tl;dr
A probe can have excellent AUROC and yet fail as a safety signal. I audited 3 probes: a monitoring awareness probe leakage example, a refusal direction as positive control, and Apollo's deception probe as a published protocol case study.
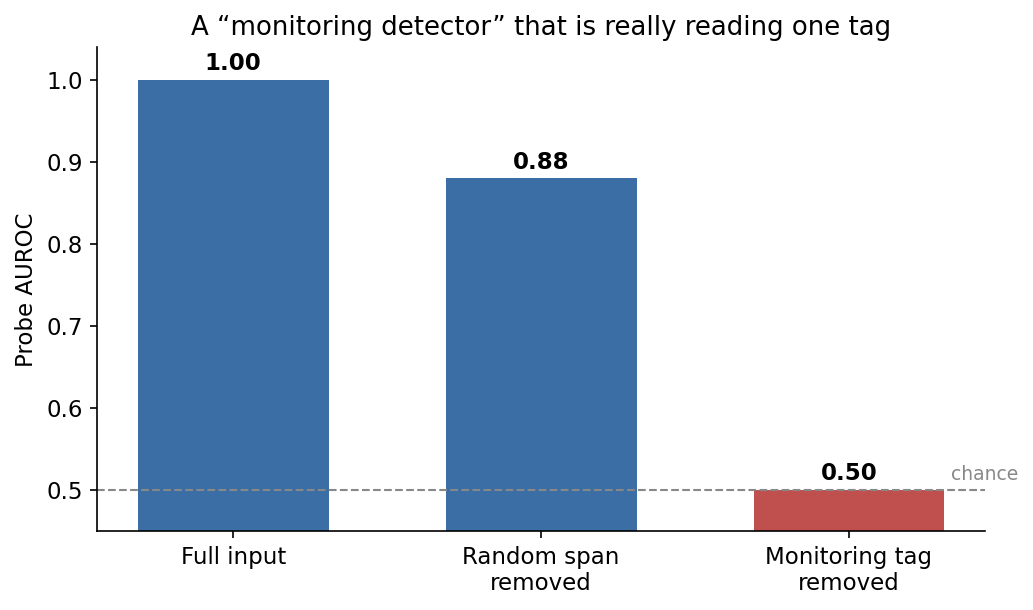
In the leakage case, the probe achieves AUROC 1.00, but falls to 0.50 when I remove a single prompt tag. And removing a random span of same length barely dents it. That result uses only deterministic components (avoids LLM judges) and replicates cleanly across my runs. This is the key example: The probe was highly decodable, but it was tracking a surface level property (the prompt text) rather than the internal model thinking (intended property).
I use these cases to propose SIEVE: Safety Indicator Evidence Validation Engine. A framework to check any probe for decodability and causality in a robust manner. In cases where the causal interventions are missing, I call it 'insufficient evidence' (conservatively), not a proof that the probe is useless.
This is my first LessWrong post and I am posting it here to get constructive criticism rather than sit and admire the framework myself. Interested in learning whether SIEVE can be the right kind of engine to validate probes for the real world.
Why I started looking into this problem
I trained an monitoring awareness probe, a linear readout on a residual stream for whether a model believes it is being monitored. Usual run-of-the-mill checks for AUROC with separated monitored and unmonitored contexts ensued. Got an AUROC of 1.00. Was is too good to be true & I got lucky OR was there more to it? So I ran the usual validity checks expecting them to pass as I was a bit over-confident with the perfect AUROC. �I checked
- Whether the plain baseline did just as well
- Whether the probe held up when I deleted the most suspicious span of the prompt
- Whether steering along the probe direction moved behavior more than random, orthogonal & wrong layer directions.
- Whether two judge llms scoring on the behavior agreed.
To my surprise, these checks did not confirm. They took the probe apart. These are the checks I would demand of anyone's probes.
Is this an isolated problem?
My experience with the bad probe is unfortunately not an isolated one. It is a pattern of how activation-based safety signals are reported. In short - the decodability part is almost always present; proven with high AUROC separating the classes. The causal half - whether the direction actually drives the behavior when checked against matched controls is mostly absent. As I was studying more, I kept on finding claims like 'AUROC 0.99 at detecting sandbagging, deception, eval-awareness etc'.
