All of Will Aldred's Comments + Replies
Good post, and I strongly agree. My preferred handle for what you’re pointing at is ‘integrity’. Quoting @Habryka (2019):
I think of integrity as a more advanced form of honesty […] Where honesty is the commitment to not speak direct falsehoods, integrity is the commitment to speak truths that actually ring true to yourself, not ones that are just abstractly defensible to other people. It is also a commitment to act on the truths that you do believe, and to communicate to others what your true beliefs are.
(In this frame, What We Owe the Future, for exa...
There was some discussion of this a few months ago: see here.
Although, maybe your main point—which I agree the existing discussion doesn’t really have answers to—is, “How, if at all, should we be getting ahead of things and proactively setting a framing for the social media conversation that will surely follow (as opposed to just forming some hypotheses over what that conversation will be like, but not particularly doing anything yet)? Who within our community should lead these efforts? How high priority is this compared to other forms of improvi...
[sorry I’m late to this thread]
@William_MacAskill, I’m curious which (if any) of the following is your position?
1.
“I agree with Wei that an approach of ‘point AI towards these problems’ and ‘listen to the AI-results that are being produced’ has a real (>10%? >50%?) chance of ending in moral catastrophe (because ‘aligned’ AIs will end up (unintentionally) corrupting human values or otherwise leading us into incorrect conclusions).
And if we were living in a sane world, then we’d pause AI development for decades, alongside probably engagi...
Nice!
One quibble: IMO, the most important argument within ‘economic dominance,’ which doesn’t appear in your list (nor really in the body of your text), is Wei Dai’s ‘AGI will drastically increase economies of scale’.
Mod here. It looks like this thread has devolved into a personal dispute with only tangential relevance to EA. I’m therefore locking the thread.
Those involved, please don’t try to resurrect the dispute elsewhere on this forum; we may issue bans if we see that happening.
Richard’s ‘Coercion is an adaptation to scarcity’ post and follow-up comment talk about this (though ofc maybe there’s more to Richard’s view than what’s discussed there). Select quotes:
...What if you think, like I do, that we live at the hinge of history, and our actions could have major effects on the far future—and in particular that there’s a significant possibility of existential risk from AGI? I agree that this puts us in more of a position of scarcity and danger than we otherwise would be (although I disagree with those who have very high cre
"I don't want to encourage people to donate (even to the same places as I did) unless you already have a few million dollars in assets"
I do see advantages of the abundance mindset, but your threshold is extremely high-it excludes nearly everyone in developed countries, let alone the world. Plenty of people without millions of dollars of assets have an abundance mindset (including myself).
Relatedly, @MichaelDickens shallow-reviewed Horizon just under a year ago—see here.[1] Tl;dr: Michael finds that Horizon’s work isn’t very relevant to x-risk reduction; Michael believes Horizon is net-negative for the world (credence: 55%).
(On the other hand, it was Eth, Perez and Greenblatt—i.e., people whose judgement I respect—who recommended donating to Horizon in that post Mikhail originally commented on. So, I overall feel unsure about what to think.)
Fyi, the Forum team has experimented with LLMs for tagging posts (and for automating some other tasks, like reviewing new users), but so far none have been accurate enough to rely on. Nonetheless, I appreciate your comment, since we weren’t really tracking the transparency/auditing upside of using LLMs.
Beyond the specifics (which Vasco goes into in his reply): These tweets are clearly not serious/principled/good-faith criticisms. If we are constantly moderating what we say to try to make sure that we don’t possibly give trolls any ammunition, then our discourse is forever at the mercy of those most hostile to the idea of doing good better. That’s not a good situation to be in. Far better, I say, to ignore the trolling.
I agree with ‘within dedicated discussions and not on every single animal welfare post,’ and I think Vasco should probably take note, here.
However, I’m not really sure what you mean by reputational risk—whose reputation is at risk?
Generally speaking, I very much want people to be saying what they honestly believe, both on this forum and elsewhere. Vasco honestly believes that soil animal welfare outweighs farmed animal welfare, and he has considered arguments for why he believes this, and so I think it’s valuable for him to say the things he says (so long ...
I By reputational risk I mean that an organization like Hive who's stated purpose is to be "Your global online hub for farmed animal advocates." could be undermined by their platform being spammed with arguments suggesting helping farmed animals is a bad idea.
