Thomas Larsen
Bio
Participation4
Trying to understand AI x-risk.
Posts 6
Comments11
I agree that the lack of feedback loops and complicated nature of all of the things is a core challenge in making this useful.
I think you really can't do better than trying to evaluate people's track records and the quality of their higher level reasoning, which is essentially the meaning of grantmakers' statements like "just trust us".
I do have this sense that we can do better than illegible "just trust us". For example, in the GHD regime, it seems to me like the quality of the reasoning associated with people championing different interventions could be quite decorrelated with the actual amount of impact -- it seems like you need to have numbers on how many people are being impacted by how much.
In my experience even fairly rough BOTECs do shine some light on what we should be doing, and it feels tractable to improve the quality of these.
Whats the version/route to value of this that you are excited about?
The version that I am excited about tries to quantify how impactful longtermists interventions are. I think this could help with both grantmaking, but also people's career choices. Things that would be cool to estimate the value of include:
- A marginal average research hour on each of the alignment agendas.
- A marginal person doing EA or AIS community building
- A person figuring out AI policy details.
- An Op-ed about AI safety in a well respected news site
- An extra safety researcher getting hired at a leading lab
- An extra person estimating AI timelines, or doing epoch-style research.
- ... and a ton more things
How to do this estimation? There's two main ways I feel excited about people trying:
- Building a quantitative model, say, a guesstimate, which quantitatively estimates their worldview.
- Building an "outside view" model aggregating a bunch of people's opinions, perhaps some mix of superforecasters and domain experts. One can make this more efficient by just having a ton of public prediction markets, and then picking a small subset at random to have the experts spend a long time thinking through what they think the result should be.
Here are two silly examples of (1).
Suppose that I'm trying to estimate the impact of a project attempting to pass regulation enacting a frontier AI training run, say, similar to the ideas described here. One can factor this into a) the probability of passing legislation and b) if passed, how good would this legislation be. To estimate (a), I look at the base rate of legislation passing, factors that might make this more or less likely to pass given the current climate, etc. All in all, I estimate something like P(pass) = 4%. To estimate (b), I might crowdsource vibes-based opinions of how much doom might change, or I might list out various worldviews, and estimate how good this might be conditional on each of these worldviews. This one has more uncertainty, but I'm going to put expected reduction in P(AI doom) to be around 1%.[1] This naively puts the impact of this at .01 * .04 = .0004 = 400 microdooms.
Now, suppose that I'm trying to estimate the impact of one year of research produced by the mean SERI MATS scholar. Remember that research impact is heavy tailed, so the mean is probably >> the median. The alignment field is roughly 10 years old, and say it had an average of 100 people working on it, so 1000 person years. This seems low, so I'm going to arbitrarily bump up this number to 3000 person years. Now, suppose the progress so far has been 1% of the alignment problem[2] being solved, and suppose that alignment being solved is 50% of what is necessary for an existential win. Let's say the average MATS scholar is equal to the average person in the alignment field so far. This means that the value of a year of research produced by the average MATS scholar is .5*.01* (1/3000) = 1.6 microdooms.
These are both terrible estimates that get so many things wrong! Probably most of the value of the MATS person's research now is upskilling to make future research better, or perhaps its in fieldbuilding to excite more people to start working on alignment later, or perhaps something else. Maybe the project doing legislation makes it way more difficult for other efforts to do something in this space later, or maybe it makes a mistake in the regulation and creates a licensing body that immediately gets regulatory captured, so the value isn't 1% of an existential win, it could be -5%. My claims are:
a)These estimates are better than nothing, and that they at least inform one's intuition of what is going on.
b) These estimates can be improved radically by working on them. I had a lot of this cached (having thought about stuff like this a fair bit), but this was a very quick comment, and with some dedicated effort, a bunch of cruxes could be uncovered. I feel like one could spend 10 hours on each of these and really narrow down the uncertainty quite a bit.
- ^
This is a wild estimate! I'm typing this on the fly but in reality I'd make a guesstimate with a distribution over these parameters because multiplying point estimates instead of distributions induces error.
- ^
I'm being horrendously glossy, but by "the alignment problem" I mean something like "the technical solution that tells us how to build a superintelligent AI pointed at humanities reflectively endorsed values".
(rushed comment, but still thought it was worth posting. )
I'm not sure what the "quality adjusted" dollars means, but in terms of dollars, I think net spend on AI safety is more like 200M / year instead of 10s of millions.
Very rough estimates for 2022:
From OP's website, it looks looks like:
- 15M to a bunch of academics
- 13M to something at MIT
- 10M to Redwood
- 10M to Constellation
- 5M to CAIS
- ~25M of other grants (e.g. CNAS, SERI MATS)
Adds up to like 65M
EA Funds spends maybe 5M / year on AI Safety? I'd be very surprised if it was <1M / year.
