Comments
Thanks for this post! I'll be interested in data from CEA hiring overall, even with the obvious caveat that hiring across different roles will require different skillsets and experiences.
Thanks for this post! I'll be interested in data from CEA hiring overall, even with the obvious caveat that hiring across different roles will require different skillsets and experiences.
Thanks! In case you haven't already seen that: this post is part of a sequence about EA hiring; other posts have information about hiring different roles.
This was a great write up, interesting topic, informational and easy to follow.
One question I had is if below were the only words you were looking for in a CV and why so. For example, you did not list "Lead", which I'd think is frequently used for engineering roles.
I'm assuming either these were just examples (so not a complete list), or applicants only used these 2 terms?
Did any previous role include the word “senior” in its title?
Did any previous role include the word “manager” in its title?
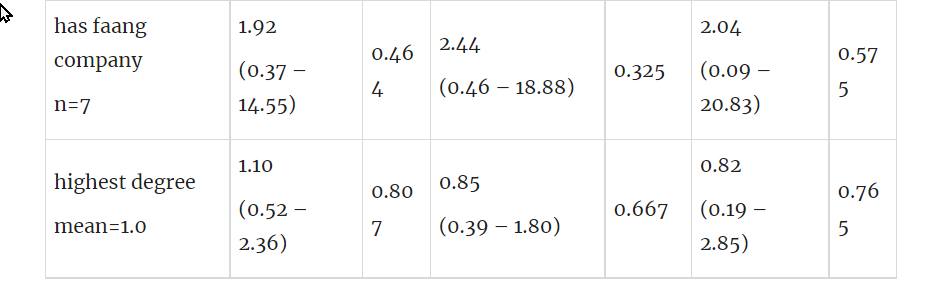
So uh you guys/girls have n=7 samples of people in this FAANG group, and you're using this to get coefficients for one of the regressions. Then for the next regression for the FAANG people making it a cut further, you probably only have 3 observations that regression?
So I think the norm here is to show "summary stats" style of data, e.g. a table that says "For the FAANG applicants, of these 7 made it). I think this table would be better.
Basically, a regression model doesn't add a lot, with this level of data.
Also, at this extremely low amount of data, I'm unsure, but there might be weird "degree of freedom" sort of things, where due to an interaction, the signs/magnitudes explode/implode.
Can you share your code for the regressions that made this table?
Basically, a regression model doesn't add a lot, with this level of data
Yes, I agree that this is the conclusion of the piece, but I feel like you are implying that this means the methodology was flawed?
We aren't trying to do some broad scientific analysis, we are just practically trying to identify ways that we can speed up our hiring process. And given that we do, in practice, have a relatively small number of people applying to each round, we are (apparently) not able to use automated methods to identify the most promising candidates with high accuracy.
(Maybe my stats/prob/econometrics is rusty, feel free to stomp this comment)
Yeah, you guys have a 94% pass rate for one dataset you use in one regression.

So you could only be getting any inference from the literally 3 people who failed for the screening interview.
So, like, in a logical, "Shannon information sense", that is all the info you have to go with, to get magnitudes and statistical power, for that particular regression. Right?
So how are you getting a whole column of coefficients for it?
No, "This model predicts whether all invited applicants (N=85) would pass the screening interview." So it's 45/85.
Yes, understood, thanks, I was just confused.
94% pass rate
Also, it does seem that, at least ex post, they might benefit from raising the bar a bit on this round.
Yeah, the point of the screening interview is mostly for the candidate to ask questions. I endorse the belief that we should be measuring programmers through programming tests instead of interviews (i.e. the pass rate of the screening interview should be very high), but I go back and forth on whether the screening interview should come first or second.
Yes, raising the bar would make the interviews more useful. This is a good thought that makes a lot of sense to me.
I think what you said makes sense and is logical.
Since I'm far away and uninformed, I think I'm more reluctant to say anything about the process and there could be other explanations.
For example, maybe Ben or his team wanted to meet with many applicants because he/they viewed them highly and cared about their EA activities beyond CEA, and this interview had a lot of value, like a sort of general 1on1.
The "vision" for the hiring process might be different. For example, maybe Ben's view was to pass anyone who met resume screening. For the interview, maybe he just wanted to use it to make candidates feel there was appropriate interest from CEA, before asking them to invest in a vigorous trial exercise.
Ben seems to think hard about issues of recruiting and exclusivity, and has used these two posts to express and show a lot of investment in making things fair.
- Whether candidates had worked in a company with more than 1000 employees - we excluded this in favour of looking at whether candidates had worked at a FAANG company; it was not possible to include both since the variables are not independent.
I'm confused, why can't you include two predictors if they are not independent? I'm assuming that with "independent" you mean correlation 0, if you instead mean no collinearity, i.e., linearly independent vectors of predictors, then feel free to ignore my comment.
Am I reading correctly that you made an offer to 8 developers and had 85 applicants?
So a 9% offer rate? That seems very high, am I missing something?
To highlight (from this comment and reply) the hire rate for this position was 3.5%

