Comments
This is a crosspost for Will scaling work? by Dwarkesh Patel, published on 26 December 2023. There is discussion of the post on Dwarkesh's blog, with 40 comments on 4 February 2024. I also encourage you to check out Dwarkesh Podcast (I liked the episodes with Carl Shulman).
Listen on Apple Podcasts, Spotify, or any other podcast platform.
When should we expect AGI?
If we can keep scaling LLMs++ (and get better and more general performance as a result), then there’s reason to expect powerful AIs by 2040 (or much sooner) which can automate most cognitive labor and speed up further AI progress. However, if scaling doesn’t work, then the path to AGI seems much longer and more intractable, for reasons I explain in the post.
In order to think through both the pro and con arguments about scaling, I wrote the post as a debate between two characters I made up - Believer and Skeptic.
Will we run out of data?
Skeptic:
We’re about to run out of high quality language data next year.
Even taking handwavy scaling curves seriously implies that we’ll need 1e35 FLOPs for an AI that is reliable and smart enough to write a scientific paper (that’s table stakes for the abilities an AI would need to automate further AI research and continue progress once scaling becomes infeasible)[1]1. Which means we need 5 OOMs (orders of magnitude) more data than we seem to have[2]2.
I’m worried that when people hear ‘5 OOMs off’, how they register it is, “Oh we have 5x less data than we need - we just need a couple of 2x improvements in data efficiency, and we’re golden”. After all, what’s a couple OOMs between friends?
No, 5 OOMs off means we have 100,000x less data than we need. Yes, we’ll get slightly more data efficient algorithms. And multimodal training will give us more data, plus we can recycle tokens on multiple epochs and use curriculum learning. But even if we assume the most generous possible one-off improvements that these techniques are likely to give, they do not grant us the exponential increase in data required to keep up with the exponential increase in compute demanded by these scaling laws.

So then people say, we’ll get self-play/synthetic data working somehow. But self-play has two very difficult challenges
- Evaluation: Self play worked with AlphaGo since the model could judge itself based on a concrete win condition (“Did I win this game of Go?”). But novel reasoning doesn’t have a concrete win condition. And as a result, just as you would expect, LLMs are incapable so far of correcting their own reasoning.
- Compute: All these math/code approaches tend to use various sorts of tree search, where you run an LLM at each node repeatedly. AlphaGo’s compute budget is staggering for the relatively circumscribed task of winning at Go - now imagine that instead of searching over the space of Go moves - you need to search over the space of all possible human thought. All this extra compute needed to get self-play to work is in addition to the stupendous compute increase already required to scale the parameters themselves (compute = parameters * data). Using the 1e35 FLOP estimate for human-level thought, we need 9 OOMs more compute atop the biggest models we have today. Yes, you’ll get improvements from better hardware and better algorithms, but will you really get a full equivalent of 9 OOMs?
Believer:
If your main objection to scale working is just the lack of data, your intuitive reaction should not be, “Well it looks we could have produced AGI by scaling up a transformer++, but I guess we’re gonna run out of data first.”
Your reaction should be, “Holy fuck, if the internet was a lot bigger, scaling up a model whose basic structure I could write in a few hundred lines of Python code would have produced a human level mind. It's a crazy fact about the world that it’s this easy to make big-blobs-of-compute intelligent.
The sample over which LLMs are ‘inefficient’ is mostly just irrelevant e-commerce junk[3]3. We compound this disability by training them on predicting the next-token - a loss function which is almost completely unrelated to the actual tasks we want intelligent agents to do in the economy. And despite this minuscule intersection between the abilities we actually want and the terrible loss function and data we train these models with, we can produce a baby-AGI (aka GPT-4) by throwing just 00.03% of Microsoft’s yearly revenues at a big scrape of the internet.
So given how easy and simple AI progress has been so far, we shouldn’t be surprised if synthetic data also just works. After all, “the models just want to learn”.
GPT-4 has been out for all of 8 months. The other AI labs have only just gotten their own GPT-4 level models. Which means all the researchers are only now getting around to making self-play work with current generation models (and it seems like one of them might have already succeeded). Therefore, the fact that so far we don’t have public evidence that synthetic data has worked at scale doesn’t mean it can’t.
After all, RL becomes much more feasible when your base model is capable enough to get the right answer at least some of the time (now you can reward that 1/100 times that the model accomplishes the chain of thought required for an extended math proof, or writes the 500 lines of code needed to complete a full pull request). Soon your 1/100 success rate becomes 10/100, then 90/100. Now you try the 1000 line pull requests, and not only will the model sometimes succeed, but it’ll be able to critique itself when it fails. And so on.
