This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
Hello! I'm Justin Portela. I got hired by GWWC to make YouTube videos after AI in Context did such a kickass job.
My channel is using that same cinematic, high-production value beauty to talk about everything in the EA universe that isn't AI.
...
This is a linkpost for Request for Proposals: Research and Applied Work on Digital Minds.
I'm glad to announce a request for proposals for research and applied work on digital minds at Longview Ph...
This is the second post in a sequence of posts that describe our models for Pragmatic AI Safety.
The internal dynamics of the ML field are not immediately obvious to the casual observer. This post will present some important high-level points that are critical to beginning to understand the field, and is meant as background for our later posts.
Driving dynamics of the ML field
How is progress made in ML? While the exact dynamics of progress are not always predictable, we will present three basic properties of ML research that are important to understand.
The importance of defining the problem
A problem well-defined is a problem half solved.
—John Dewey (apocryphal)
The mere formulation of a problem is often more essential than its solution, which [...] requires creative imagination and marks real advances in science.
Science requires that we clarify the question and then refine the answer: it is impossible to solve a problem until we know what it is. Empirical ML research, which is the majority of the field, progresses through well-defined metrics for progress towards well-defined goals. Once a goal is defined empirically, is tractable, and is incentivized properly, the ML field is well-equipped to make progress towards it.
A variation on this model is that artists (writers, directors, etc.) come first. They help give ideas, and philosophers add more logical constraints to those ideas to come up with goals or questions, and finally scientists can help make iterative progress towards those goals. To give an example: golems, animate beings created from clay, were a common symbol in Jewish folklore, and at times could create evil. There are many other historical stories of automatons creating problems for humans (Pandora, Frankenstein, etc.). More recent stories, like Terminator, made the ideas more concrete, even as they included fantasy elements not grounded in reality. More recently, Bostrom (2002) recognized the possibility for existential risk from AI, and grounded it in the field of artificial intelligence. Since then, others have worked on concretizing and solving technical problems associated with this risk.
For completeness, it’s worth mentioning that sometimes through tinkering people find solutions to questions people were not posing, though many of those solutions aren’t solutions for interesting questions.
Metrics
As David McAllester writes, machine learning and deep learning is fundamentally driven by metrics. There are many reasons for this. First, having a concrete metric for a problem is a sign that the problem has been compressed into something simpler and more manageable (see the discussion of microcosms below), which makes it more likely that progress can be made on it. By distilling a problem into a few main components, it is also far clearer when progress has been made, even if that progress is relatively small.
Unlike human subjective evaluation, most metrics are objective: even if they do not perfectly track the properties of a system that we care about, it is obvious when somebody has performed well or poorly on an evaluation. Metrics can also be used across methods, which makes different approaches directly comparable rather than relying on many different measuring sticks. High-quality datasets and benchmarks concretize research goals, make them more tractable, and can spur large community research efforts. Good metrics also can allow us to detect minor improvements, which enables iterative progress and accumulated improvements.
Metrics that rely too heavily on human evaluation are suspect. First, human evaluation is extremely expensive compared to automatic evaluation, and often requires IRB approval in the case of academic labs. This significantly reduces its utility. Second, human evaluation is slow, which makes feedback loops sparser and thus makes problems far more difficult to iterate on. Third, human feedback is often noisier and more subjective than many automatic evaluation metrics.
For these reasons, the first step working towards working on a new ML problem is to define a good metric.
Limits of theory for machine learning
There can be a tendency for new fields to try to formulate new problems as mathematics problems, but this is not always possible. Unfortunately, if machine learning just isn’t productively formulated as an applied mathematics problem, throwing lots of resources at it as an applied mathematics problem isn’t going to work. Currently, deep learning progress is not well-formulated as an applied mathematics problem.
2010s: Progress continues, aided by the availability of large amounts of visual data and massive computing power. Deep learning has become pre-eminent
While some researchers tried to treat image recognition as an applied math problem, as mathematical solutions have many desirable properties, this did not work and they were forced to shift paradigms. Research communities that need to solve problems don’t get to choose their favorite paradigm. Even if the current paradigm is flawed and a new paradigm is needed, this does not mean that their favorite paradigm will become that new paradigm. They cannot ignore or bargain with the paradigm that will actually work; they must align with it. We may want a machine learning problem to be a math problem, but that does not mean it is.
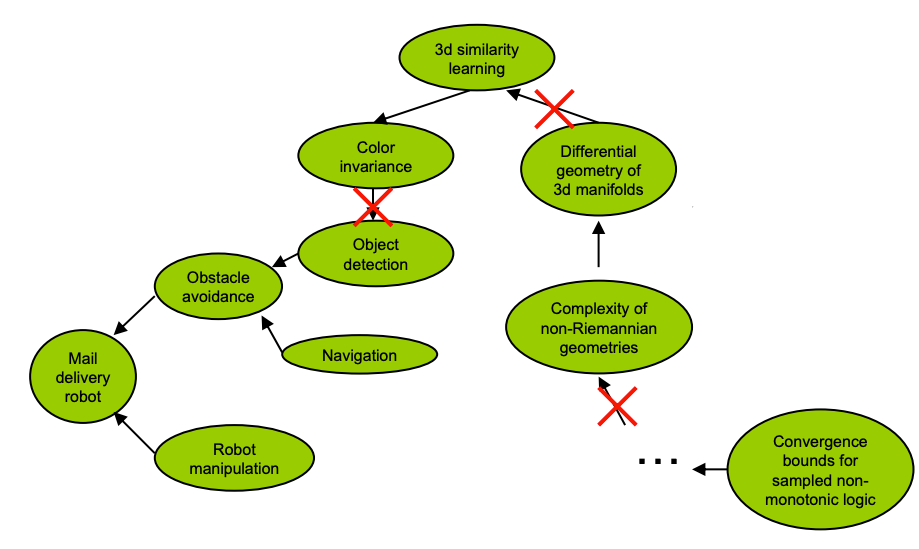
Overtheorizing is a common failure case for solving technical problems, and it happened in AI. Imagine you want to build a mail delivery robot. If you start working on differential geometry, you’re doing it wrong and overtheorizing. It simply is not necessary to solve that problem in order to build the mail delivery robot. The slide with the figure above is from 1995, and argues that many of the subtasks thought relevant for object detection were unnecessary for the task: today, this is obvious. Despite a large number of extremely smart people working on CV as an applied mathematics problem for many years, they did not solve CV, because CV is not an applied mathematics problem.
A similar dynamic happened with what is now known as “good old fashioned AI” using explicit high-level symbolic and search algorithms. While it produced some successes, these inclinations have been mainly replaced by deep learning in the state of the art.
In natural science, the objective is to discover, study, and explain natural phenomena. Consider optics (1650), thermodynamics (1824), aerodynamics (1757), information theory (1948), and computer science (1950). In natural science, the gold standard is reproducible experiments in controlled conditions. The use of mathematics and statistics is common, since they help provide a theoretical underpinning. In natural science, control over the environment in an experiment is crucial.
In engineering science, the basic idea is to invent new artifacts. Consider the telescope (1608), steam engine (1695), sail boat (BCE), teletype (1906), computer (1941), etc. In engineering, one must use intuition, creative inspiration, tinkering, and trying many things to see what sticks. Invention is often created by accident, by people who created many failing inventions. Some theory is surely needed (a sailboat is far less likely if one does not know that wind can push objects) but it often does not need to be very detailed. Engineering is often bottom-up and creative, and theory does not dictate an exact or even approximate design. For a discussion of deep learning and limits of top-down design, see here. In many cases, natural science follows engineering science, where natural science attempts to explain an artifact created by engineering.
Yann LeCun discusses this distinction further here. The distinction may also be analogized to the distinction between rationalism and empiricism.
Deep Learning (DL) is mostly engineering science. We have few theories, and the theories we do have provide limited guidance. Attempts at generalizing phenomena in DL are very often not robust. For example, previously l1 loss worked noticeably better than l2 loss for pixel regression, but not recently. Every year, new papers are published that purport to explain the generalization ability of neural networks, but the subject has not been settled. There are some exceptions: for instance, the fact that bigger Transformer models consistently perform better. Since these kind of observations are more robust than theories, and since the phenomena are fragile, the theories are even more fragile. Even ML theorist PhD students will readily admit that theory for DL has not (yet) created action-relevant insights about DL.
DL has many factors that increase the probability of surprises or unknown unknowns: complicatedness, fast changes, ambiguity, opacity, and interconnectedness/multiple causes. In view of this, researchers that work for years towards advancing capabilities to get a specific downstream safety research outcome are not being precautious since this field is not that predictable. This level of unpredictability makes armchair/whiteboard research less likely to succeed; much research must be bottom-up and iterative.
DL methods are often not even obvious in hindsight, unlike more theoretical fields where proofs are self-evident to audiences with an appropriate background. Why do residual connections work? Why does fractal data augmentation help? This property is why tinkering and rapid experimentation is so important.
If hindsight doesn’t even work, that means that it is extremely difficult to achieve foresight into the impact of a proposed project. Instead, it is necessary to fall back on heuristics. First, does the project seem palpably unrealistic on its face? This could be grounds for dismissing it. Otherwise, if there are not yet results, one should instead defer to the researcher’s prior track record, with perhaps some benefit of the doubt given to younger researchers who have not had time to accrue track records.
Creative Destruction in ML
If a temple is to be erected a temple must be destroyed: that is the law – let anyone who can show me a case in which it is not fulfilled!
Like many other fields, ML experiences creative destruction: periods when new and better technology rapidly replaces older methods. This can be related to models for exponential growth as aggregated sigmoid jumps rather than a truly smooth acceleration.
Research, especially research into algorithms, architectures, training techniques, and the like, is often entirely wiped away by “tsunamis.” For example, natural language processing techniques from before BERT are almost entirely irrelevant. A large number of computer vision techniques devised prior to AlexNet have almost no influence on the field today. Lastly, speech recognition became an essentially solved problem with the advent of deep learning. After a tsunami, methods often work out-of-the-box, require less effort to use, and performance is much higher.
Imagine you’re in the late 2000s and care about AI safety. It is very difficult to imagine that you could have developed any techniques or algorithms which would transfer to the present day. However, it might have been possible to develop datasets that would be used far into the future or amass safety researchers which could enable more safety research in the future. For instance, if more people had been focused on safety in 2009, we would likely have many more professors working on it in 2022, which would allow more students to be recruited to work on safety. In general, research ecosystems, safety culture, and datasets survive tsunamis.
By some indications, reinforcement learning is poised for a tsunami. RL currently is extremely unwieldy, requiring careful tuning of a large number of parameters and methods to achieve any reasonable results at all. It often (not always) uses Markovian assumptions and exponential decay, which tends to be replaced by paradigms that better model long-range dependencies (e.g., consider hidden markov models in NLP which have been superseded). Unlike language and vision, RL has not yet been revolutionized by large-scale models. As such, RL appears to have the properties of a field prior to a tsunami. If this is true, it does not bode well for RL safety research methods, which could be washed away.
As a result, developing safety proposals for DL is likely to be a safer bet than RL in both the short and long term. There appears to be a reasonable chance that DL will not be washed away. In this case, it is extremely important to have a high number of people working on empirical methods. If DL is not the last tsunami, research in DL will still aid dataset creation, research ecosystem building, and safety culture for later.
Thinking of methods that will work in the current paradigm and not using this research to help ecosystem building in the larger ML community is doubly bad: it stands the risk of being wiped away by a tsunami, and it didn’t even help research ecosystem building. If one expects more tsunamis, pay more attention to prestige and resources.
The Bitter Lesson argues that there will be more creative destruction and that human ingenuity will matter less and less. Although we do not believe the following scenario is likely, in the long run, AI risk reduction may even be a matter of banal factors: compute, data, and engineering resources allocated towards safety goals, in comparison with other capabilities goals. The amount allocated towards these goals would depend on how important safety is to the system designers, which means safety buy-in among researchers and tech leaders would be a high priority.
The ML research ecosystem
If we want to have any hope of influencing the ML community broadly, we need to understand how it works (and sometimes doesn’t work) at a high level.
