Note: This post was crossposted from Planned Obsolescence by the Forum team, with the author's permission. The author may not see or respond to comments on this post.
This startlingly fast progress in LLMs was driven both by scaling up LLMs and doing schlep to make usable systems out of them. We think scale and schlep will both improve rapidly.
Kelsey Piper co-drafted this post. Thanks also to Isabel Juniewicz for research help.
In January 2022, language models were still a pretty niche scientific interest. Once ChatGPT was released in November 2022, it accumulated a record-breaking 100 million users by February 2023. Many of those users were utterly flabbergasted by how far AI had come, and how fast. And every way we slice it, most experts were very surprised as well.
This startlingly fast progress was largely driven by scale and partly driven by schlep.
Scale involves training larger language models on larger datasets using more computation, and doing all of this more efficiently over time. “Training compute,” measured in “floating point operations” or FLOP, is the most important unit of scale. We can increase training compute by simply spending more money to buy more chips, or by making the chips more efficient (packing in more FLOP per dollar). Over time, researchers also invent tweaks to model architectures and optimization algorithms and training processes to make training more compute-efficient — so each FLOP spent on training goes further in 2023 compared to 2020.
Scale has been by far the biggest factor in the improvements in language models to date. GPT-4 is bigger than GPT-3.5 which is bigger than GPT-3 which is bigger than GPT-2 which is bigger than GPT.
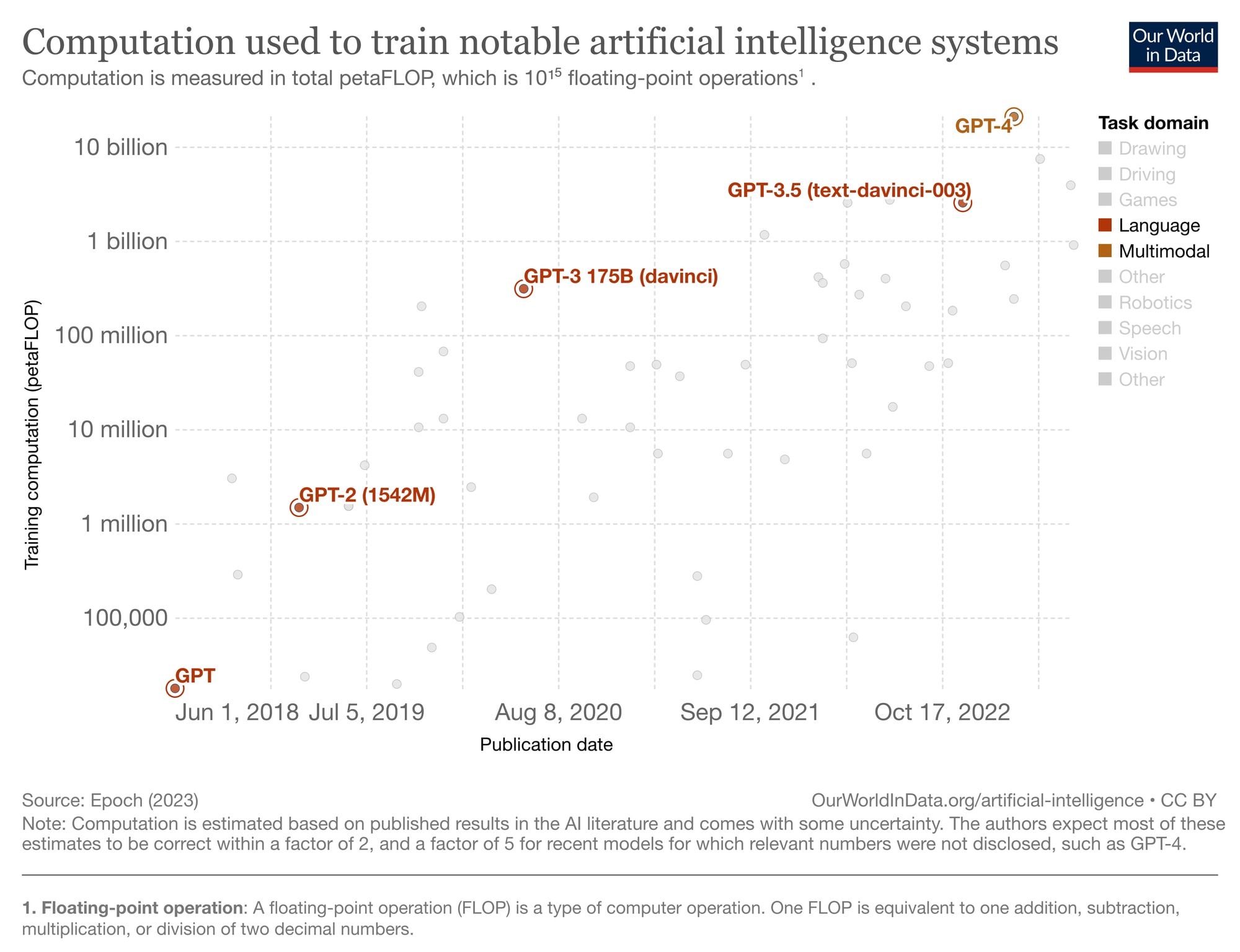
Increasing scale automatically improves performance on pretty much every test of skill or practically useful task. GPT-2 got an F- on college-level multiple choice tests ranging from abstract algebra to business ethics; GPT-4 got a B+. GPT-2 was just starting to string together plausible-sounding paragraphs; GPT-4 can write essays that net a B+ at Harvard — and hundreds of lines of functioning code that can take human programmers hours to reproduce.