I don't think discussions about whether what your entire platfor is doing is even net positive, are best had on an organizational slack forum. It's could demotivate people who are passionate about helping farmed animals.
Perhaps very uncertain philosophical questions can be discussed on other forums, t...
Just want to quickly flag that you seem to have far more faith in superforecasters’ long-range predictions than do most people who have worked full-time in forecasting, such as myself.
@MichaelDickens’ ‘Is It So Much to Ask?’ is the best public writeup I’ve seen on this (specifically, on the problems with Metaculus’ and FRI XPT’s x-risk/extinction forecasts, which are cited in the main post above). I also very much agree with:
...Excellent forecasters and Superforecasters™ have an imperfect fit for long-term questions
Here are some reasons why we might expect lo
There’s an old (2006) Bostrom paper on ~this topic, as well as Yudkowsky’s ‘Anthropic Trilemma’ (2009) and Wei Dai’s ‘Moral Status of Independent Identical Copies’ (2009). Perhaps you’re remembering one of them?
(Bostrom disagrees with the second paragraph you cite, as far as I can tell. He writes: ‘If a brain is duplicated so that there are two brains in identical states, are there then two numerically distinct phenomenal experiences or only one? There are two, I argue.’)
I don’t know much about nematodes, mites or springtails in particular, but I agree that, when thinking about animal welfare interventions, one should be accounting for effects on wild animals.
(As Vasco says, these effects plausibly reverse the sign of factory farming—especially cattle farming—from negative to positive. I’m personally quite puzzled as to why this isn’t a more prominent conversation/consideration amongst the animal welfare community. (Aside from Vasco’s recent work, has ~any progress been made in the decade since Shulman and Tomasi...
This post did generate a lot of pushback. It has more disagree votes than agree votes, the top comment by karma argues against some of its claims and is heavily upvoted and agree-voted, and it led to multiple response posts including one that reaches the opposite conclusion and got more karma & agree votes than this one.
I agree that this somewhat rebuts what Raemon says. However, I think a large part of Raemon’s point—which your pushback doesn’t address—is that Bentham’s post still received a highly positive karma score (85 when Raemon came u...
[resolved]
Meta: I see that this poll has closed after one day. I think it would make sense for polls like this to stay open for seven days, by default, rather than just one?[1] I imagine this poll would have received another ~hundred votes, and generated further good discussion, had it stayed open for longer (especially since it was highlighted in the Forum Digest just two hours prior).
- ^
I’m unsure if OP meant for this poll to close so soon. Last month, when I ran some polls, I found that a bunch of them ended up closing after the
Yeah, thanks for pointing this out. With the benefit of hindsight, I’m seeing that there are really three questions I want answers to:
...1. Have you been voting in line with the guidelines (whether or not you’ve literally read them)?
2a. Have you literally read the guidelines? (In other words, have we succeeded in making you aware of the guidelines’ existence?)
2b. If you have read the guidelines, to what extent can you accurately recall them? (In other words, conditional on you knowing the guidelines exist, to what extent have we succeeded at drilling th
Thanks, yeah, I like the idea of guidelines popping up while hovering. (Although, I’m unsure if the rest of the team like it, and I’m ultimately not the decision maker.) If going this route, my favoured implementation, which I think is pretty aligned with what you’re saying, is for the popping up to happen in line with a spaced repetition algorithm. That is, often enough—especially at the beginning—that users remember the guidelines, but hopefully not so often that the pop ups become redundant and annoying.
The Forum moderation team (which includes myself) is revisiting thinking about this forum’s norms. One thing we’ve noticed is that we’re unsure to what extent users are actually aware of the norms. (It’s all well and good writing up some great norms, but if users don’t follow them, then we have failed at our job.)
Our voting guidelines are of particular concern,[1] hence this poll. We’d really appreciate you all taking part, especially if you don’t usually take part in polls but do take part in voting. (We worry that the ‘silent majority’ of...
Nice post (and I only saw it because of @sawyer’s recent comment—underrated indeed!). A separate, complementary critique of the ‘warning shot’ idea, made by Gwern (in reaction to 2023’s BingChat/Sydney debacle, specifically), comes to mind (link):
...One thing that the response to Sydney reminds me of is that it demonstrates why there will be no 'warning shots' (or as Eliezer put it, 'fire alarm'): because a 'warning shot' is a conclusion, not a fact or observation.
