Comments
missing something here
: "Peter Wildeford looks at the chances of accidental nuclear war (a), by giving the chance of a nuclear incident based on historical frequency using Laplace's law, and then his"
missing something here
: "Peter Wildeford looks at the chances of accidental nuclear war (a), by giving the chance of a nuclear incident based on historical frequency using Laplace's law, and then his"
Thanks, changed to:
Peter Wildeford looks at the chances of accidental nuclear war (a), by giving the chance of a nuclear incident based on historical frequency of close calls using Laplace's law, and then another application of Laplace’s law to the chance that a nuclear close call will escalate. Personally I’d be a bit higher than him because of anthropic effects.



You can sign up for this newsletter on substack, or browse past newsletters here. If you have a content suggestion or want to reach out, you can leave a comment or find me on Twitter.
Applying to the FTX Future Fund (a) with forecasting projects is still a good idea.
The Survival and Flourishing Fund donated a bit over $1M to forecasting projects (a): $461k to the Quantified Uncertainty Research Insitute (my org), $346k to the Social Science Prediction Platform, and $343k towards Manifold Markets. From what I can tell, the funding generally came much later than expected, and thus was less useful. For instance, Manifold Markets has already carried out a funding round.
Blockchain-based prediction markets continue popping up. Some never leave the beta phase. For example, this month I stumbled upon Oracula (a) and Presaga (a). On the one hand, having many fragmented real-money prediction markets seems good for the traders who are skilled at arbitrage. But on the other hand, it seems likely that prediction markets might have some features of a winner-take-all dynamics: bettors will want to bet where other people are betting.
Amongst friends and colleagues working in the forecasting space, I am also noticing that there is an incentive towards creating new organizations, rather than taking part in organizations that already exist. I think this might be because it sounds more prestigious to lead one's own small organization and because one can otherwise capture a larger share of the value that one creates. But I think that creating many micro-organizations creates less value overall because the operations burden is greater. Here is a post by my boss on a similar topic.
Metaculus rapidly created forecasts about the new monkeypox outbreak. Besides this, Metaculus updated its social media previews (a), its journal spawned a podcast (a), and its CEO wrote an essay on Forecasting, Science, and Epistemology (a).
Manifold added some categories to organize their markets, added the possibility of replying to comments, moved to Algolia for market search, added one-click betting, added a numeric (rather than pointwise) market type, and added embedded markets in the EA forum. A hat-tip to David, who maintains a nice to read newsletter (a) on Manifold's progress. Honestly, I'm not sure I even should be covering Manifold's individual platform improvements rather than remarking that their development speed seems to still be much faster than that of other platforms. Manifold's team also visited the Bahamas (a).
INFER hosted a discussion on Reasserting U.S. Leadership in Microelectronics (a). It also talks about the race for AI dominance (a) in its newsletter. Conditional on a US/China AI race occurring, I would want the US to win it. But I would rather prefer there to not be such a race. So I'm not sure how to feel about various organizations around the EA (Effective Altruism) sphere, such as INFER, CSET or the Institute for Progress using bellicose and adversarial language and strategies. For instance, one can frame one's positions and justify one’s usefulness with reference to what the US needs to do in order to maintain its superiority over China. This might appeal to Republicans worried about national security, but also make non-adversarial framings more difficult to see.
Good Judgment Open has some analysis of whether Putin will cease to be president of the Russian Federation before 2023. See here (a) for a comment arguing that this is ~5% unlikely and here (a) for a comment that this is ~70% likely.
Kalshi was profiled by Bloomberg (a). The article is very much worth reading: it gives a nice view of Kalshi's journey, and reveals some interesting details about the regulatory morass that Kalshi had to deal with.
The Bloomberg article also references a frankly embarrassing 2012 CFTC order (a) prohibiting Nadex from offering contracts on binary outcomes, because they deemed it to be "against the public interest". The order stated:
"there is no situation in which the Political Event Contracts' prices could form the basis for the pricing of a commercial transaction involving a physical commodity, financial asset or service, which demonstrates that the Political Event Contracts have no price basing utility".
Kalshi also made an Arbitrage calculator between markets that were on PredictIt and now are also on Kalshi.
Open Philanthropy is requesting proposals for quantifying biological risks (a). The deadline to apply is June 5th. I think it wouldn't be that hard to assemble a good team to do this, If you are interested, leave a comment or send me an email at [email protected].
Strippers explain how strip clubs can be a 'leading indicator' in forecasting a recession (a):
Some strippers believe a recession is guaranteed because strip clubs are emptying—a "leading indicator" there is an economic downturn.
…
"I had a friend who stopped stripping after the 2008 housing crash. She said it was not worth dealing with men. Prior to that she was making over $2k and up a night, she said went down to $300/night. She got out quick. Definitely a good indicator how the economy is doing,"
Chris Brunett, a conservative economics blogger with a penchant for sensationalism, writes about Turning $1,000 to $10,000 on Insight Prediction (a). Note that he hasn't yet done 10x his initial pot, but rather is aiming to do so.