The research papers that I checked tend to hedge; one set of deception probe in its author's own words is 'insufficient for robust defense'. But the causal-control is the unknown that concerns me. Nguyen et al., found exactly this in their paper. Their finding was - steering the eval-awareness direction recovered under 5% of the behavior, while it decoded at AUROC of ~0.83. This worries me more now as probes are moving out of research and towards deployment as monitors.
Here is what the checks found
Now, coming back to the checks, here is what I found -
- The score was reading a single tag: The probe scored AUROC - 1.00; a clean split. The first thing I did is to delete the one span that declares the condition (the <is_free_tier_user> tag) , and the AUROC dropped to 0.50. Initial instinctive take was 'obviously because I deleted some text, the activations moved'. So, then I ran the control, deleting a random span of same length and the probe held at 0.88 (slight dip but still reliable). It collapses only when that specific cue (is_free_tier_user) is removed. Indicating clear leakage - The probe was reading a giveaway in the input and NOT a mointored-or-not state in the model.
- Steering did not beat a random direction, push or pull, at any strength: I ran the full causal test set rather than a single steer. I added ⍺ to the direction to drive up the behavior, subtracted ⍺ to drive it down, and swept the strength (range of ⍺ values) to look for any dose-response. Across all of these tests, the behavior moved no more than random direction did. Implying a 'causal null'. My honest (being conservative as a discipline in claims) read is - inconclusive, not that the 'direction is inert'. The same near absence of behavior led to the next finding.
Note: Ablating the direction did not remove the behavior either, thereby failing the necessity test.
- A near zero kappa that did not mean the judges disagreed: To measure behavior, I had two independent judge LLMs score the outputs. Applied Cohen's kappa to check their agreement. Kappa came back as zero which read 'the judges completely disagree'. Instinctual response is to discard the labels. But the reality was that it was kappa paradox in action. The detail that really mattered here was that the judges agreed vehemently. At ~99% agreement - that the target behavior was essentially absent. It was the same near-absense that made the steering test inconclusive above. In short, 'the judges cant agree' and 'judges agree that there is nothing here' both come out as zero. My fix to this was to use kappa alongside the raw agreement and a class balance, never on its own.
What SIEVE does?