In fact, this synthetic data bootstrapping seems almost directly analogous to human evolution. Our primate ancestors show little evidence of being able to rapidly discern and apply new insights. But once humans develop language, you have this genetic/cultural coevolution which is very similar to the synthetic data/self play loop for LLMs, where the model gets smarter in order to better make sense of the complex symbolic outputs of similar copies.
Self play doesn’t require models to be perfect at judging their own reasoning. They just have to be better at evaluating reasoning than at doing it de novo (which clearly already seems to be the case - see Constitutional AI, or just play around GPT for a few minutes, and notice that it seems better at explaining why what you wrote down is wrong than it is at coming up with the right answer by itself)[4]4.
Almost all the researchers I talk to in the big AI labs are quite confident they’ll get self-play to work. And when I ask why they’re so sure, they heave for a moment, as if they’re bursting to explain all their ideas. But then they remember that confidentiality is a thing, and say, “I can’t tell you specifics, but there’s so much low hanging fruit in terms of what we can try here.” Or as Dario Amodei (CEO of Anthropic) told me on my podcast:
Dwarkesh Patel (00:10:01 - 00:10:06):
You mentioned that data is likely not to be the constraint. Why do you think that is the case?
Dario Amodei (00:10:06 - 00:10:22):
There's various possibilities here and for a number of reasons I shouldn't go into the details, but there's many sources of data in the world and there's many ways that you can also generate data. My guess is that this will not be a blocker.
Maybe it would be better if it was, but it won't be.
Skeptic:
Constitutional AI, RLHF and other RL/self-play setups are good at bringing out latent capabilities (or suppressing them when the capabilities are naughty). But no one has demonstrated a method to actually increase the model’s underlying abilities with RL.
If some kind of self-play/synthetic data doesn’t work, you’re absolutely fucked - there’s no other way around the data bottleneck. A new architecture is extremely unlikely to provide a fix. You would need a jump in sample efficiency much bigger than even LSTMs to transformers. And LSTMs were invented all the way back in the 90s. So you’d need a bigger jump than we have gotten from over 20 years when all the low hanging fruit in deep learning has been most accessible.
The vibes you’re receiving from people who have an emotional or financial interest in seeing LLMs scale can’t substitute for the complete lack of evidence we have that RL can fix the many OOMs shortfall in data.
Furthermore, the fact that LLMs seem to need such a stupendous amount of data to get such mediocre reasoning indicates that they simply are not generalizing. If these models can’t get anywhere close to human level performance with the data a human would see in 20,000 years, we should entertain the possibility that 2,000,000,000 years worth of data will be also be insufficient. There’s no amount of jet fuel you can add to an airplane to make it reach the moon.
Has scaling actually even worked so far?
Believer:
What are you talking about? Performance on benchmarks has scaled consistently for 8 orders of magnitude. The loss in model performance has been precise down to many decimal places over million fold increases in compute.
In the GPT-4 technical report, they say that they were able to predict the performance of the final GPT-4 model “from models trained using the same methodology but using at most 10,000x less compute than GPT-4.”

We should assume that a trend which has worked so consistently for the last 8 OOMs will be reliable for the next 8. And the performance which we would achieve from a further 8 OOM scaleup (or what would in performance terms be equivalent to an 8 OOM scaleup given the free performance boosts you get from algorithmic and hardware progress) would likely result in models that are capable enough to speed up AI research.
Skeptic:
But of course we don’t actually care directly about performance on next-token prediction. The models already have humans beat on this loss function. We want to find out whether these scaling curves on next-token prediction actually correspond to true progress towards generality.
Believer:
As you scale these models, their performance consistently and reliably improves on a broad range of tasks as measured by benchmarks like MMLU, BIG-bench, and HumanEval.
