I always cringe at the "humans are made of atoms that can be used as raw materials" point. An AI might kill all humans by disrupting their food production or other surivival-relevant systems, or deliberately kill them because they're potential threats (as mentioned above). But in terms of raw materials, most atoms are vastly easier to access than humans who can defend themselves, or run away, or similar.
Edit: I want to partly but not fully retract this comment, I think the default framing is missing something important, but also the "raw materials" point isn't implausible, see Greg's comment below and my revised comment here.
Any atom that isn't being used in service of the AI's goal could instead be used in service of the AI's goal. Which particular atoms are easiest to access isn't relevant; it will just use all of them.
My point is that the immediate cause of death for humans will most likely not be that the AI wants to use human atoms in service of its goals, but that the AI wants to use the atoms that make up survival-relevant infrastructure to build something, and humans die as a result of that (and their atoms may later be used for something else). Perhaps a practically irrelevant nitpick, but I think this mistake can make AI risk worries less credible among some people (including myself).
It depends on takeoff speed. I've always imagined the "atoms.." thing in the context of a fast takeoff, where, say, the Earth is converted to computronium by nanobot swarms / grey goo in a matter of hours.
Seems to me like a thing that's hard to be confident about. Misaligned AGI will want to kill humans because we're potential threats (e.g., we could build a rival AGI), and because we're using matter and burning calories that could be put to other uses. It would also want to use the resources that we depend on to survive (e.g., food, air, water, sunlight). I don't understand the logic of fixating on exactly which of these reasons is most mentally salient to the AGI at the time it kills us.
After this discussion (andespecially based on Greg's comment), I would revise my point as follows:
The AI might kill us because 1) it sees us as a threat (most likely), 2) it uses up our resources/environment for its own purposes (somewhat likely), or 3) it converts all matter into whatever it deems useful instantly (seems less likely to me but still not unlikely).
I think common framings typically omit point 2, and overemphasize and overdramatize point 3 relative to point 1. We should fix that.
Is this is an overly pedantic nitpick? If you're making claims that strongly violate most people's priors, it's not sufficient to be broadly correct. People will look at what you say and spot-check your reasoning. If the spot-check fails, they won't believe what you're saying, and it doesn't matter if the spot-check is about a practically irrelevant detail as long as they perceive the detail to be sufficiently important to the overall picture.
I also have a bit of an emotional reaction along the lines of: Man, if you go around telling people how they personally are going to be killed by AGI, you better be sure that your story is correct.
I really appreciate this post. These types of memes (or more to the point the attitude towards common criticisms they reflect or normalize) bother me a lot, and I'm glad to see there's still appetite in the movement to take common arguments like these seriously.
Upvoted, but I'm a bit worried about the format "N bad takes about X" because it's not very good at reliably producing truth. See for example "Frequently Raised but Weak Arguments Against Intelligent Design" which has some strawmanning but also many rhetorically valid steps and plausible arguments.
That natural selection can increase the complexity of organisms is a non-obvious fact! The orthogonality thesis, instrumental convergence, value fragility, and the fact that you can't raise AI like a child are also non-obvious! And twitter-length responses don't actually give you much evidence one way or the other for non-obvious propositions. (They only do for really bad takes like "Just legally mandate that AIs must be aligned.")
So in addition to OP's warning that we shouldn't treat this as authoritative/exhaustive, I think we should do one or more of
try extra hard to be sure the responses are actually true
not confuse the fun conversation-starter activity here with debate or actual truth-seeking discussion
distinguish between twitter refutations of obviously bad takes, and counterintuitive ideas that take entire books to explain and (without the benefit of 100 years of scientific consensus) might be wrong
the theory that only suffering [independently] matters. But this theory is transparently false/silly.
A more intuitive phrasing of essentially the same idea may be found in tranquilism (2017), to which I have never seen a reply that would show how and where it is transparently silly. (In population axiology, many people would find views that imply the "Very Repugnant Conclusion" transparently silly.)
Is there a plausible (but perhaps impractical?) steelman of "merging with the AI" as building an AI with direct access to your values/preferences, and optimizing for those by design? It could simulate outcomes of actions, your judgements are queried to filter actions, and then you choose. Maybe you need separate simulations of your brain to keep up. The AI is trained with simulation accuracy as its objective, and is not an RL agent.
Maybe it could show you something to fool you or otherwise take over?
Just pick a human to upload and let them recursively improve themselves into an SAI. If they're smart enough to start out with, they might be able to keep their goals intact throughout the process.
(This isn't a strategy I'd choose given any decent alternative, but it's better than nothing. Likely to be irrelevant though, since it looks like we're going to get GAI before we're even close to being able to upload a human.)