If you add more data, more parameters, and more compute, you’ll probably get something that is a lot better yet. GPT-4.5 will perform much better than GPT-4 on most tests designed to measure understanding of the world, practical reasoning in messy situations, and mathematical and scientific problem-solving. A whole lot of things GPT-4 struggles with will probably come easily to GPT-4.5. It will probably generate a whole lot more economic value, and present much bigger societal risks. And then the same thing will happen all over again with GPT-5. We think the dramatic performance improvements from scale will continue for at least another couple of orders of magnitude — as Geoffrey Hinton joked in 2020, “Extrapolating the spectacular performance of GPT-3 into the future suggests that the answer to life, the universe and everything is just 4.398 trillion parameters.”
But even if no one trained a larger-scale model than GPT-4, and its basic architecture and training process never got any more efficient, there would still probably be major economic change from language models over the next decade. This is because we can do a lot of schlep to better leverage the language models we already have and integrate them into our workflows.
By schlep, we mean things like prompting language models to give higher-quality answers or answers more appropriate to a certain use case, addressing annoying foibles like hallucination with in-built fact-checking and verification steps, collecting specialized datasets tailored to specific tasks and fine-tuning language models on these datasets, providing language models with tools and plug-ins such as web search and code interpreters, and doing a lot of good old fashioned software engineering to package all this into sleek usable products like ChatGPT.
For one example of what schlep can do to improve language models, take chain of thought prompting. Chain of thought prompting is dead simple — it’s basically the same thing as your teacher reminding you to show your work — and it substantially improves the performance of language models on all kinds of problems, from mathematical problem-solving to ‘common sense’ reasoning.
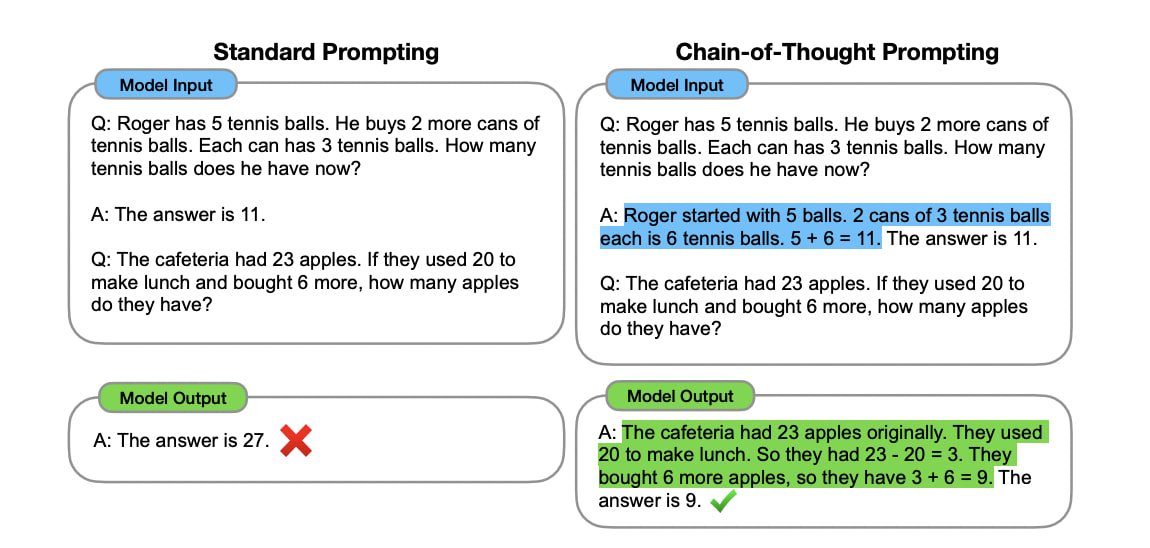
By default, language models can only answer questions by immediately spitting out the first word of their answer, then rolling with whatever they said and immediately spitting out the next word, and so on word-by-word until eventually they’ve completed their thought. They are unable to backtrack or get any thinking done outside of the next-word rhythm.
