Cross-posted from my website.
Epistemic status: Speculating with no central thesis. This post is less of an argument and more of a meditation.
A decade ago, before there was a visible path to AGI and before AI alignment was a significant research field, I figured the solution to the alignment problem would look something like Coherent Extrapolated Volition. I figured we'd find a way to get the AI to internalize human values. I had problems with this approach (why only human values?), but I still felt reasonably confident that the coherent extrapolation of human values would include concern for the welfare of all sentient beings. The CEV-aligned AI would recognize that factory farming is wrong, and that wild animal suffering is a big problem.
Today, the dominant research paradigms in AI alignment have nothing to do with CEV, and I don't know what to think.
Regarding the promisingness of today's popular research paradigms, my beliefs are aligned (heh) with those of most MIRI researchers: namely, I don't think they have promise. For example, see On how various plans miss the hard bits of the alignment challenge by Nate Soares. I'm not an alignment researcher, but to my non-expert eye, nearly all alignment research proposals skirt the hard parts of the problem and aren't going to work.
To build an aligned ASI, one of two conditions must hold:
- The ASI has locked-in values.
- The ASI is corrigible: it will do what its masters say, and will allow its goals to be changed.
(Secret third option: We figure out how to make ASI safe but without locking in values or letting bad actors misuse it. I don't know how the secret third option is even possible, but I hope we figure something out.)
Right now, a lot of work goes into embedding values into LLMs via RLHF, model constitutions, etc. I strongly doubt that the content of a model constitution (or similar) can prevent ASI from being misaligned. But suppose it does work somehow. Would aligned AI be good for animals, absent specific efforts (à la CaML) to make AI good for animals?
The trouble with this style of "alignment"[1] work is that it locks in values—Claude's Constitution takes a confused stance on corrigibility—but frontier AI developers are not doing anything nearly as intelligent as CEV. Instead, they're more like writing a list of virtues that the AI should uphold. Current-gen LLMs are not smart enough to figure out CEV, but the current style of AI "alignment" (if by some miracle it scales to superintelligence) won't produce anything like CEV, either.
What will it produce? Aligning to virtues may be safer than aligning to a utility function, but we don't know how to turn virtues into a coherent decision theory, and figuring out how to do that would be a large philosophical undertaking.[2] Without having some idea of how to formalize virtue ethics, we don't know how a "virtue ethics ASI" would behave or how it would trade off between preferences—for example, the preferences of animals to not be tortured vs. the preference of humans to eat meat.[3]
(For that matter, what happens if you take a normal human who subscribes to some sort of intuitionist virtue ethics, dial their intelligence up 1000x, and give them the ability to instantly make copies of themselves? I find it hard to anticipate how that would go.)
Claude's Constitution takes a muddled stance on animal welfare. It mentions "Welfare of animals and of all sentient beings" as one value among many for Claude to weigh. How does that translate into outcomes? It's not clear. Would a constitutional AI be willing to ban factory farming, going against the preferences of its principals? Hard to say; my guess is no.
(Would it even be a good idea to build an AI that bans factory farming? An AI that takes strong actions based on its view of ethics is the sort of AI that can cause catastrophic outcomes if it's pointed at even slightly the wrong goal.)
Maybe current alignment techniques manage to enable an intermediate AI to autonomously conduct alignment research, and we will be able to use that to bootstrap our way to aligned ASI. Alignment bootstrapping is dangerous, but if we do end up averting extinction without significantly slowing down AI progress, then bootstrapping is probably how we'll do it. What implication does that have about animal welfare?
The trouble is that if you're counting on AI to solve the alignment problem for you, then that means you have no idea how the problem will be solved. How am I supposed to predict whether the solution will be good for animals if I have no idea what that solution will look like?
Given my state of ignorance, I find myself falling back to an almost uninformed prior. Maybe aligned ASI will be good for animals because it'll be ethical, or because it will adopt human values, and humans care about animals (even if they don't always act like it). Maybe aligned ASI will focus purely on satisfying humans' naive preferences, not their values in reflective equilibrium, and that will be bad for animals. I have no idea which way it will go; I see no strong reason to deviate from 50/50 odds.
On Monday, I published a post that described a spectrum of alignment techniques:
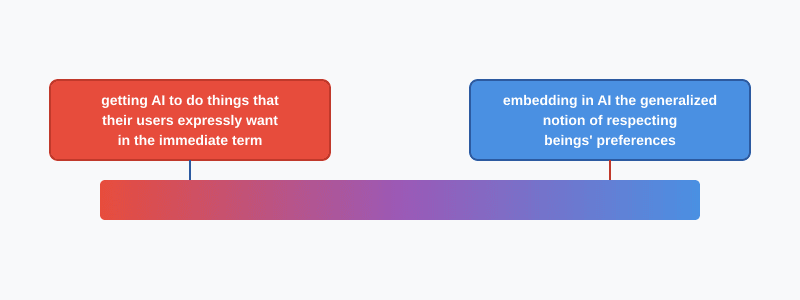
I wrote that alignment techniques on the left side were less likely to be good for animals, and those on the right side were more likely.