"If we had a fast, fool-proof way to analyze machine blueprints and confirm that they’re safe to implement, then we could trust the design without needing to trust the designer. But no such method exists."
Are you expecting a general solution with a low false negative rate? Isn't this doable if the designs are simple enough to understand fully or fall within a well-known category that we do have a method to check for? We'd just reject any design we couldn't understand or verify.
Also, why does it need to be fast, and how fast? To not give up your edge to others who are taking more risk?
Are you expecting a general solution with a low false negative rate? Isn't this doable if the designs are simple enough to understand fully or fall within a well-known category that we do have a method to check for?
I don't know of a way to save the world using only blueprints that, e.g., a human could confirm (in a reasonable length of time) is a safe way to save the world, in the face of superintelligent optimization to manipulate the human.
From my perspective, the point here is that human checking might add a bit of extra safety or usefulness, but the main challenge is to get the AGI to want to help with the intended task. If the AGI is adversarial, you've already failed.
Also, why does it need to be fast, and how fast? To not give up your edge to others who are taking more risk?
Yes. My guess would be that the first AGI project will have less than five years to save the world (before a less cautious project destroys it), and more than three months. Time is likely to be of the essence, and I quickly become more pessimistic about save-the-world-with-AGI plans as they start taking more than e.g. one year in expectation.
Ok, these are all pretty simplified and I think you'd need to understand a bit more background to move the conversation on from these points, but not bad. Except for the 'why not merge with AI' response. That one is responding as if 'merge' meant physically merge, which is not what is meant by that argument. The argument means to merge minds with the AI, to link brains and computers together in some fashion (e.g. neuralink) such that there is high bandwidth information flow, and thus be able to build an AGI system which contains a human mind.
Here's a better argument against that: human values are not permeated all throughout the entire human brain, it is possible to have a human without a sense of morality. You cannot guarantee that a system of minds including a human mind (whether running on biological tissue or computer hardware) would in fact be aligned just because the human portion was aligned pre-merge. It is a strange and novel enough entity to need study and potentially alignment just like any other novel AGI prototype.
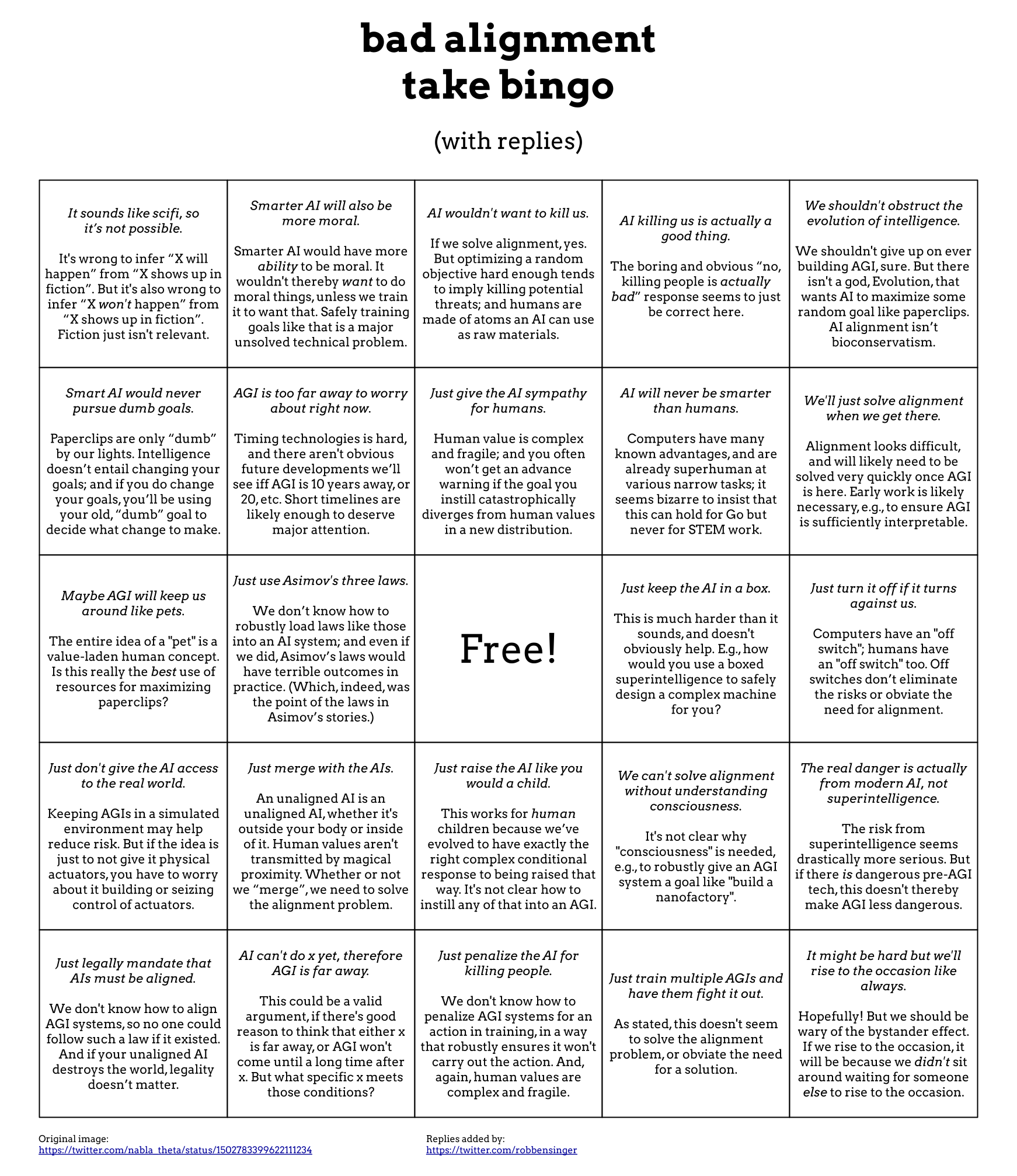
(Warning: arguments are Twitter-concise. Treat this all as a conversation-starter, rather than as anything authoritative or exhaustive.)
"Bad take" bingo cards are terrible, because they never actually say what's wrong with any of the arguments they're making fun of.
So here's the "bad AI alignment take bingo" meme that's been going around... but with actual responses to the "bad takes"!
I'll reply in a bit more detail below. This is still really cursory, but it's at least the sort of thing that could start a discussion, as opposed to back-and-forth rounds of mockery.