Imagine if you had to take a standardized test like that: by answering every question on the spot without any backtracking, as if you were being interviewed on live TV. For one thing, it would be very hard! For another, you’d probably do a lot better if you verbalized your reasoning step by step than if you just tried to blurt out the final answer. This is exactly what we see in chain-of-thought.
This suggests chain-of-thought is probably not just a one-off trick, but an instance of a more general pattern: language models will probably perform better if they can spend more effort iterating on and refining their answers to difficult questions, just like humans get to do. In fact, simply allowing language models to spit out a “pause and think longer” symbol rather than having to commit to the next word immediately also seems to improve performance.
Scale makes language models better. Techniques like chain-of-thought improve models at any given scale. But it’s more than that: chain of thought prompting only works at all on sufficiently large language models, and the returns are greater when it’s used on bigger models which were already more powerful to begin with.
You could imagine a variety of more elaborate techniques that follow the same principle. For example, you could imagine equipping an LLM with a full-featured text editor, allowing it to backtrack and revise its work in the way humans do. Or you could imagine giving a language model two output streams: one for the answer, and one for its stream-of-consciousness thoughts about the answer it’s writing. Imagine a language model that had the option to iterate for days on one question, writing notes to itself as it mulls things over. The bigger and more capable it is, the more use it could get out of this affordance. Giving a genius mathematician a scratchpad will make a bigger difference than giving one to a six year old.
Another technique that dramatically improves performance of models at a given size is fine-tuning: retraining a large model on a small amount of well-chosen data in order to get much better-targeted responses for a given use case. For example, reinforcement learning from human feedback (RLHF) involves fine-tuning models on whether human raters liked its answer. Without RLHF, a language model might riff off a question or generate the kind of text that would surround that question on a website, instead of answering it. In effect, RLHF gets the model to ‘realize’ that it should be aiming to use its capabilities and knowledge to answer questions well rather than predict text on the internet: two different tasks, with a lot of overlapping skills.