We examine what factors predicted advancement in our engineering hiring round. We show two trends which seem common in EA hiring[1]: first, candidates with substantial experience (including at prestigious employers) were often unsuccessful, and second, candidates with limited experience and/or limited formal education were sometimes successful.
We sometimes hear of people being hesitant to apply to jobs out of a fear that they are hard to get. This post gives quantitative evidence that people can receive EA job offers even if their seemingly more qualified peers are rejected (and, indeed, traditional qualifications are almost uncorrelated with getting an offer).
This builds on our previous post which found that participation in EA had limited ability to predict success in our hiring round.
There were 85 applicants for the role. The success rates for candidates in each stage are shown below. Some candidates voluntarily withdrew between the screening interview and trial task, hence there are fewer people taking part in the trial task than passed the interview.
| Stage | Number participating | Number passing | Success rate |
| Initial application sift | 85 | 48 | 57% |
| Screening interview | 48 | 45 | 94% |
| Trial task | 35 | 8 | 23% |
After the recruitment process was completed, we aggregated information about each applicant using the CVs and LinkedIn profiles they provided with their application. The metrics we were interested in were[2]:
This is not rigorous analysis; a “proper” model would include as many explanatory factors as possible, and the factors should be independent. This is reflected in the eventual predictive power of the models.
We fitted logistic regression models to the data; with the dependent variable being whether a candidate passed a given stage, and the independent variables being the factors listed above.
We then calculated modelled odds ratios and probabilities associated with each "predictor". The results of this are shown below, with a data table in the appendix.
This model predicts whether all submitted applicants (N=85) would pass an initial sift and be invited to the screening interview, with sensitivity 56% and specificity 76%.

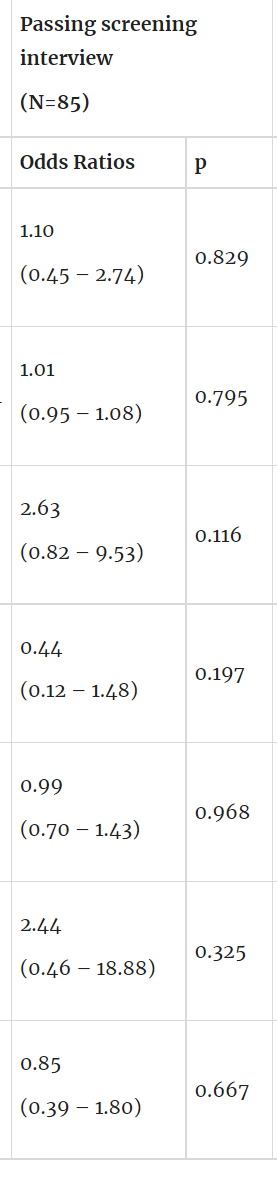
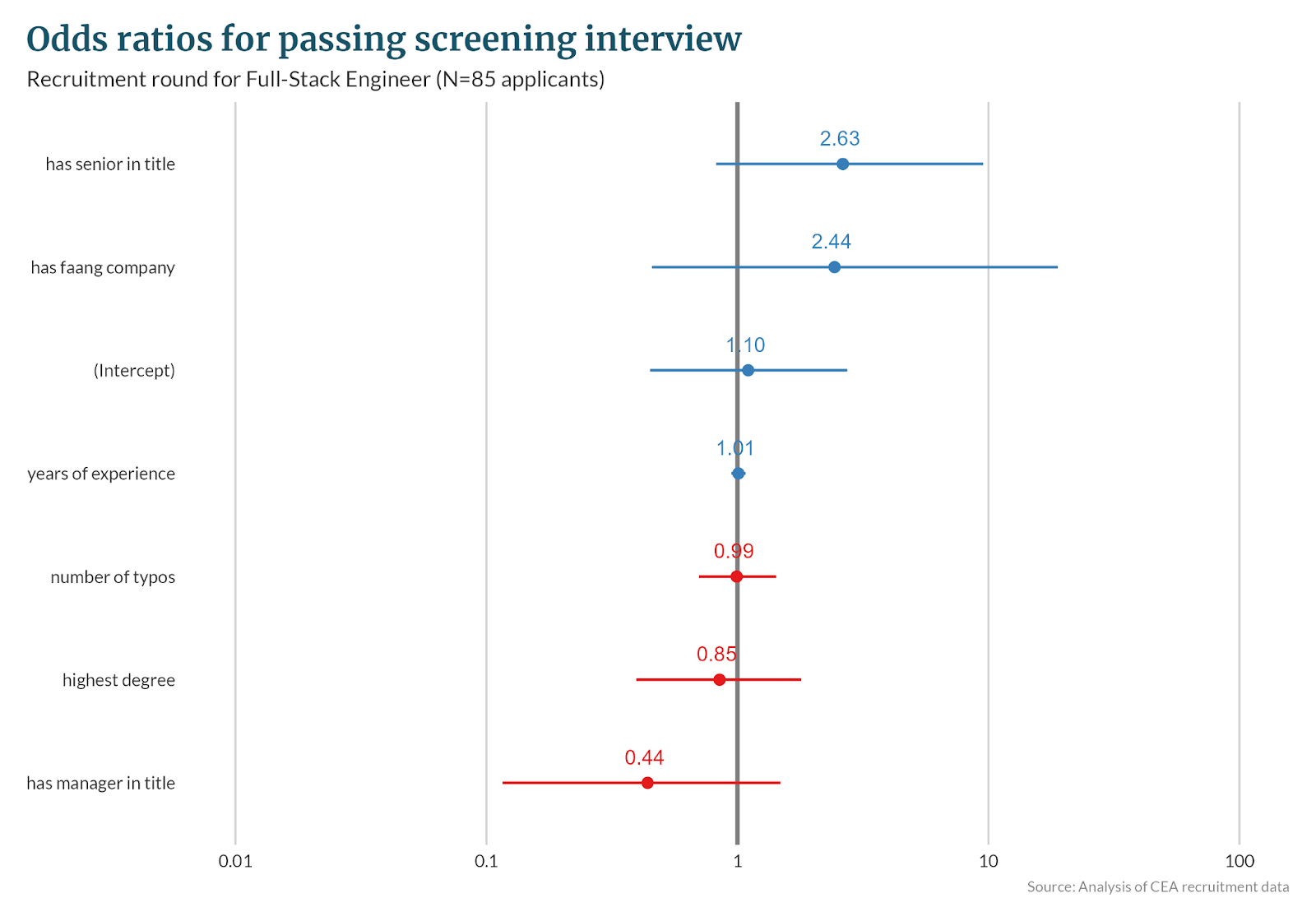
This model predicts whether all invited applicants (N=85) would pass the screening interview, with sensitivity 56% and specificity 70%.
This model predicts whether applicants who did not withdraw prior to this point (N=83) would pass the trial task, with sensitivity 88% and specificity 58%.

