Comments
If you are looking at presidential candidates, why restrict your analysis to AI alignment?
If you're super focused on that issue, then it will definitely be better to spend your money on actual AI research, or on some kind of direct effort to push the government to consider the issue (if such an effort exists).
When judging among the presidential candidates, other issues matter too! And in this context, they should be weighted more by their sheer importance than by philanthropic neglectedness. So AI risk is not obviously the most important.
With some help from other people I comprehensively reviewed 2020 candidates here: https://t.co/kMby2RDNDx
The conclusion is that yes, Yang is one of the best candidates to support - alongside Booker, Buttigieg, and Republican primary challengers. Partially due to his awareness of AI risk. But in the updates I've made for the 8th edition (and what I'm about to change now, seeing some other comments here about the lack of tractability for this issue), Buttigieg seems to move ahead to being the best Democrat by a small margin. Of course these judgments are pretty uncertain so you could argue that they are wrong if you find some flaw or omission in the report. Very early on, I decided that both Yang and Buttigieg were not good candidates, but that changed as I gathered new information about them.
But it's wrong to judge a presidential candidate merely by their point of view on any single issue, including AI alignment.
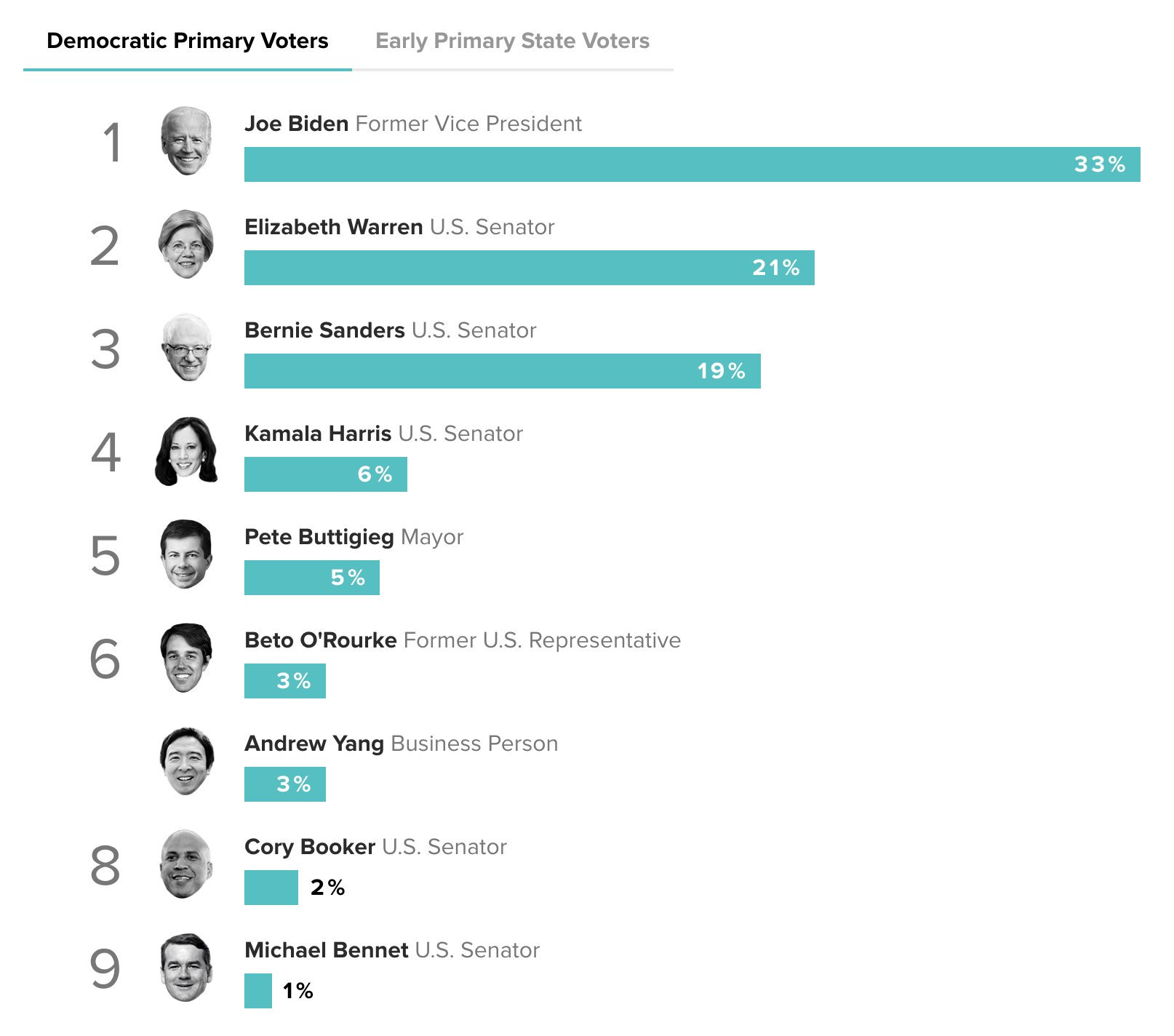
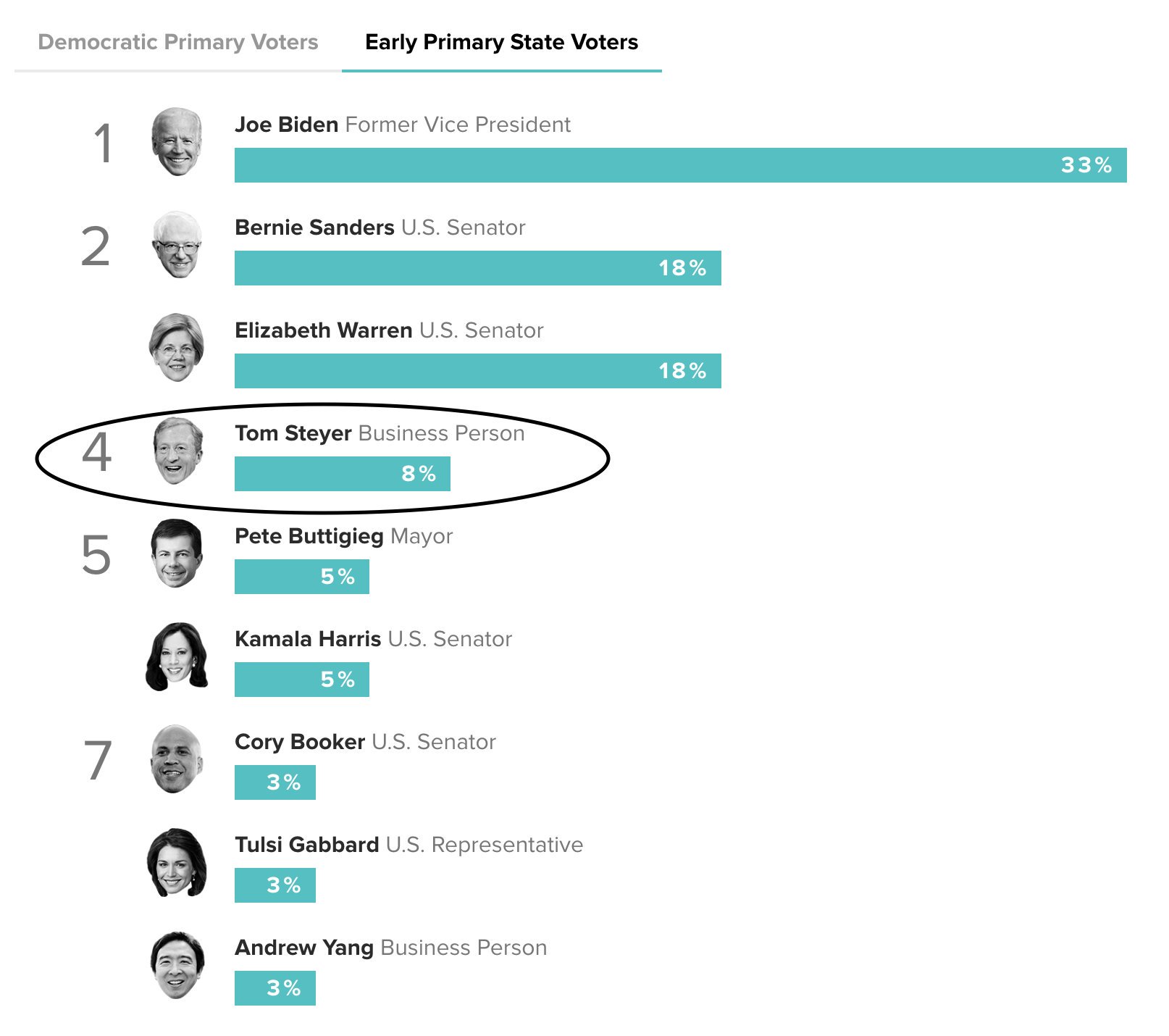



I think that we largely cannot give a president any actionable advice regarding AI alignment or policy, for the reasons outlined in Tom Kalil's interview with 80k. I wrote a post here with the relevant quotes. I can imagine this being good but mostly it's unclear to me and I think I can see a lot of ways for this to be strongly negative.
