Something you hear a lot in discussions is that it's important not to strawman arguments: to assume they are much weaker than they are. This is uncharitable.
Instead, the suggestion is you should steelman arguments: consider the strongest version of it, even if that's not what the person has said, and then evaluate that. Steelmanning is thought of as getting the principle of charity just right.
However, I suspect there should be a third category, call it mithrilman: where arguments are treated as much stronger than they are, and you accept them even though you don't understand the reasons. For the non-nerds out there, mithril is Tolkien's fictional super-strong metal in Lord of the Rings.
Whilst strawmanning is being too uncharitable, mithrilmanning is being too charitable. You don't want to do either. Goldilocks lies inbetwixt the two.
I see mithrilmanning quite a lot among effective altruists. Usually, it goes something like this. People are discussing a view or argument they've heard person X make. The individuals are sitting around, brows furrowed, and struggling to find a good steelman of the argument: they can't work out what plausible reasons that person could have for their conclusion. After a while, even though they can't find a suitable steelman, someone says "Well, X does seem really smart, so...". Everyone nods. The conversation moves on.
What's happened is that someone has suggested the group should defer, even though they can't follow the reasoning or provide it themselves. This seems to happen much more often when person X is important (not least because you don't want to risk looking stupid).
I think there can be good cases where one should defer, but I'm worried I see too much of this. We should give people the benefit of the doubt - assume they are smart, thoughtful, etc. rather than fools - but we should still doubt. To err is human. We all make mistakes. We make progress by pointing those out.