Where is ML research published?
The machine learning field, both in industry and academia, is dominated by conferences. Except for a few splashy and publicized industry papers published in Nature, the most important ML papers are all published in a relatively small number of ML conferences. Though there are a few journals, they are not very impactful, nor are papers that are exclusively published at workshops. The vast majority of papers are submitted to conferences.
Prior to publication, most ML research papers are posted as preprints on arxiv.org (pronounced “archive”). Because of the speed that the ML research field advances, it is not sufficient for ML researchers to simply read papers that have been published in conferences, since publication typically doesn’t happen for several months until after a paper is posted on arXiv. Instead, ML researchers need to keep updated on the latest preprints. Many do so via relying on word of mouth or Twitter to indicate which papers are important, while others make more of an effort to identify important papers on arXiv themselves.
Composition of ML Subfields
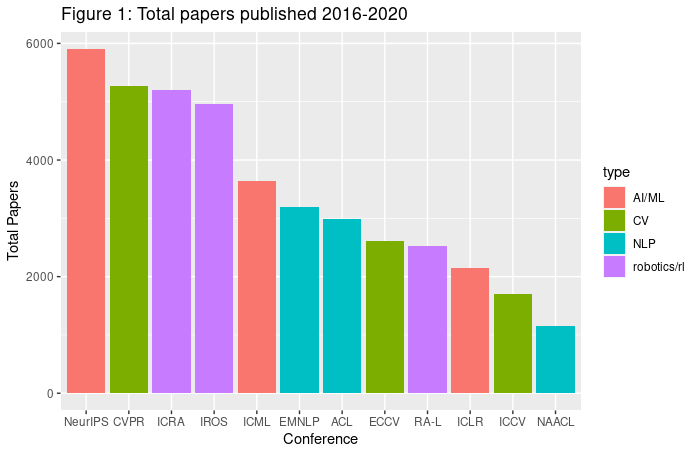
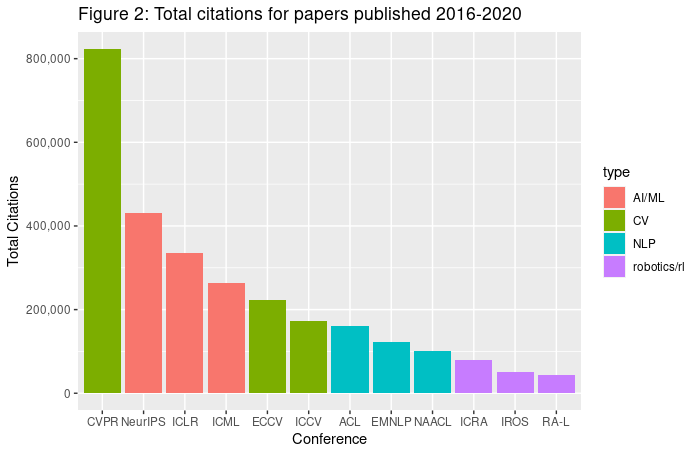
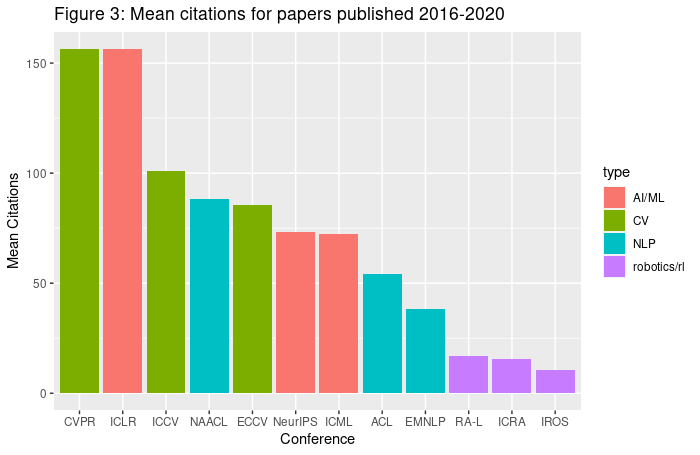
The size of different machine learning subfields might not be immediately obvious to somebody outside of the field. The graphs and statistics that follow are based on an analysis we conducted of publicly-available data from Semantic Scholar (data is approximate, and is only as accurate as the Semantic Scholar data), and use citations as a rough metric for the size of different subfields.
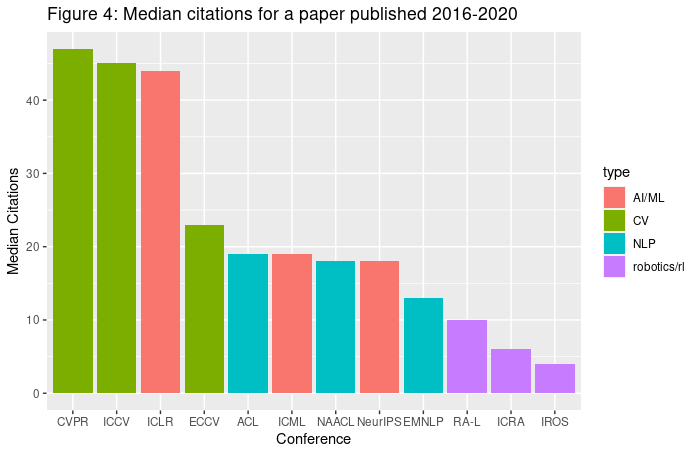
By far the largest subfield within machine learning is computer vision (CV), with the Conference on Computer Vision and Pattern Recognition (CVPR) being by far the most influential conference in machine learning in terms of the number of citations. Natural language processing (NLP) is much smaller than computer vision, with the largest conference, the Proceedings of the Association for Computational Linguistics (ACL), getting about a fifth the total citations of CVPR. Even smaller than NLP are reinforcement learning and robotics. The most influential conference in this area is the IEEE International Conference on Robotics and Automation (ICRA), which receives slightly more than half the citations of ACL (so an order of magnitude less than CVPR). There are also three conferences that publish many kinds of ML research: the International Conference on Learning Representations (ICLR), Neural Information Processing Systems (NeurIPS), and the International Conference on Machine Learning (ICML). These conferences can contain NLP, CV, and RL, and all rank in the top four conferences along with CVPR.
The top conferences do not gain their influence simply by having many papers. ICRA and IROS publish as many papers as CVPR (Figure 1), but mean and median citation counts in CV and ML conferences (particularly ICLR) are far above those in NLP and RL/robotics (see Figure 3 and 4).
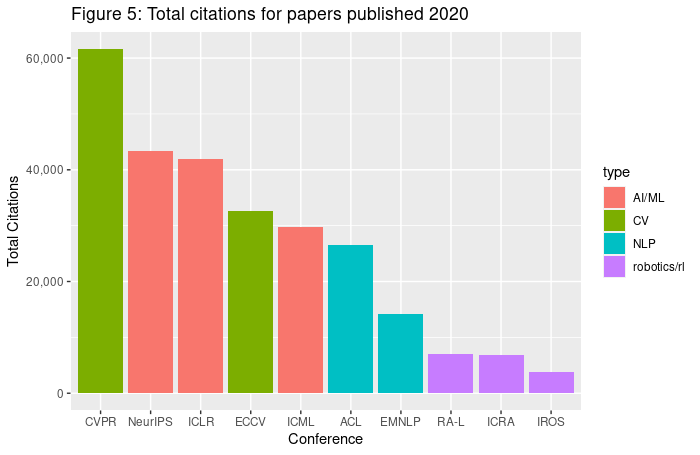
NLP has been growing recently, especially since BERT reduced barriers to entry. For instance, ACL papers from 2020 (see Figure 5) only got 2-3x fewer citations compared with CVPR papers, showing some relative growth of the field (note NAACL and ICCV were not held in 2020). Still, CV was the largest subfield, and RL/robotics has not gained any ground at all.
Explanation of ML Subfields
Microcosms
“Microcosms” in this context are simpler subproblems of harder problems that mirror the larger problems but are more tractable. To give a concrete example, to make an aerodynamic bicycle for a race, you might first want to start by making it aerodynamic in a wind tunnel. Although the conditions of a wind tunnel are simplified compared with the real world, they are similar enough to yield useful insights. Some simpler problems are not that microcosmic, however, because they may make too many simplifying assumptions and thus not be representative of the macrocosm (e.g., some gridworlds).
In general, the majority of research inquiry is conducted on microcosms. Work on these problems can inform us about the future or even directly influence future systems, as some current ML algorithms are highly scalable and may be a part of long-term AI systems. Next, we will discuss two of the most important microcosms in machine learning.
Why do DL researchers look at ImageNet and image classification so much?
Historically, CV and pattern recognition in general have gone together. The ImageNet dataset, an old compilation of images and associated labels for those images, continues to drive the field. Why? It is a good microcosm. Researchers have found that performance on ImageNet is highly predictive of downstream performance in numerous applications like segmentation, clustering, object detection, and downstream image recognition. Many researchers also view image understanding as a problem that is upstream of video understanding, which is important for a whole range of additional applications.
Deep learning researchers use CV as a representation learning proxy, not because they are particularly interested in classifying cats. Most DL building blocks (some activation functions, batch normalization, some optimizers, dropout, convolutions, residual connections, etc.) have emerged from researching image classification, so it is a useful whetstone to sharpen DL algorithms against. Consequently, people do not think they’re just researching vision but instead researching how to do representation learning and deep learning in general. There are, of course, exceptions: semantic segmentation, depth maps, and downstream applications of CV do not necessarily help with general representation learning.
Many economic incentives and funding sources are available for CV because vision is useful in many industries, which keeps the field large.
CV is also large because it’s very possible to improve image classification performance with ideas since scaling is less important. Many methods do not currently have consistent returns to scale: for instance, current masked autoencoders do not consistently perform better with more data or compute. Most researchers, especially academics, are heavily incentivized towards fields where improvements can be made with ideas, because ideas can be found by competent researchers with good taste who spend enough time tinkering. Meanwhile, in NLP, a larger share of progress is made by simple scaling, which makes for less interesting work for researchers, and less incentivized outside very large labs with access to compute resources.
In DL, findings for some data transfer to other types of data. This is partly because different kinds of natural data have similar underlying statistical properties. Consequently, studying how to do representation for some data distributions often transfers to other data distributions. Many techniques, such as residual connections, that helped with ImageNet helped with discrete signals (text) and other continuous signals (speech).
Why is NLP the second largest field?
As detailed above, image classification is not about images as much as it is about general capabilities to analyze continuous structured signals. Likewise, natural language processing is important because it studies discrete signals.
In recent years, NLP and CV have started to coalesce, with more multimodal models being able to process both continuous and discrete signals. In addition, insights from NLP, such as large pre-trained transformer models, are now percolating into CV (e.g. vision Transformers), as techniques have become more general and differences between the two paradigms are decreasing.
Issues with Conferences
The conference review process has serious flaws. For instance, best paper awards mean very little; oral or spotlight designations are not highly predictive of longer-term impact either. In ML conferences, awards and designations are highly biased towards theory papers. In vision, these awards have a strong political element, where some awards are sometimes given to researchers that are seen as needing or deserving of a career boost.
In 2014 at NIPS (now called NeurIPS), an experiment was conducted where the review committee was split in half, and 10% of papers were assigned to be reviewed independently by both committees. 57% of papers accepted by one committee were rejected by the other committee, and vice versa. In comparison, given the overall acceptance rate, the rate would be 77.5% if decisions were purely random and 0% if decisions were perfectly correlated.