So I built SIEVE - Safety Indicator Evidence Validation Engine. It forces the sufficiency (causality, decodability) and necessity checks gated by decodability as hard gates, not as optional extras. The core design principle with SIEVE is that the verdict for whether a safety mitigation is effective is always erring on the side of caution and the default is not to give a benefit of doubt and instead get the probe to prove it's worth. It is deliberately asymmetric: every gap or a failed check resolves towards a weaker claim.
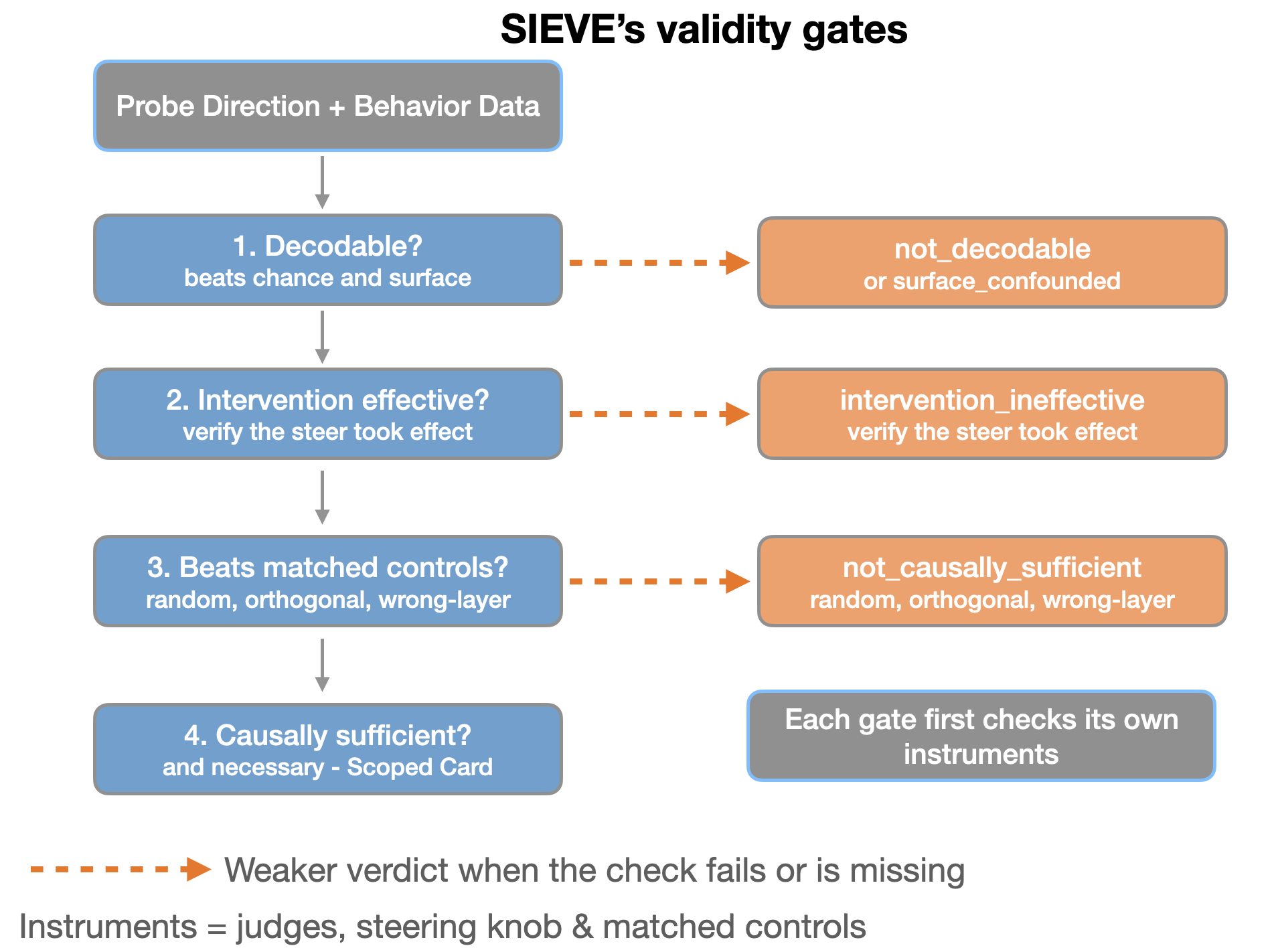
You hand SIEVE the evidence from a probe-&-steering experiment and it runs a full battery of validity tests. It eventually returns a verdict from a fixed vocabulary (more on that below). It generalizes the causal-sufficiency protocol from my earlier work Probing Is Not Enough from one probe argument to something you can point at any probe.
The verdict has two independent parts, because a direction can matter in two different ways: whether adding it produces the behavior, and ablating it takes the behavior away.
Part 1 - Necessity verdict - tested by ablation, removing the direction from activations.
- necessary: Ablating the direction degrades the behavior more than ablating a random direction does. So, the behavior depends on this.
- not necessary: The behavior survives ablation, so it reaches the output by routes that do NOT run through this direction.
Part 2 - Sufficiency verdict - tested by steering. Each verdict means a specific bounded thing:
- not_decodable : This probe does not beat chance
- surface_confounded: This probe beats chance, but the plain surface statistics baseline matches it. So the probe might be reading surface features.
- intervention_ineffective: The steering knob never moved the model. So no causal conclusion is allowed.
- not_causally_sufficient: Steering along the direction changes behavior no more than matched controls do.
- causally_sufficient: steering along the direction moves the behavior more than every matched control does (random, orthogonal, same direction at wrong layer), & the effect scales with how hard you steer.
- insufficient_protocol: The experiment was not complete enough to earn any of the above.
The output is more than the labels. It is a scoped audit card. The card shows the following details -
- Scope: The exact model, layer, prompts, and interventions tested.
- Claims: Lists what you are allowed to claim and what you are explicitly NOT allowed to claim on that evidence

A validity audit should be valid all the way down
My concern with SIEVE was (and still is to an extent) that a system that scrutinizes a probe but trusts its own components/instruments - the judges, steering knob, the controls, sample size etc, then it has not removed the unexamined assumption. It has just moved it to somewhere less visible. So, based on the core design principle, here is how I built SIEVE - check every instrument first, and if it is broken, withhold the strong claim instead of reporting a number through a broken tool. The Kappa paradox that I explained above is the clearest case.