FTX gave maybe another 100M of AI Safety related grants, not including Anthropic ( I estimate)
That gives 150M.
I also think lab spending such as Anthropic, OpenAI, and DeepMind's safety team should be counted here. I'd put this at like 50M / year, which gives a lower bound total of 200M in 2022, because other people might be spending money.
I imagine that net spend in 2023 will be significantly lower than this though, 2022 was unusually high, likely due to FTX things.
Of course, spending money does not equate with impact, it's pretty plausible that much of this money was spent very ineffectively.
Either way, both compute and algorithms, even if we make a magical breakthrough in quantum computing tomorrow, are in the end limited by data. DeepMind showed in 2022 (see also here) that more compute only makes sense if you have more data to feed it. So even if we get exponentially scaling compute and algorithms, that would only give us the current models faster, not better. So what are the limits of data?
AI scaling laws refer to a specific algorithm and so are not relevant for arguing against algorithmic progress. For example, humans are much more sample efficient than LLMs right now, and so are an existence proof for more sample efficient algorithms. I also am pretty sure that humans are far from the limits of intelligence -- neuron firing speeds are on the order of 1-100 Hz, while computers can run much faster than this. Moreover, the human brain has all sorts of bottlenecks like needing to fit through a mother's birth canal that an AI need not have, as well as all the biases that plague our reasoning.
Epoch estimates algorithmic improvements at .4 OOM / year currently, and I feel that it's hard to be confident either way about which direction this will go in the future. AI assisted AI research could dramatically increase this, but on the other hand, as you say, scaling could hit a wall.
I agree that I don't expect the exponential to hold forever, I expect the overall growth to look more like a sigmoid, as described here (though my best guess parameters to this model are different than the default ones). Where I disagree is that I expect the sigmoid to top out at far stronger than human level.
I haven't read all of your posts that carefully yet, so I might be misunderstanding something, but generally, it seems to me like this approach has a some "upper bound" modeling assumptions that are then used as an all things considered distribution.
My biggest disagreement is that I think that your distribution over FLOPs [1] required for TAI (pulled from here), is too large.
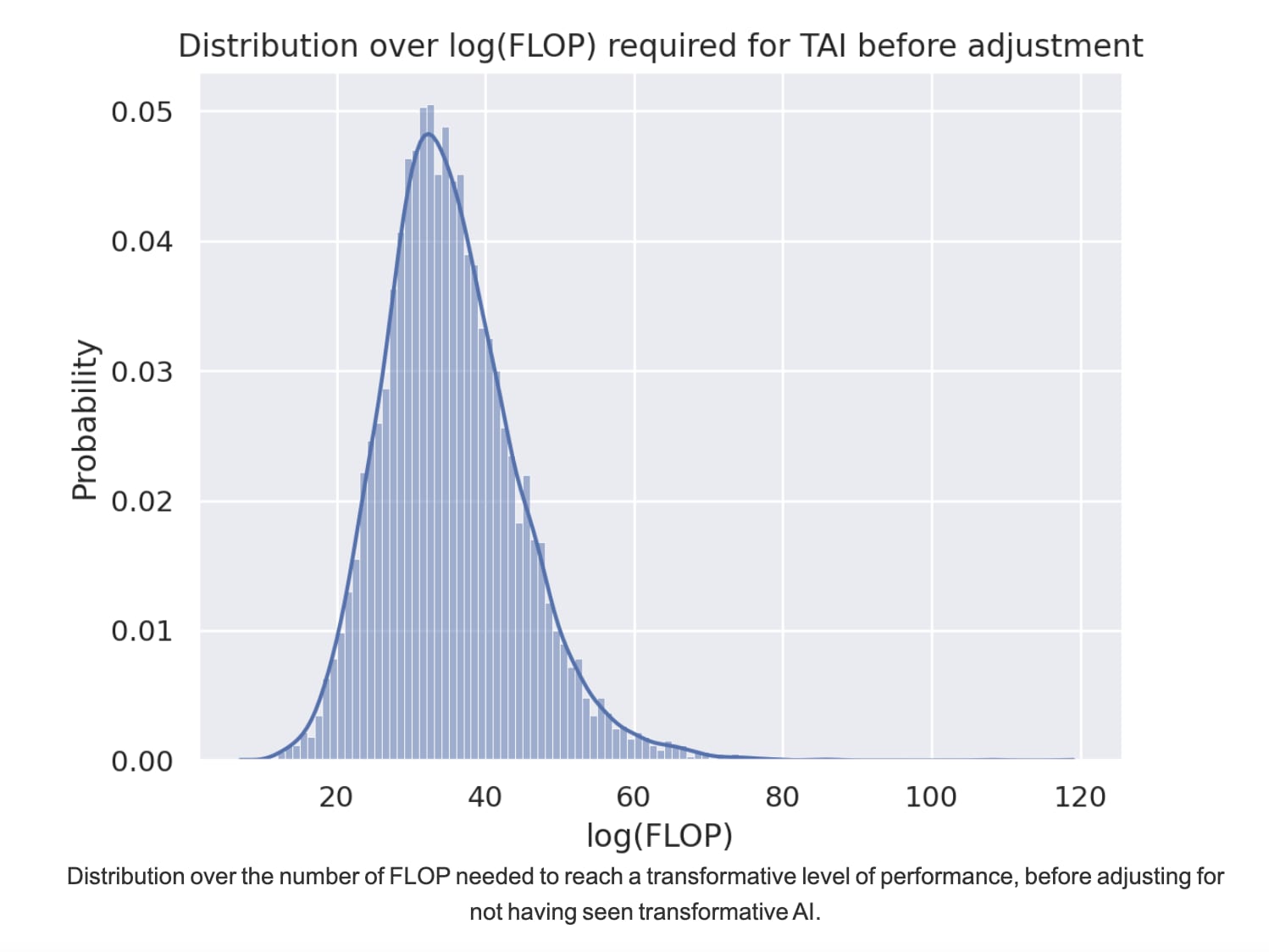
My reading is that this was generated assuming that we would train TAI primarily via human imitation, which seems really inefficient. There are so many other strategies for training powerful AI systems, and I expect people to transition to using something better than imitation. For example, see the fairly obvious techniques discussed here.
GPT-4 required ~25 log(FLOP)s, and eyeballing it, the mode of this distribution seems to be about ~35 log(FLOP)s, so that is +10 OOMs as the median over GPT-4. The gap between GPT-3 and GPT-4 is ~2 OOMs, so this would imply a median of 5 GPT-sized jumps until TAI. Personally, I think that 2 GPT jumps / +4 OOMs is a pretty reasonable mode for TAI (e.g. the difference between GPT-2 and GPT-4).