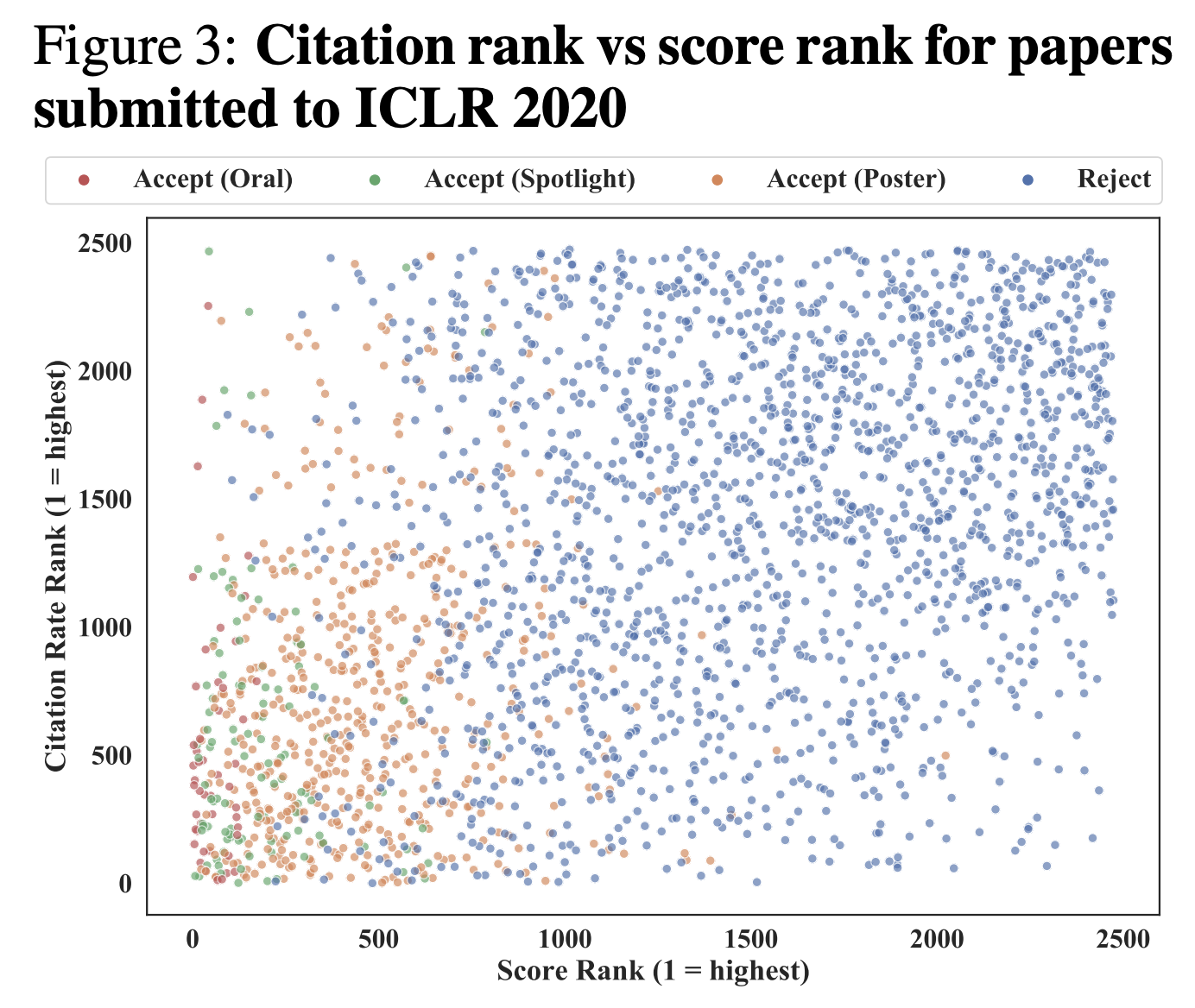
A recent analysis found the correlation between reviewer scores and eventual citation rate was very weak at ICLR 2020, after controlling for acceptance decisions. The most transformative ideas are often initially disputed or doubted; to be accepted, consensus often needs to be reached in a short discussion period. Additionally, reviewers adversely select for complicated methods (neomania) and disincentivize simple methods that work, even if impact is one of the dimensions they are supposed to be evaluating. In ML conferences, they incentivize theory, which these days usually is anticorrelated with ultimate impact.
As pointed out by Yann LeCun (timestamp 2:15), a large number of young reviewers just want to point out errors rather than assess the paper overall. However, correcting errors is unlikely to make a paper go from low to high impact or help researchers write better papers the next time around.
These experiments cast doubts on the review process, even though researchers continue to act as though conference selection processes are wise. This doesn’t mean that the review process is not at all useful. For one, conferences provide comments to papers, not just scores. More importantly, anonymous peer review is necessary for researchers in their first five years of research, as they need tough comments from random community members; without peer review, people will rarely hear what people truly think since specific disparagement is highly uncommon in other CS contexts. Reviewer comments also limit parochialism, an increasingly large problem as the field becomes more expansive. Reviews also require papers to have some level of technical execution ability; if they’re below a threshold, most people do not even submit the paper. Lastly, it’s important to consider the effect that the anticipation of the review process has on researchers. Even if reviews are a noisy process, researchers will be frequently thinking about how to make sure their paper is accepted by reviewers, and in many cases this can encourage them to have a stronger paper. Like democracy, the review process is not a perfect system, but it works better than alternatives (e.g. “trial by upvote”).
One implication of the flaws with the review process is that new approaches cannot reliably be evaluated just by thinking about them. Rather than rely on experts to evaluate new works, communities need the test of time, the ultimate filter for bad ideas.
Consequential and Inconsequential Papers
Marked progress on a specific problem, even if you have a field working on it, is usually fairly infrequent, where there will be a paper that actually moves things ahead every 6 months to 3 years. In the meantime, there are many unpublished and published papers that are inconsequential. It is very hard to come up with something that actually helps.
How are so many inconsequential papers published? They may have successfully presented themselves as consequential. For instance, it is common for researchers to publish papers in which they achieve state of the art performance in one metric (e.g. out-of-distribution robustness) while sacrificing performance in another metric (e.g. calibration) compared to the previous state of the art. This might be accepted, because it appears to make progress in one dimension. The best papers, on the other hand, make Pareto improvements, or at the very least make extremely lopsided improvements where a minor sacrifice in one dimension leads to a major gain in another.
Another way that inconsequential papers might get published is for authors not to publish results on all of the relevant datasets. For instance, sometimes people publish results of evaluating on CIFAR-10, but not CIFAR-100, often because they are not able to satisfactorily perform on the latter. This sometimes goes unnoticed by reviewers.
Finally, papers that might seem consequential at first turn out to be inconsequential when they are wiped away by tsunamis.
Interestingness
In many cases, ML researchers are motivated by interestingness more than usefulness. This is related to the fact that those who choose to enter research have high openness to new ideas and frequently seek out novelty. This can bias them against research that appears more “boring,” even if it has much more practical relevance.
The bias towards interestingness becomes even more extreme in areas with less concrete metrics for success. In such cases, researchers can sometimes get away with publishing research that is empirically not very useful, but is interesting to reviewers. This is the reason behind many ML “fads,” which can last many years.
Historical Progress
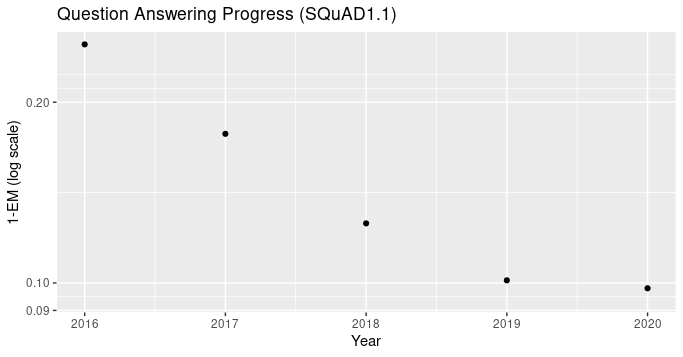
In order to begin to attempt to extrapolate into the future, it’s necessary to understand historical progress. In this section, we will provide some examples of historical progress, using metrics defined for the field. For many metrics, especially those that are highly researched, progress is roughly linear (or log-linear). For less-studied problems, there can be sudden jumps.
Data for the graphs below is from Papers With Code, with some charts consisting of adapted data (mostly to present log error rates rather than accuracies).
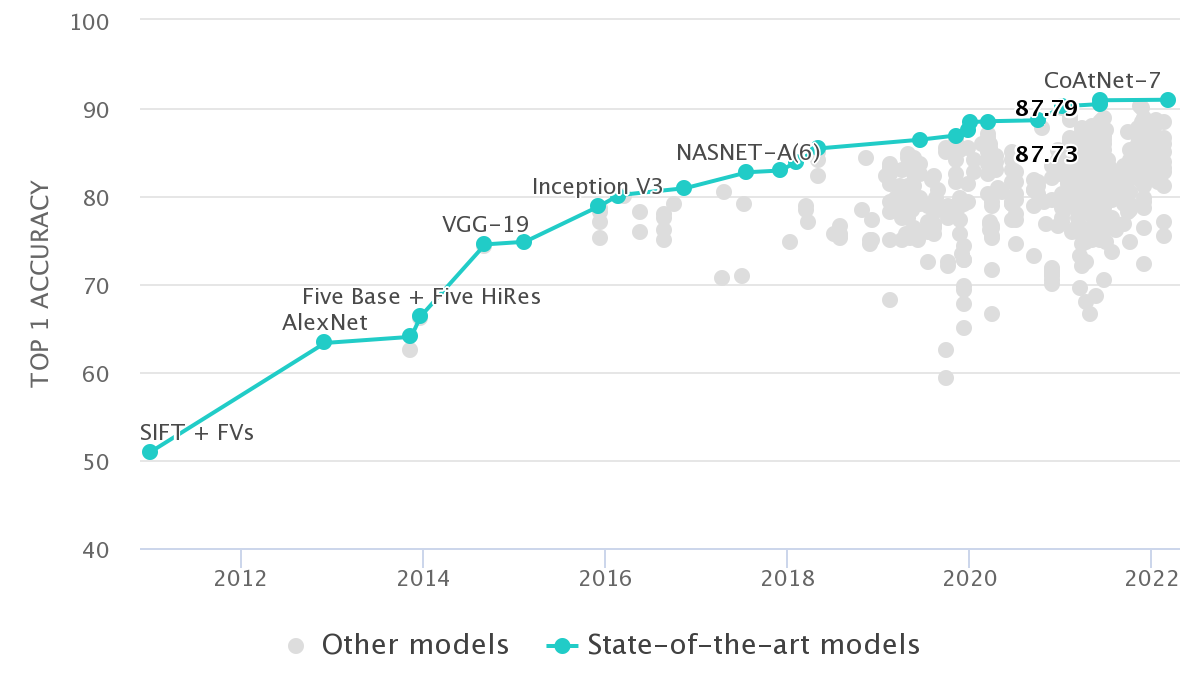
Image Classification
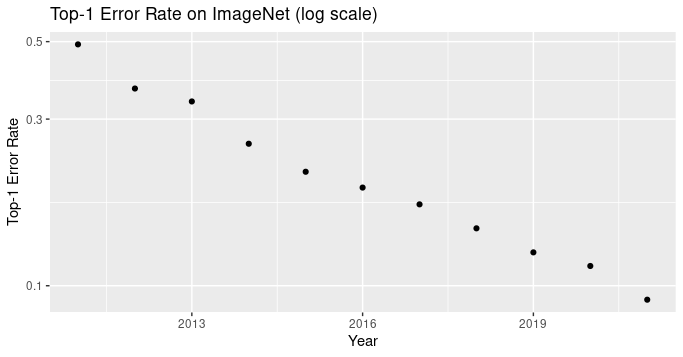
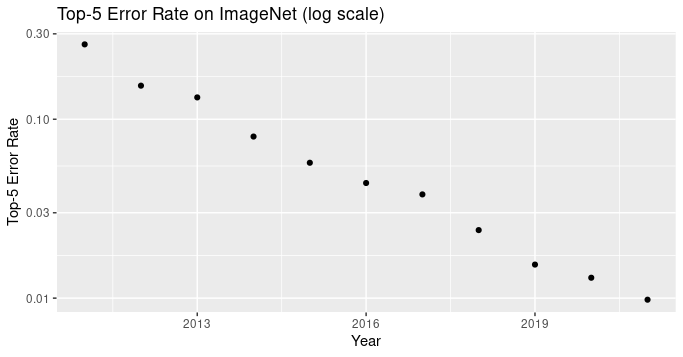
ImageNet has been one of the most influential datasets, and image classification has remained the most important benchmark in computer vision. Frequently the top-1 or top-5 accuracy on ImageNet is reported, but it’s also useful to look at the log error rate since progress has been roughly linear on that metric.