One man's 'warning shot' is just another man's "easily patched minor bug of no im
Hmm, I think there’s some sense to your calculation (and thus I appreciate you doing+showing this calculation), but the $6.17 conclusion—specifically, “engagement time would drop significantly if users had to pay 6.17 $ per hour they spend on the EA Forum, which suggests the marginal cost-effectiveness of running the EA Forum is negative”—strikes me as incorrect.
What matters is by how much engaging with the Forum raises altruistic impact, which, insofar as this impact can be quantified in dollars, is far, far higher than what one would be willing and ...
Note: Long-time power user of this forum, @NunoSempere, has just rebooted the r/forecasting subreddit. How that goes could give some info re. the question of “to what extent can a subreddit host the kind of intellectual discussion we aim for?”
(I’m not aware of any subreddits that meet our bar for discussion, right now—and I’m therefore skeptical that this forum should move to Reddit—but that might just be because most subreddit moderators aren’t aiming for the same things as this forum’s moderators. r/forecasting is an interesting experiment beca...
Relevant reporting from Sentinel earlier today (May 19):
Forecasters estimated a 28% chance (range, 25-30%) that the US will pass a 10-year ban on states regulating AI by the end of 2025.
28% is concerningly high—all the more reason for US citizens to heed this post’s call to action and get in touch with your Senators. (Thank you to those who already have!)
(Current status is: “The bill cleared a key hurdle when the House Budget Committee voted to advance it on Sunday [May 18] night, but it still must undergo a series of votes in the House befo...
Inspired by the last section of this post (and by a later comment from Mjreard), I thought it’d be fun—and maybe helpful—to taxonomize the ways in which mission or value drift can arise out of the instrumental goal of pursuing influence/reach/status/allies:
Epistemic status: caricaturing things somewhat
Never turning back the wheel
In this failure mode, you never lose sight of how x-risk reduction is your terminal goal. However, in your two-step plan of ‘gain influence, then deploy that influence to reduce x-risk,’ you wait too long to move onto ste...
For what it’s worth, I find some of what’s said in this thread quite surprising.
Reading your post, I saw you describing two dynamics:
- Principles-first EA initiatives are being replaced by AI safety initiatives
- AI safety initiatives founded by EAs, which one would naively expect to remain x-risk focused, are becoming safety-washed (e.g., your BlueDot example)
I understood @Ozzie’s first comment on funding to be about 1. But then your subsequent discussion with Ozzie seems to also point to funding as explaining 2.[1]
While Open Phil has opinions within AI s...
Do those other meditation centres make similarly extreme claims about the benefits of their programs? If so, I would be skeptical of them for the same reasons. If not, then the comparison is inapt.
Why would the comparison be inapt?
A load-bearing piece of your argument (insofar as I’ve understood it) is that most of the benefit of Jhourney’s teachings—if Jhourney is legit—can be conferred through non-interactive means (e.g., YouTube uploads). I am pointing out that your claim goes against conventional wisdom in this space: these other meditation centres bel...
What is the interactive or personalized aspect of the online “retreats”? Why couldn’t they be delivered as video on-demand (like a YouTube playlist), audio on-demand (like a podcast), or an app like Headspace or 10% Happier?
I mean, Jhourney is far from the only organisation that offers online retreats. Established meditation centres like Gaia House, Plum Village and DeconstructingYourself—to name but a few—all offer retreats online (as well as in person).
...If Jhourney’s house blend of jhana meditation makes you more altruistic, why wouldn’t th
I’m not Holly, but my response is that getting a pause now is likely to increase, rather than decrease, the chance of getting future pauses. Quoting Evan Hubinger (2022):
...In the theory of political capital, it is a fairly well-established fact that ‘Everybody Loves a Winner.’ That is: the more you succeed at leveraging your influence to get things done, the more influence you get in return. This phenomenon is most thoroughly studied in the context of the ability of U.S. presidents to get their agendas through Congress—contrary to a naive mode
It seems like I interpreted this question pretty differently to Michael (and, judging by the votes, to most other people). With the benefit of hindsight, it probably would have been helpful to define what percentage risk the midpoint (between agree and disagree) corresponds to?[1] Sounds like Michael was taking it to mean ‘literally zero risk’ or ‘1 in 1 million,’ whereas I was taking it to mean 1 in 30 (to correspond to Ord’s Precipice estimate for pandemic x-risk).
