TLDR: The Harvard AI Safety Team (HAIST) is a new research-focused student group aimed at encouraging Harvard undergrads to pursue careers in technical AI safety. We think the club has been successful, and that other groups may have success following a similar format. We are also currently looking for AIS researchers to advise 1-3 person research projects in the fall (compensated); please email me if you’d like to help with this, or if you have any other advice for HAIST.
Three months ago, I helped start the Harvard AI Safety Team (HAIST), a student group aimed at encouraging Harvard undergraduates to pursue careers in technical AI safety. Currently, the team has 15+ active members, nearly all of whom are seriously considering careers in AI safety. I think the club has been successful, and I want other colleges to start similar groups. The following document describes HAIST’s motivation and approach, how we started HAIST, and our plans for the fall.
Motivation
We think that preventing catastrophic accidents from artificial general intelligence may be one of the most important problems of our time. We also think that there are open opportunities for many more researchers to make progress on it, and that technical undergraduates are particularly well suited to begin careers in AI safety.
Although there are existing outreach efforts at Harvard oriented around effective altruism and avoiding existential risk, we think there are specific benefits to outreach and community aimed at AI safety in particular (more focused/directed mission, bigger tent by allowing for varying motivations, different pitch).
Research-Centered Approach
We want AI safety to be motivated not just by mitigating existential risk and maximizing utility, but also as one of the most interesting, exciting, and important problems humanity faces. Accordingly, HAIST’s website and internal programming is intentionally heavy on research and light on general discussion of existential risk.
We think that participating in and discussing safety research is also good for helping HAIST members build skills and gain legitimacy, both of which are useful in connecting them to technical jobs in safety after graduating. We also think that framing HAIST as primarily research-focused (as opposed to emphasizing our outreach and skill-building efforts) helps with attracting new members and creating a healthy and productive internal atmosphere (we aren’t just talking about scary things, we are working to prevent them!).
Starting HAIST, Tips & Tricks
HAIST began after a full semester of existential risk focused outreach (handing out The Precipice, running reading groups, weekly dinners). We think this outreach is responsible for a big portion of HAIST’s success (namely, having interested participants to work with). We sent emails (copy here) individually inviting people we knew were interested in AI safety[1] to join HAIST, and followed up individually with everyone we invited. Nearly everyone we reached out to joined HAIST.
We think HAIST was most successful in immediately establishing well-attended meetings that attendees found useful. We met weekly (5:30-7:30 on Mondays with dinner), and usually did a mix of eating/socializing, silent reading, and discussion.
Meeting Format. HAIST meetings never had assigned readings; instead, we spent a significant portion (50ish%) of each meeting silently reading the assigned material together. Combined with serving dinner and meeting in a convenient location, this significantly lowered the barrier to entry for attendance. It also made it easier to plan meetings (just pick some readings!) that were immediately valuable and productive, and improved discussions (everyone has always done the reading). It also feels really good to be in a room full of peers reading silently about alignment. We printed physical copies of most of the readings (heresy!), which some people preferred.
Participant Filter. We used a rough filter of “considering career in alignment” as the criterion for admission in HAIST. This filter meant that everyone took the topic seriously, but also that people came in with different background knowledge. This was not much of an issue, mostly because reading well-chosen papers about AI safety tends to be a useful exercise, as is explaining complicated concepts to new but invested participants. We encourage groups to apply a similar bar if possible (even if that means starting with ~5 people); everyone taking the topic seriously was important both for the meetings themselves and for developing a community.
Content. In our first semester, we covered the current alignment landscape overviews, Transformer interpretability (Anthropic, Redwood Research talks), Eliciting Latent Knowledge (ARC talk), GridWorlds, etc.[2] We usually silently read ~1 hour worth of content (research papers, AF posts) on each of these. This was not supposed to be a curriculum (we will be running other programming for this [see Future Plans]), and the content was probably less important than us all being together and learning something. I do think, however, this probably would not have worked without leadership and a few core members already having a background in alignment (maybe AGISF or equivalent), which made it possible to select relevant and high quality readings without too much effort.