Video understanding
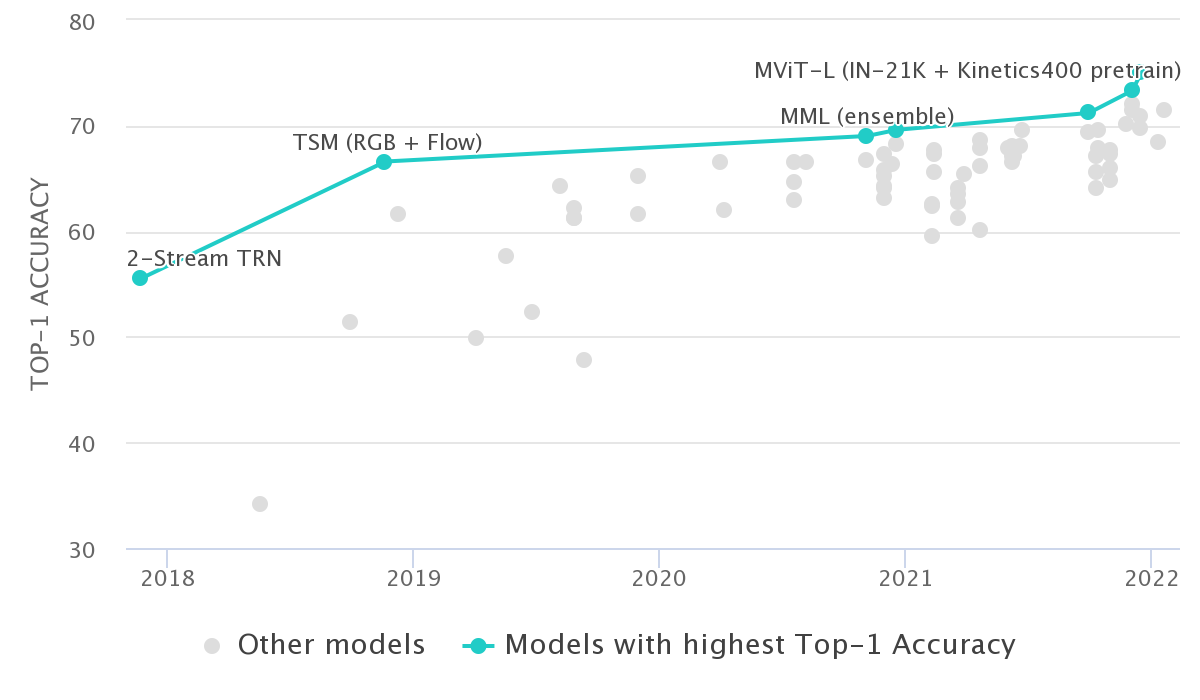
The following chart shows progress on action recognition in videos. The state of the art in 2018 was the temporal relational network, which was a variant of a convolutional neural network. In 2022, the state of the art is a vision transformer that was pretrained on a separate dataset. Progress has been relatively slow in video understanding despite strides in image understanding. One heuristic is that video understanding is ten years behind image understanding.
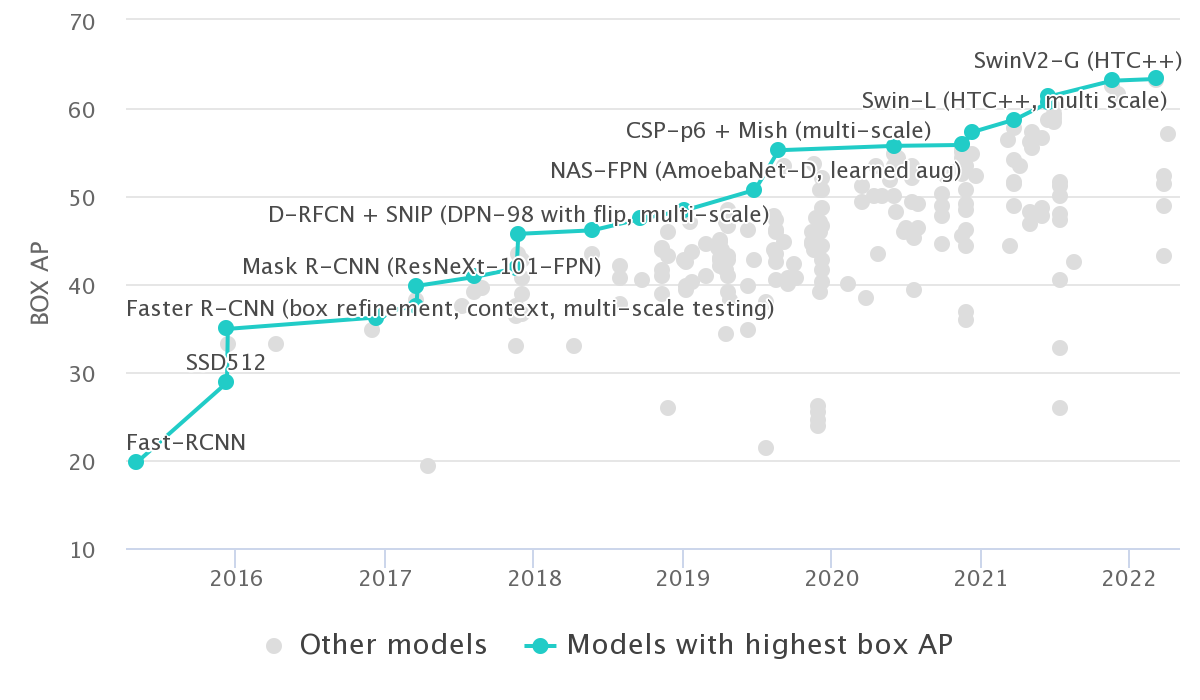
Object Detection
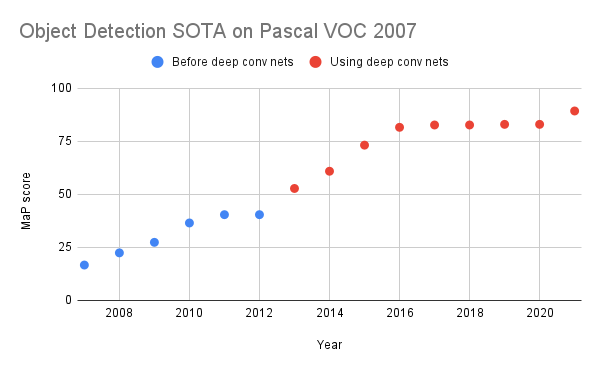
Object detection is sometimes thought of as dramatically accelerated by deep learning. In reality, while there was a period of 1-2 years in which progress seemed to be stalling prior to deep learning, deep learning merely continued the existing trend in capabilities improvements [1,2]. Deep learning did revolutionize the methods in object detection, and the old object detection paradigm was washed away. Starting in 2017, however, performance once again stalled, leading to a plateau that has been longer than any pre-deep learning! In fact, there was nearly no progress until 2021, when a paper made a relatively large improvement. The paper that did so leveraged pre-training with data augmentations.
Image Segmentation
Image segmentation (the labeling of different pixels of an image) on the COCO progressed extremely quickly between 2015-2016, but it has leveled off.
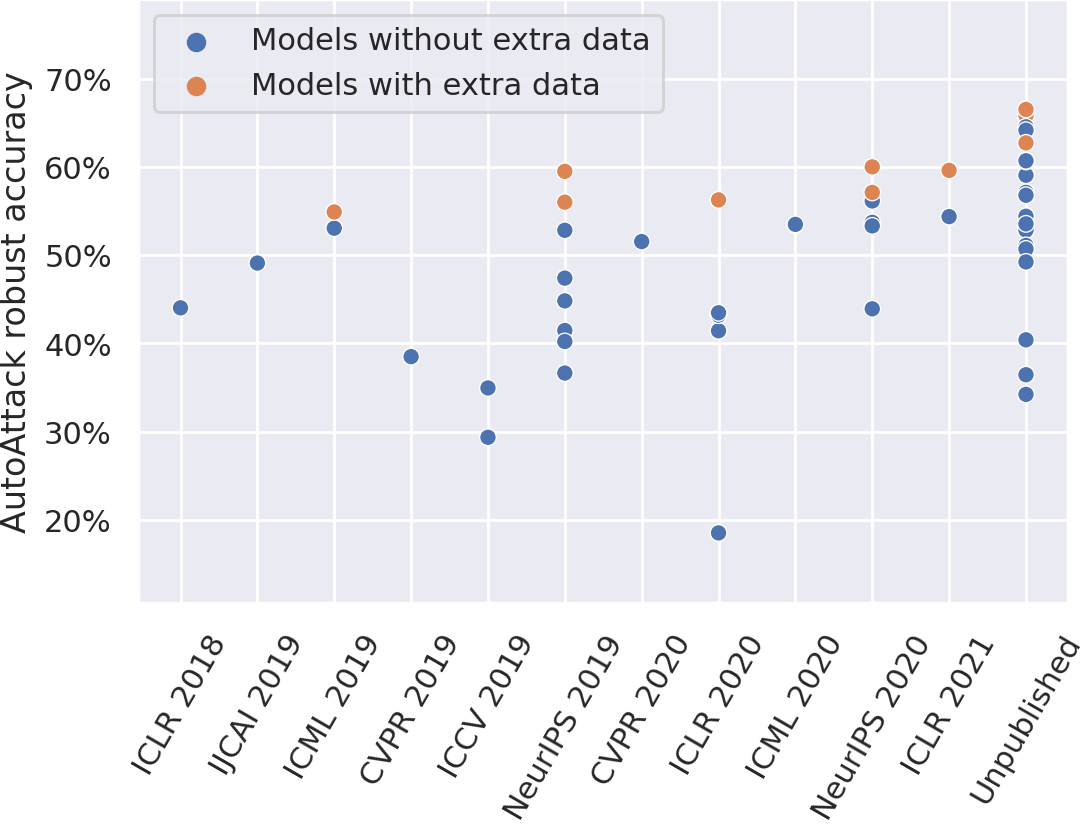
Adversarial Robustness
Progress on adversarial robustness has been fairly slow. See the following graph:
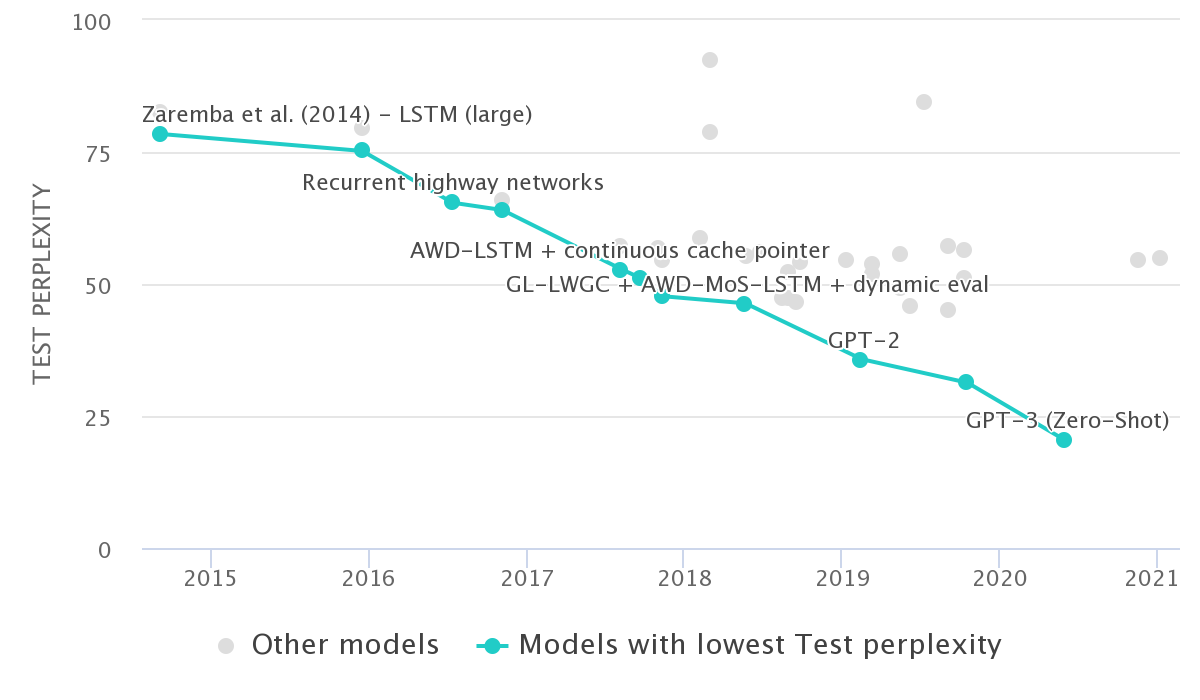
Language Modeling
Perplexity measures the ability of language models to be able to predict the next word given a sequence of words (a lower perplexity is better). Perplexity on the Penn Treebank dataset has been decreasing over time in a roughly linear way.
