful frame I had overlooked before. Apologies if you've already covered this in other comments.
My impression is that, if asked, many people would say that EA is significantly worse than other spaces. There's some amount of trying to figure out which other spaces are reasonable to compare to, which allows people to agree with some versions and disagree with others, but on a vibes level, I feel like people think EA is significantly worse. [1] Idk if this is useful, but unlike (most?) other commenters, I do think Nathan is responding to a real sentiment.
Re "why do we even care about a baseline?" Ime, when harassment gets brought up (e.g. on the forum), people say that there were basic/common/cheap/expected mitigations that would have prevented the incident. If it turns out that most other orgs/communities, in fact, don't have these measures in place or are similarly bad at mitigating problems, then imo it's harder for proponents of change to argue that "EA" "should"[2] solve the problem. [3]
I liked the events analogy - one reason why I don't care that much about baselines for events (particiularly ones I have little connection to) is that most events are just ... pretty bad - or at least bad at achieving goals that are analogous to mine, and if I expected a similar level of success to them, I'd spend my time doing other stuff, but I do care a lot about the performance of events that seem particularly great and where my events stack up compared to those (maybe a baseline for "competent according to me" events) - idk if there are transparent groups out there that are doing a really great job in this area and would meet the standards of forum commenters but if there are I would be curious to hear about them.
- ^
As an aside, talking about this topic does seem pretty cursed, and I don't think there's much upside socially to being on the "EA is no worse than others" side or even the "idk man, it's pretty confusing how bad EA is on this dimension" side.
- ^
To be clear, I mean "should" in more of a deontological sense than a consequentialist one. I do care about outcomes in the world, but I just don't think it's possible to have an online discussion about the consequentialist case that couldn't ~only engage with one side.
- ^
It might even point to the problem being unusually difficult to solve (otherwise, why haven't the other well-intentioned communities solved it?).
Hmm, I think if smart EA/Rat types get "corrupted" in general, they'll present as thoughtful people with reasons that are hard to dismiss quickly when questioned by EAs. I get the vague sense that your evidence bar for "corruption" is going to be too high to be useful in most worlds where there's a lot of corruption.
(that's not to say that EAs/Rats/etc. who join labs/start wildly profitable companies speeding up AI progress have been "corrupted" - I just think if they were, it would present pretty similarly to how it has done and it's hard to get lots of easy to share evidence)
Interesting, is sports betting plausibly as bad as tobacco/alcohol in low-income countries?
Like, I think sports betting is plausibly one of the "worst businesses" for the US, comparable to alcohol/tobacco - but my impression is that the EAs that care about tobacco/alcohol don't care very much about interventions in high-income countries relative to low-income countries.
I think this post significantly overstates its conclusion and is plausibly poorly calibrated on the relative value of forecasting.
My main "directional" issues with the post as it's currently written:
- I think it overstates the amount of funding devoted to forecasting on a "worldview" basis.
- Most forecasting funding is (iiuc) not going to neartermist causes or particularly fungible with neartermist causes, so pointing to a bunch of neartermist causes to justify better funding options seems irrelevant.
- From my perspective, it seems like:
- Within Animal welfare fungible money, very little goes into forecasting e.g. less than $2M per year
- Tbh - I would probably prefer that more money went into some kinds of forecasting on the margin. For example, I think that people are generally too bullish on clean meat, and Linch/Open Phil's work investigating the difficulty of clean meat has plausibly resulted in better allocation of millions of dollars because there are, in fact, good alternatives (like cage-free campaigns).
- Within Longtermist/AI fungible money, maybe $10M/year goes into forecasting, which seems pretty reasonable to me but i think to get to 10M you need to be including projects that seems very promising to me for different reasons to mainstream forecasting infrastructure e.g. AI 2027, METR.
- I think the strongest version of the argument would be attacking AI evals but I'm unsure about whether those are in-scope for this post - my impression is that evals are useful for forecasting capabilities are a pretty great bet relative to other funding opportunities within the AI space.
- So the argument actually seems to be "longtermist funding is not as cost-effective as neartermist funding" which is not totally unreasonable, but clearly needs to engage with the long/neartermist worldview (e.g. moral size of the future) as opposed to just engaging with tangible short-term impact indicators.
- Within Animal welfare fungible money, very little goes into forecasting e.g. less than $2M per year
- I'm less convinced than the OP that funders in particular are overrating forecasting - I just don't see much effort going into forecasting grantmaking compared to ~every other grantmaking area.
- My impression is that a lot of forecasting dollars are funded by organisations that are incentivised to use the money well (e.g. AI companies paying FRI to produce forecasts around safety and capability evaluations for safety planning). I see that others have weighed in on this already so not planning to elaborate on this more.
I agree with some of the post's vibes and think it's pointing at real cultural traits of rationalist communities. Though tbh, I think OP is too bearish on the usefulness of betting/making falsifiable predictions for people in EA-spaces. I suspect that OP seen lots of people getting very distracted by futarchy/manifold etc. (and I do think this is a risk), but culturally I think EA should be pretty into "betting/making falsifiable predictions" and that cluster of epistemic traits AND I think forecasting infrastructure has a meaningful effect on this. E.g In two office spaces (out of three that I've spent substantial time in), I think Manifold/prediction markets have very clearly made the communities more forecasting-y, and this has had tangible effects on people's research/choice of projects - this is probably the most explicit example, though most changes are harder to hyperlink.
My impression is that Pangram has very low false positive rates and unclear-to-me false negative rates - so I'd suggest using it to rule things in as AI-generated, but not strongly rule them out.
A little related discussion here https://x.com/caleb_parikh/status/2035434186417262863