All of Zach Stein-Perlman's Comments + Replies
Quick take on longtermist donations for giving tuesday.
My favorite donation opportunity is Alex Bores's congressional campaign. I also like Scott Wiener's congressional campaign.
If you have to donate to a normal longtermist 501c3, I think Forethought, METR, and The Midas Project—and LTFF/ARM and Longview's Frontier AI Fund—are good and can use more money (and can't take Good Ventures money). But I focus on evaluating stuff other than normal longtermist c3s, because other stuff seems better and has been investigated much less; I don't feel very strongly abo...
As one of Zach's collaborators, I endorse these recommendations. If I had to choose among the 501c3s listed above, I'd choose Forethought first and the Midas Project second, but these are quite weakly held opinions.
I do recommend reaching out about nonpublic recommendations if you're likely to give over $20k!
- +1
- Random take: people underrate optionality / information value. Even within EA, few opportunities are within 5x of the best opportunities (even on the margin), due to inefficiencies in the process by which people get informed about donation opportunities. Waiting to donate is great if it increases your chances of donating very well. Almost all of my friends regret their past donations; they wish they'd saved money until they were better-informed.
- Random take: there are still some great c3 opportunities, but hopefully after the Anthropic people eventually g
Thanks. I'm somewhat glad to hear this.
One crux is that I'm worried that broad field-building mostly recruits people to work on stuff like "are AIs conscious" and "how can we improve short-term AI welfare" rather than "how can we do digital-minds stuff to improve what the von Neumann probes tile the universe with." So the field-building feels approximately zero-value to me — I doubt you'll be able to steer people toward the important stuff in the future.
A smaller crux is that I'm worried about lab-facing work similarly being poorly aimed.
I endorse Longview's Frontier AI Fund; I think it'll give to high-marginal-EV AI safety c3s.
I do not endorse Longview's Digital Sentience Fund. (This view is weakly held. I haven't really engaged.) I expect it'll fund misc empirical and philosophical "digital sentience" work plus unfocused field-building — not backchaining from averting AI takeover or making the long-term future go well conditional on no AI takeover. I feel only barely positive about that. (I feel excited about theoretical work like this.)
I'm a grantmaker at Longview and manage the Digital Sentience Fund—thought I'd share my thinking here: “backchaining from… making the long-term future go well conditional on no Al takeover” is my goal with the fund (with the restriction of being related to the wellbeing of AIs in a somewhat direct way), though we might disagree on how that’s best achieved through funding. Specifically, the things you’re excited about would probably be toward the top of the list of things I’m excited about, but I also think broader empirical and philosophical work and field...
$500M+/year in GCR spending
Wait, how much is it? https://www.openphilanthropy.org/grants/page/4/?q&focus-area%5B0%5D=global-catastrophic-risks&yr%5B0%5D=2025&sort=high-to-low&view-list=true lists $240M in 2025 so far.
I pulled the 500M figure from the job posting, and it includes grants we expect to make before the end of the year— I think it’s a more accurate estimate of our spending. Also, like this page says, we don’t publish all our grants (and when we do publish, there’s a delay between making the grant and publishing the page, so the website is a little behind).
I have a decent understanding of some of the space. I feel good about marginal c4 money for AIPN and SAIP. (I believe AIPN now has funding for most of 2026, but I still feel good about marginal funding.)
There are opportunities to donate to politicians and PACs which seem 5x as impactful as the best c4s. These are (1) more complicated and (2) public. If you're interested in donating ≥$20K to these, DM me. This is only for US permanent residents.
I mostly agree with the core claim. Here's how I'd put related points:
- Impact is related to productivity, not doing-your-best.
- Praiseworthiness is related to doing-your-best, not productivity.
- But doing-your-best involves maximizing productivity.
- Increasing hours-worked doesn't necessarily increase long-run productivity. (But it's somewhat suspiciously convenient to claim that it doesn't, and for many people it would.)
I haven't read all of the relevant stuff in a long time but my impression is Bio/Chem High is about uplifiting novices and Critical is about uplifting experts. See PF below. Also note OpenAI said Deep Research was safe; it's ChatGPT Agent and GPT-5 which it said required safeguards.

I haven't really thought about it and I'm not going to. If I wanted to be more precise, I'd assume that a $20 subscription is equivalent (to a company) to finding a $20 bill on the ground, assume that an ε% increase in spending on safety cancels out an ε% increase in spending on capabilities (or think about it and pick a different ratio), and look at money currently spent on safety vs capabilities. I don't think P(doom) or company-evilness is a big crux.