So, if you think someone is really smart, but you can't make sense of what they are thinking, at least hesitate on deferring to them. If possible, ask them to explain. It seems too charitable to assume they are right, not charitable enough to assume they are wrong. In assuming that they can give you a sensible answer, you are treating them with appropriate charity.
I don't think I need to say why strawmanning is bad. The danger of mithrilmanning is you end up with too much deference, an information cascade and ultimately false beliefs. People end up believing what X says, even though no one really understands why.
So, if you find yourself overhearing, or even saying yourself, "well, they do seem really smart..." consider adding "um, are we mithrilmanning this? We don't want to defer uncritically."
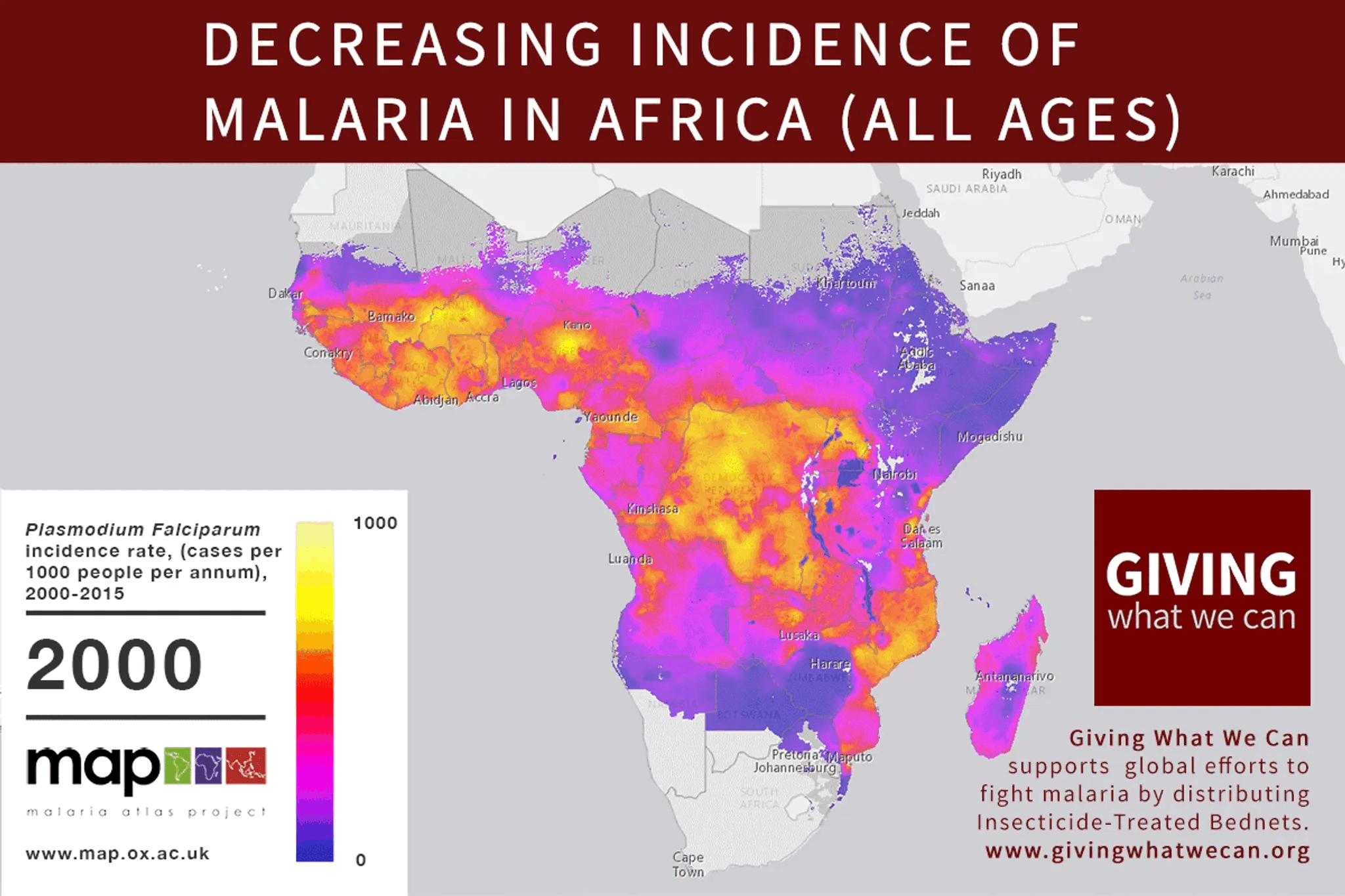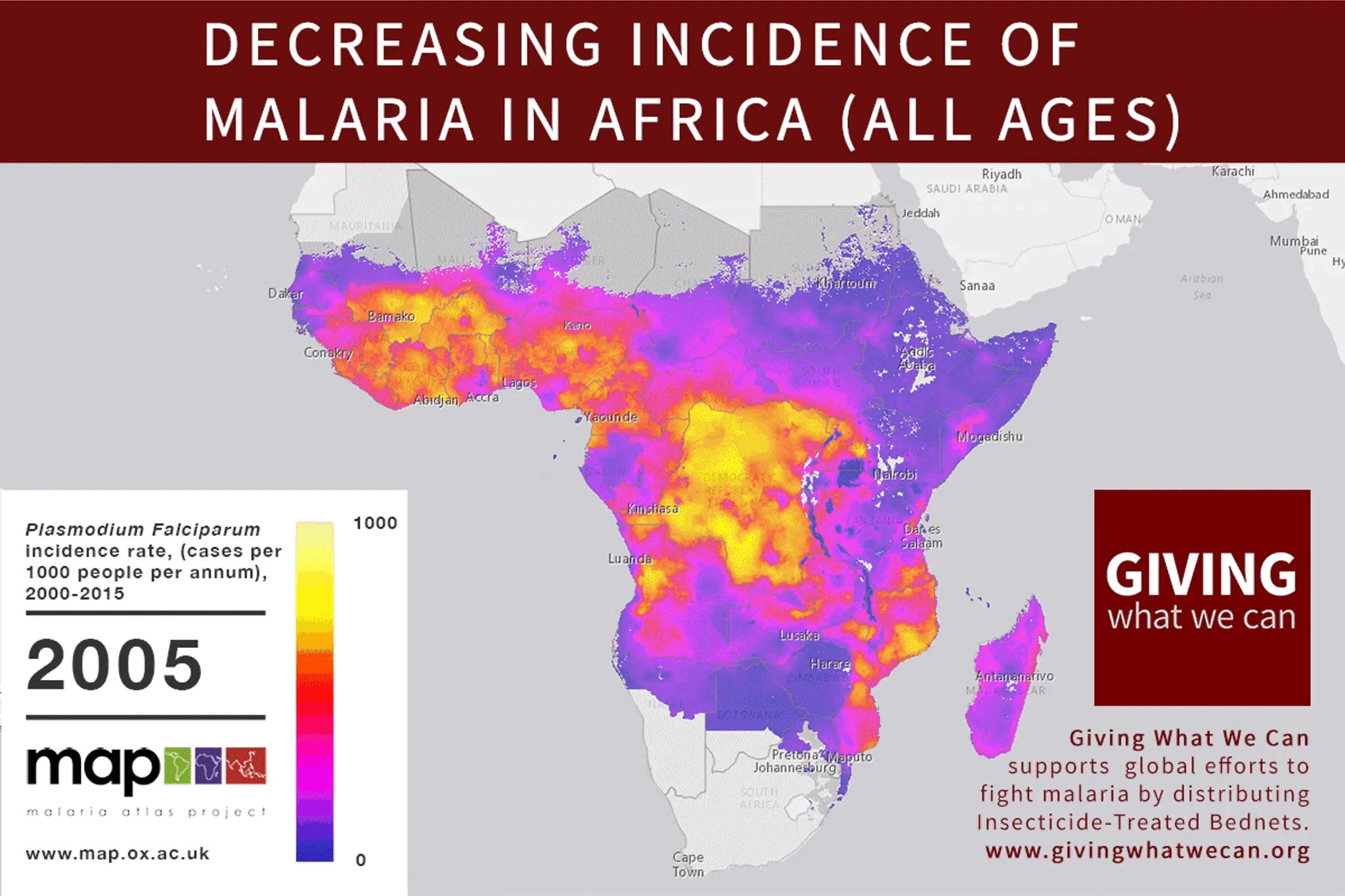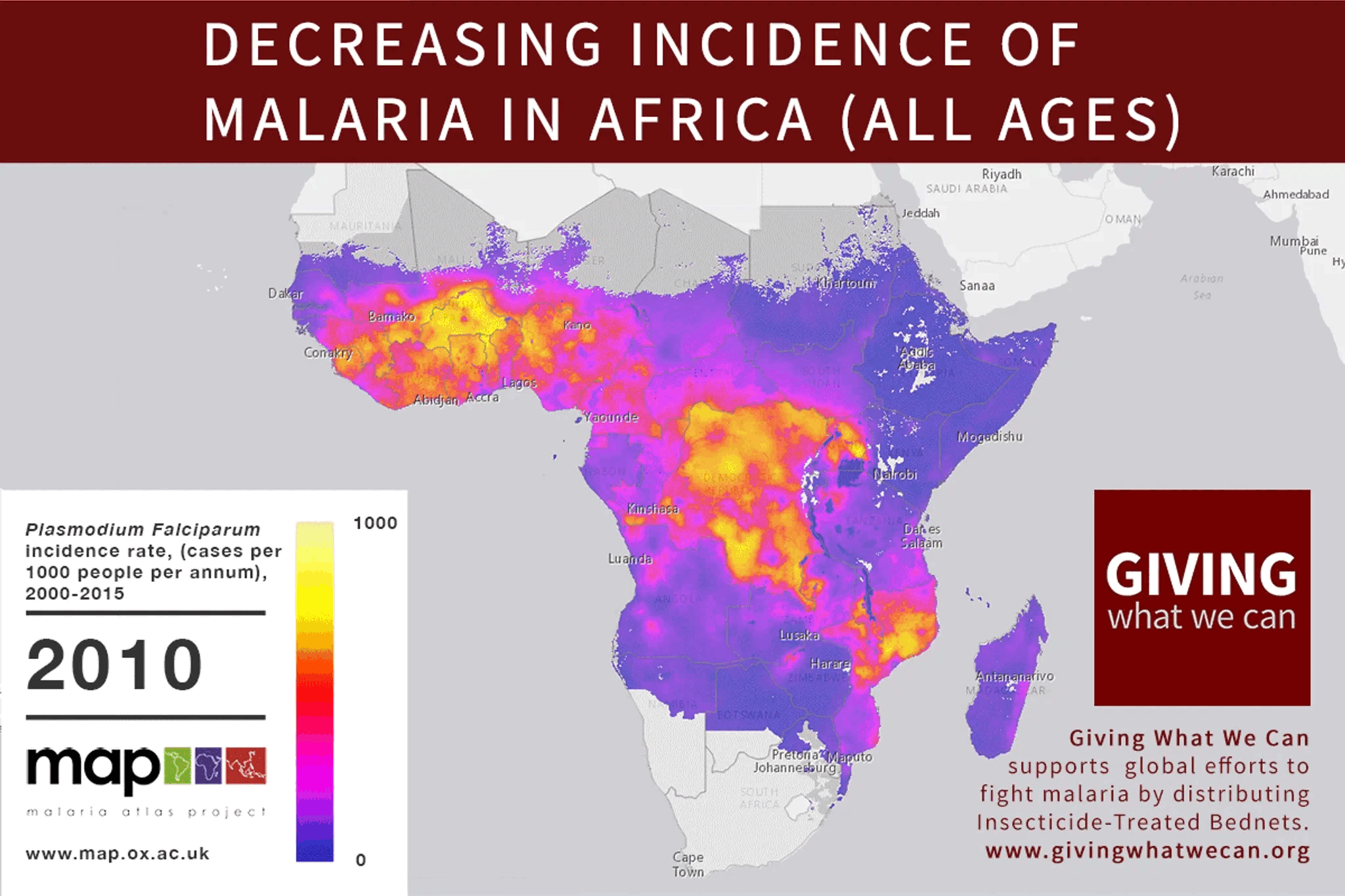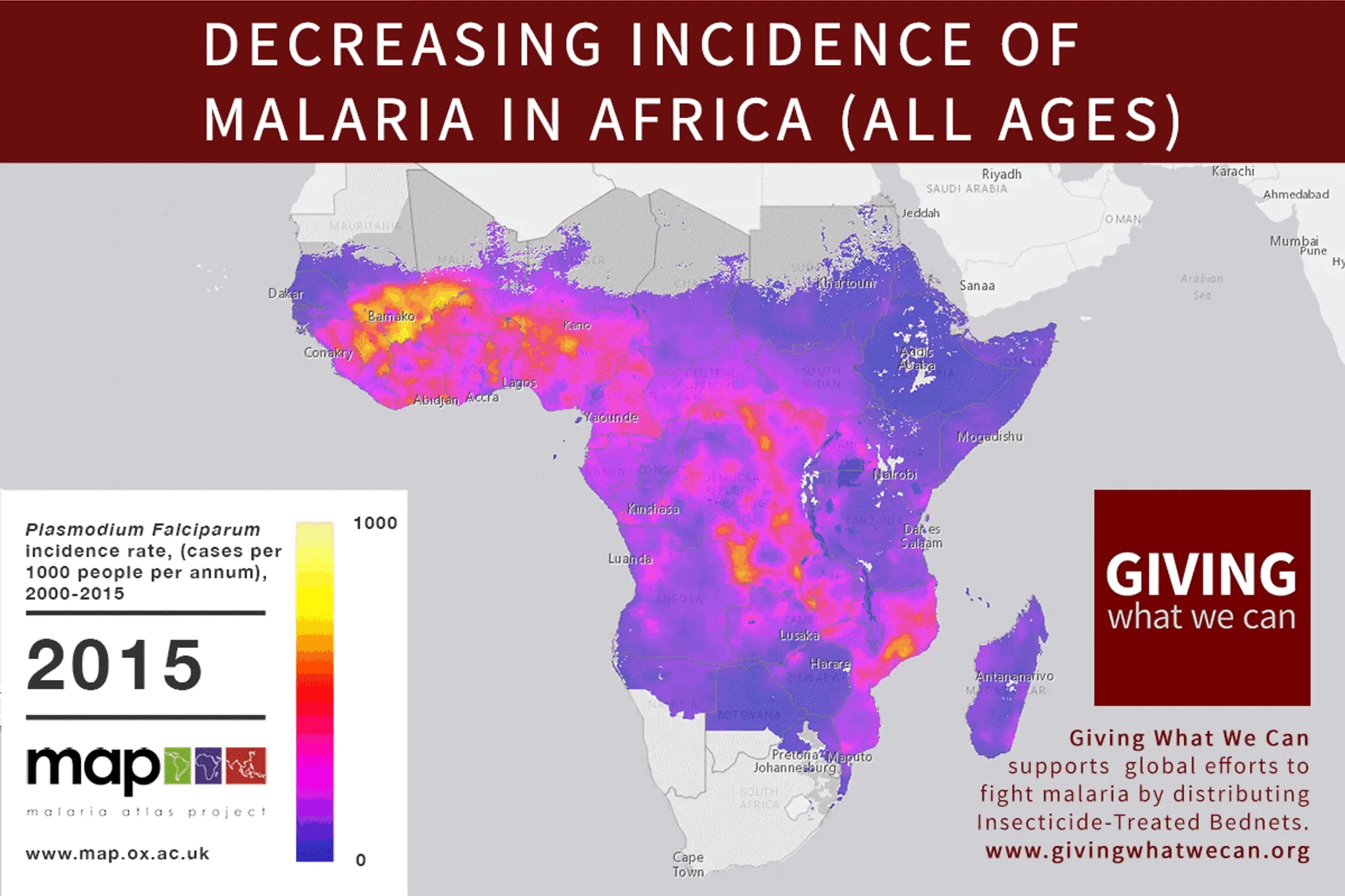