Guest Lectures. Guest lectures were fun but not necessary for productive meetings (silently reading and then discussing is actually a really high standard for productivity). We think a lot of the value of guest lectures is to communicate to newer members that the researchers who are working on safety are, in fact, real.
Community & Housekeeping. My guess is a fair amount of HAIST's success came down to small things. I reached out to most members before most meetings (especially those I thought may not come by default), asked people to let me know if they were going to miss a given week, and made sure the food was good. I also tried to make the meetings feel well-run and legit by making nice slides and meeting in a fancy room. We also have a Messenger group chat and Slack channel, where members regularly share and discuss AI safety related news, thoughts, and worries.
Future Plans and Path to Impact
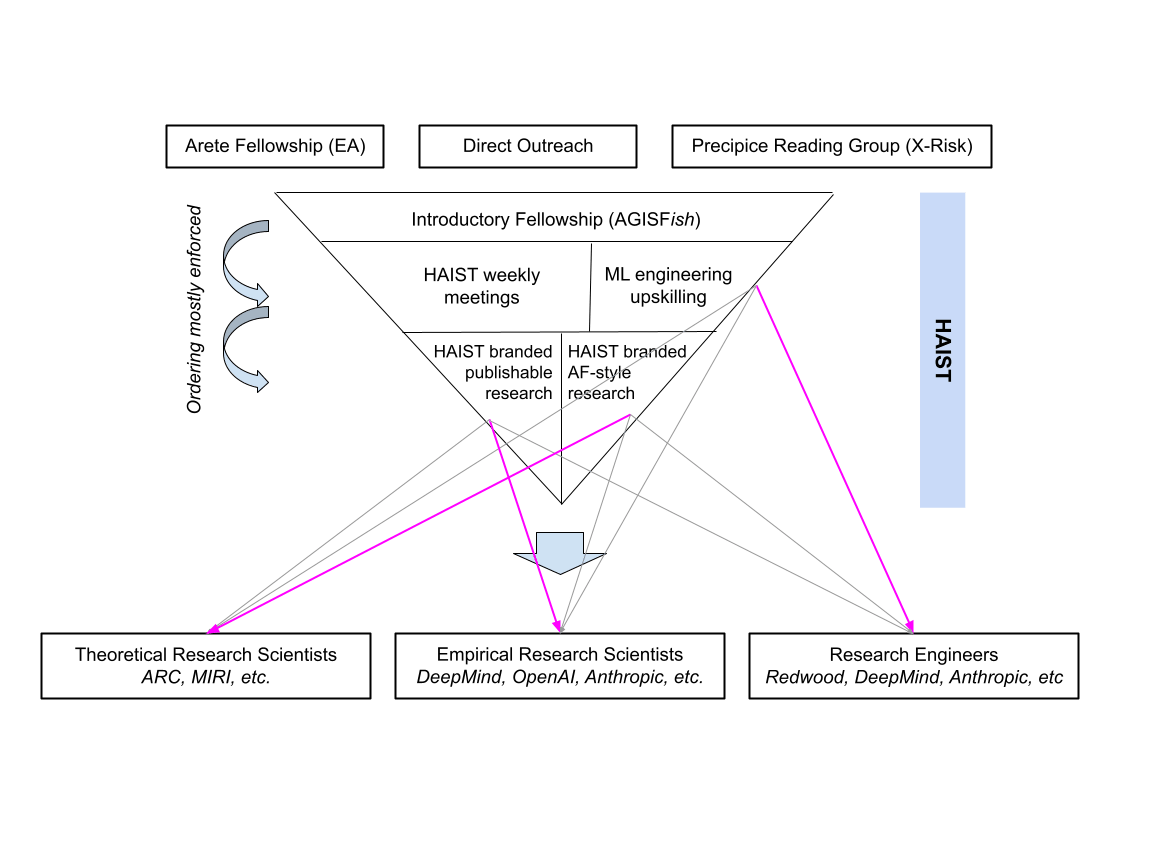
Last semester we focused on holding high quality and well-attended meetings to develop a core of engaged members. This semester, we want to focus on intro programming (probably AGISF-ish), ML engineering upskilling (likely MLAB-ish or SUDRL-ish, intensive and targeted at engaged club members), and research (HAIST-branded safety-relevant research projects of 1-3 people, probably advised by AI safety-aligned PhD students).