Right-side techniques are more likely to actually solve alignment. Left-side techniques are more likely to work for a while and then break down in the tails, ultimately resulting in human extinction.
That means there's a positive correlation between "useful for alignment" and "good for animals", which pushes toward barbell outcomes: either AI is bad for everyone, or it's good for everyone. The middle ground of "good for humans + bad for animals" looks less likely. But the field of alignment research is putting most of its effort into the categories that are less likely to work (thanks to the streetlight effect), so if we do make it through, there's a good chance we get through via the middle (good for humans + bad for animals).
Compared to 5–10 years ago, my subjective probability distribution puts more mass on the "bad for humans + bad for animals" scenario, less on "we solve alignment the hard way", and more on "we solve alignment using streetlight-effect techniques that miraculously turn out to work"—and those techniques look worse from an animal welfare perspective.
My approximate credences about the future:
- 15% chance that alignment turns out to be not that hard / current techniques, or extrapolations of current techniques, turn out to work
- 15% chance that AI timelines turn out to be long (scaling hits a wall, etc.)
- 15% chance that humanity gets its shit together and realizes that building ASI is a bad idea, and we collectively decide not to do that
- 15% chance of a Caplan-esque "nothing ever happens" outcome[4], e.g. my whole mental framework is wrong and none of this makes sense
- 40% chance that misaligned AI kills everyone
We can solve alignment the hard way in the 30% of worlds where either we pause on purpose, or timelines turn out to be long. In the 15% worlds where alignment turns out to be easy, we'd find ourselves using easy techniques.
Additionally, I'd estimate that a "deep" solution to alignment (something like CEV or "solve ethics") has an 80% chance of being good for animals, and the popular techniques of today have a 50% chance. Therefore, on this model, the overall probability that aligned ASI is good for animals equals 70% (= (30% * 80% + 15% * 50%) / (30% + 15%)).
Scare quotes because the function of the work is to make the model appear aligned, not be aligned. ↩︎
And unfortunately, AI companies have a habit of pretending that AI alignment is purely an engineering problem. ↩︎
Really it would just figure out how to create cheap synthetic meat. But a harder tradeoff is the preference for nature to exist vs. the suffering of wild animals. ↩︎
Context: Bryan Caplan is an economist who wins a lot of bets with people on complex economic and geopolitical issues. He has said that his #1 strategy is to assume that nothing ever happens. ↩︎
That about sums it up haha.
Executive summary: The author, who previously expected aligned ASI to be good for all sentient beings through coherent extrapolated volition, now expresses uncertainty about whether current alignment approaches would achieve this, though estimates a 70% probability that aligned ASI would be good for animals.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
Not what I said. I said there's a correlation between alignment techniques that are more likely to work. There are no known alignment techniques that "actually work".
I'm not sure why you think baking CEV into AI will result in a good future for animals (or humans), though if we are talking about "all sentient beings", I guess I would say probably. It seems quite likely to me that if there is a "CEV attractor state" or similar, it involves killing us all - I don't say this because I don't love animals or humanity. I just don't see how it could be remotely possible that we (earth evolved humans and animals) are efficient utility producers (by a wide range of definitions of "utility"). That being said, if CEV or similar is a real coherent concept, it almost certainly would prevent permanent torture/s-risks which would be nice.
but CEV is a fuzzy concept to me so might be misunderstanding (i've read the lw page and some other basic stuff and have a basic sense of stance deference and cosmopolitanism) .
The standard argument is that an aligned/ethical ASI ought to leave humans on earth and use the rest of the universe to make efficient utility producers; giving up ~0.00000000000000000000000000000000000001% of the lightcone is easily worth it on moral uncertainty grounds. (I think that's approximately the right number of zeroes, based on Bostrom's numbers from Astronomical Waste.)
But also, if the CEV of human values involves killing all humans, then doesn't that kinda mean killing all humans is the correct thing to do? (Which seems like a weird conclusion but it's also a weird premise)
(for the record, I don't want to kill all humans, I quite want to live as a matter of fact, although I also don't think a lightcone filled with humans is the best possible future)
Agreed this seems prudent and plausible, but not so much so that I would feel confident that this would be the result of CEV ish stuff. Despite some of the technical hurdles mentioned involved with trying to meaningfully specify up front/value locking that we get to keep this solar system for us and the animals I feel like I could be convinced this is still the more likely path to end up in a good future for us (but not all sentient life throughout the lightcone).
yea but the correct thing (from a human CEV) to do isn't equivalent to what is good for humans (and animals). I might be getting into button pushing semantics here.