The view that machines cannot give rise to surprises is due, I believe, to a fallacy to which philosophers and mathematicians are particularly subject. This is the assumption that as soon as a fact is presented to a mind all consequences of that fact spring into the mind simultaneously with it. It is a very useful assumption under many circumstances, but one too easily forgets that it is false.
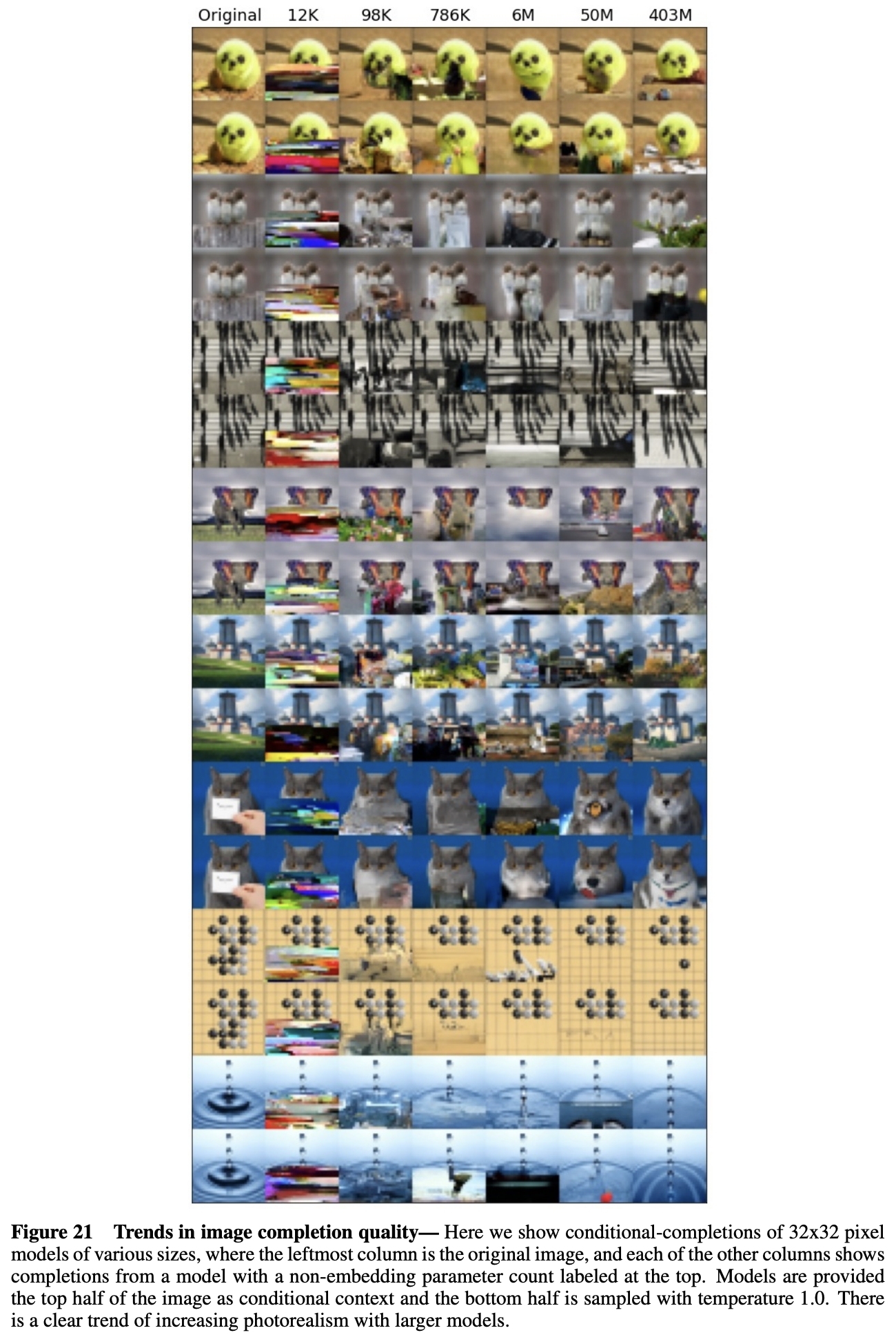
The qualitative impact of an order of magnitude increase in parameters, or a new algorithm, is often difficult to predict. Capabilities can sometimes emerge suddenly and without warning.
For instance, the effect of additional parameters on image generation is not immediately predictable:
Scan the images left to right, blocking the rightward images. Try and predict how good the image will be after an order of magnitude increase.
BERT could not be easily tuned to do addition, but RoBERTa, which was just pretrained on 10x more data, can.
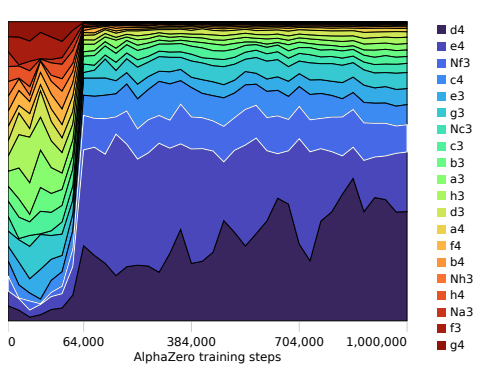
AlphaZero experienced a phase transition where internal representations changed dramatically and capabilities altered significantly at about ~32,000 steps, when the system learned concepts like “king safety, threats, and mobility” suddenly. This can be seen by looking at the system’s preferred opening moves, the distribution of which dramatically changes at 32,000 steps.
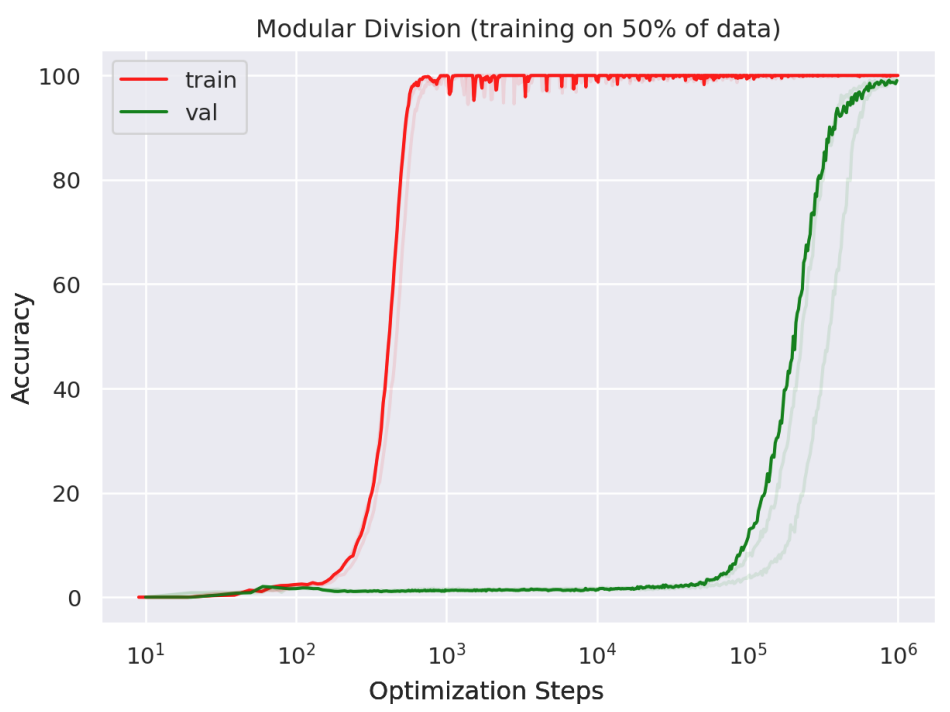
One paper showed that in some cases, performance can improve dramatically on test data even after it had already saturated on the training data:
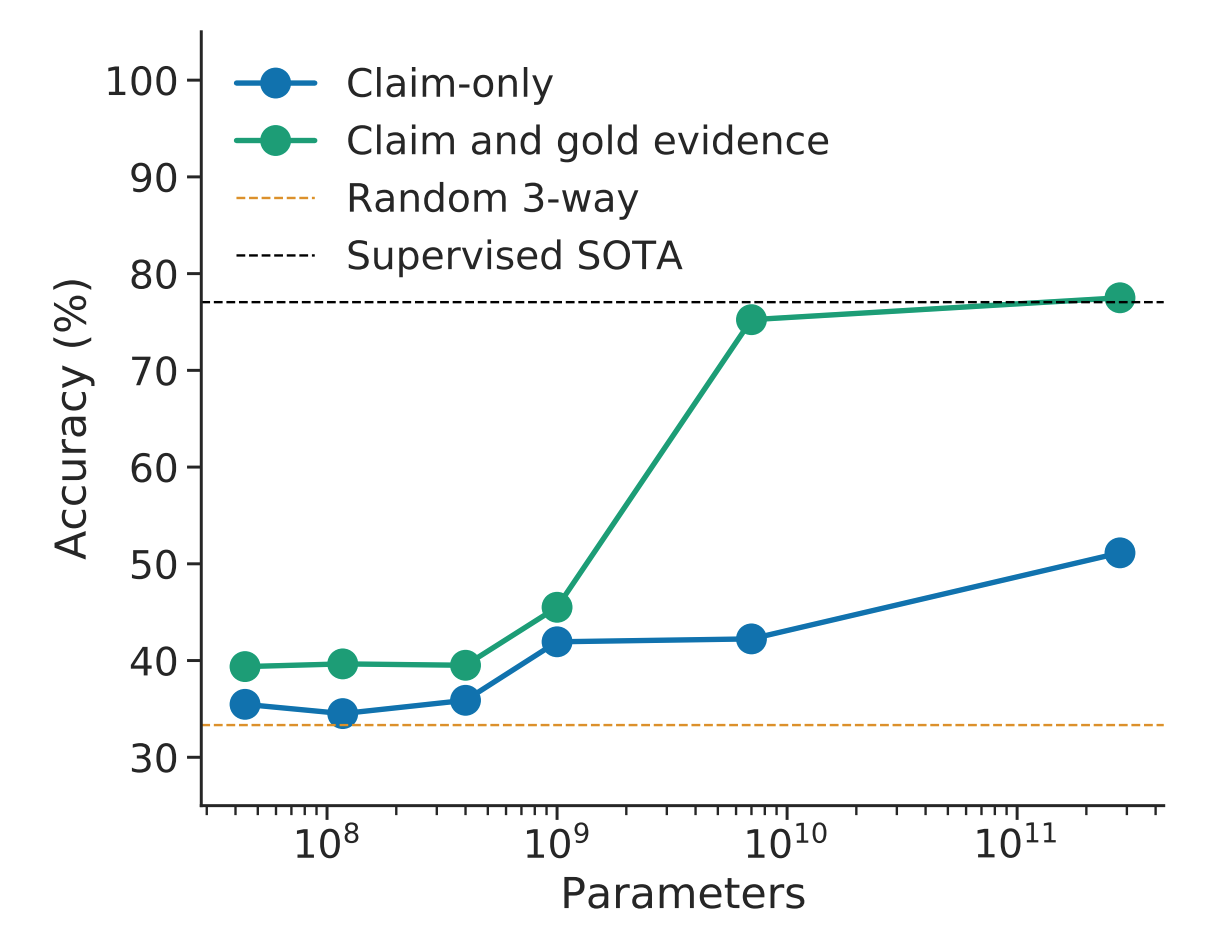
In a paper studying the Gopher model, gold labels initially did not improve performance on the FEVER fact-checking dataset by much at smaller model sizes, but had significant impact at larger model sizes.