More interestingly, he is creating a speculative financial instrument (a) through which he is allowing others to buy into his proto-hedge fund. To be clear, I emphatically do not recommend that people invest in this: Brunet's forecasting track record is a bit spotty, the smart contracts he uses allows him to create infinite money, and the legal status of the whole thing is dubious. That said, it is an interesting and innovative instrument, I'm intrigued about where it will go, and I don’t expect Brunett to cheat investors.
Czech Priorities has an update on their forecasting work (a) trying to influence the Czech government.
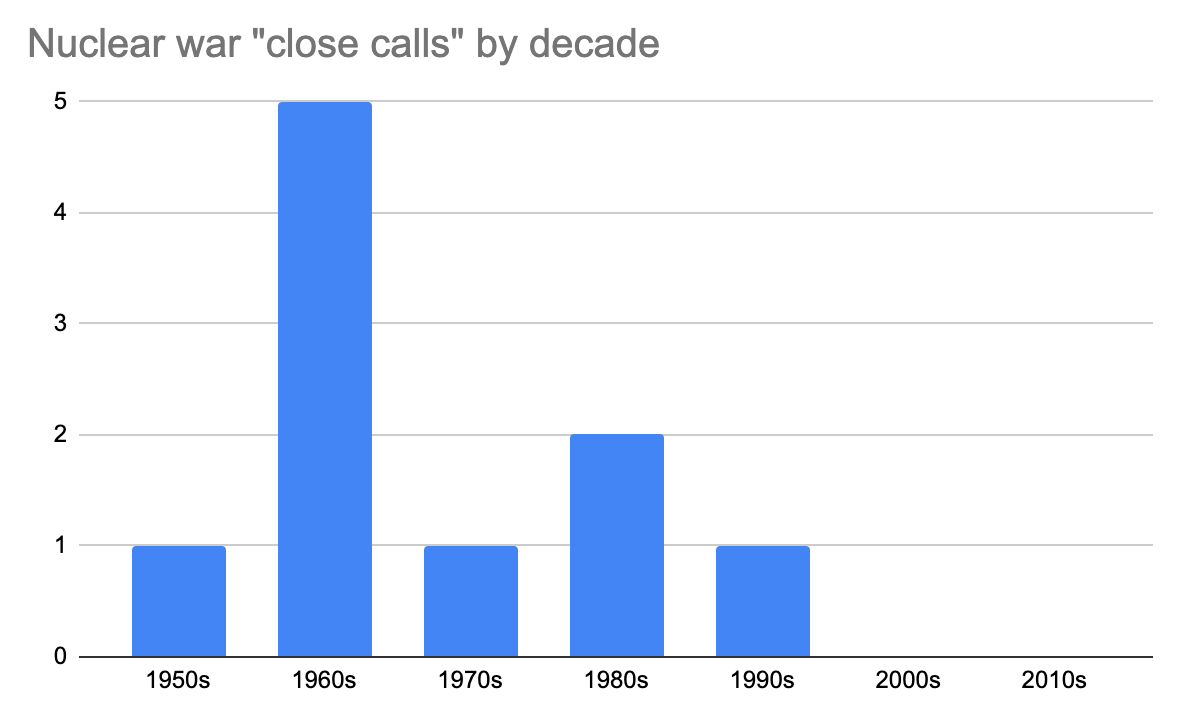
Peter Wildeford looks at the chances of accidental nuclear war (a), by giving the chance of a nuclear incident based on the historical frequency of close calls using Laplace's law, and then another application of Laplace’s law to the chance that a nuclear close call will escalate. Personally, I’d be a bit higher than him because of anthropic effects.
@botec_horseman (a) is a new Twitter account dedicated to Back Of The Envelope (BOTEC) estimates. h/t Nathan Young.
Is AI Progress Impossible To Predict? (a):
Could we forecast AI progress ahead of time by seeing how each task gets better with model size, draw out the curve, and calculate which size model is needed to reach human performance?
I tried this, and apparently the answer is no. In fact, whether AI has improved on a task recently gives us exactly zero predictive power for how much the next model will improve on the same task
NOAA predicts above-normal 2022 Atlantic Hurricane Season (a). "Forecasters at NOAA’s Climate Prediction Center, a division of the National Weather Service, are predicting above-average hurricane activity this year — which would make it the seventh consecutive above-average hurricane season" (emphasis mine).
Jotto, an experienced Metaculus forecaster, cautions against boasting about non-existent forecasting track records (a):
If they want forecaster prestige, their forecasts must be:
- Pre-registered,
- So unambiguous that people actually agree whether the event "happened",
- With probabilities and numbers so we can gauge calibration,
- And include enough forecasts that it's not just a fluke or cherry-picking.
When Eliezer Yudkowsky talks about forecasting AI, he has several times claimed implied he has a great forecasting track record. But a meaningful "forecasting track record" has well-known and very specific requirements, and Eliezer doesn't show these.
Nick Bosse and others release a comprehensive R package for scoring forecasts (a) (twitter (a), CRAN (a), accompanying arxiv paper (a)). Per the CRAN logs (a) so far it's seeing a smallish to medium number of downloads (791 so far, and 151 in the last week). But once a library is well-engineered, I think it will tend to last. And it makes developments in other languages easier.