I think for many people, positive comments would be much less meaningful if they were rewarded/quantified, because you would doubt that they're genuine. (Especially if you excessively feel like an imposter and easily seize onto reasons to dismiss praise.)
I disagree with your recommendations despite agreeing that positive comments are undersupplied.
Given 3, a key question is what can we do to increase P(optimonium | ¬ AI doom)?
For example:
- Averting AI-enabled human-power-grabs might increase P(optimonium | ¬ AI doom)
- Averting premature lock-in and ensuring the von Neumann probes are launched deliberately would increase P(optimonium | ¬ AI doom), but what can we do about that?
- Some people seem to think that having norms of being nice to LLMs is valuable for increasing P(optimonium | ¬ AI doom), but I'm skeptical and I haven't seen this written up.
(More precisely we should talk about expected fraction of ...
One key question for the debate is: what can we do / what are the best ways to "increas[e] the value of futures where we survive"?
My guess is it's better to spend most effort on identifying possible best ways to "increas[e] the value of futures where we survive" and arguing about how valuable they are, rather than arguing about "reducing the chance of our extinction [vs] increasing the value of futures where we survive" in the abstract.
I want to make salient these propositions, which I consider very likely:
- In expectation, almost all of the resources our successors will use/affect comes via von Neumann probes (or maybe acausal trade or affecting the simulators).
- If 1, the key question for evaluating a possible future from scope-sensitive perspectives is will the von Neumann probes be launched, and what is it that they will tile the universe with? (modulo acausal trade and simulation stuff)
- [controversial] The best possible thing to tile the universe with (maybe call it "optimonium") is wild
This is circular. The principle is only compromised if (OP believes) the change decreases EV — but obviously OP doesn't believe that; OP is acting in accordance with the do-what-you-believe-maximizes-EV-after-accounting-for-second-order-effects principle.
Maybe you think people should put zero weight on avoiding looking weird/slimy (beyond what you actually are) to low-context observers (e.g. college students learning about the EA club). You haven't argued that here. (And if that's true then OP made a normal mistake; it's not compromising principles.)
Just flagging this for context of readers, I think Habryka's position/reading makes more sense if you view it in the context of an ongoing Cold War between Good Ventures and Lightcone.[1]
Some evidence on the GV side:
- The change of funding priorities from Good Ventures seems to include stopping any funding for Lightcone.
- Dustin seems to associate the decoupling norms of Lightcone with supporting actors and beliefs that he wants to have nothing to do with.
- Dustin and Oli went back and forth in the comments above, some particularly revealing comments from Dustin
I agree that things tend to get tricky and loopy around these kinds of reputation-considerations, but I think at least the approach I see you arguing for here is proving too much, and has a risk of collapsing into meaninglessness.
I think in the limit, if you treat all speech acts this way, you just end up having no grounding for communication. "Yes, it might be the case that the real principles of EA are X, but if I tell you instead they are X', then you will take better actions, so I am just going to claim they are X', as long as both X and X' include cos...
My impression is that CLTR mostly adds value via its private AI policy work. I agree its AI publications seem not super impressive but maybe that's OK.
Probably same for The Future Society and some others.
...My top candidates:
- AI Safety and Governance Fund
- PauseAI US
- Center for AI Policy
- Palisade
- MIRI
A classification of every other org I reviewed:
Good but not funding-constrained: Center for AI Safety, Future of Life Institute
Would fund if I had more money: Control AI, Existential Risk Observatory, Lightcone Infrastructure, PauseAI Global, Sentinel
Would fund if I had a lot more money, but might fund orgs in other cause areas first: AI Policy Institute, CEEALAR, Center for Human-Compatible AI, Manifund
Might fund if I had a lot more money: AI Standards Lab, Centre for
Here's my longtermist, AI focused list. I really haven't done my research, e.g. I read zero marginal funding posts. MATS is probably the most popular of these, so this is basically a vote for MATS.

I would have ranked The Midas Project around 5 but it wasn't an option.
"Improve US AI policy 5 percentage points" was defined as
Instead of buying think tanks, this option lets you improve AI policy directly. The distribution of possible US AI policies will go from being centered on the 50th-percentile-good outcome to being centered on the 55th-percentile-good outcome, as per your personal definition of good outcomes. The variance will stay the same.
(This is still poorly defined.)
A few DC and EU people tell me that in private, Anthropic (and others) are more unequivocally antiregulation than their public statements would suggest.