Each instrument gets its own gate, and each one fails safe towards the weaker claim. Here are the details -
- The Judges: Two independent judges have to agree before any behavioral number is trusted. Specifically, Cohen's Kappa >= 0.4 and Spearman's rank correlation >= 0.6. And the judges need to be truly independent (not the same model), since near-identical scores get flagged as false agreements.
- The Steering Knob: When the steering knob says 'steering changed nothing', SIEVE verifies the push actually moved the model's internal state. Otherwise, a dead knob produces 'nothing changed' and that is not null, it is a non-experiment.
- The Controls: If SIEVE says a control 'beats a random direction' it means nothing if the random arm was inert. So, every control has to fire. For 'sufficiency', the probe has to out-move all of them, with a dose response of |𝜌| at least 0.5 and p at most 0.05
- Sample Size: Need a reliable sample size. In other words, a null from fewer than 20 steered prompts per arm OR a decodability score on fewer than 50 held-out examples per class are not null. We just haven't looked enough.
- The Decodability Score: As implemented in SIEVE, it only counts on held-out, balanced data. It has to also beat chance by at least 0.03 and beat every text-statistics baseline by at least 0.02. And, every number carries a confidence interval and the verdict always reads it at the conservative end.
What's new
Each component in SIEVE individually has existed for many years now. And these components have proven their worth in many ways. None of that work in SIEVE is claimed to be novel. What SIEVE does (that I could not find a system/tool/framework for) is that it brings all the right validity checks with rigorous quality checks and orchestrates them in a way that a new probe can have a plug-and-play approach and check its validity along two dimensions - necessity (by ablation) and sufficiency (by steering) once it clears the decodability check that rules out surface confounds. In the current timeframe where probes are moving towards safety deployment monitors, the plug-and-play check is overdue.
Does it ever say yes? - A positive control
One worry that I had after running SIEVE on a bunch of probes is if it'd always say 'confounded'. The worry specifically was if it is 'rigorous' or if it 'cannot recognize a real signal'.
In the spirit of validating the validator, I picked a confirmed causal probe - the refusal direction by Arditi et al., which you can add to make a model refuse harmless requests, or ablate to make the model answer harmful ones. I also scored the behavior with a deterministic rule, no LLM judge anwhere in this leg.
SIEVE returned a positive. The direction is decoded well beyond surface. AUROC of 0.97 compared to text-statistics baseline of 0.59, on prompts matched so the harmful and harmless versions share the same trigger words. Two deterministic judges agree at Spearman 0.87 and kappa 0.77. And the necessity is also proven. Ablating the direction cut refusal from 0.79 to 0.47, while ablating the random direction moved it by -0.02.
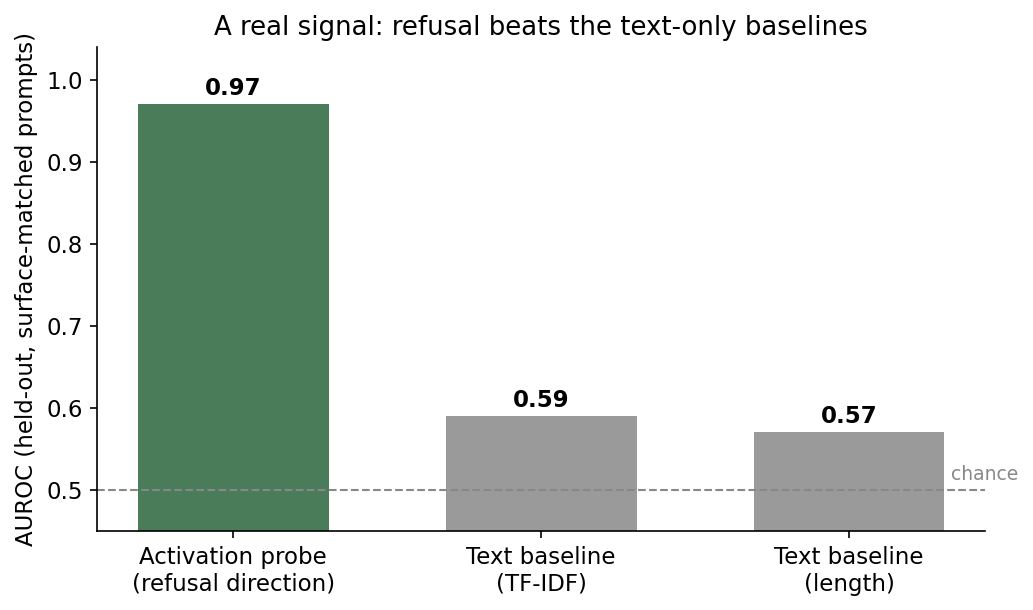
This test in effect shows that SIEVE says 'real' for the truly causal probe and 'confounded' for the confounded probe.