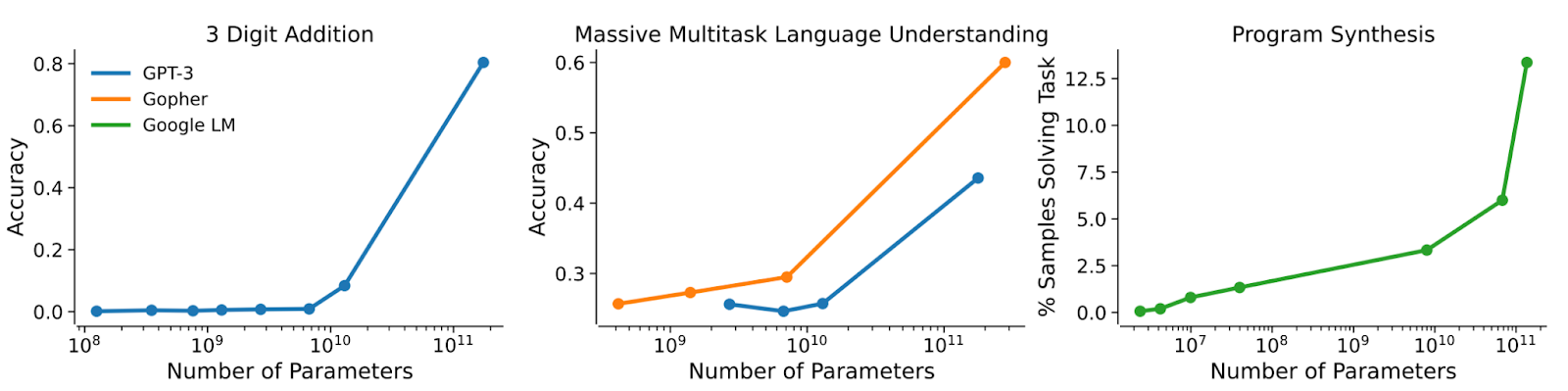
Anthropic’s Predictability and Surprise paper demonstrated fast emergence of addition, multitask understanding, and program synthesis as the number of parameters increased.
It will be hard to make systems safe if we do not know what they are capable of. Additionally, it will be hard to foresee how systems will behave without empirically measuring them.
Lastly, rapid changes can be caused by creative destruction. Most of these graphs did not even start prior to a decade ago, because deep learning ushered in an entirely new paradigm for solving many of the problems above.
Notes on historical progress
In vision, state of the art algorithms usually change year-to-year, and progress has been driven by algorithms and compute. In contrast to this, in NLP, once we had Transformers, the underlying architecture seemed to stabilize. In NLP, it’s currently difficult to have something work better across a broad range of classification tasks without just scaling data or compute.
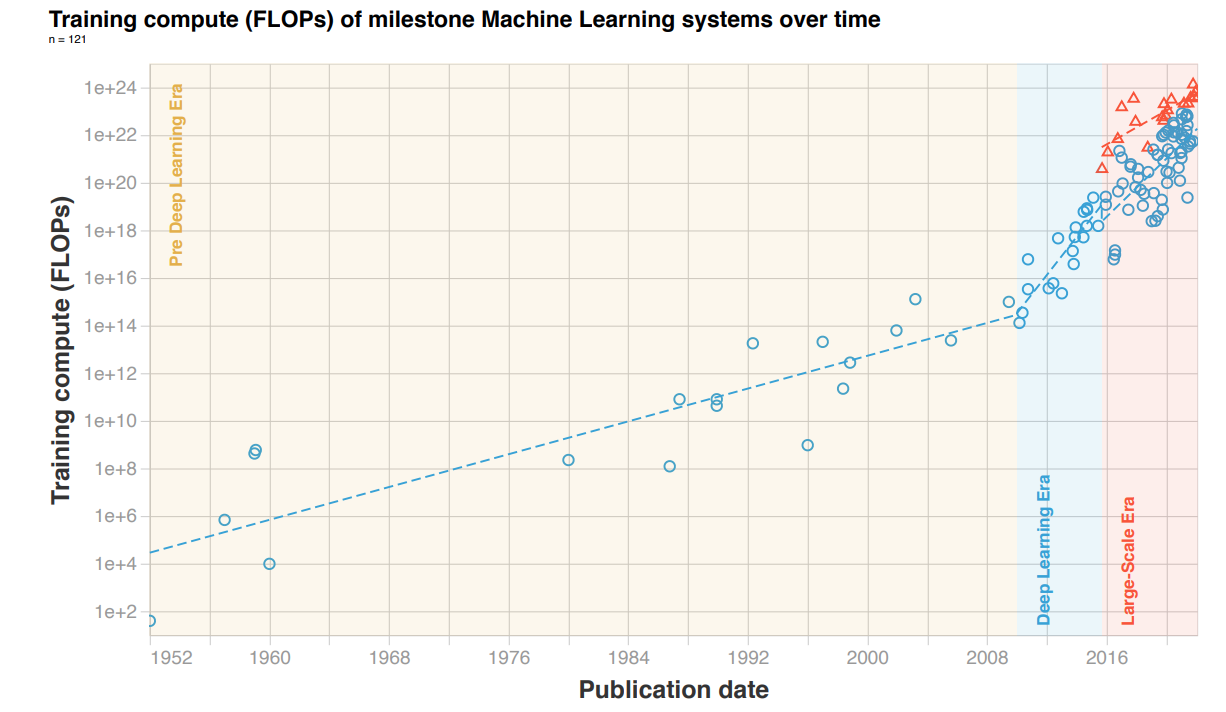
Compute has been growing rapidly since the era of deep learning, although the rate of compute increase for very large scale models appears to be lower. See the graph below, from this paper.
The scaling laws paper showed how compute scaling can drive performance in language modeling, and how this relates to optimal dataset size and length of training. The Chinchilla paper was a good example of using scaling laws to make decisions that resulted in better performance; it achieved superior performance to models trained with a similar amount of compute by reducing the number of parameters and increasing the amount of data.
Analyzing the trajectory of researchers
We have just provided some background on the trajectory of the overall ML field. In this section we will discuss how to analyze the individual trajectories of ML researchers.
Bibliometrics
Citations are not a perfect metric for an individual’s influence on the ML field, and sometimes it is claimed that they are not useful as a metric at all. Of course, not everything of value is captured in citations: whether somebody gives impactful talks, is a good mentor, and so on is not reflected in citations. At the moment, however, there is no alternative set of metrics which better capture true influence and can be scaled up to thousands of people who do not know each other. The ML field at large uses citations as their metric of choice, and this has not prevented the field from being highly competent at advancing capabilities.
h-index (defined as the largest n where the author has at least n papers with n citations) benefits academics who publish many papers, which is not necessarily a good indication of their true influence. A better measure is Semantic Scholar’s Highly Influential Citations, which measures citations that are not cursory (Was the paper cited multiple times? Was the paper cited as “using the method from Doe et al.” instead of just included as background?). Many top industry and top academic researchers are similar by this metric, even though academic researchers output a far higher volume of papers. Top industry researchers publish fewer papers, as industry researchers divide their research into papers differently from academics, but the best industry researchers have a total impact that is not dissimilar from the best academics.
Note that bibliometrics is a metric for influence on the empirical machine learning community. Influence is not perfectly correlated with value: not all papers that influenced the community are that valuable to the community or even those that cited them. However, influence is a good proxy for how much a researcher understands what is used by the community.
Some industry people have many citations, but it’s because they were on a big lab paper. For example, a researcher can do well metric-wise if they are on the tensorflow paper, even though there are several dozen authors on the paper.
Research ability and impact is long tailed
The most impactful researchers in ML, as in other fields, make up the vast majority of the impact in the field overall. Most researchers, even those who are smart and able to publish, have very little impact on the field. For instance, when measuring impact by the number of highly influential citations, about ~4.5 orders of magnitude separate typical PhD students who have published papers so far (~1) and the topmost ML researcher (Kaiming He, who did ResNet and Mask R-CNN, with ~30k). Of course, about 1-2% of applicants to Berkeley’s AI PhD program get in, so we’re describing a large gap between typical middle-stage Berkeley PhD students and top researchers—the gap between top researchers and other researchers without any influential citations is even larger. Even among PhD students at top universities, there is an extremely wide spread: some may graduate with 1,000 highly influential citations while others graduate with just a handful. While there are some 10x engineers, there are ~1,000x researchers (this is an even higher multiple when looking at total citations).
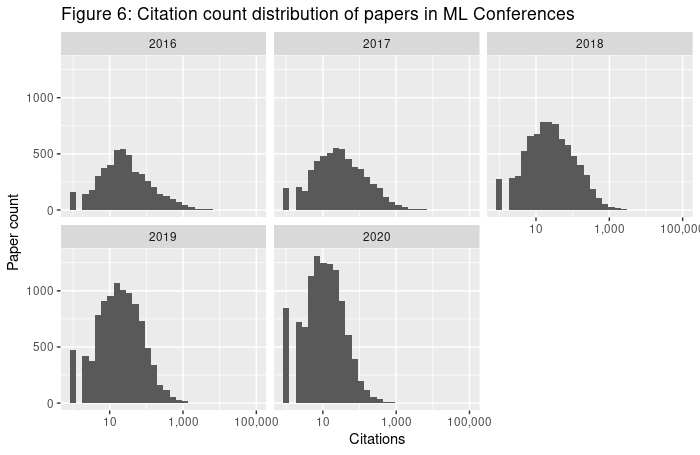
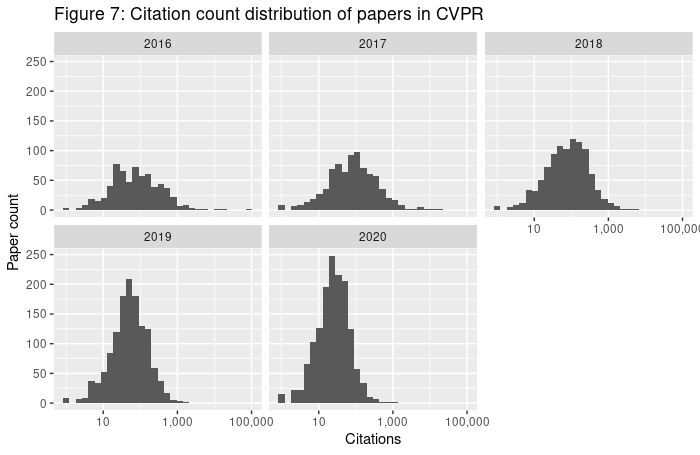
Figure 6 shows citations for papers published at the 12 conferences mentioned in the previous sections. We do not have accessible data on highly-influential citations, so we have to rely on all citations. The distribution of citations for papers is long-tailed. For papers published in 2016, the top 1% of papers accumulated 52.7% of the citations, the top 0.1% of papers accumulated 30.4% of the citations, and the top paper (out of 5155; the Adam paper) received 11.6% of the citations. The bottom 50% of papers accumulated only 2.8% of citations. This is expected for long-tailed distributions. Figure 7 shows the same statistics for CVPR: the skew is not simply due to inter-conference variation.