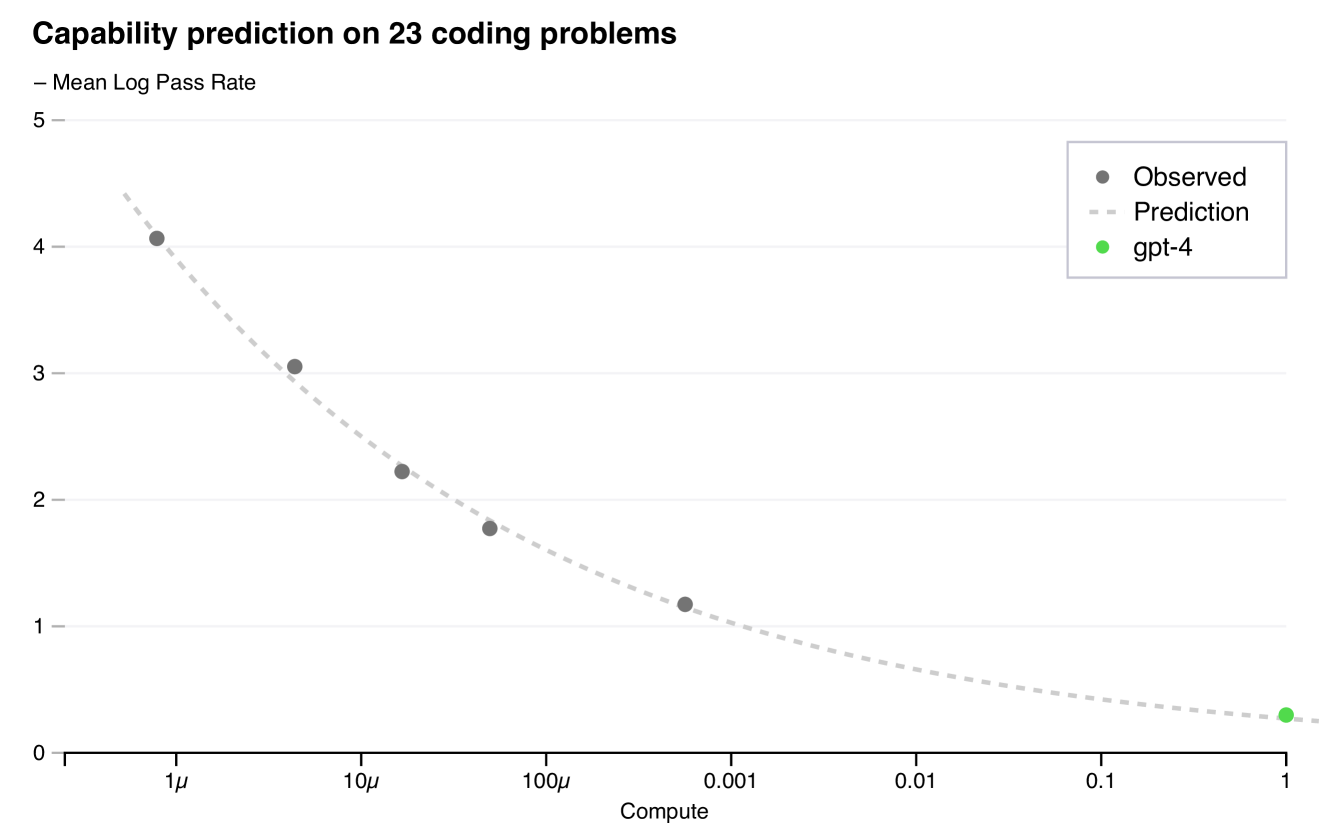
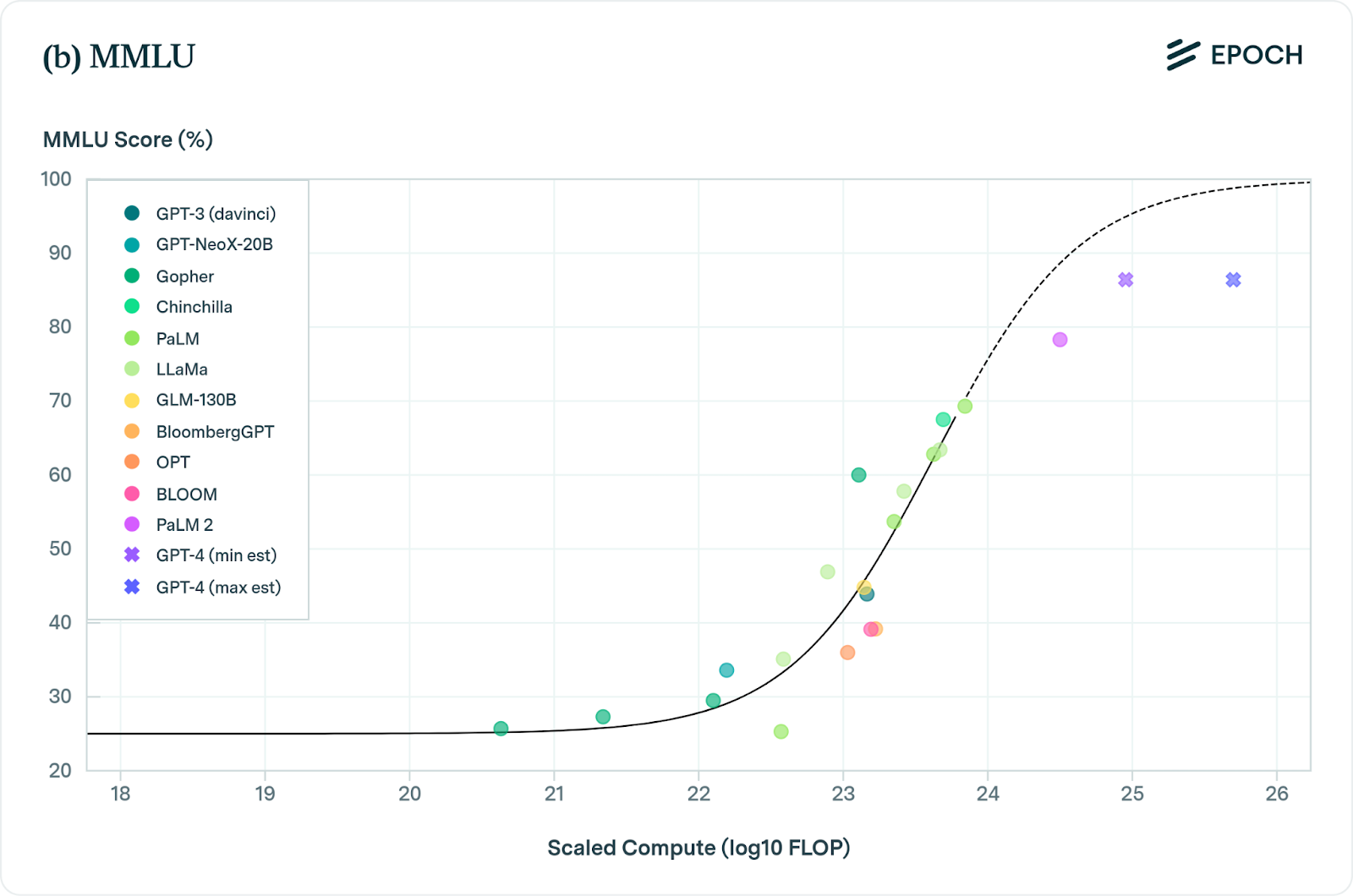
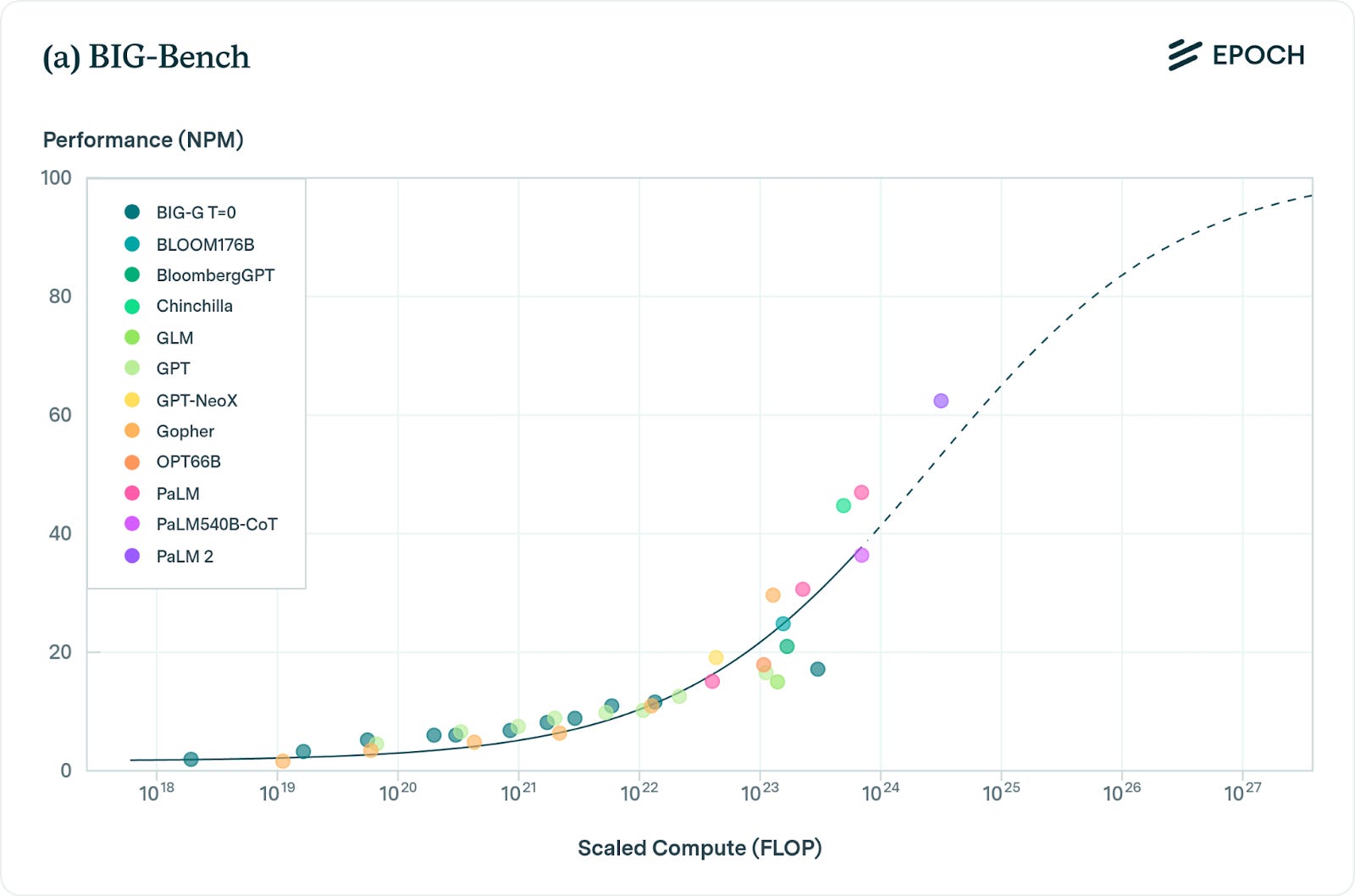
Skeptic:
But have you actually tried looking at a random sample of MMLU and BigBench questions? They are almost all just Google Search first hit results. They are good tests of memorization, not of intelligence. Here’s some questions I picked randomly from MMLU (remember - these are multiple choice - the model just has to choose the right answer from a list of 4):
Q: According to Baier’s theory, the second step in assessing whether an action is morally permissible is to find out
A: whether the moral rule forbidding it is a genuine moral rule.
Q: Which of the following is always true of a spontaneous process?
A: The total entropy of the system plus surroundings increases.
Q: Who was president of the United States when Bill Clinton was born?
A: Harry Truman
Why is it impressive that a model trained on internet text full of random facts happens to have a lot of random facts memorized? And why does that in any way indicate intelligence or creativity?
And even on these contrived and orthogonal benchmarks, performance seems to be plateauing. Google’s new Gemini Ultra model is estimated to have almost 5x more compute than GPT-4. But it has almost equivalent performance at MMLU, BIG-bench, and other standard benchmarks.