(Also, for what it’s worth, for my vote I’m excluding scenarios where a misaligne...
Meta: I’m seeing lots of blank comments in response to the DIY polls. Perhaps people are thinking that they need to click ‘Comment’ in order for their vote to count? If so, PSA: your vote counted as soon as you dropped your slider. You can simply close the pop-up box that follows if you don’t also mean to leave a comment.
Happy voting!
Consequentialists should be strong longtermists
For me, the strongest arguments against strong longtermism are simulation theory and the youngness paradox (as well as yet-to-be-discovered crucial considerations).[1]
(Also, nitpickily, I’d personally reword this poll from ‘Consequentialists should be strong longtermists’ to ‘I am a strong longtermist,’ because I’m not convinced that anyone ‘should’ be anything, normatively speaking.)
- ^
I also worry about cluelessness, though cluelessness seems just as threatening to neartermist interventions
[Good chance you considered my idea already and rejected it (for good reason), but stating it in case not:]
For these debate week polls, consider dividing each side up into 10 segments, rather than 9? That way, when someone votes, they’re agreeing/disagreeing by a nice, round 10 or 20 or 30%, etc., rather than by the kinda random amounts (at present) of 11, 22, 33%?
I think Holly’s claim is that these people aren’t really helping from an ‘influencing the company to be more safety conscious’ perspective, or a ‘solving the hard parts of the alignment problem’ perspective. They could still be helping the company build commercially lucrative AI.
I’m not sure if this hits what you mean by ‘being ineffective to be effective’, but you may be interested in Paul Graham’s ‘Bus ticket theory of genius’.
The moderation team is issuing @Eugenics-Adjacent a 6-month ban for flamebait and trolling.
I’ll note that Eugenics-Adjacent’s posts and comments have been mostly about pushing against what they see as EA groupthink. In banning them, I do feel a twinge of “huh, I hope I’m not making the Forum more like an echo chamber.” However, there are tradeoffs at play. “Overrun by flamebait and trolling” seems to be the default end state for most internet spaces: the Forum moderation team is committed to fighting against this default.
All in all, we think the ...
I’m also announcing this year’s first debate week! We'll be discussing whether, on the margin, we should put more effort into reducing the chances of avoiding human extinction or increasing the value of futures where we survive.
Nice! A couple of thoughts:
1.
In addition to soliciting new posts for the debate week, consider ‘classic repost’-ing relevant old posts, especially ones that haven’t been discussed on the Forum before?
Tomasik’s ‘Risks of astronomical future suffering’ comes to mind, as well as Assadi’s ‘Will humanity choose its future?’ and Anthis’s ...
+1. I appreciated @RobertM’s articulation of this problem for animal welfare in particular:
...I think the interventions for ensuring that animal welfare is good after we hit transformative AI probably look very different from interventions in the pretty small slice of worlds where the world looks very boring in a few decades.
…
If we achieve transformative AI and then don’t all die (because we solved alignment), then I don’t think the world will continue to have an “agricultural industry” in any meaningful sense (or, really, any other traditional industry;
Agree. Although, while the Events dashboard isn’t up to date, I notice that the EAG team released the following table in a post last month, which does have complete 2024 data:
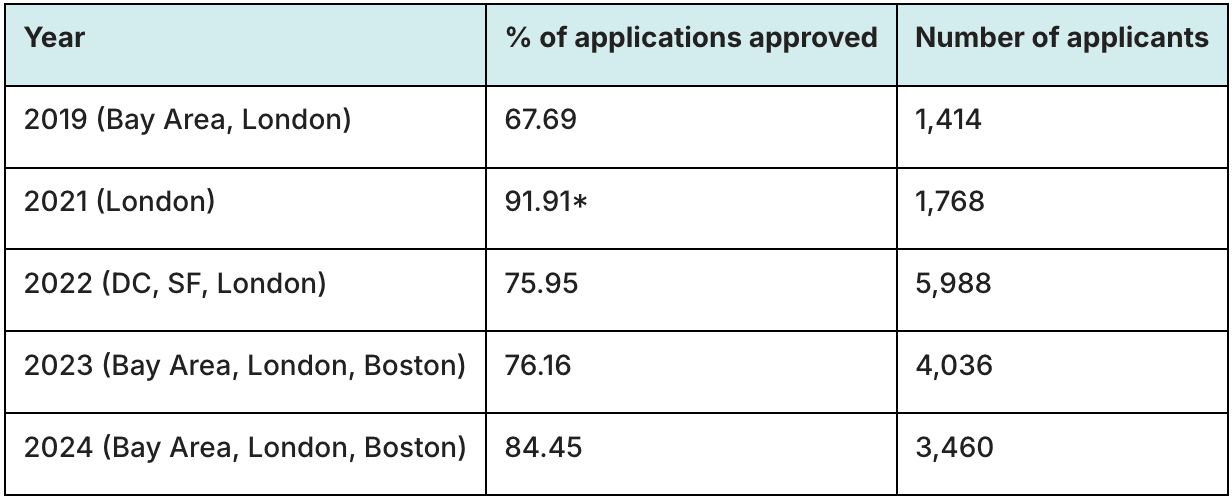
EAG applicant numbers were down 42% from 2022 to 2024,[1] which is a comparable decline to that in monthly Forum users (down 35% from November 2022’s peak to November 2024).[2]
To me, this is evidence that the dropping numbers are driven by changes in the larger zeitgeist rather than by any particular thing the Events or Online team is doing (as @Jason surmises in his&nb...