The problem with strawmanning and steelmanning isn't a matter of degree, and I don't think goldilocks can be found in that dimension at all. If you find yourself asking "how charitable should I be in my interpretation?" I think you've already made a mistake.
Instead, I'd like to propose a fourth category. Let's call it.. uhh.. the "blindman"! ^^
The blindman interpretation is to forget you're talking to a person, stop caring about whether they're correct, and just try your best to extract anything usefwl from what they're saying.[1] If your inner monologue goes "I agree/disagree with that for reasons XYZ," that mindset is great for debating or if you're trying to teach, but it's a distraction if you're purely aiming to learn. If I say "1+1=3" right now, it has no effect wrt what you learn from the rest of this comment, so do your best to forget I said it.
For example, when I skimmed the post "agentic mess", I learned something I thought was exceptionally important, even though I didn't actually read enough to understand what they believe. It was the framing of the question that got me thinking in ways I hadn't before, so I gave them a strong upvote because that's my policy for posts that cause me to learn something I deem important--however that learning comes about.
Likewise, when I scrolled through a different post, I found a single sentence[2] that made me realise something I thought was profound. I actually disagree with the main thesis of the post, but my policy is insensitive to such trivial matters, so I gave it a strong upvote. I don't really care what they think or what I agree with, what I care about is learning something.
"What they believe is tangential to how the patterns behave in your own models, and all that matters is finding patterns that work."
From a comment on reading to understand vs reading to defer/argue/teach.
"The Waluigi Effect: After you train an LLM to satisfy a desirable property P, then it's easier to elicit the chatbot into satisfying the exact opposite of property P."
You might enjoy the book 'Thanks for the Feedback', which basically emphasises this point a lot.