I've tried to get this on the record—person X says that Anthropic said Y at meeting Z, or just Y and Z—but my sources have declined.
I believe that Anthropic's policy advocacy is (1) bad and (2) worse in private than in public.
But Dario and Jack Clark do publicly oppose strong regulation. See https://ailabwatch.org/resources/company-advocacy/#dario-on-in-good-company-podcast and https://ailabwatch.org/resources/company-advocacy/#jack-clark. So this letter isn't surprising or a new betrayal — the issue is the preexisting antiregulation position, insofar as it's unreasonable.
Actually, this is a poor description of my reaction to this post. Oops. I should have said:
Digital mind takeoff is maybe-plausibly crucial to how the long-term future goes. But this post seems to focus on short-term stuff such that the considerations it discusses miss the point (according to my normative and empirical beliefs). Like, the y-axis in the graphs is what matters short-term (and it's at most weakly associated with what matters long-term: affecting the von Neumann probe values or similar). And the post is just generally concerned with short-term ...
The considerations in this post (and most "AI welfare" posts) are not directly important to digital mind value stuff, I think, if digital mind value stuff is dominated by possible superbeneficiaries created by von Neumann probes in the long-term future. (Note: this is a mix of normative and empirical claims.)
When telling stories like your first paragraph, I wish people either said "almost all of the galaxies we reach are tiled with some flavor of computronium and here's how AI welfare work affected the flavor" or "it is not the case that almost all of the galaxies we reach are tiled with some flavor of computronium and here's why."
The universe will very likely be tiled with some flavor of computronium is a crucial consideration, I think.
Briefly + roughly (not precise):
At some point we'll send out lightspeed probes to tile the universe with some flavor of computronium. The key question (for scope-sensitive altruists) is what that computronium will compute. Will an unwise agent or incoherent egregore answer that question thoughtlessly? I intuit no.
I can't easily make this intuition legible. (So I likely won't reply to messages about this.)
I agree this is possible, and I think a decent fraction of the value of "AI welfare" work comes from stuff like this.
Those humans decide to dictate some or all of what the future looks like, and lots of AIs end up suffering in this future because their welfare isn't considered by the decision makers.
This would be very weird: it requires that either the value-setters are very rushed or that they have lots of time to consult with superintelligent advisors but still make the wrong choice. Both paths seem unlikely.
Caveats:
- I endorse the argument we should figure out how to use LLM-based systems without accidentally torturing them because they're more likely to take catastrophic actions if we're torturing them.
- I haven't tried to understand the argument we should try to pay AIs to [not betray us / tell on traitors / etc.] and working on AI-welfare stuff would help us offer AIs payment better; there might be something there.
- I don't understand the decision theory mumble mumble argument; there might be something there.
(Other than that, it seems hard to tell a story about ...
My position on "AI welfare"
- If we achieve existential security and launch the von Neumann probes successfully, we will be able to do >>10^80 operations in expectation. We could tile the universe with hedonium or do acausal trade or something and it's worth >>10^60 happy human lives in expectation. Digital minds are super important.
- Short-term AI suffering will be small-scale—less than 10^40 FLOP and far from optimized for suffering, even if suffering is incidental—and worth <<10^20 happy human lives (very likely <10^10).
- 10^20 isn't even
Why does "lock-in" seem so unlikely to you?
One story:
- Assume AI welfare matters
- Aligned AI concentrates power in a small group of humans
- AI technology allows them to dictate aspects of the future / cause some "lock in" if they want. That's because:
- These humans control the AI systems that have all the hard power in the world
- Those AI systems will retain all the hard power indefinitely; their wishes cannot be subverted
- Those AI systems will continue to obey whatever instructions they are given indefinitely
- Those humans decide to dictate some or all of what the fut
I basically agree with this with some caveats. (Despite writing a post discussing AI welfare interventions.)
I discuss related topics here and what fraction of resources should go to AI welfare. (A section in the same post I link above.)