Are you saying that advocating for AI alignment would fail at this point?:
Yes. I think mostly nobody knows what to do, a few people have a few ideas, but nothing that the president can help with.
OpenPhil largely has not been able to spend 5% of its $10 billion dollars, more funding will not help. Nick Bostrom has no idea what policies to propose, he is still figuring out the basic concepts (unilateralist's curse, vulnerable world, etc). His one explicit policy paper doesn't even recommend a single policy - again, it's just figuring out the basic concepts. I recall hearing that the last US president tried to get lots of AI policy things happening but nothing occurred. Overall it's not clear to me that the president is able to do useful stuff in the absence of good ideas for what to do.
I think that the most likely strongly negative outcome is that AI safety becomes attached to some standard policy tug-o-war and mostly people learn to read it as a standard debate between republicans and democrats (re: the candidate discussed in the OP, their signature claim is automation of jobs is currently a major problem, which I'm not even sure is happening, and it'd sure be terrible if the x-risk perspective on AI safety and AI policy was primarily associated with that on a national or global scale).
There's a slightly different claim which I'm more open to arguments on, which is that if you run the executive branch you'll be able to make substantial preparations for policy later without making it a big talking point today, even if you don't really know what policy will be needed later. I imagine that CSET could be interested in having a president who shared a mood-affiliation with them on AI, and probably they have opinions about what can be done now to prepare, though I don't actually know what any of those things are or whether they're likely to make a big difference in the long-run. But if this is the claim, then I think you actually need to make the plan first before taking political action. Kalil's whole point is that 'caring about the same topic' will not carry you through - if you do not have concrete policies or projects, the executive branch isn't able to come up with those for you.
I think that someone in office who has a mood affiliation with AI and alignment and x-risk who thinks they 'need to do something' - especially if they promised that to a major funder - will be strongly net negative in most cases.
I don't think this is very likely (see my other comment) but also want to push back on the idea that this is "strongly negative".
Plenty of major policy progress has come from partisan efforts. Mobilizing a major political faction provides a lot of new support. This support is not limited to legislative measures, but also to small bureaucratic steps and efforts outside the government. When you have a majority, you can establish major policy; when you have a minority, you won't achieve that but still have a variety of tools at your disposal to make some progress. Even if the government doesn't play along, philanthropy can still continue doing major work (as we see with abortion and environmentalism, for instance).
A bipartisan idea is more agreeable, but also more likely to be ignored.
Holding everything equal, it seems wise to prefer being politically neutral, but it's not nearly clear enough to justify refraining from making policy pushes. Do we refrain from supporting candidates who endorse any other policy stance, out of fear that they will make it into something partisan? For instance, would you say this about Yang's stance to require second-person authorization for nuclear strikes?
It's an unusual view, and perhaps reflects people not wanting their personal environments to be sucked into political drama more than it reflects shrewd political calculation.
This is closer to what seems compelling to me.
Not so much "Oh man, Yang is ready to take immediate action on AI alignment!"
More "Huh, Yang is open to thinking about AI alignment being a thing. That seems good + different from other candidates."
This could be ameliorated by having the funder not extract any promises, and further by the funder being explicit that they're not interested in immediate action on the issue.
I'm not hearing any concrete plans for what the president can do, or why that position you quote is compelling to you.
To clarify again, I'm more compelled by Yang's openness to thinking about this sort of thing, rather than proposing any specific plan of action on it. I agree with you that specific action plans from the US executive would probably be premature here.
It's compelling because it's plausibly much better than alternatives.
[Edit: it'd be very strange if we end up preferring candidates who hadn't thought about AI at all to candidates who had thought some about AI but don't have specific plans for it.]
That doesn't seem that strange to me. It seems to mostly be a matter of timing.
Yes, eventually we'll be in an endgame where the great powers are making substantial choices about how powerful AI systems will be deployed. And at that point I want the relevant decision makers to have sophisticated views about AI risk and astronomical stakes.
But in the the decades before that final period, I probably prefer that governmental actors not really think about powerful AI at all because...
1. There's not much that those governmental actors can usefully do at this time.
2. The more discussion of powerful AI there is in the halls of government, the more likely someone is to take action.
Given that there's not much that can be usefully done, it's almost a tautology that any action taken is likely to be net-negative.
Additionally, there are specific reasons to to think that governmental action is likely to be more bad than good.
My overall crux here is point #1, above. If I thought that there were concrete helpful things that governments could do today, I might very well think that the benefits outweighed the risks that I outline above.