With prompting and fine-tuning and a lot of other schlep, we can build systems out of language models. ChatGPT is a very simple and very familiar example of a language model system. To understand all of the ways that ChatGPT is a system, not just a language model, it’s useful to compare it to InstructGPT, which is the same basic underlying technology. Before ChatGPT was released, InstructGPT was available to people who made an account to test it out in OpenAI’s playground.
Here’s the UI for OpenAI’s playground today (it was worse a year ago but unfortunately we don’t have a screenshot of it from then):
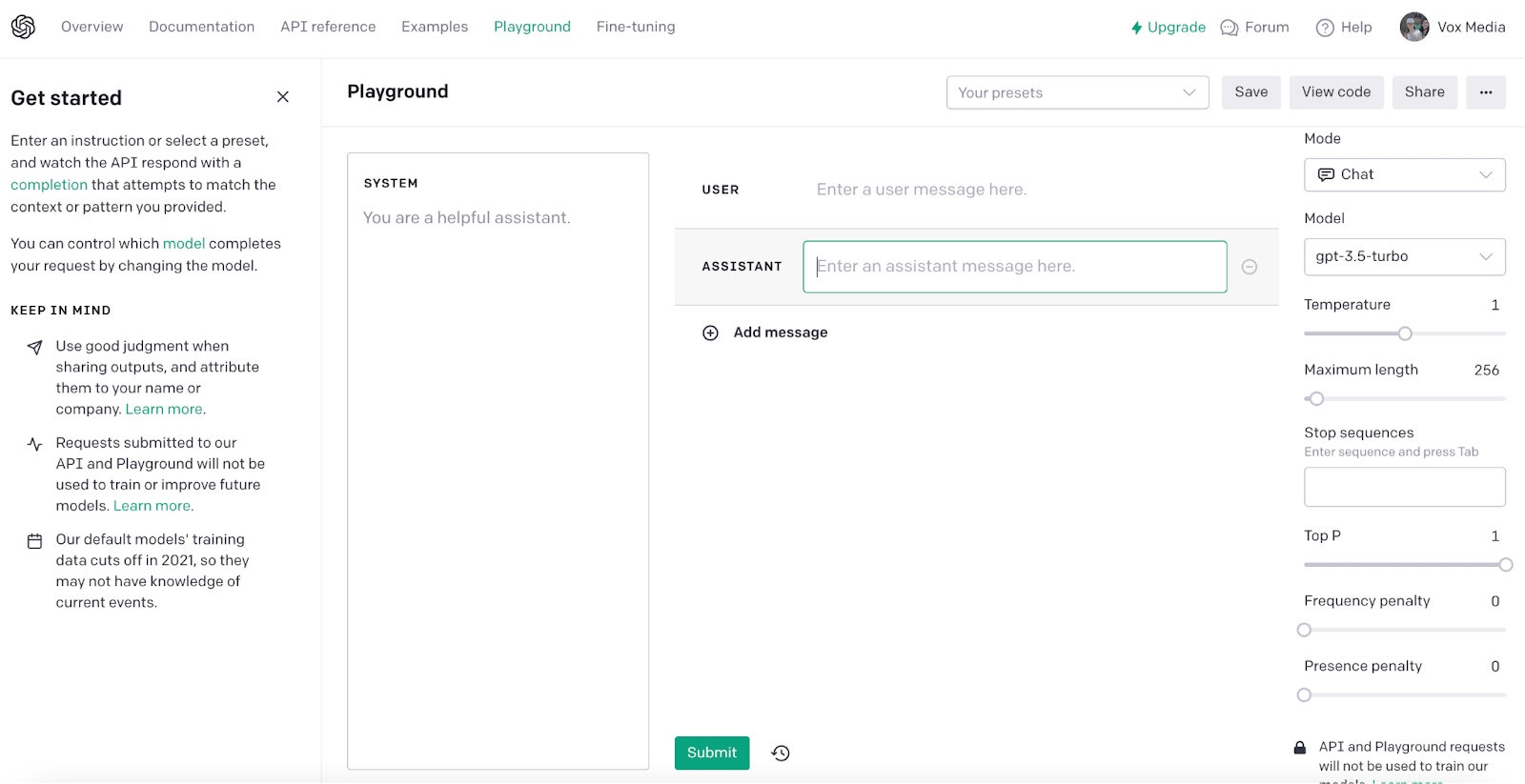
If you’re an experienced LLM expert, the option to customize temperature and adjust the frequency penalty and presence penalty, add stop sequences, and so on is really useful. If you’re a random consumer, all of that is intimidating. ChatGPT’s UI abstracts it away:
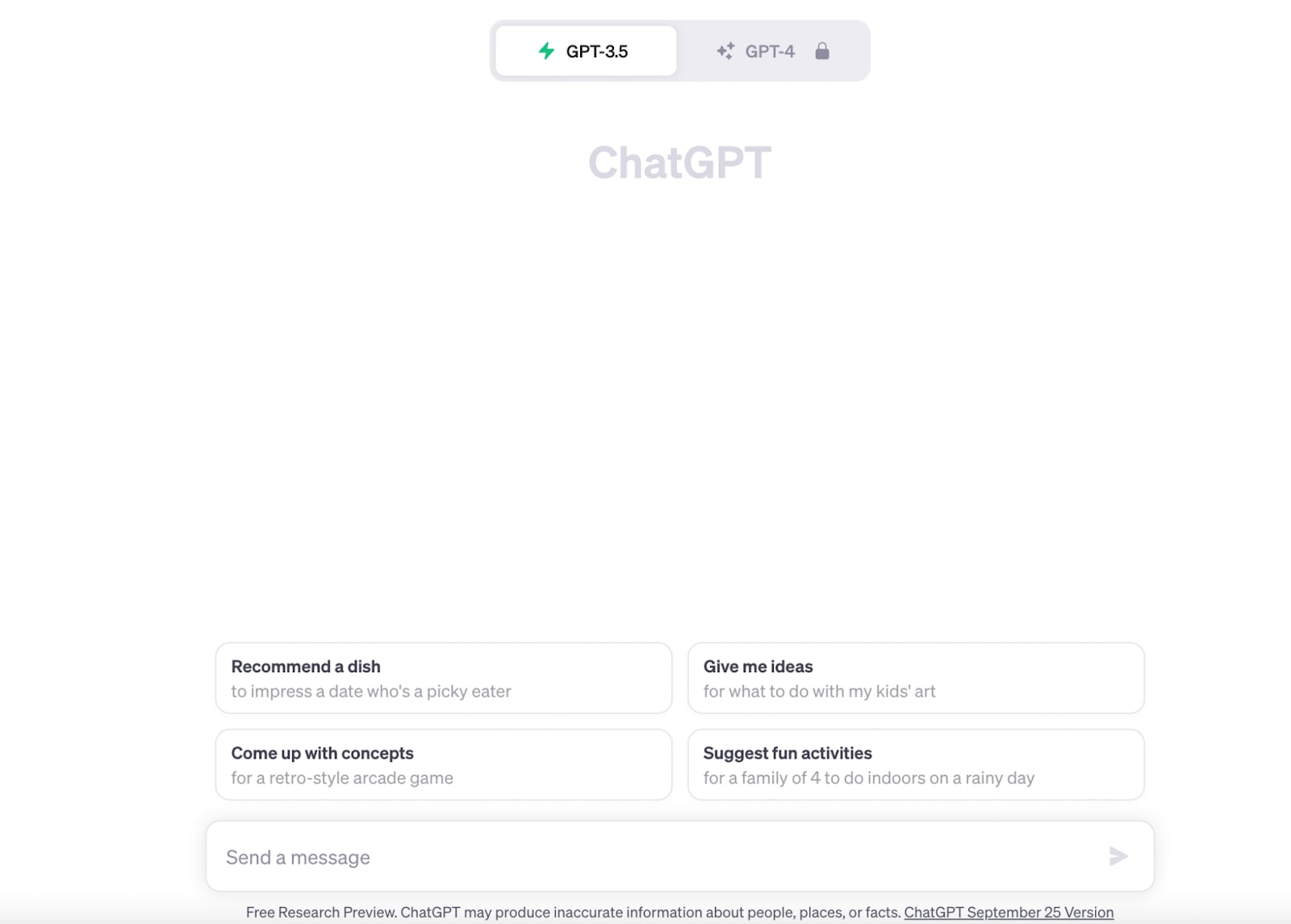
That UI difference might seem small. But InstructGPT was mostly used only by a small community of researchers, and ChatGPT reached 100 million users within two months of launch. The difference between the two products was essentially presentation, user experience, and marketing. That kind of thing can result in massive differences in actual user behavior. Some of the work that goes into making language model systems, then, is about figuring out how to make the model usable for users.
If language models are like engines, then language model systems would be like cars and motorcycles and jet planes. Systems like Khan Academy’s one-on-one math tutor or Stripe’s interactive developer docs would not be possible to build without good language models, just as cars wouldn’t be possible without engines. But making these products a reality also involves doing a lot of schlep to pull together the “raw” language model with other key ingredients, getting them all to work well together, and putting them in a usable package. Similarly, self-driving cars would not be possible without really good vision models, but a self-driving car is more than just a big vision neural network sitting in a server somewhere.