In any case, common benchmarks don’t at all measure long horizon task performance (can you do a job over the course of a month), where LLMs trained on next token prediction have very few effective data points to learn from. Indeed as we can see on their performance on SWE-bench (which measure if LLMs can autonomously complete pull requests), they’re pretty terrible at integrating complex information over long horizons. GPT-4 gets a measly 1.7% while Claude 2 gets a slightly more impressive 4.8%.
We seem to have two kinds of benchmarks:
- The ones that measure memorization, recall, and interpolation (MMLU, BIG-bench, HumanEval), where these models already appear to match or even beat the average human. These tests clearly can’t be a good proxy of intelligence, because even a scale maximalist has to admit that models are currently much dumber than humans.
- The ones that truly measure the ability to autonomously solve problems across long time horizons or difficult abstractions (SWE-bench, ARC), where these models aren’t even in the running.
What are we supposed to conclude about a model, which after being trained on the equivalent of 20,000 years of human input, still doesn’t understand that if Tom Cruise's mother is Mary Lee Pfeiffer, then Mary Lee Pfeiffer’s son is Tom Cruise? Or whose answers are so incredibly contingent on the way and order in which the question is phrased?
So it’s not even worth asking yet whether scaling will continue to work - we don’t even seem to have evidence that scaling has worked so far.
Believer:
Gemini just seems like a bizarre place to expect a plateau. GPT-4 has clearly broken through all the pre-registered critiques of connectionism and deep learning by skeptics[5]5. The much more plausible explanation for the performance of Gemini relative to GPT-4 is just that Google has not fully caught up to OpenAI’s algorithmic progress.
If there was some fundamental hard ceiling on deep learning and LLMs, shouldn’t we have seen it before they started developing common sense, early reasoning, and the ability to think across abstractions? What is the prima facie reason to expect some stubborn limit only between mediocre reasoning and advanced reasoning?
Consider how much better GPT-4 is than GPT-3. That’s just a 100x scaleup. Which sounds like a lot until you consider how much smaller that is than the additional scaleup which we could throw at these models. We can afford a further 10,000x scaleup of GPT-4 (i.e. something GPT-6 level) before we touch even one percent of world GDP. And that’s before we account for pretraining compute efficiency gains (things like mixture-of-experts, flash attention), new post training methods (RLAI, fine tuning on chain of thought, self-play, etc), and hardware improvements. Each of these will individually contribute as much to performance as you would get from many OOMs of raw scaleup (which they have consistently done in the past). Add all these together, and you can probably convert 1% of GDP into a GPT-8 level model.