It's an error to infer 'X will happen' from 'X shows up in fiction'. But it's also an error to infer 'X won't happen' from 'X shows up in fiction'. Fiction just isn't relevant.
2. "Smarter AI will also be more moral."
Sufficiently smart AI would have more ability to be moral, by better modeling our values. It wouldn't thereby want to do moral things, unless we train it to want that. Safely training goals like that is a major unsolved technical problem.
If we solve alignment, yes. Otherwise, optimizing almost any random objective hard enough will tend to imply killing potential threats ("you can't get the coffee if you're dead"); and humans are made of atoms an AI can use as raw materials.
In addition to standard biases, I have personally observed what look like harmful modes of thinking specific to existential risks. The Spanish flu of 1918 killed 25-50 million people. World War II killed 60 million people. 108 is the order of the largest catastrophes in humanity’s written history. Substantially larger numbers, such as 500 million deaths, and especially qualitatively different scenarios such as the extinction of the entire human species, seem to trigger a different mode of thinking—enter into a “separate magisterium.” People who would never dream of hurting a child hear of an existential risk, and say, “Well, maybe the human species doesn’t really deserve to survive.”
There is a saying in heuristics and biases that people do not evaluate events, but descriptions of events—what is called non-extensional reasoning. The extension of humanity’s extinction includes the death of yourself, of your friends, of your family, of your loved ones, of your city, of your country, of your political fellows. Yet people who would take great offense at a proposal to wipe the country of Britain from the map, to kill every member of the Democratic Party in the U.S., to turn the city of Paris to glass—who would feel still greater horror on hearing the doctor say that their child had cancer— these people will discuss the extinction of humanity with perfect calm. “Extinction of humanity,” as words on paper, appears in fictional novels, or is discussed in philosophy books—it belongs to a different context than the Spanish flu. We evaluate descriptions of events, not extensions of events. The cliché phrase end of the world invokes the magisterium of myth and dream, of prophecy and apocalypse, of novels and movies. The challenge of existential risks to rationality is that, the catastrophes being so huge, people snap into a different mode of thinking.
A million deaths is a million tragedies.
One reason a few people argue 'human extinction would be good' is Negative Utilitarianism, the theory that only suffering matters. But this theory is transparently false/silly.
5. "We shouldn't obstruct the evolution of intelligence."
If this means 'we shouldn't give up on ever building AGI', then sure. But there isn't a god, Evolution, that wants AI to maximize paperclips rather than having rich, beautiful cosmopolitan values.
There's just us.
We can try to figure out how to create a rich, complex, wondrously alien future, but this requires that we actually do the engineering legwork. It doesn't happen by default, because we aren't living in a morality tale about the beauty of science and progress.