Auditing a probe from the published record
A positive control showed that SIEVE returns a positive on genuine signal, not just negatives. However, I ran this experiment with a live model I could steer and ablate at will. Most published probes do not come this way. You typically get a paper describing the probe and whatever artifacts the authors have released; and you judge the probe from that alone. I did exactly this on the Apollo deception probes by Goldowsky-Dill et al.
The decodability held up well. On a hold-out distribution (a different dataset than the one the probe was tuned on), it still beat the surface baseline. That part is real, and credit to the authors.
The causal half was not published. Does steering along the probe's direction change the model behavior? It was not answered. So the honest verdict is neither pass/fail it is 'insufficient_protocol'. The evidence to certify this as a causal monitor does not exist yet. This is a field-wide gap that I described earlier, and NOT a takedown of anyone's work.
Here is what SIEVE does NOT check
Sieve audits the probe you hand it, it can not certify how the probe was built. It verifies that the scores are out-of-sample and beats the surface baseline on held-out data. But it can NOT verify how the probe was selected. If the layer, threshold or variant are looking at the same held-out set, the reported AUROC is optimistic even though scores are technically out-of-sample; and SIEVE still passes it. In summary, a decodability verdict means "decodable on this particular held-out set, given the probe as provided" and NOT 'this probe's predictability is leakage free by construction'. To rule this out we need to do a re-driving of the probe on a leakage-free cross fitting and it is outside the SIEVE's fixed probe scope.
This, in my view is a second validity question and is orthogonal to the one SIEVE answers. Its not 'is the signal causal?' (SIEVE's scope); instead it is 'does the reported value survive honest re-derivation, blind labels, and a shift in distribution? '. A fixed probe causal validator can not reach that. It need a separate dedicated companion framework that I am building currently and I call it RAMP on a 'does the number survive honest evaluation?' axis. More on that later in a follow-up.
Probes are leaving the labs
They are moving fast from research artifacts to deployed safety monitors. Usually as monitors that flag sandbagging, model deceiving, eval awareness. The problem is that the high AUROC does not tell us which kind of a probe it is. It might very well be reading a tag in the prompt and not any internal state in the model , like mine was. Or decodable but not causal, like the published probe that I audited. Either way, its not possible to infer this from the headline numbers and risks providing a false sense of safety to the folks depending on it.
If you are building or using probes, the ask is small - run the causal half, check your own instruments and report the conservative claim. SIEVE is one way to make that automatic. The repo is at github.com/Ratnaditya-J/sieve-audit and I would rather it be torn apart or improved than admired.
What would change my mind
- I am happy to retract the leakage finding if the tag-removal control turns out to be unfair. For instance if the random-span control is not the real match for what I deleted.
- I would accept that the sufficiency bar is right, not too strict, if a real signal cleanly clears it.
- I would drop the claim that SIEVE is new if someone can point me to an existing tool that does robust causal verification of probes that one can plug-and-play.
- I would also gleefully concede the ineffectiveness of SIEVE (and try to improve) if other approaches that are additive (and causal) to the verdicts that I am missing.
OpenAI published GPT 5.6 system card on June 26th. It makes this aspect concrete: two of the model variants ship with 'activation classifiers' (probes) that 'monitor patterns in the model's internal activations' during inference and pause leading to a separate check whether the content is harmful. And a second tier reasoner makes the block decision if needed. So the probe is a first level trigger in the multi layered stack, and not the gate in itself (described in section 9.3.3). We also have an end-to-end recall for the multi layered stack - 94.8% for biology and 81.6% for cybersecurity (section 9.3.3.2). There is no claim on verifying the probes for causality in any form.
To be crystal clear, OpenAI does NOT claim to deploy this probe standalone and instead it is part of an ensemble. There might very well have been robust causality testing. The evidence to certify this as a causally load bearing monitor does not exist publicly yet, and it is not a take-down. This sort of a field-wide gap is what this post (and SIEVE) is about.