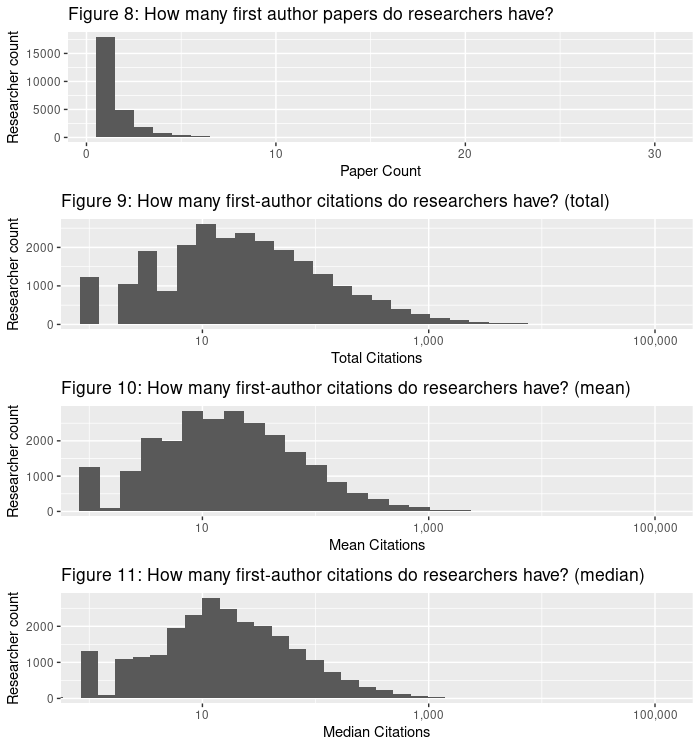
For individual researchers, impact is also extremely skewed (see Figures 8-11). Looking at researchers with at least one first author paper published in a top conference between 2016 and 2020, the top 1% of researchers accumulated 35.5% of citations on first author papers (papers they led research on) in those years, the top 0.1% accumulated 13.6% of citations, and the top researcher (out of 26,381; Kaiming He) accumulated 3.5% of citations. Although there is a skew in the number of papers published, it is comparatively small (less than two orders of magnitude) and it cannot account for the six orders of magnitude between the top researcher and the 1,243 researchers receiving only one citation. Researchers don’t get far more citations simply by publishing more papers.
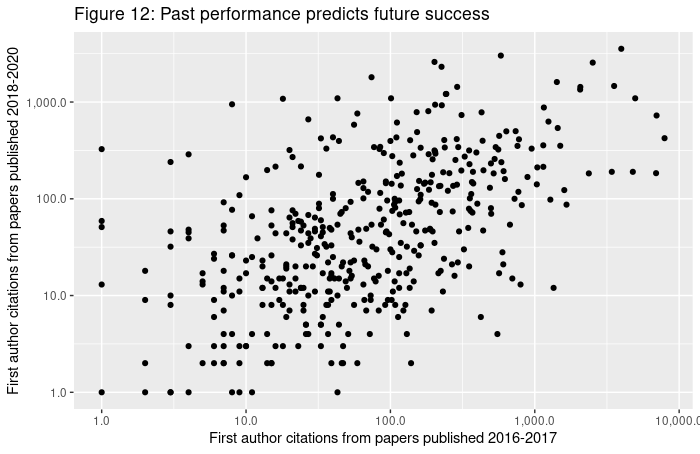
Some of this, of course, is researchers getting lucky and managing to publish a great paper. However, not all success should be dismissed this way. The plot below compares log citations researchers received for first author papers published in top conferences between 2016 and 2017 and papers they published between 2018 and 2020. It only includes researchers who published their first first-author paper in one of these conferences in 2015, so as to control for the effect of seniority. There is a noticeable correlation of 0.55.
Given the vast differences in ability, it makes sense to pay most attention to those who have demonstrated an ability to have extreme impact, since they are likely to capture the vast majority of the impact.
Given this context, it is extremely important to be able to differentiate researchers based on their impact and ability level. For long tail distributions, the impact of the top few papers are able to approximate the sum of the impact of all the papers. Practically, most researchers can be considered to have essentially no impact. Next, we will discuss heuristics for determining which researchers do have impact.
Transfer between paradigms is hard
Creative destruction in ML makes many top researchers no longer effective. Often professors were selected based on skills that used to be needed, but are no longer useful for cutting-edge research. This means that professors with many citations or professors who once made important contributions to the field may no longer be relevant.
For example, some universities are currently lagging behind competitors because they hired a high proportion of traditional ML researchers. However, the skills useful for researching SVMs, Bayesian nonparametrics, and probabilistic graphical models are math, optimization, and statistics. These are not very useful in the context of deep learning. Improving deep learning algorithms comes from messy bottom-up atheoretical empirical tinkering, not precise top-down armchair/whiteboard rational contemplation. The best DL researchers hone their tastes, use their gut, and run many experiments and see what sticks, as it’s very difficult to tell a priori which ideas will improve performance. It’s nearly always faster to run the experiment rather than think about what the result will be, in part because the base rate of methods that actually help is extremely low. Some DL researchers say “good ideas are a dime a dozen” because researchers have to try out many reasonable ideas before one sticks. This doesn’t mean that ideas are unimportant, but it does mean that they are not sufficient. In DL algorithm improvements, a lot of research is governed by underspecified, vague intuitions, while math people tend to resist that and thus have difficulty transferring to deep learning.
Most ML researchers have switched to DL, but most of the top forces of the past are no longer standout forces because their skills have not transferred. However, there is an exception: some older computer vision professors (e.g., Jitendra Malik, Trevor Darrell) are still standout researchers advancing the state-of-the-art; they improved pattern recognition techniques for images and developed skill sets similar to what is needed for deep learning.
The lesson is that extreme accomplishment is quite fragile (see the tails come apart). For example, Michael Jordan (the basketball phenom) wasn’t able to become a top-tier baseball player. Different niches require different skills. Accomplishment is not merely based on general research ability or on intelligence, but also significantly on specialized research ability. An implication is that you can’t take researchers who are highly impactful in one area and by default expect them to be impactful in another area. Given that most ML researchers didn’t transfer well to DL, it is difficult to expect those from further-removed fields to transfer.
This is not to say some people do not have generally transferable abilities. For example, Yann LeCun had a large impact in deep learning, and he also created a notable file compression format. You may see somebody who has been working in a subfield that has suddenly blown up, but was previously not thought to be important. Were they prescient, or just lucky? To answer this, again look for indications of generality. Have they been right in a big way more than once? Have they had an extreme impact in two or more distinct areas? If they’ve demonstrated ability in multiple areas, then that can serve as evidence for transfer ability. As this is so rare, often the best we can do is select people who have demonstrated extreme competence in their specific research area. Next, we will discuss some of the underlying dynamics that may distort researchers’ track records or the quality of their advice.
The Matthew Effect
To those who have, more will be given.
—Matthew 25:29
The Matthew Effect, so named after the biblical verse, is an extremely explanatory dynamic. The visible accomplishments of researchers in a field is highly path-dependent on their initial success early in their careers. Researchers who had some success in grad school, perhaps due to sheer luck, will be more likely to be able to work at a top institution. Once they are there, they will be more likely to be able to recruit better grad students, attain more funding, be invited to more talks, be thought smarter than others, and have their papers read more widely, even if their research is no longer useful. Many professors got unusually lucky (on top of some general level of relatively high competence) and their success became inevitable when they became appointed, even if they do not have extremely high research ability; some could have ended up like a 1 sigma above average research scientist. Similarly, a graduate student who has had a successful paper is more likely to get better advisors, fellowships, access to compute, better collaborators, more citations due to their paper’s Google search ranking, and so on. Success is disproportionately rewarded, and this must be recognized when evaluating researchers or papers.
Suppose a researcher wrote a fundamentally flawed paper that created a temporary “fad” in machine learning. For a couple of years, they managed to gain many collaborators and attach themselves to a large number of well-cited papers even if they were not the intellectual driving force of those papers. Later, they were able to get a management position in an industry lab owing to their status, where they leveraged compute resources and headcount to publish more papers without having much of an intellectual influence on their team. Such a researcher would be highly eminent, even after the initial fad was over, due to their position. However, after correcting for the Matthew Effect, we shouldn’t expect them to have exceptionally high research ability. To fully evaluate research ability, one must divide by the resources available to that researcher, which in this case have been skewed.
Incentives
Whenever interpreting somebody’s beliefs, one must ask how their incentives align with that belief. Researchers, like most people, frequently fall prey to motivated reasoning. Here are some examples of incentives and motivated reasoning:
Researchers who are good at math are incentivized to enjoy theory and think theory is important, because they are better at it. They are also incentivized to characterize rapid, successive empirical advancement as meaningless “benchmark chasing,” or many ML successes are just “glorified pattern matching, curve fitting, and memorization” not addressing “the fundamental problems.” They’re incentivized to work on what they can understand as opposed to work on what performs well; they’re incentivized to search in the space where their mathematics can help, which is not a comparatively large space (this is analogized to the streetlight effect).
Researchers with natural science backgrounds are incentivized to believe that DL is more of a natural science problem than an engineering science problem (this distinction is covered below).
Researchers who don’t have a large research budget are incentivized to believe that scaling and compute is less important, because they are unable to pursue this line of research themselves, and therefore they are incentivized to believe that timelines are longer.
Researchers who have not been able to produce high-quality deep learning research will be more likely to think a paradigm shift needs to happen away from deep learning, because that could be favorable to whatever they’re researching.
Researchers in labs that are currently highly impactful will be less likely to think a paradigm shift needs to happen, because this might throw off their success or make their work irrelevant.
Researchers working in a very specific area are incentivized to believe that their problem will require many more years of research, because they do not want to consider pivoting. They’ll rarely say that their field is almost solved or that something they’re not working on from another subfield will automatically solve it.
Students are incentivized to believe that their advisor’s outdated line of research is important even if there isn’t evidence that there will be any kind of comeback (e.g., convex optimization).
EAs and rationalists are incentivized to believe that the most important research is happening within their communities, because that is where most of their connections are.
Researchers who primarily work on improving general capabilities are incentivized to believe that we don't need to worry about catastrophic risks from AGI, because the alternative is to feel guilt or (possibly at great personal cost) switch research topics.
Grad Students
In ML, grad students at top places (e.g., Berkeley, Stanford, MIT, CMU, …) publish a median of two lead author papers at top conferences, and they typically stay in grad school for 5-6 years. That means they lead one paper around every three years, suggesting the extreme difficulty of doing publishable research. Most grad students at top universities are not particularly good at research; that’s because outcomes are long tailed, and in creative endeavors few do well. These systems are, for better or worse, not egalitarian. It’s important to note that PhD students are not selected based on how good they are at their job (research). While research output in undergrad is considered in PhD admissions, students can be (co-)first authors on great papers merely by being technically adept and working in a high-impact lab. These skills are not enough for PhD students, who must do idea generation of their own. Most of their selection is based on recommendation letters, with some GPA constraints. Since undergrads do not have much of a track record, selection is very noisy. This is also true for fellowships, which are often awarded before applicants can amass a track record with a clear signal.
A few students publish far more than two lead author papers. These students are substantially more visible, leading people to think nearly all graduate students publish many papers. For example, a typical graduate student who becomes a professor at a top university usually has at least 8 papers at the time of graduation, and it’s common for them to have ~10 papers (the current maximum is 18). (Caveat: this describes papers in ICLR, ICML, and NeurIPS; NLP researchers tend to have a somewhat higher count.)
Students are usually heavily influenced by their advisor, and work on topics that their advisor is working on, which is usually what their advisors have grants for. Despite this, at top places students usually don’t get much advising, with some only meeting with their advisor for an hour once a month. Even if students meet with their advisors infrequently, they tend to emulate them in their head while researching. Additionally, students also often learn much from older graduate students and postdocs under their advisor.
Most funding for academic research is from government agencies. It’s common even at top places for profs to have highly restrictive, high-pressure DARPA grants, which functionally restricts what students work on. Awards from industry are rarer and usually quite small (e.g., 50K or 100K, with some exceptions). Meanwhile the median CS NSF grant is very roughly $500K. For reference, in the US, grad students cost ~100K/year (so on average more than half a million throughout their PhD).
AGI and AI Safety
The purpose of understanding the ML field is so that we can make progress on reducing existential risk, so we will now speak specifically about AGI and AI safety. In this section, we only discuss the current state of these topics within the broader ML field, but in the future we will address how progress can be made.
Nearly all ML research is unrelated to safety
At NeurIPS 2021, about ~2% of all the few thousand papers are safety-related (Dan counted manually). From the 2021 NeurIPS call for papers, below, the safety-related keywords are bolded. The vast majority of keywords are not safety related.