The main caveats to my agreement are:
- From a deontology-style perspective, I think there is a pretty good case for trying to do something reasonable on AI welfare. Minimally, we should try to make sure that AIs consent to their current overall situation insofar as they are capable of consenting. I don't put a huge amount of w
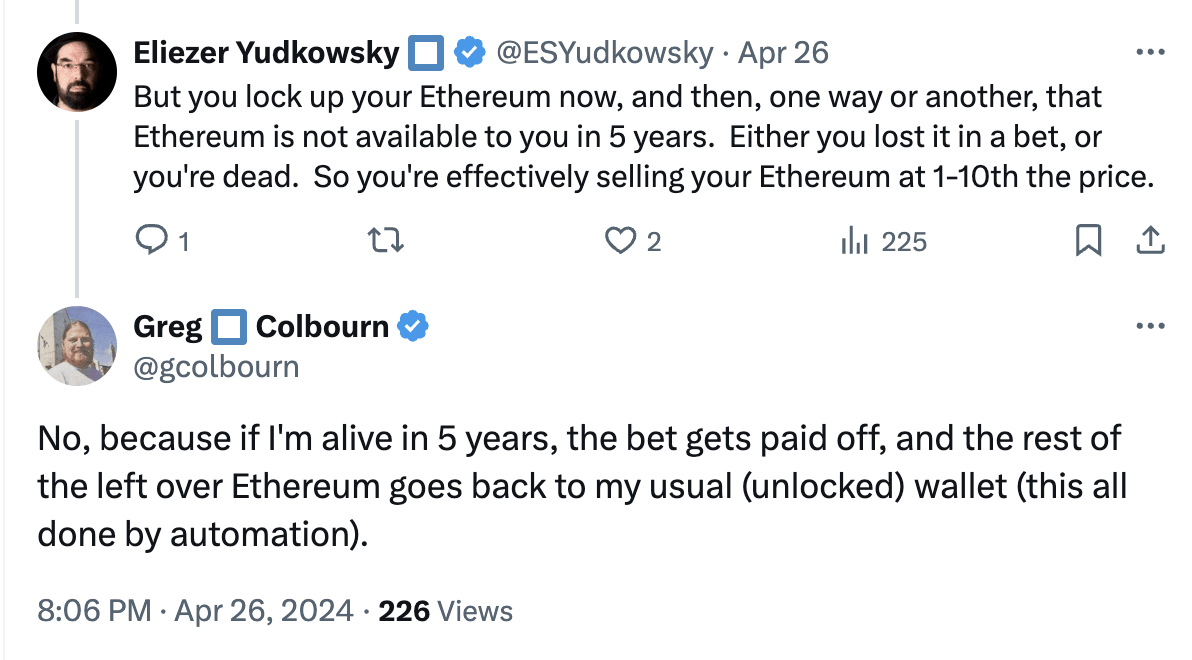
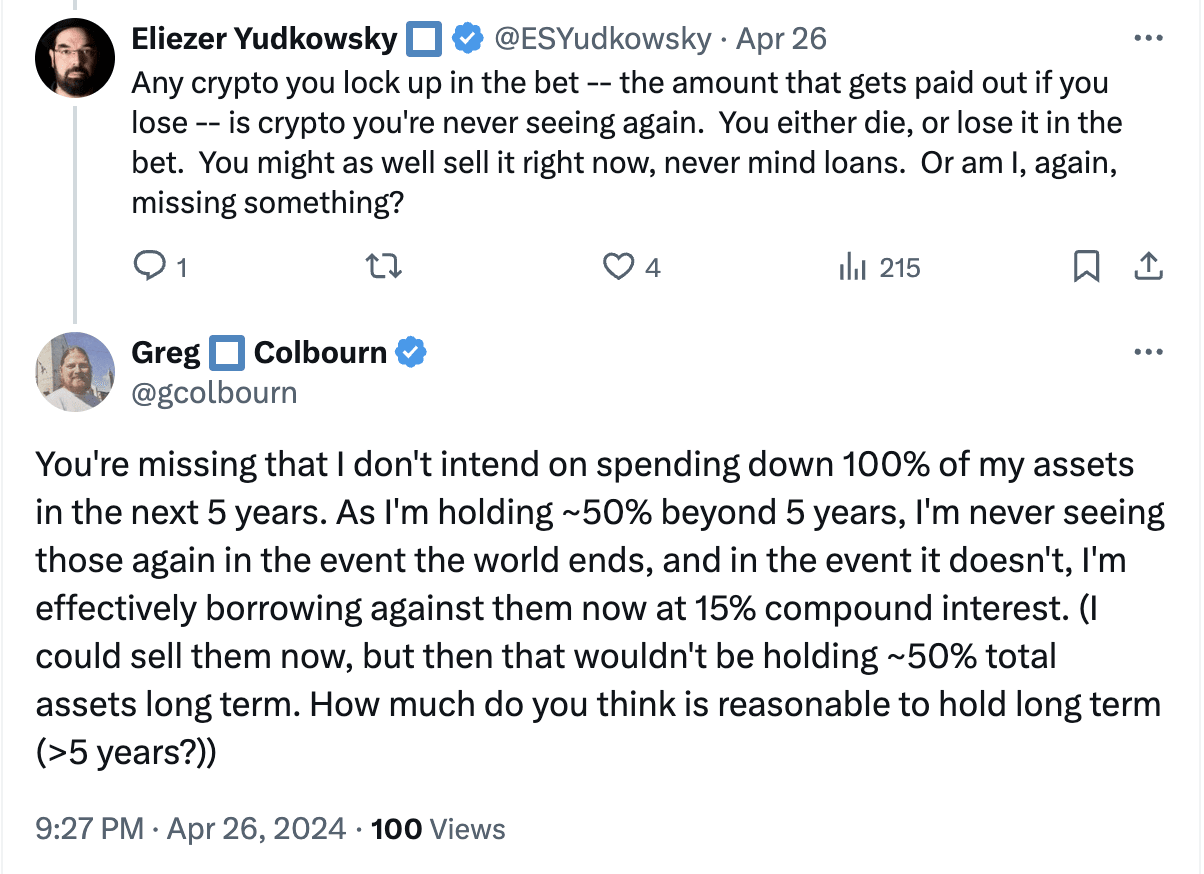
For anyone who wants to bet on doom:
- I claim it can’t possibly be good for you
- Unless you plan to spend all of your money before you would owe money back
- People seem to think what matters is ∫bankroll when what actually matters is ∫consumption?
- Or unless you're betting on high rates of returns to capital, not really on doom
- Unless you plan to spend all of your money before you would owe money back
- Good news: you can probably borrow cheaply. E.g. if you have $2X in investments, you can sell them, invest $X at 2x leverage, and effectively borrow the other $X.
Greg made a bad bet. He could do strictly better, by his lights, by borrowing 10K, giving it to PauseAI, and paying back ~15K (10K + high interest) in 4 years. (Or he could just donate 10K to PauseAI. If he's unable to do this, Vasco should worry about Greg's liquidity in 4 years.) Or he could have gotten a better deal by betting with someone else; if there was a market for this bet, I claim the market price would be substantially more favorable to Greg than paying back 200% (plus inflation) over <4 years.
[Edit: the market for this bet is, like, the market for 4-year personal loans.]
Thanks for the comment, Zach! Jason suggested something similar to Greg:
As much as I may appreciate a good wager, I would feel remiss not to ask if you could get a better result for amount of home equity at risk by getting a HELOC and having a bank be the counterparty? Maybe not at lower dollar amounts due to fixed costs/fees, but likely so nearer the $250K point [Greg was willing to bet up to this] -- especially with the expectation that interest rates will go down later in the year.