Discourse about EA hiring is sometimes simplified to "EA jobs are hard to get" (and therefore you shouldn't bother applying unless you are very qualified) or "there is a big talent gap" (and therefore everyone should apply).
This post gives evidence that “hard versus easy” isn’t really the right axis: it's hard to get a job (in the sense that well-qualified applicants were rejected) but also easy (in the sense that applicants with limited qualifications were accepted).
"When in doubt, just apply" continues to seem like good advice to me.
From the hiring manager’s perspective: This builds on our previous post which found that participation in EA had limited ability to predict success in our hiring rounds. Together, these posts make me pessimistic that simple automated screening criteria like “you need X years of experience” will be useful.
Passing initial sift (N=85) | Passing screening interview (N=85) | Passing trial task (N=75) | ||||
| Predictors | Odds Ratios | p | Odds Ratios | p | Odds Ratios | p |
| (Intercept) | 1.06 (0.43 – 2.63) | 0.893 | 1.10 (0.45 – 2.74) | 0.829 | 0.36 (0.08 – 1.29) | 0.135 |
years of experience mean=9.4 | 1.01 (0.95 – 1.08) | 0.781 | 1.01 (0.95 – 1.08) | 0.795 | 0.90 (0.74 – 1.03) | 0.181 |
has senior in title n=17 | 2.23 (0.70 – 7.99) | 0.189 | 2.63 (0.82 – 9.53) | 0.116 | 0.81 (0.04 – 7.19) | 0.860 |
has manager in title n=14 | 0.50 (0.14 – 1.67) | 0.263 | 0.44 (0.12 – 1.48) | 0.197 | 0.90 (0.04 – 7.09) | 0.925 |
number of typos mean=0.9 | 0.93 (0.66 – 1.31) | 0.648 | 0.99 (0.70 – 1.43) | 0.968 | 0.90 (0.41 – 1.50) | 0.738 |
has faang company n=7 | 1.92 (0.37 – 14.55) | 0.464 | 2.44 (0.46 – 18.88) | 0.325 | 2.04 (0.09 – 20.83) | 0.575 |
highest degree mean=1.0 | 1.10 (0.52 – 2.36) | 0.807 | 0.85 (0.39 – 1.80) | 0.667 | 0.82 (0.19 – 2.85) | 0.765 |
They seem common in the authors’ experience; we would appreciate feedback in the comments from other hiring managers about their own experience.
We collected other factors but ultimately chose to exclude them from the analysis:
- University rankings - we could not obtain these for enough candidates, which reduced the sample size considered and affected their accuracy.
- Likely salaries in the candidate’s previous position - we used online sources to estimate the typical salary for the candidate’s most recent position and company, but again could not obtain this for enough candidates.
- Whether candidates had worked in a company with more than 1000 employees - we excluded this in favour of looking at whether candidates had worked at a FAANG company; it was not possible to include both since the variables are not independent.

Assets aren't showing up:
Images should be fixed now, thanks for pointing this out.
Yep, images are broken. My guess is the document was copy-pasted from a Google Doc, with the images hosted in a way that isn't publicly accessible.