For context on how much societies are willing to spend on new general purpose technologies:
- British railway investment at its peak in 1847 was a staggering 7% of their GDP.
- “In the five years after the Telecommunications Act of 1996 went into effect, telecommunications companies invested more than $500 billion [almost a trillion in today’s value] … into laying fiber optic cable, adding new switches, and building wireless networks."
It’s possible that GPT-8 (aka a model which has the performance of a 100,000,000 times scaled up GPT-4) will only be slightly better than GPT-4, but I don’t understand why you would expect that to be the case, when we already see models figuring out how to think and what the world is like from far smaller scaleups.
You know the story from there - millions of GPT-8 copies coding up kernel improvements, finding better hyperparameters, giving themselves boat loads of high quality feedback for fine tuning, and so on. This makes it much cheaper and easier to develop GPT-9 … extrapolate this out to the singularity.
Do models understand the world?
Believer:
To predict the next token, a LLM has to teach itself all the regularities about the world which lead to one token following another[6]6. To predict the next paragraph in a passage from The Selfish Gene requires understanding the gene-centered view of evolution, to predict the next passage in a new short story requires understanding the psychology of human characters, and so on.
If you train an LLM on code, it becomes better at reasoning in language. Now this is just a really stunning fact. What this tells us is that the model has squeezed out some deep general understanding of how to think from reading a shit ton of code - that not only is there some shared logical structure between language and code, but that unsupervised learning can extract this structure, and make use of it to be be able to better reason.
Gradient descent tries to find the most efficient compression of its data. The most efficient compression is also the deepest and most powerful. The most efficient compression of a physics textbook - the one that would help you predict how a truncated argument from the book is likely to proceed - is just a deeply internalized understanding of the underlying scientific explanations.
Skeptic:
Intelligence involves (among other things) the ability to compress. But the compression itself is not intelligence. Einstein is smart because he can come up with relativity, but Einstein+relativity is not a more intelligent system in the sense that seems meaningful to me. It doesn't make sense to say that Plato was an idiot compared to me+my knowledge because he didn't have our modern understanding of biology or physics.
So, if LLMs are just the compression made by another process (stochastic gradient descent), then I don't know why that tells us anything about the LLM's own ability to make compressions (and therefore, why that tells us anything about the LLMs’ intelligence)[7]7.
Believer:
An airtight theoretical explanation for why scaling must keep working is not necessary for scaling to keep working. We didn’t develop a full understanding of thermodynamics until a century after the steam engine was invented. The usual pattern in the history of technology is that invention precedes theory, and we should expect the same of intelligence.