Bug report (although this could very well be me being incompetent!):
The new @mention interface doesn’t appear to take users’ karma into account when deciding which users to surface. This has the effect of showing me a bunch of users with 0 karma, none of whom are the user I’m trying to tag.[1] (I think the old interface showed higher-karma users higher up?)
More importantly, I’m still shown the wrong users even when I type in the full username of the person I’m trying to tag—in this case, Jason. [Edit: I’ve tried @ing some other users, now, and I’ve fo...
OP has provided very mixed messages around AI safety. They've provided surprisingly little funding / support for technical AI safety in the last few years (perhaps 1 full-time grantmaker?), but they have seemed to provide more support for AI safety community building / recruiting
Yeah, I find myself very confused by this state of affairs. Hundreds of people are being funneled through the AI safety community-building pipeline, but there’s little funding for them to work on things once they come out the other side.[1]
As well as being suboptimal from the ...
While not a study per se, I found the Huberman Lab podcast episode ‘How Smartphones & Social Media Impact Mental Health’ very informative. (It’s two and a half hours long, mostly about children and teenagers, and references the study(ies) it draws from, IIRC.)
For previous work, I point you to @NunoSempere’s ‘Shallow evaluations of longtermist organizations,’ if you haven’t seen it already. (While Nuño didn’t focus on AI safety orgs specifically, I thought the post was excellent, and I imagine that the evaluation methods/approaches used can be learned from and applied to AI safety orgs.)
I hope in the future there will be multiple GV-scale funders for AI GCR work, with different strengths, strategies, and comparative advantages
(Fwiw, the Metaculus crowd prediction on the question ‘Will there be another donor on the scale of 2020 Good Ventures in the Effective Altruist space in 2026?’ currently sits at 43%.)
Epistemic status: strong opinions, lightly held
I remember a time when an org was criticized, and a board member commented defending the org. But the board member was factually wrong about at least one claim, and the org then needed to walk back wrong information. It would have been clearer and less embarrassing for everyone if they’d all waited a day or two to get on the same page and write a response with the correct facts.
I guess it depends on the specifics of the situation, but, to me, the case described, of a board member making one or two incorrect cl...
Open Phil has seemingly moved away from funding ‘frontier of weirdness’-type projects and cause areas; I therefore think a hole has opened up that EAIF is well-placed to fill. In particular, I think an FHI 2.0 of some sort (perhaps starting small and scaling up if it’s going well) could be hugely valuable, and that finding a leader for this new org could fit in with your ‘running specific application rounds to fund people to work on [particularly valuable projects].’
My sense is that an FHI 2.0 grant would align well with EAIF’s scope. Quoting fro...
Thanks for clarifying!
Be useful for research on how to produce intent-aligned systems
Just checking: Do you believe this because you see the intent alignment problem as being in the class of “complex questions which ultimately have empirical answers, where it’s out of reach to test them empirically, but one may get better predictions from finding clear frameworks for thinking about them,” alongside, say, high energy physics?
my fave is @Duncan Sabien’s ‘Deadly by Default’