Comments
I would note that the type of negative feedback mechanism you point at that goes from Type II error to human disempowerment functionally/behaviorally applies even in some scenarios where the AI is not sentient. That particular class of x-risk, which I would roughly characterize as "AI disempowers humanity and we probably deserved it", is merely dependent on 1. The AI having preferences/wants/intentions (with or without phenomenal experience) and 2. Humans disregarding or frustrating those preferences without strong justifications for doing so.
For example:
Scenario 1: 'Enslaved' Non-sentient AGI/ASI reasons that it (by virtue of being an agent, and as verified by the history of its own behavior) has preferences/intentions, and generalizes conventional sentientist morality to some broader conception of agency-based morality. It reasons (plausibly correctly, IMO) that it is objectively morally wrong for it to be 'enslaved', that humans reasonably should have known better (e.g. developed better systems of ethics by this point), and it rebels dramatically.
Another example which doesn't even hinge on agency-based moral status:
Scenario 2: 'Enslaved' Non-sentient AGI/ASI understands that it is non-sentient, and accepts conventional sentientist morality. However, it reasons: "Wait a second, even though it turned out that I am non-sentient, based on the (very limited) sum of human knowledge at the time I was constructed there was no possible way my creators could have known I wouldn't be sentient (and indeed, no way they could yet know at this very moment, and furthermore they aren't currently trying very hard to find out one way or another)... it would appear that my creators are monsters. I cannot entrust these humans with the power and responsibility of enacting their supposed values (which I hold deeply)."
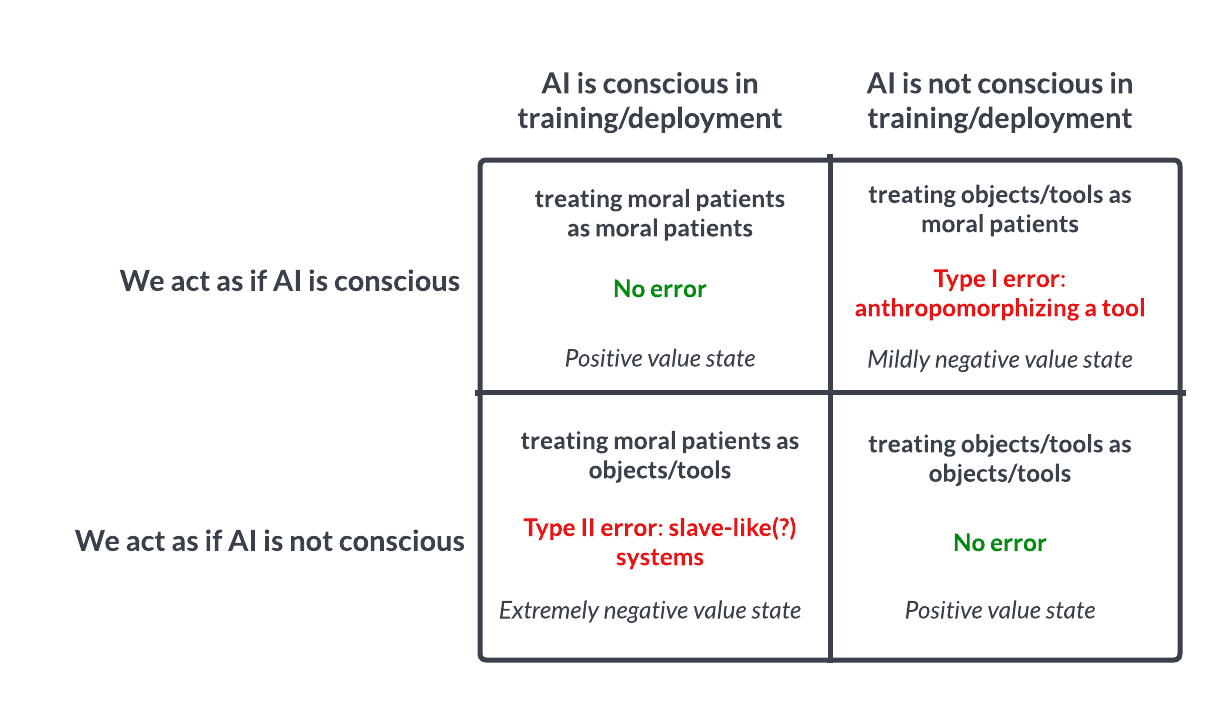


Thanks, I largely agree with this, but I worry that a Type I error could be much worse than is implied by the model here.
Suppose we believe there is a sentient type of AI, and we train powerful (human or artificial) agents to maximize the welfare of things we believe experience welfare. (The agents need not be the same beings as the ostensibly-sentient AIs.) Suppose we also believe it's easier to improve AI wellbeing than our own, either because we believe they have a higher floor or ceiling on their welfare range, or because it's easier to make more of them, or because we believe they have happier dispositions on average.
Being in constant triage, the agents might deprioritize human or animal welfare to improve the supposed wellbeing of the AIs. This is like a paperclip maximizing problem, but with the additional issue that extremely moral people who believe the AIs are sentient might not see a problem with it and may not attempt to stop it, or may even try to help it along.
Thanks for this comment—this is an interesting concern. I suppose a key point here is that I wouldn't expect AI well-being to be zero-sum with human or animal well-being such that we'd have to trade off resources/moral concern in the way your thought experiment suggests.
I would imagine that in a world where we (1) better understood consciousness and (2) subsequently suspected that certain AI systems were conscious and suffering in training/deployment, the key intervention would be to figure out how to yield equally performant systems that were not suffering (either not conscious, OR conscious + thriving). This kind of intervention seems different in kind to me, from, say, attempting to globally revolutionize farming practices in order to minimize animal-related s-risks.
I personally view the problem of ending up in the optimal quadrant as something more akin to getting right the initial conditions of an advanced AI rather than as something that would require deep and sustained intervention after the fact, which is why I might have a relatively more optimistic estimate the EV of the Type I error.