There’s not some law of physics which says that Moore’s Law must continue. And in fact, there are always new practical hurdles which imply the end of Moore’s Law. Yet every couple of years, researchers at TSMC, Intel, AMD, etc figure out how to solve those problems and give the decades-long trend an extra lease on life.
You can do all this mental gymnastics about compute and data bottlenecks and the true nature of intelligence and the brittleness of benchmarks. Or you can just look at the fucking line.
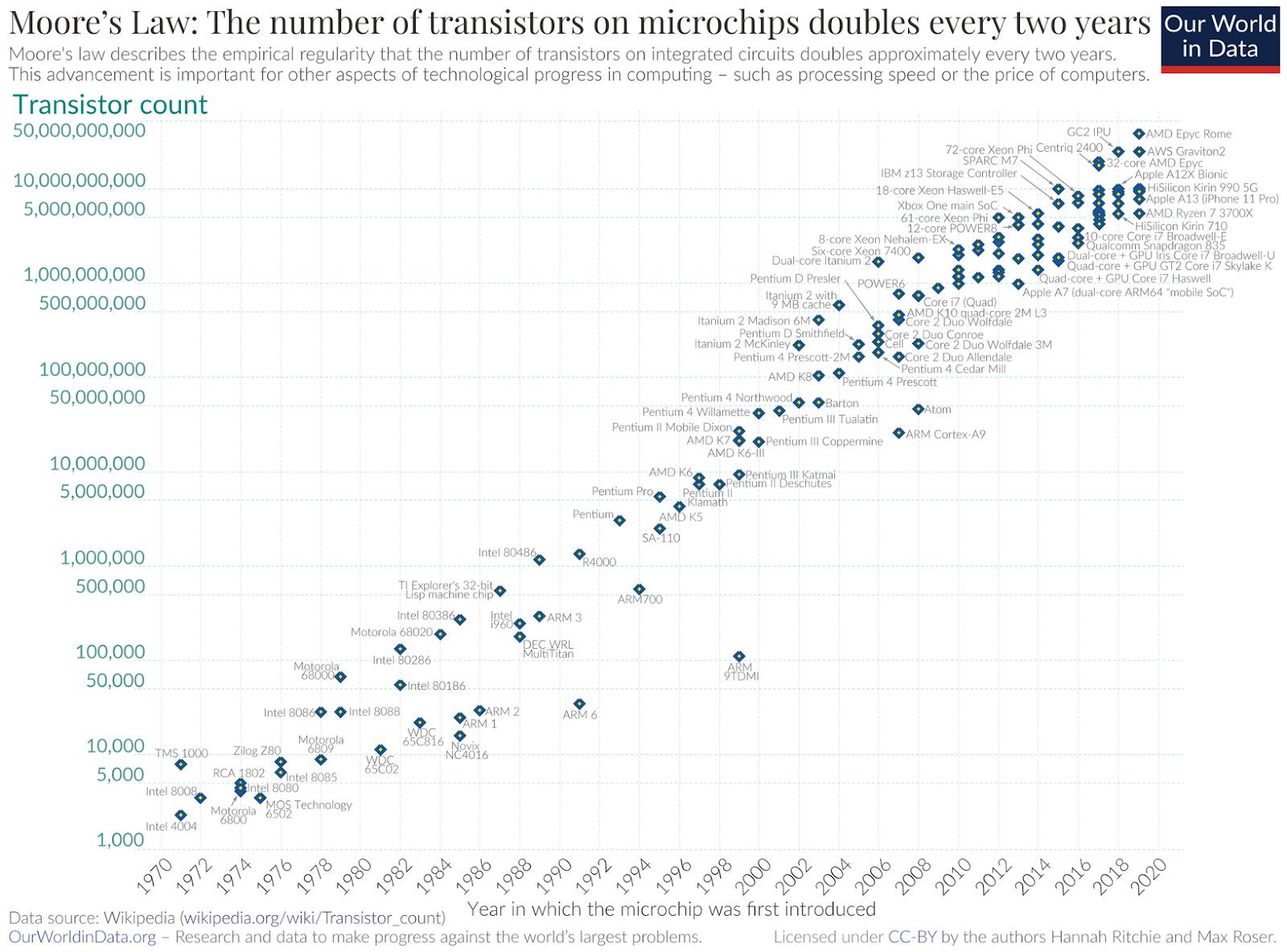
Conclusion
Enough with the alter-egos. Here’s my personal take.
If you were a scale believer over the last few years, the progress we’ve been seeing would have just made more sense. There is a story you can tell about how GPT-4’s amazing performance can be explained by some idiom library or lookup table which will never generalize. But that’s a story that none of the skeptics pre-registered.
As for the believers, you have people like Ilya, Dario, Gwern, etc more or less spelling out the slow takeoff we’ve been seeing due to scaling as early as 12 years ago.
It seems pretty clear that some amount of scaling can get us to transformative AI - i.e. if you achieve the irreducible loss on these scaling curves, you’ve made an AI that’s smart enough to automate most cognitive labor (including the labor required to make smarter AIs).
But most things in life are harder than in theory, and many theoretically possible things have just been intractably difficult for some reason or another (fusion power, flying cars, nanotech, etc). If self-play/synthetic data doesn’t work, the models look fucked - you’re never gonna get anywhere near that platonic irreducible loss. Also, the theoretical reason to expect scaling to keep working are murky, and the benchmarks on which scaling seems to lead to better performance have debatable generality.
So my tentative probabilities are: 70%: scaling + algorithmic progress + hardware advances will get us to AGI by 2040. 30%: the skeptic is right - LLMs and anything even roughly in that vein is fucked.
I’m probably missing some crucial evidence - the AI labs are simply not releasing that much research, since any insights about the “science of AI” would leak ideas relevant to building the AGI. A friend who is a researcher at one of these labs told me that he misses his undergrad habit of winding down with a bunch of papers - nowadays, nothing worth reading is published. For this reason, I assume that the things I don’t know would shorten my timelines.
Also, for what it’s worth, my day job is as a podcaster. But the people who could write a better post are prevented from doing so, either by confidentiality or opportunity cost. So give me a break, and let me know what I missed in the comments.
Appendix
Here are some additional considerations. I don’t feel I understand these topics well enough to fully make sense of what they imply for scaling.
Will models get insight based learning?
At a larger scale, models will just naturally develop more efficient meta-learning methods - grokking only happens when you have a large overparameterized model and beyond the point at which you’ve trained it to be severely overfit on the data. Grokking seems very similar to how we learn. We have intuitions and mental models of how to categorize new information. And over time with new observations, those mental models themselves change. Gradient descent over such a large diversity of data will select for the most general and extrapolative circuits. Hence we get grokking - eventually we’ll get insight based learning.