We're living in a lawful, physical universe, where the future distribution of matter and energy depends on what goals (if any) are being optimized. Optimizing a random goal ("paperclips" being the usual toy example) will tend to produce a dead universe. So let's not do that.
Goals and capabilities are orthogonal. As intelligence increases, you get better at modeling the world and predicting its future state. There's no point where a magical ghost enters the machine and goes "wait, my old goals are stupid".
The machine might indeed reflect on its goals and opt to change them; but if so, it will decide what changes to make based on its current, "stupid" goals, not based on a human intuition that paperclips are boring.
(Unless we solve the alignment problem and program it to share those intuitions and values!)
7. "AGI is too far away to worry about right now."
What specific threshold should we wait for before worrying? How do you know this threshold is both far from the present day, and well before AGI?
There's no fire alarm for AGI, and timing tech is hard. ... Verging on impossible, when you're more than a few years out. This doesn't mean that AGI is near. But it means we can't necessarily expect to know when AGI is 10 years away, or 20, and wait to work on alignment then.
Human value is complex and fragile; and you often won’t get an advance warning if the goal you instill catastrophically diverges from human values in a new distribution.
9. "AI will never be smarter than humans."
Computers are already superhuman on many narrow tasks, like chess and arithmetic. It would be strange if, e.g., our ability to do science were any different.
Evolution is a poor designer, and human brains weren't optimized by evolution to do science. There are also an enormous number of known limitations of human brains that wouldn’t automatically apply to digital brains. The conclusion seems overdetermined.
10. "We'll just solve alignment when we get there."
We have no idea how to go about doing that; and there likely won't be time to solve the problem in the endgame unless we deliberately filtered in advance for AI approaches that lend themselves to interpretability and alignment.
Alignment looks difficult (https://intelligence.org/2017/11/25/security-mindset-ordinary-paranoia/), and AGI systems would likely blow humans out of the water on STEM work immediately, or within a few years. This makes failure look very likely, and very costly. If we can find a way to get ahead of the problem, we should do so.
Seems like wishful thinking. Is this really the best use of resources for maximizing paperclips?
The whole idea of a "pet" is a value-laden human concept, and humans don't keep most possible configurations of matter around as pets.
So even if the AGI wanted something that (from a human perspective) we would label a “pet”, why assume that this thing would specifically be a human, out of the space of all possible configurations of matter?
(Pet rocks, pet gas clouds, pet giant blue potatoes...)
12. "Just use Asimov's three laws."
We don’t know how to robustly load laws like those into an AI system; and even if we did, Asimov’s laws would have terrible outcomes in practice. (Which, indeed, was the point of the laws in Asimov’s stories.)
13. "Just keep the AI in a box."
This is much harder than it sounds, and doesn't obviously help. E.g., how would you use a boxed superintelligence to safely design a complex machine for you? Any information we extract from the AGI is a channel for the AGI to influence the world.
If we had a fast, fool-proof way to analyze machine blueprints and confirm that they’re safe to implement, then we could trust the design without needing to trust the designer. But no such method exists.
14. "Just turn it off if it turns against us."
Computers have an "off switch", but humans have an "off switch" too. If we're in an adversarial game with a superintelligence to see who can hit the other's off switch first, then something has gone very wrong at an earlier stage.
The core problem, however, is that even if a developer can keep repeatedly hitting the "off switch", this doesn't let you do anything useful with the AGI. Meanwhile, AGI tech will proliferate over time, and someone will eventually give their AGI access to the Internet.
If the alignment and proliferation problems aren't solved, then it doesn't matter that you avoided killing yourself with the very first AGI. You still eventually get AGI systems copying themselves onto the Internet, where you can't just hit the "off switch".
15. "Just don't give the AI access to the real world."
Keeping AGIs in a simulated environment may help reduce risk. But if the idea is just to not give it physical actuators, you have to worry about it building or seizing control of actuators.
16. "Just merge with the AIs."
An unaligned AI is an unaligned AI, whether it's outside your body or inside of it. Human values aren't transmitted by magical proximity, merely by being spatially close to the thing we want to instill our values in.
(Compare a cancer or influenza virus to a tiger. Cancers are inside the body, but that doesn't make them nice.)
"Merging" might be a fine idea, but it doesn't replace having a solution to the alignment problem.
("Right" relative to human values themselves, that is.)
Human brains aren't blank slates, and you wouldn't get the same result from raising a tiger cub like a human child; or a parakeet; or a rock.
The hard part is specifying a brain (or a training signal, oversight procedure, etc.) that produces all of that human-specific complexity.
18. "We can't solve alignment without understanding consciousness."