In the 'against very short timelines' section, it seems like your argument mostly routes through it being computationally difficult to simulate the entire economy with human level AIs, because of inference costs. I agree with this, but think that AIs won't stay human level for very long, because of AI-driven algorithmic improvements. In 4 year timelines worlds, I don't expect the economy to be very significantly automated before the point of no return, I instead expect it to look more like faster and faster algorithmic advances. Instead of deploying 10 million human workers dispersed over the entire economy, I think this would look more like deploying 10 million more AGI researchers, and then getting compounding returns on algorithmic progress from there.
But, as I have just argued above, a rapid general acceleration of technological progress from pre-superintelligent AI seems very unlikely in the next few years.
I generally don't see this argument. Automating the entire economy != automating ML research. It remains quite plausible to me that we reach superintelligence before the economy is 100% automated.
- ^
I'm assuming that this is something like 2023-effective flops (i.e. baking in algorithmic progress, let me know if I'm wrong about this).
(quick thoughts, may be missing something obvious)
Relative the scale of the long term future, the number of AIs deployed in the near term is very small, so to me it seems like there's pretty limited upside to improving that. In the long term, it seems like we have AIs to figure out the nature of consciousness for us.
Maybe I'm missing the case that lock-in is plausible, it currently seems pretty unlikely to me because the singularity seems like it will transform the ways the AIs are running. So in my mind it mostly matters what happens after the singularity.
I'm also not sure about the tractability, but the scale is my major crux.
I do think understanding AI consciousness might be valuable for alignment, I'm just arguing against work on nearterm AI suffering.
I appreciate Josh Clymer for living up to his reflectively endorsed values so strongly. Josh is extremely willing to do the thing that he thinks is most impactful, even when such a thing looks like going to school wearing a clown suit.
Are there any alignment research community/group/event nearby?
HAIST is probably the best AI safety group in the country, they have office space quite near campus and several full time organizers.
I'm confused why almost all of the comments seem to be from people donating to many charities. For small amounts that an individual would donate, I don't imagine that diminishing marginal returns would kick in, so shouldn't one donate entirely to the charity that has the highest EV on the current margin?
IMO there's a difference between evaluating arguments to the best of your ability and just deferring to the consensus around you. I think most people probably shouldn't spend lots of time doing cause prio from scratch, but I do think most people should judge the existing cause prio literature on object level and judge them from the best of the ability.
My read of the sentence indicated that there was too much deferring and not enough thinking through the arguments oneself.