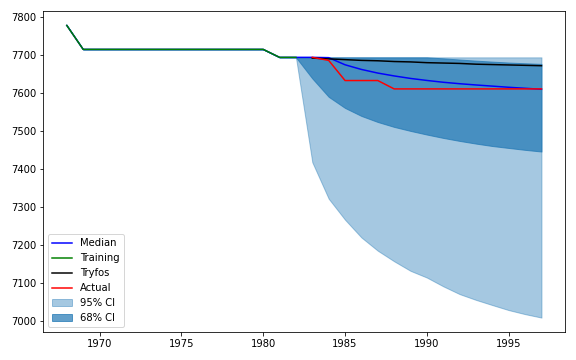
Jaime Sevilla and Jonathan Lindbloom publish some research on Bayesian models of records (a) (twitter summary (a)), that is, on the maximums and minimums that a time series will take. I was expecting the approach to be based on having a large database of past records to create a prior. Instead, the authors model records as attempts drawn from the same distribution, which they model as uncertainty over a flat prior over Weibull distributions.
This approach might work for some problems, like Olympic records. But it would do less well over other problems where assuming identically distributed draws would not be a good assumption. For instance, Moore's law—or technological progress more generally—doesn't lend itself well to being modelled using this approach, because new approaches tend to build on top of previous approaches. The authors are planning to address this in future work.
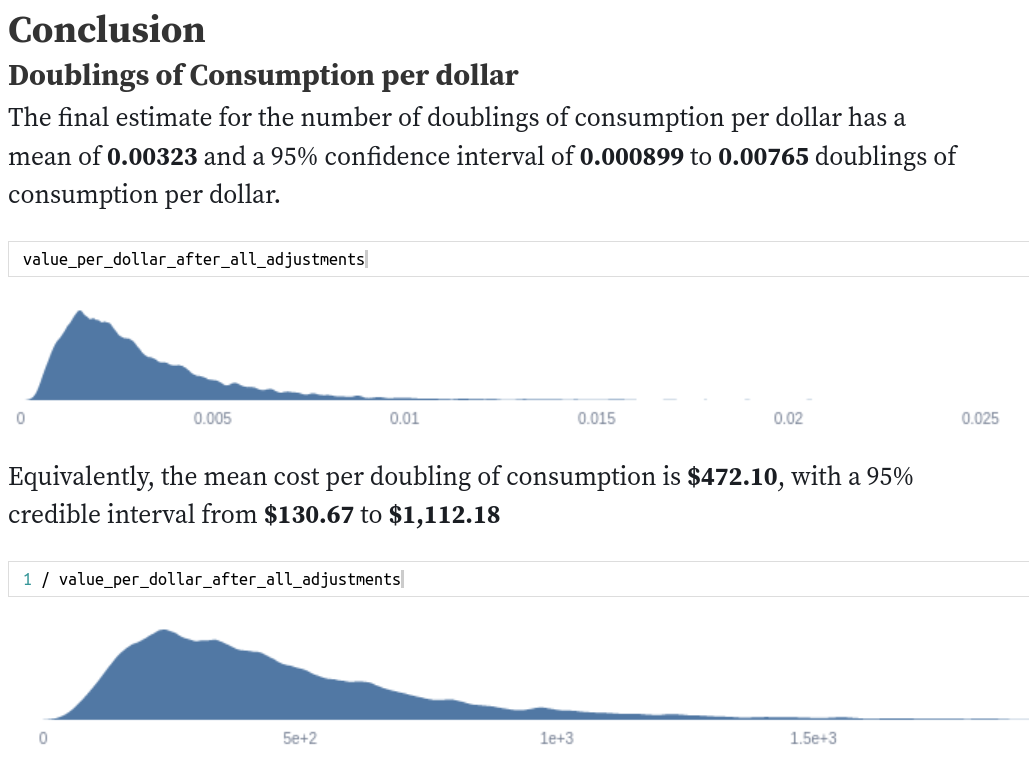
My colleague Sam Nolan looks at Quantifying Uncertainty in GiveWell's GiveDirectly Cost-Effectiveness Analysis (a). He takes point estimates of impact by GiveDirectly, and transforms them into estimates using distributions.
Niplav looks at range and forecasting accuracy (a). I reviewed a version of this post in a previous newsletter. The new version has analysis in Python as well as some further analysis. I would recommend reading the results section at the top.
Note to the future: All links are added automatically to the Internet Archive, using this tool (a). "(a)" for archived links was inspired by Milan Griffes (a), Andrew Zuckerman (a), and Alexey Guzey (a).
There are no stupid questions, but there are a lot of inquisitive idiots
— Unattributed
+1
+1. It seems like an instance of the general problem non-profit organisations get started too frequently and closed down too infrequently (compared to for-profits). Of course we do want small new projects to be started, and to compete with one another when they are genuinely scalable. I suppose the appropriate solution to incentivise all of this is to increase salaries at these orgs, and to make the grantmaking more sensitive to scale and impact...
Cheers!