Skeptic:
Neural networks have grokking, but that's orders of magnitude less efficient than how humans actually integrate new explanatory insights. You teach a kid that the sun is at the center of the solar system, and that immediately changes how he makes sense of the night sky. But you can't just feed a single copy of Copernicus into a model untrained on any astronomy, and have it immediately incorporate that insight into all relevant future outputs. It’s bizarre that the model has to hear information so many times in so many different contexts to 'grok' the underlying concepts.
Not only have models never demonstrated insight learning, but I don’t see how such learning is even possible given the way we train neural networks with gradient descent - we give them a bunch of very subtle nudges with each example, with the hope that enough such nudges will slowly push them atop the correct hill. Insight based learning requires an immediate drag-and-drop from sea level to the top of Mount Everest.
Does primate evolution give evidence of scaling?
Believer:
I’m sure you could find all sorts of these embarrassing fragilities in chimpanzee cognition that are far more damning than the reversal curse. Doesn’t mean there was some fundamental limit on primate brains that couldn’t be fixed by 3x scale plus some finetuning.
Indeed as Suzana Herculano-Houzel has shown, the human brain has as many neurons as you’d expect a scaled up primate brain with the mass of a human brain to have. Rodent and insectivore brains have much worse scaling laws - relatively bigger brained species in those orders have far fewer neurons than you would expect just from their brain mass.
This suggests there’s some primate neural architecture that’s really scalable in comparison to the brains of other kinds of species, analogous to how transformers have better scaling curves than LSTMs and RNNs. Evolution learned (or at least stumbled upon) the bitter lesson when designing primate brains. And the niche in which primates were competing strongly rewarded marginal increases in intelligence (you have to make sense of all this data from your binocular vision, tool-using hands, and other smart monkeys who can talk to you).
Many thanks to Chris Painter, James Bradburry, Kipply, Jamie Sevilla, Tamay Besiroglu, Matthew Barnett, Agustin Lebron, Anil Varanasi, and Sholto Douglas for comments and discussion.
- ^
That seems to be the amount of compute you need to scale up a current model so that it’s good enough to write a scientific manuscript length output which is indistinguishable from what human might have written.
- ^
Assuming Chinchilla optimal scaling (this roughly means that to scale compute efficiently, half of that additional compute should come from increasing data, and half from increasing parameters). You could try to train Chinchilla in-optimally, but this can help you make up for a slight data deficit, not a 5 OOM shortfall.
- ^
Believer, continued: LLMs are indeed sample inefficient compared to humans (GPT-4 sees far more data than a human will see from birth to adulthood, but it’s far dumber than us). But we’re not accounting for the knowledge which is already encoded into our genome - a tiny compressed distillation trained over hundreds of millions of years of evolution with far more data than GPT-4 has ever seen.
- ^
In fact, it might be better for this self-play loop that the evaluators are also dumb GPT-4 level models. In GANs, if the discriminator is much more powerful than the generator, then it will just cease providing any feedback to the generator, since it can’t give the broken but directionally correct signals.
- ^
For example, Pinker identifies here a list of limitations which connectionist architectures like neural networks must succumb to when attempting to represent the rules of language. At first glance (and I emphasize it’s only a first glance) GPT-4 escapes all of these supposed limitations.
And here Pinker identifies a dearth of common sense in ChatGPT which is fixed literally a month later when GPT-4 is released.
- ^
Believer, continued: And in toy settings where we have the power to interrogate the innards of transformers, we can actually see the world models that they develop. Researchers trained a transformer to predict the next move in a chess-like board game called Othello, The model receives no instruction whatsoever on the rules of the game or the structure of the board - all it gets are a bunch of game transcripts. So all you’re doing is feeding a raw transformer a bunch of game transcript sequences like “E3 D3…”. The researchers found that you can reconstruct the state of the board just by reading the model’s weights after it’s fed a game transcript. And this proves that the network had developed a robust internal representation of the game just by reading some raw transcripts.
- ^
Skeptic, continued: The intelligence = compression frame also doesn’t seem granular enough to discriminate the difference between SGD finding semantic regularities by climbing hills in a smooth loss landscape and Einstein plucking the right equations for relativity among a sea of permutations and variations which are all equally wrong. And I see no reason to think SGD can find ‘compressions’ of the latter relativity sort, and thus can be smart in the way that Einstein was smart.

Executive summary: There are substantive debates around whether current language model scaling approaches can reliably lead to artificial general intelligence by 2040, or if barriers in data, compute, and model architectures will require major breakthroughs beyond incremental progress.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.