I think that's too speculative a line of thinking to use for judging candidates. Sure, being intelligent about AI alignment is a data point for good judgment more generally, but so is being intelligent about automation of the workforce, and being intelligent about healthcare, and being intelligent about immigration, and so on. Why should AI alignment in particular should be a litmus test for rational judgment? We may perceive a pattern with more explicitly rational people taking AI alignment seriously as patently anti-rational people dismiss it, but that's a unique feature of some elite liberal circles like those surrounding EA and the Bay Area; in the broader public sphere there are plenty of unexceptional people who are concerned about AI risk and plenty of exceptional people who aren't.
We can tell that Yang is open to stuff written by Bostrom and Scott Alexander, which is nice, but I don't think that's a unique feature of Rational people, I think it's shared by nearly everyone who isn't afflicted by one or two particular strands of tribalism - tribalism which seems to be more common in Berkeley or in academia than in the Beltway.
Totally agree that many data points should go into evaluating political candidates. I haven't taken a close look at your scoring system yet, but I'm glad you're doing that work and think more in that direction would be helpful.
For this thread, I've been holding the frame of "Yang might be a uniquely compelling candidate to longtermist donors (given that most of his policies seem basically okay and he's open to x-risk arguments)."
If you read it, go by the 7th version as I linked in another comment here - most recent release.
I'm going to update on a single link from now on, so I don't cause this confusion anymore.
moved comment to another spot.
The other thing is that in 20 years, we might want the president on the phone with very specific proposals. What are the odds they'll spend a weekend discussing AGI with Andrew Yang if Yang used to be president vs. if he didn't?
But as for what a president could actually do: create a treaty for countries to sign that ban research into AGI. Very few researchers are aiming for AGI anyway. Probably the best starting point would be to get the AI community on board with such a thing. It seems impossible today that consensus could be built about such a thing, but the presidency is a large pulpit. I'm not talking about making public speeches on topic; I mean inviting the most important AI researchers to the White House to chat with Stuart Russell and some other folks. There are so many details to work out that we could go back and forth on, but that's one possibility for something that would be a big deal if it could be made to work.
You only mean this as a possibility in the future, if there is any point where AGI is believed to be imminent, right?
Still, I think you are really overestimating the ability of the president to move the scientific community. For instance, we've had two presidents now who actively tried to counteract mainstream views on climate-change, and they haven't budged climate scientists at all. Of course, AI alignment is substantially more scientifically accepted and defensible than climate skepticism. But the point still stands.
They may not have budged climate scientists, but there other ways they may have influenced policy. Did they (or other partisans) alter the outcomes of Washington Initiative 1631 or 732? That seems hard to evaluate.
Yes, policy can be changed for sure. I was just referring to actually changing minds in the community, as he said - "Probably the best starting point would be to get the AI community on board with such a thing. It seems impossible today that consensus could be built about such a thing, but the presidency is a large pulpit."
I have updated in your direction.
Yep.
No I meant starting today. My impression is that coalition-building in Washington is tedious work. Scientists agreed to avoid gene editing in humans well before it was possible (I think). In part, that might have made it easier since the distantness of it meant fewer people were researching it to begin with. If AGI is a larger part of an established field, it seems much harder to build a consensus to stop doing it.
FWIW I don't think that would be a good move. I don't feel like fully arguing it now, but main points (1) sooner AGI development could well be better despite risk, (2) such restrictions are hard to reverse for a long time after the fact, as the story of human gene editing shows, (3) AGI research is hard to define - arguably, some people are doing it already.
Can you expand on this?
Making AI Alignment into a highly polarized partisan issue would be an obvious one.
I don't think that making alignment a partisan issue is a likely outcome. The president's actions would be executive guidance for a few agencies. This sort of thing often reflects partisan ideology, but doesn't cause it. And Yang hasn't been pushing AI risk as a strong campaign issue, he only acknowledged it modestly. If you think that AI risk could become a partisan battle, you might want to ask yourself why automation of labor - Yang's loudest talking point - has NOT become subject to partisan division (even though some people disagree with it).
My (relatively weak and mostly intuitive) sense is that automation of labor and surrounding legislation has become a pretty polarized issue on which rational analysis has become quite difficult, so I don't think this seems like a good counterexample.
By 'polarized partisan issue' do you merely mean that people have very different opinions and settle into different camps and make it hard for rational dialogue across the gap? That comes about naturally in the process of intellectual change, it has already happened with AI risk, and I'm not sure that a political push will worsen it (as the existing camps are not necessarily coequal with the political parties).
I was referring to the possibility that, for instance, Dems and the GOP take opposing party lines on the subject and fight over it. Which definitely isn't happening.
Right. Important to clarify that I'm more compelled by Yang's open-mindedness & mood affiliation than the particular plan of calling a lot of partisan attention to AI.