Greg replied the following on April 17:
...I don't have a stable income so I
This isn't really against Zach’s point, but presumably, a lot of Greg's motivation here is signalling that he is serious about this belief and having a bunch of people in this community see it for advocacy reasons. I think that taking out a loan wouldn't do nearly as well on the advocacy front as making a public bet like this.
This isn’t true if Greg values animal welfare donations above most non-AI things by a sufficient amount. He could have tried to shop around for more favorable conditions with someone else in EA circles but it seems pretty likely that he’d end up going with this one. There’s no market for these bets.
Yes, I've previously made some folks at Anthropic aware of these concerns, e.g. associated with this post.
In response to this post, Zac Hatfield-Dodds told me he expects Anthropic will publish more information about its governance in the future.
I claim that public information is very consistent with the investors hold an axe over the Trust; maybe the Trust will cause the Board to be slightly better or the investors will abrogate the Trust or the Trustees will loudly resign at some point; regardless, the Trust is very subordinate to the investors and won't be able to do much.
And if so, I think it's reasonable to describe the Trust as "maybe powerless."
Maybe. Note that they sometimes brag about how independent the Trust is and how some investors dislike it, e.g. Dario:
Every traditional investor who invests in Anthropic looks at this. Some of them are just like, whatever, you run your company how you want. Some of them are like, oh my god, this body of random people could move Anthropic in a direction that's totally contrary to shareholder value.
And I've never heard someone from Anthropic suggest this.
I suspect the informal agreement was nothing more than the UK AI safety summit "safety testing" session, which is devoid of specific commitments.
Two hours before you posted this, MacAskill posted a brief explanation of viatopianism.
... (read more)