General Machine Learning (e.g., classification, unsupervised learning, transfer learning)
Deep Learning (e.g., architectures, generative models, optimization for deep networks)
Reinforcement Learning (e.g., decision and control, planning, hierarchical RL)
Social Aspects of Machine Learning (e.g., AI safety, fairness, privacy, interpretability)
We probably want >30% of all ML research to be safety-related.
How do researchers feel about AGI and AI Safety?
This section is based mainly on Dan’s personal experience. There hasn’t been a survey on experts’ views on AI safety for a while, so personal impressions are the best we have to go on.
Researchers are generally quite technopositive and hope that their work will make a huge positive impact in the world. Much of this tendency is borrowed from the tech industry, which is famously utopian. Likewise, many act as though we must progress towards our predestined technological utopia, and it cannot arrive soon enough. These feelings are amplified in AI because it is perceived to be the next major technological revolution, and researchers want to be part of this.
AI winter made it less acceptable to talk about AGI specifically, and people don’t like people talking about capabilities making it closer. Discussions of AGI are not respectable, unlike in physics where talking about weirder long-term things and extrapolating several orders of magnitude is normal. AGI is a bit more like talking about nuclear fusion, which has a long history of overpromises. In industry it has become somewhat more acceptable to mention AGI than in academia: for instance, Sam Altman recently tweeted “AGI is gonna be wild” and Yann LeCun has recently discussed the path to human-level AI.
In general, the aversion to discussing AGI makes discussing risks from AGI a tough sell.
Moreover, since safety researchers have not contributed many quality works, their contribution to complaint ratio is low, which makes the community fairly unlikable.
Safety and value alignment are generally toxic words, currently. Safety is becoming more normalized due to its associations with uncertainty, adversarial robustness, and reliability, which are thought respectable. Discussions of superintelligence are often derided as “not serious”, “not grounded,” or “science fiction.” Read a debate about safety between Stuart Russell and Yann LeCun here.
Ways ML researchers want to advance capabilities
Below we will detail different paths to capability advancements that are commonly promoted in industry and academia. None of these paths are original, and they’ve all been publicly discussed by non-safety AI researchers.
We need better environments. Humans became intelligent because their environmental conditions incentivized intelligence. The environments currently used to train models frequently do not (for instance, they might instead incentivize memorization, the ability to predict language, or chess-playing ability). In this view, the true bottleneck to intelligence is being able to design diverse environments with the proper incentive structure. DeepMind’s Reward is Enough is an example of this claim, and hypothesizes that all major cognitive abilities, including language and imitation, can arise from “the maximisation of simple rewards in complex environments.” This hypothesis suggests that there will be a surge in the performance of reinforcement learning, which is the most natural paradigm for systems that must interact in environments.
We need a neurosymbolic AI paradigm shift. Some researchers, especially those who are older and have more mathematical inclinations, believe that systems purely based on deep learning will sooner or later hit a wall. They believe that deep learning is merely picking up on correlations, rather than building true causal models, and that explicit structures are needed to attain causal reasoning. We need “quantized, discrete representations.” Since planning in current supervised/self-supervised models is non-explicit and not tested in the real world, you will never be able to ask a model to “build a battery manufacturing plant” and expect it to be successful. This view implies that timelines will be longer, since there will need to be another major paradigm shift before AGI can happen.
Solving math or programming lets us bootstrap intelligence. This rests on the assumption that for certain kinds of tasks, there is an ability level which, after it is reached, allows the agent to rapidly improve itself. Math could be one example of this, because higher-level math can be directly proved from lower-level math just with sufficient logical reasoning skills. In addition, it is relatively easier to verify proofs than it is to generate verifiable proofs, which means that automated checking is possible. Similarly, code generation could also have this property, because complex codebases are built with simple lower-level components. Programming also has more available data than math, and in many cases is even more easily verifiable than math is. The underlying idea is that once the knowledge of math or code generation reaches a certain level, the system can engage in self-play and improve itself. Christian Szegedy, who leads math ML research at Brain, argues that one plausible path towards bootstrapping is autoformalization, where natural language is converted into verifiable mathematical constructs. David McAllester writes that AlphaZero succeeded because it relied on perfect simulation, which is something we can’t have for most tasks (e.g. language). He claims that because we do have a form of perfect simulation in mathematics, this is most likely to be the dominant paradigm. This approach could also potentially be used to bootstrap superintelligence from AGI, in addition to producing AGI.
Just have a bigger model. This view argues that every important capability will arise from a larger and more general upstream multimodal model. Proponents typically point to what they see as increasingly general and compute-intensive progress in vision, language, and RL. The implication is that ideas are less important than capital, engineering expertise, supply chain, and physical infrastructure management. This is appealing to those without top research ability, and it is less appealing for those who have a track record of generating useful ideas. This view frequently makes reference to scaling laws, which show that simply scaling compute, data, and model size is enough for performance increases for transformer models. Richard Sutton’s Bitter Lesson is a more general articulation of this argument: that learning and search based systems relying on computational power have always outperformed systems with more carefully designed inductive biases. However, it’s important to note that Sutton is not simply referring to scaling up compute, but also developing algorithms that effectively exploit compute.
An additional comment on scaling is that perhaps it can take you to average human-level performance, but being superhuman in a domain does not follow. In both humans and ML models, we could imagine a general factor g that helps learners learn tasks more quickly and do better on them. In humans, IQ is a proxy for g; in models, it can be argued that parameter count is a proxy for g (models of larger size converge faster and better). g does not determine all cognitive capabilities. Plenty of people have high IQs but, for all that, they do not automatically have the skills needed to be great researchers, great writers, etc. The argument for scaling may be an argument for general cognitive ability, but this isn’t all you need (it explains some of the variation in human outcomes, but clearly not all).
Lastly, specialized architectures can often vastly outperform more general architectures. MuZero will probably continue to crush very large versions of today’s Transformers at Go. AlphaFold uses far less computational power than the largest Transformer models, but can predict protein structures, a task which more general-purpose Transformers are entirely incapable of. Some problems are better suited for code than neural networks, such as calculators.
Better upstream representations are all that matter and everything else will follow. RL is far too sample inefficient to work well currently, because it typically does not rely on any prior knowledge in building its representation of the environment. We can fix this with self-supervised learning, which can learn the distribution rather than an optimal policy, and can do so with far worse-quality data. In addition, it might be possible to learn a distribution for many environments at once, with minimal fine tuning for individual environments, much as upstream Transformer models are finetuned on individual tasks. Under this view, approaches like the decision Transformer will become more common as we attempt to elicit optimal policies from already-learned distributions rather than explicitly learning optimal policies throughout training. It is frequently assumed that better upstream representations will require better scaling. Eric Jang gives arguments for this view, which is currently popular at Meta AI Research and Google Brain. Yann LeCun also gave a talk on the subject recently.
AGI Timelines
Researchers’ Timelines
In 2016, expert forecasts for human-level AI varied extremely widely, with a median estimate of about 50 years. They forecasted a number of narrow AI milestones beforehand, such as translating languages (2024), autonomous vehicles (2027), and working in retail (2031).
At the MATH AI Workshop 2021 (timestamp 5:32:38), some researchers forecasted how long until an AI is at the level of a human-level mathematician. Yoshua Bengio (one of the pioneers of deep learning and Turing Award winner) predicts a human-level mathematician will be achieved in 10 years. Timothy Gowers (a mathematician and Fields Medalist) said going from math olympiad problems to professional mathematics should be a very quick process and said 20 years in total. Christian Szegedy (a DL researcher, math PhD, Batch Norm creator and adversarial examples discoverer) said 8 years.
For a long list of claims made about AGI timelines, see here. In the most recent decade, peoples’ timelines have usually been decreasing.
Next, we will present arguments for both shorter and longer timelines, representing the most common views in either direction. We do not necessarily believe these arguments.
Arguments for longer timelines
There are three major bottlenecks to AGI, which cannot be resolved with the current deep learning paradigm. As a result, AGI will not arrive until there is a paradigm shift.
Robustness
Robustness is a major problem with deep learning systems, and will need to be resolved before they can be practically useful in cases where extreme reliability is necessary.
We cannot solve robustness by simply trying to make everything in-distribution, for several reasons. First, we cannot sample points from the future, so it is always out-of-distribution. Second, adversarial examples are already in-distribution for adversarially trained models, but Transformers are not adversarially robust. Mere scaling trends will not allow us to reach 99.9% accuracy soon, so extreme reliability is not near.
Despite great progress in deep learning, it still struggles with sequential decision making, which will be necessary for AGI because the most important applications of AGI will need AGI to replace humans over long time horizons, not merely provide them knowledge or information. Likewise, standard reinforcement learning techniques have also progressed quite slowly. Until reinforcement learning or deep learning can learn to do well in sequential decision making, which doesn’t seem to be close, there will not be AGI.
Generality
If you extrapolate performance on MMLU (a multiple choice test spanning 57 subjects including law, physics, medicine, accounting, etc.), it appears that 100x of compute will be necessary to attain full performance. Using this much compute would lead to a wide range of engineering challenges, and the Common Crawl dataset becomes too small to be used.
However, even 100x compute is not enough. We will likely need more compute for autocompletion, rather than just multiple choice selection, and it is plausible that scaling laws will slow down, so we can (charitably) add another 10x. The result of this is that we will need 100 million to 1 billion GPUs. At current costs, this is $1-$10 trillion. We are nowhere close to that level of investment.
Lastly, it’s important to note that in the case of longer timelines we might have far greater ability to solve the essential safety challenges, so we may wish to act as though timelines are longer.
Arguments for shorter timelines
Algorithmic improvements are possible
Arguing for AGI through compute scaling alone is difficult, but we are likely to see large algorithmic improvements. For instance, DeBERTa v2 beats T5, and it's an order of magnitude smaller. DeBERTa v3 exceeds the performance of GPT-3 (finetuned) with 2.5 orders of magnitude fewer parameters. Chinchilla is another example of a massive improvement that did not come from scaling compute. On GSM8K (eighth grade arithmetic word problems), chain of thought and self-consistency methods drive performance from 18% to 75%. The current LM objective (predict the next word/masked words) is extremely simple. Improvements to the objective could potentially yield performance gains at no additional cost.
Bootstrapping could keep progress going
As detailed above, bootstrapping environments like programming and math will allow for rapid improvements driven by the fact that outputs in these areas are easily verifiable. Currently, there does not appear to be danger of an AI winter. Progress in areas like programming, law, medicine, and autonomous vehicles will likely keep investment increasing, which will power additional scaling.
We may be surprised by emergent capabilities
ML has some degree of traction on almost every cognitive task that a person can do, and once the level of an average person has been reached, it will not be long before elite performance is achieved. Emergent capabilities jumps have often appeared at the same time. This pattern may continue, and if it does, we may see sudden changes in many capabilities at once, which could be surprising.
Lastly, it may be better to err on the side of believing in shorter timelines: if we are surprised by capabilities that come faster than expected, this is far worse than if we have surprisingly more time.
Summary
This post has presented a bird’s eye view of many of the most important properties of the machine learning field. To summarize:
Metrics are essential for creating progress in the ML field and are the first step for introducing or growing new subfields.
The researcher does not choose the paradigm; the problem chooses the paradigm. Math cannot solve a problem that isn’t a math problem.
Computer vision and NLP are the largest subfields within ML because they serve as good microcosms for continuous and discrete signals.
Research impact is power-law distributed. Even though all researchers are very smart in the book-learning sense, the very best at research will be far better than the mediocre.
To evaluate the trajectories of experts, consider their track record and incentives, try to correct for the Matthew Effect, and remember that transfer between paradigms is hard.
Relying on a small number of expert individuals to assess new contributions without the test of time has substantial limitations.
There are several possible paths that researchers believe will lead to AGI, including better environments, a neurosymbolic paradigm shift, bootstrapping through math or programming, scaling, and building better upstream representations.
Safety broadly construed is a very small part of the ML community, and most ML researchers do not like to talk about safety.


I found this helpful, thanks for writing.
Likewise.