One kind of language model system that has attracted a lot of attention and discussion is a language model agent.
An agent is a system which independently makes decisions and acts in the world. A language model is not an agent, but language models can be the key component powering a system which is agentic and takes actions in the world. The most famous early implementation of this is Auto-GPT, a very straightforward and naive approach: you can tell it a goal, and it will self-prompt repeatedly to take actions towards this goal. People have already employed it towards a wide range of goals, including building ChaosGPT, which has the goal of destroying humanity.
Auto-GPT is not very good. Users have complained that it constantly comes up with reasons to do more research and is reluctant to decide that it’s done enough research and can actually do the task now. It’s also just not very reliable. But there are many people building agentic language models for commercial uses, and working to solve all of these shortcomings, including well-funded and significantly-sized companies like Imbue and Adept. Adding chain of thought prompting, fine tuning the underlying language models, and many similar measures will likely make agents a lot better – and, of course, increasing scale will make them better too.
We’re really at the very beginning of this work. It wouldn’t be surprising to see major advances in the practical usefulness of LLMs achieved through schlep alone, such that agents and other systems built out of GPT-4 tier models are much more useful in five years than they are today. And of course, we are continuing to scale up models at the same time. That creates the conditions for rapid improvements along many dimensions at once — improvements which could reinforce each other. Many people will be trying hard to make this a reality. Even if specific approaches meet dead-ends, the field as a whole doesn’t seem likely to.


Just out of curiosity: Where is the word "schlep" originating from in the context of AI? Don't think I ever came across it before reading this post.
I assume and (ChatGPT agrees) that it's the tedious, unglamorous, and labor-intensive work. It probably comes from the Germany "schleppen" which is "heavy lifting".