The following diagram shows the path to impact of HAIST programming. I think it’s useful to think of it as a funnel, with more safety researchers as the end-state. I also think it’s useful to use Rohin Shah’s partitioning of research roles to design targeted programming, as opposed to targeting an amorphous safety researcher, since different alignment roles use different skills and require different credentials. These targets are indicated with arrows (purple arrows for emphasis on particularly targeted paths).
Downside Risk
We acknowledge that HAIST could introduce AI to students who may later go on to do research that leads to the deployment of harmful ML systems. We think that the prospect of HAIST accelerating timelines to AGI carries serious risks, and we are actively working to reduce this risk.[3] We also acknowledge that HAIST has the potential to significantly raise the salience of AGI at Harvard, which could have unexpected effects.
Conclusion
We are very excited about HAIST, and encourage other universities to start similar groups. I am happy to talk or email ([email protected]) with anyone interested in doing so, and/or provide slide/website/email templates if useful. We are also currently looking for AIS researchers to advise 1-3 person research projects in the fall (compensated); please email me if you’d like to help with this, or if you have any other advice for HAIST or thoughts on downside risks.
Thank you to Fiona Pollack, Trevor Levin, and Nikola, without whom HAIST would not have happened. Thanks to Juan Gil and Worldline for funding, and Jack Ryan for leading a retreat in the spring. Thanks to Davis Brown, Max Nadeau, Steve Byrnes, Zac Hatfield-Dodds, and Mark Xu for excellent guest lectures. Thanks to Rohin Shah, Max Nadeau, Warren Sunada-Wong, Madhu Sriram, Andrew Garber, Al Xin, Sam Marks, Lauro Langosco, and Jamie Bernardi for thoughtful comments and revisions.
For example, our skillbuilding is aimed at students who have completed an intro fellowship to the level of AGISF or equivalent, which will necessarily include discussion of risks from unaligned AGI.
This seems really exciting, and I agree that it's an underexplored area. I hope you share resources you develop and things you learn to make it easier for others to start groups like this.
PSA for people reading this thread in the future: Open Phil is also very open to and excited about supporting AI safety student groups (as well as other groups that seem helpful for longtermist priority projects); see here for a link to the application form.
Awesome that this exists! Especially the way this student group is research focused, as opposed to pure community building - seems to me that there being different types of EA-aligned student groups around might give us information on what works. Best of luck!
This is so so cool! Love the idea of focusing on concrete goals with high-investment groups, and approaching important questions from different angles. I've been unsure whether the "nerdsniping" approach of "isn't this actually just an interesting problem?" that I've advocated before really holds up, but I'm glad it potentially did here, though maybe because you had the standard outreach first.
I'm curious how you think this would have gone if you hadn't had the first stage of outreach?
Generally I'm really excited about people using intro stage outreach and then being selective for further things in exactly the way you describe here.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
New Video from AI in Context: The Fall and Rise of Sam Altman
If you want to skip straight to the video, here it is!
AI in Context is excited to be back with our fourth video! For those just hearing from us, we make videos for 80,000 Hours, telling stories about transformative AI...


This seems really exciting, and I agree that it's an underexplored area. I hope you share resources you develop and things you learn to make it easier for others to start groups like this.
PSA for people reading this thread in the future: Open Phil is also very open to and excited about supporting AI safety student groups (as well as other groups that seem helpful for longtermist priority projects); see here for a link to the application form.