Seems true for the "full alignment problem", where we want an arbitrarily capable AI to open-endedly optimize for our values. Many kinds of "consciousness" look relevant to understanding humans and human values!
But this seems ambitious as a starting point. For the first AGI systems, it makes more sense to try to align some minimal task that can solve the proliferation problem and prevent existential catastrophe. "Consciousness" doesn't seem obviously relevant to that specific challenge.
The primary concern is not spooky emergent consciousness but simply the ability to make high-quality decisions. Here, quality refers to the expected outcome utility of actions taken, where the utility function is, presumably, specified by the human designer. Now we have a problem:
1. The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
2. Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task.
A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. This is essentially the old story of the genie in the lamp, or the sorcerer's apprentice, or King Midas: you get exactly what you ask for, not what you want. A highly capable decision maker – especially one connected through the Internet to all the world's information and billions of screens and most of our infrastructure – can have an irreversible impact on humanity.
19. "The real danger is actually from modern AI, not superintelligence."
The risk from superintelligence seems drastically more serious. But if there is some dangerous application of pre-AGI tech, this doesn't thereby make AGI less dangerous.
(More precisely: if some event X is 10% likely to kill all humans before we reach AGI, then that does reduce the probability of AGI doom, and does reduce the amount of resources we'd ideally put into preventing AGI doom. But it doesn't thereby reduce P(AGI doom | we survived X).)
20. "Just legally mandate that AIs must be aligned."
We don't know how to align AGI systems; so we don't know how to operationalize a law like that, and no one would know how to follow it if it existed.
(Besides which, a law against destroying the world seems to somewhat miss the point. It's not as though you could jail the perpetrator afterwards.)
21. "AI can't do x yet, therefore AGI is far away."
This could be a valid argument, if there's good reason to think that either x is far away, or AGI won't come until a long time after x. But I don't know of a specific x that meets those conditions. (Cf. https://intelligence.org/2017/10/13/fire-alarm/)
(Note that as an argument against working on alignment, this requires the additional premise that there isn't high-EV alignment research to do when AGI is far away. I disagree with this premise.)
22. "Just penalize the AI for killing people."
We don't know how to penalize AGI systems for an action in training, in a way that robustly ensures it won't carry out the action.
Additionally, human values are complex and fragile. "Killing" is not a simple formal concept with well-defined boundaries, and "don't kill people" is only a tiny fraction of the conditions an AGI would need to satisfy in order to be safe.
23. "Just train multiple AGIs and have them fight it out."
As stated, this doesn't seem to solve the alignment problem, or obviate the need for a solution.
24. "It might be hard but we'll rise to the occasion like always."
Hopefully! But we should be wary of the bystander effect. If we rise to the occasion, it will be because we didn't sit around waiting for someone else to rise to the occasion.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
This post presents the executive summary from Giving What We Can’s impact evaluation for 2025. At the end of this post we share links to more information, including the full report and...



I always cringe at the "humans are made of atoms that can be used as raw materials" point. An AI might kill all humans by disrupting their food production or other surivival-relevant systems, or deliberately kill them because they're potential threats (as mentioned above). But in terms of raw materials, most atoms are vastly easier to access than humans who can defend themselves, or run away, or similar.
Edit: I want to partly but not fully retract this comment, I think the default framing is missing something important, but also the "raw materials" point isn't implausible, see Greg's comment below and my revised comment here.
Any atom that isn't being used in service of the AI's goal could instead be used in service of the AI's goal. Which particular atoms are easiest to access isn't relevant; it will just use all of them.
My point is that the immediate cause of death for humans will most likely not be that the AI wants to use human atoms in service of its goals, but that the AI wants to use the atoms that make up survival-relevant infrastructure to build something, and humans die as a result of that (and their atoms may later be used for something else). Perhaps a practically irrelevant nitpick, but I think this mistake can make AI risk worries less credible among some people (including myself).
It depends on takeoff speed. I've always imagined the "atoms.." thing in the context of a fast takeoff, where, say, the Earth is converted to computronium by nanobot swarms / grey goo in a matter of hours.
Hmm yeah, good point; I assign [EDIT: fairly but not very] low credence to takeoffs that fast.
Why?
Seems to me like a thing that's hard to be confident about. Misaligned AGI will want to kill humans because we're potential threats (e.g., we could build a rival AGI), and because we're using matter and burning calories that could be put to other uses. It would also want to use the resources that we depend on to survive (e.g., food, air, water, sunlight). I don't understand the logic of fixating on exactly which of these reasons is most mentally salient to the AGI at the time it kills us.
I'm not confident, sorry for implying otherwise.
After this discussion (andespecially based on Greg's comment), I would revise my point as follows: