I generally agree that the formal thesis for the debate week set a high bar that is difficult to defend and I think that this is a good statement of the case for that. Even if you think that AI welfare is important (which I do!), the field doesn't have the existing talent pipelines or clear strategy to absorb $50 million in new funding each year. Putting that much in over the next few years could easily make things worse. It is also possible that AI welfare has the potential for non-EA money and it should aim for that rather than try to take money that would otherwise go to EA cause areas.
That said, there are other points that I disagree with:
It is not good enough to simply say that an issue might have a large scale impact and therefore think it should be an EA priority, it is not good enough to simply defer to Carl Shulman's views if you yourself can't argue why you think it's "pretty likely... that there will be vast numbers of AIs that are smarter than us" and why those AIs deserve moral consideration.
I think that this is wrong. The fact that something might have a huge scale and we might be able to do something about it is enough for it to be taken seriously and provides prima facie evidence that it should be a priority. I think it is vastly preferrable to preempt problems before they occur rather than try to fix them once they have. For one, AI welfare is a very complicated topic that will take years or decades to sort out. AI persons (or things that look like AI persons) could easily be here in the next decade. If we don't start thinking about it soon, then we may be years behind when it happens.
AI people (of some form or other) are not exactly a purely hypothetical technology, and the epistemic case for them doesn't seem fundamentally different from the case for thinking that AI safety will be an existential issue in the future, that the average intensively farmed animal leads a net-negative life, or that any given global health intervention won't have significant unanticipated negative side effects. We're dealing with deep uncertainties no matter what we do.
Additionally, it might be much harder to try to lobby for changes once things have gone wrong.
I wish some groups were actively lobbying against intensified animal agriculture in the 1930s (or the 1880s). It may not have been tractable. It may not have been clear, but it may have been possible to outlaw some terrible practices before they were adopted. We might have that opportunity now with AI welfare. Perhaps this means that we only need a small core group, but I do think some people should make it a priority.
> It is not good enough to simply say that an issue might have a large scale impact and therefore think it should be an EA priority [...]
I think that this is wrong. The fact that something might have a huge scale and we might be able to do something about it is enough for it to be taken seriously and provides prima facie evidence that it should be a priority. I think it is vastly preferrable [sic] to preempt problems before they occur rather than try to fix them once they have. For one, AI welfare is a very complicated topic that will take years or decades to sort out. AI persons (or things that look like AI persons) could easily be here in the next decade. If we don't start thinking about it soon, then we may be years behind when it happens.
I feel like you are talking past the critique. For an intervention to be a longtermist priority, there needs to be some kind of story for how it improves the long-term future. Sure, AI welfare may be a large-scaled problem which takes decades to sort out (if tackled by unaided humans), but that alone does not mean it should be worked on presently. Your points here do not engage with the argument, made by @Zach Stein-Perlman early on in the week, that we can just punt solving AI welfare to the future (i.e., to the long reflection / to once we have aligned superintelligent advisors), and in the meantime continue focusing our resources on AI safety (i.e., on raising the probability that we make it to a long reflection).
(There is an argument going in the opposite direction that a long reflection might not happen following alignment success, and so doing AI welfare work now might indeed make a difference to what gets locked in for the long-term. I am somewhat sympathetic to this argument, as I wrote here, but I still don’t think it delivers a knockdown case for making AI welfare work a priority.)
Likewise, for an intervention to be a neartermist priority, there has to be some kind of quantitative estimate demonstrating that it is competitive—or will soon be competitive, if nothing is done—in terms of suffering prevented per dollar spent, or similar, with the current neartermist priorities. Factory farming seems like the obvious thing to compare AI welfare against. I’ve been surprised by how nobody has tried coming up with such an estimate this week, however rough. (Note: I’m not sure if you are trying to argue that AI welfare should be both a neartermist and longtermist priority, as some have.)
(Note also: I’m unsure how much of our disagreement is simply because of the “should be a priority” wording. I agree with JWS’s current “It is not good enough…” statement, but would think it wrong if the “should” were replaced with “could.” Similarly, I agree with you as far as: “The fact that something might have a huge scale and we might be able to do something about it is enough for it to be taken seriously.”)
[ETA: On a second read, this comment of mine seems a bit more combative than I intended—sorry about that.]
For an intervention to be a longtermist priority, there needs to be some kind of concrete story for how it improves the long-term future.
I disagree with this. With existential risk from unaligned AI, I don't think anyone has ever told a very clear story about how AI will actually get misaligned, get loose, and kill everyone. People have speculated about components of the story, but generally not in a super concrete way, and it isn't clear how standard AI safety research would address a very specific disaster scenario. I don't think this is a problem: we shouldn't expect to know all the details of how things go wrong in advance, and it is worthwhile to do a lot of preparatory research that might be helpful so that we're not fumbling through basic things during a critical period. I think the same applies to digital minds.
Your points here do not engage with the argument, made by @Zach Stein-Perlman early on in the week, that we can just punt solving AI welfare to the future (i.e., to the long reflection / to once we have aligned superintelligent advisors), and in the meantime continue focusing our resources on AI safety (i.e., on raising the probability that we make it to a long reflection).
I think this viewpoint is overly optimistic about the probability of locking in / the relevance of superintelligent advisors. I discuss some of the issues of locking in in a contribution to the debate week. In brief, I think that it is possible that digital minds will be sufficiently integrated in the next few decades that they will have power in social relationships that will be extremely difficult to disentangle. I also think that AGI may be useful in drawing inferences from our assumptions, but won't be particularly helpful at setting the right assumptions.
With existential risk from unaligned AI, I don't think anyone has ever told a very clear story about how AI will actually get misaligned, get loose, and kill everyone.
This should be evidence against AI x-risk![1] Even in the atmospheric ignition case in Trinity, they had more concrete models to use. If we can't build a concrete model here, then it implies we don't have a concrete/convincing case for why it should be prioritised at all, imo. It's similar to the point in my footnotes that you need to argue for both p and p->q, not just the latter. This is what I would expect to see if the case for p was unconvincing/incorrect.
I don't think this is a problem: we shouldn't expect to know all the details of how things go wrong in advance
Yeah I agree with this. But the uncertainty and cluelessness in the future should decrease one's confidence that they're working on the most important thing in the history of humanity, one would think.
and it is worthwhile to do a lot of preparatory research that might be helpful so that we're not fumbling through basic things during a critical period. I think the same applies to digital minds.
I'm all in favour of research, but how much should that research get funded? Can it be justified above other potential uses of money and general resource? Should it be an EA priority as defined by the AWDW framing? These we (almost) entirely unargued for.
> For an intervention to be a longtermist priority, there needs to be some kind of concrete story for how it improves the long-term future.
I disagree with this. With existential risk from unaligned AI, I don't think anyone has ever told a very clear story about how AI will actually get misaligned, get loose, and kill everyone.
When I read the passage you quoted I thought of e.g. Critch's description of RAAPs and Christiano's what failure looks like, both of which seem pretty detailed to me without necessarily fitting the "AI gets misaligned, gets loose and kills everyone" meme; both Critch and Christiano seem to me to be explicitly pushing back against consideration of only that meme, and Critch in particular thinks work in this area is ~neglected (as of 2021, I haven't kept up with goings-on). I suppose Gwern's writeup comes closest to your description, and I can't imagine it being more concrete; curious to hear if you have a different reaction.
To add to the intensive animal agriculture analogy: this time, people are designing them, which provides a lot of reason to believe early intervention can affect AI welfare compared to animal agriculture.
Even if you think that AI welfare is important (which I do!), the field doesn't have the existing talent pipelines or clear strategy to absorb $50 million in new funding each year.
Yep completely agree here, and as Siebe pointed out I did got to the extreme end of 'make the changes right now'. It could be structured in more gradual way, and potential from more external funding.
The fact that something might have a huge scale and we might be able to do something about it is enough for it to be taken seriously and provides prima facie evidence that it should be a priority.
I agree in principle on the huge scale point, but much less so the 'might be able to do something'. I think we need a lot more than that, we need something tractable to get going, especially for something to be considered a priority. I think the general form of argument I've seen this week is that AI Welfare could have a huge scale, therefore it should be an EA priority without much to flesh out the 'do something' part.
AI persons (or things that look like AI persons) could easily be here in the next decade...AI people (of some form or other) are not exactly a purely hypothetical technology,
I think I disagree empirically here. Counterfeit "people" might be here soon, but I am not moved much by arguments that digital 'life' with full agency, self-awareness, autopoiesis, moral values, moral patienhood etc will be here in the next decade. Especially not easily here. I definitely think that case hasn't been made, and I think (contra Chris in the other thread) that claims of this sort should have been made much more strongly during AWDW.
We might have that opportunity now with AI welfare. Perhaps this means that we only need a small core group, but I do think some people should make it a priority.
Some small people should, I agree. Funding Jeff Sebo and Rob Long? Sounds great. Giving them 438 research assistants and $49M in funding taken from other EA causes? Hell to the naw. We weren't discussing whether AI Welfare should be a priority for some EAs, we were discussing specific terms set out in the week's statement, and I feel like I'm the only person during this week who paid any attention to them.
Secondly, the 'we might have that opportunity' is very unconving to me. It's the same convingness to me of saying in 2008 that '"If CERN is turned on, it make create a black hole that destroys the world. Nobody else is listening. We might only have the opportunity to act now!" It's just not enough to be action-guiding in my opinion.
I'm pretty aware the above is unfair to strong advocates of AI Safety and AI Welfare, but at the moment that's where the quality of arguments this week have roughly stood from my viewpoint.
Nice, this was a helpful reframe for me. Thanks for writing this!
I wish more people posting during the debate week were more centered on addressing the specific debate question, instead of just generally writing interesting things — although it's easier to complain than contribute, and I'm glad for the content we got anyway :)
"5%+ of unrestricted EA talent and funding should be focused on the potential well-being of future artificial intelligence systems".
As a rough estimate for the number of EAs, I take the number of GWWC Pledgers even if they'd consider themselves 'EA-Adjacent'.[2] At my last check, the lifetime members page stated there were 8,983 members, so 5% of that would be ~449 EAs working specifically or primarily on the potential well-being of future artificial intelligence systems.
This seems to me to be too expansive an operationalization of "EA talent".
If we're talking about how to allocate EA talent, it doesn't seem to be that it can be 'all EAs' or even all GWWC pledgers. Many of these people will be retired or earning to give, or unable to contribute to EA direct work for some other reason. Many don't even intend to do EA direct work. And many of those who are doing EA direct work will be doing ops or other meta work, so even the EA direct work total is not the total number who could be directly working as AI welfare researchers. I think, if we use this bar, then most EA cause areas won't reach 5% of EA talent.
In a previous survey, we found 8.7% of respondents worked in an EA org. This is likely an overestimate, because fewer less engaged EAs (who are less likely to take the survey) are EA org employees). 8.7% of the total EA community (assuming growth based on the method we employed in 2019 and 2020 implies around 1300 people in EA orgs (5% of which would be around 67 people). We get a similar estimate from applying the method above to the total number of people who reported working in EA orgs in 2022. To be sure, the number of people who are in specifically EA orgs will undercount total talent, since some people are doing direct work outside EA orgs. But using the 2022 numbers for people reporting they are doing direct work, would only increase the 5% figure to around 114 (which I argue would still need to be discounted for people doing ops and similar work, if we want to estimate how many people should be doing AI welfare work specifically).
Great point, I did not think of the specific claim of 5% when thinking of the scale but rather whether more effort should be spent in general.
My brain basically did a motte and baily on me emotionally when it comes to this question so I appreciate you pointing that out!
It also seems like you're mostly critiquing the tractability of the claim and not the underlying scale nor neglectedness?
It kind of gives me some GPR vibes as for why it's useful to do right now and that dependent on initial results either less or more resources should be spent?
It also seems like you're mostly critiquing the tractability of the claim and not the underlying scale nor neglectedness?
Yep, everyone agrees it's neglected. My strongest critique is the tractability, which may be so low as to discount astronomical value. I do take a lot of issue with the scale as well though. I think that needs to be argued for rather than assumed. I also think trade-offs from other causes need to be taken into account at some point too.
And again, I don't think there's no arguments that can make traction on the scale/tractability that can make AI Welfare look like a valuable cause, but these arguments clearly weren't made (imho) in AWDW
Executive summary: The proposition to make AI welfare an EA priority, which would allocate 5% of EA talent and funding to this cause, lacks sufficient justification and should not be supported without stronger arguments.
Key points:
Making AI welfare an EA priority would require significant reallocation of resources, potentially at the expense of other important causes.
The burden of proof for such a major shift in priorities is high and requires strong justifications, which have not been adequately provided during AI Welfare Debate Week.
Most arguments presented for AI welfare prioritization rely on speculative possibilities rather than concrete evidence or robust reasoning.
The author argues that the precautionary principle alone is insufficient justification for allocating significant resources to AI welfare.
While AI welfare research may be interesting and potentially valuable, this does not automatically qualify it as an EA priority.
The author recommends Forum voters lean against making AI welfare an EA priority until stronger justifications are provided, while acknowledging that such justifications may exist but have not been presented.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
I think it’s very valuable for you to state what the proposition would mean in concrete terms.
On the other hand, I think it’s quite reasonable for posts not spend time engaging with the question of whether “there will be vast numbers of AIs that are smarter than us”.
AI safety is already one of the main cause areas here and there’s been plenty of discussion about these kinds of points already.
If someone has something new to say on that topic, then it’d be great for them to share it, otherwise it makes sense for people to focus on discussing the parts of the topic that have not already been covered as part of the discussions on AI safety.
I think it’s very valuable for you to state what the proposition would mean in concrete terms.
It's not just concrete terms, it's the terms we've all agreed to vote on for the past week!
On the other hand, I think it’s quite reasonable for posts not spend time engaging with the question of whether “there will be vast numbers of AIs that are smarter than us”.
I think I just strongly disagree on this point. Not every post has to re-argue everything from the ground up, but I think every post does need at least a link or backing to why it believes that. Are people anchoring on Shulman/Cotra? Metaculus? Cold Takes? General feelings about AI progress? Drawing lines on graphs? Specific claims about the future that making reference only to scaled-up transformer models? These are all very different claims for the proposition, and differ in terms of types of AI, timelines, etc.
AI safety is already one of the main cause areas here and there’s been plenty of discussion about these kinds of points already.
If someone has something new to say on that topic, then it’d be great for them to share it, otherwise it makes sense for people to focus on discussing the parts of the topic that have not already been covered as part of the discussions on AI safety.
I again disagree, for two slightly different reasons:
I'm not sure how good the discussion has been about AI Safety. How much have these questions and cruxes actually been internalised? Titotal's excellent series on AI risk scepticism has been under-discussed in my opinion. There are many anecdotal cases of EAs (especially younger, newer ones) simply accepting the importance of AI causes through deference alone.[1] At the latest EAG London, when I talked about AI risk skepticism I found surprising amounts of agreement with my positions even amongst well-known people working in the field of AI risk. There was certainly an interpretation that the Bay/AI-focused wing of EA weren't interested in discussing this at all.
Even if something is consensus, it should still be allowed (even encouraged) to be questioned. If EA wants to spend lots of money on AI Welfare (or even AI Safety), it should be very sure that it is one of the best ways we can impact the world. I'd like to see more explicit red-teaming of this in the community, beyond just Garfinkel on the 80k podcast.
I also met a young uni organiser who was torn about AI risk, since they didn't really seem to be convinced of it but felt somewhat trapped by the pressure they felt to 'towe the EA line' on this issue
What do you think was the best point that Titotal made?
I'm not saying it can't be questioned. And there wasn't a rule that you couldn't discuss it as part of the AI welfare week. That said, what's wrong with taking a week's break from the usual discussions that we have here to focus on something else? To take the discussion in new directions? A week is not that long.
I don't quite know what to respond here.[1] If the aim was to discuss something differently then I guess there should have been a different debate prompt? Or maybe it shouldn't have been framed as a debate at all? Maybe it should have just prioritised AI Welfare as a topic and left it at that. I'd certainly have less of an issue with the posts that were were that have happened, and certainly wouldn't have been confused by the voting if there wasn't a voting slider.[2]
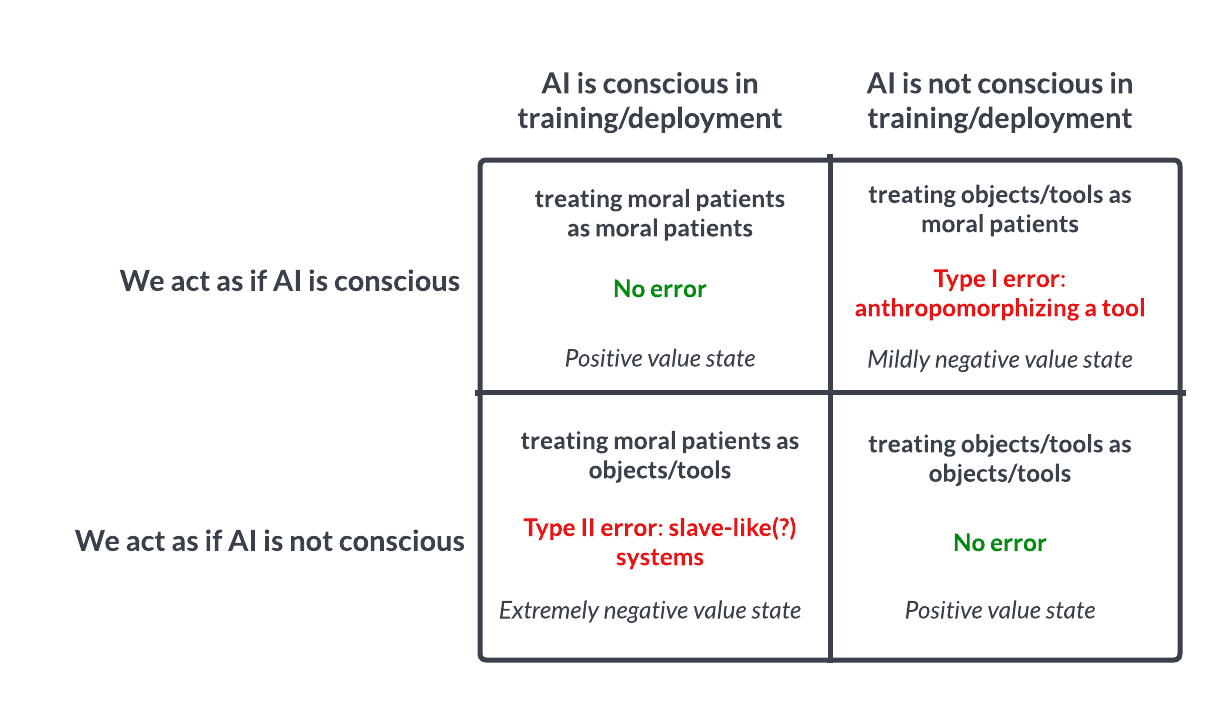
Responding to your critique of the model we put forward:
You still need to argue how and why it is useful and should be used to guide decision-making. In neither of the two cases, from what I can tell, do the authors attempt to understand which of the boxes we are in...
We argue that this model can be used to guide decision-making insofar as the Type II error in particular here seems very reckless from both s-risk and x-risk perspectives—and we currently lack the requisite empirical knowledge that would enable us to determine with any confidence which of these four quadrants we are currently in.
You seem to be claiming that this model would only be useful if we also attempted to predict which quadrant we are in, whereas the entire point we are making is that deep uncertainty surrounding this very question is a sufficiently alarming status quo that we should increase the amount of attention and resources being devoted to understanding what properties predict whether a given system is sentient. Hopefully this work would enable us to predict which quadrant we are in more effectively so that we can act accordingly.
In other words, the fact that we can't predict with any confidence which of these four worlds we are currently in is troubling given the stakes, and therefore calls for further work so we can be more confident ASAP.
spending on the order of $5-10M this year, and increasing it year by year only in high quality options, until at least 5% of EA total spending is reached
about 45 people working on AI welfare by approximately the middle of next year, and that increasing in a pace such that each position remains a good use of talent, until at least 5% of EA talent is reached
Author's Note: Written in a slightly combative tone [1]as I have found the arguments for the proposition this week to be insufficiently compelling for the debate statement at hand. Also, I'm very rushed getting this out in time so with more time I would probably have focused more on the ideas and had more time to add nuance and caveats. I apologise in advance for my shortcomings, and hope you can take the good parts of it and overlook the bad.
Parsing the Debate statement correctly means that supporting it entails supporting radical changes to EA
The statement for AI Welfare Debate Week (hereafter AWDW) is “AI welfare should be an EA priority”. However, expanding this with the clarifications provided by the Forum team leads to the expanded statement: "5%+ of unrestricted EA talent and funding should be focused on the potential well-being of future artificial intelligence systems".
Furthermore, I'm interpreting this as a "right now course of action" claim and not an "in an ideal world wouldn't it be nice if" claim. A second interpretation I had about AWDW was that posters were meant to argue directly for the proposition instead of providing information to help voters make up their minds. I think, in either case, though especially the first, the argument forthe proposition has been severely underargued.
To get even more concrete, I estimate the following:
As a rough estimate for the number of EAs, I take the number of GWWC Pledgers even if they'd consider themselves 'EA-Adjacent'.[2] At my last check, the lifetime members page stated there were 8,983 members, so 5% of that would be ~449 EAs working specifically or primarily on the potential well-being of future artificial intelligence systems.
For funding, I indexed on Tyler Maule's 2023 estimates of EA funding. That stood at $980.8M in estimated funding, so 5% of that would be ~$49.04M in yearly funding spent on AI Welfare.
This is obviously a quick and dirty method, but given the time constraints I hope it's in the rough order of magnitude of the claims that we're talking about.
Furthermore, I think the amount of money and talent that are spent on AI Welfare in EA is already is quite low, so unless one thinks there can be an influx of new talent and donors to EA specifically to work on AI Welfare then this re-prioritisation must necessarily come at the cost of other causes that EA cares about.[3]
These changes can only be justified if the case to do so is strongly justified
This counterfactual impact on other EA causes cannot, therefore, be separated from arguments for AI Welfare. In my opinion, one of the Forum's best ever posts is Holly Elmore's We are in triage every second of every day. Engaging with Effective Altruism should help make us all more deeply realise that the counterfactual costs of our actions can be large. To me, making such a dramatic and sudden shifts to EA priorities would require strong justifications, especially given the likely high counterfactual costs of the change.[4]
As an example, Tyler estimated that 2023 EA funding for Animal Welfare was around ~$54M. In the world where AI Welfare was made a priority as per the statement definition then it would likely gain some resources at the expense of Animal Welfare, and plausibly become a higher EA priority by money and talent. This is a result I would prima facie think that many or most EAs would not support, and so I wonder if all of those who voted strongly or relatively in favour of AWDW's proposition fully grasped the practical implications of their view.
Most posts on AI Welfare Debate Week have failed to make this case
The burden of proof for prioritising AI Welfare requires stronger arguments
However, arguments this week seem to have not made the positive case at all. In fact, while reading (and skim reading) other posts I didn't find any specific reference to the proposition of AWDW. If so, the baseline should be that they haven't made a good argument for it.
In some cases this is likely because they were written beforehand (or pre-briefed to be about the topic of AI Welfare). Perhaps, as I mentioned above, this was not meant to be what the posts were discussing, in which case the misinterpretation is on my end. But even in this case, I would still implore those reading these posts and voting on AWDW to understand the proposition on which they are voting is a specific proposition and they ought to vote as such.
I was originally planning to write a post for AWDW arguing that LLM-based AI systems do not deserve moral consideration on the grounds that they are 'counterfeit people' as the late Daniel Dennett argued. This was dropped due to time constraints, but also because I believe that the onus is on the proponents of AI Welfare to make a much more compelling case for enacting such as significant shift in EA priorities.
The justifications that are provided seem rather weak
In the posts that I interpreted as arguing in favour of the AWDW proposition, I saw many framings arguing that it is possible that AI Welfare could be a highly important topic. For example, the following claims directly come from posts written for AWDW:
These are interesting and broad philosophical claims, but to be action guiding they require justification and grounding[5] and I expected the authors to provide robust evidence and grounding for these claims. For example, we may have decades or less, but we may not. AIs could soon have an outsized impact, but they could not. The future may consist of mostly digital minds, but it could not.
It is not good enough to simply say that an issue might have a large scale impact and therefore think it should be an EA priority, it is not good enough to simply defer to Carl Shulman's views if you yourself can't argue why you think it's "pretty likely... that there will be vast numbers of AIs that are smarter than us" and why those AIs deserve moral consideration.
Unfortunately, I could find very little in the posts to actually argue that these possibilities hold, and to me this is simply not enough grounding to take ~450 people and ~$49M away from other causes that are not in the 'may' stage, but are actually doing good in issues that effect moral patients right now, and that we can be much more confident in the tractability of our interventions and set up feedback loops to investigate if what we are doing actually is working.
As George Box said: "All models are wrong, but some are useful". But clearly, not all models are useful. You still need to argue how and why it is useful and should be used to guide decision-making. In neither of the two cases, from what I can tell, do the authors attempt to understand which of the boxes we are in, and in the latter case make an appeal to the precautionary principle.
But one could make precautionary appeals to almost any hypothetical proposition, and for AI Welfare to get the amount of funding and talent the proposition implies, stronger arguments are needed. Without the advocates for AI Welfare making a stronger case that current or near-future AI systems deserve enough moral consideration to be an EA priority, I will continue to find myself unmoved.
Working on AI Welfare can still be valuable and interesting
I've worded this essay pretty harshly, so I want to end with a tone of reconciliation and to clarify my point of view:
I do think that AI Welfare is an interesting topic to explore.
I think the surrounding research into questions of consciousness is exciting and fundamentally connected to many other important questions EA cares about.
If digital beings were to exist and be morally relevant, then these questions would need to be answered.[7]
Those who find these questions deeply interesting and motivating should still work on them.
It is possible that these questions deserve more funding and talent than they are currently getting both within and outside of EA.
Nevertheless, the fact that a topic is interesting and potentially valuable is not enough to make it an EA priority, especially in terms of the question that AWDW has placed before us.
Conclusion: A Win by Default?
The tl;dr summary of the post is this:
AWDW's proposition to make AI welfare an EA priority means allocating 5% of EA talent and funding to this cause area.
This would require significant changes to EA funding allocation and project support, and would entail significant counterfactual costs and trade-offs.
To make this change, therefore, requires strong justification and confidence about the value[8] of AI Welfare work.
Such justification has not than has been provided during AWDW.
Therefore, Forum voters ought to vote toward the left end of the slider until such justifications are provided.
This does not mean such justifications do not exist or cannot be provided, only that they have not on the Forum during AWDW.
While AI welfare should not be an EA Priority at the moment, as defined by AWDW, it could still be interesting and valuable work.
The zero-sum nature falls out of my highly practical interpretation of the AWDW question. Maybe you're defining talent and funding more maleably, in which case I'd like to see that explicitly argued. If you didn't read the clarifications given by the Forum team and are just voting based on 'vibes' then I think you failed to understand the assignment.
By which I mean it is not enough to argue that p->q entials q, where q is some course of action you want to take. You need to argue that both p->q holds and that p is the case, which is what I think has been substantially missing from posts this week.
Now, in the former article, they point out that this is isomorphic to Pascal's Wager, which to me should be a consideration that something has potentially gone wrong in the reasoning process.
This is the third in a sequence of posts taken from my recent report: Why Did Environmentalism Become Partisan?
Summary
Rising partisanship did not make environmentalism more popular or politically effective. Instead, it saw flat or falling overall public opinion, fewer major legislative achievements, and fluctuating executive actions.
Public Opinion...
I think right now EAs might be making a significant mistake by paying insufficient attention to the political realm. As EAs we tend to figure out what’s most impactful for us to work on and focus hard. That’s great! But there are various actions that are ‘non-delegatable’ - the extent to which an individual can do the action is limited (like voting, going to a protest, making hard money contributions to particular campaigns). It might be useful if we were all more in the habit of doing variou...
New Video from AI in Context: The Fall and Rise of Sam Altman
If you want to skip straight to the video, here it is!
AI in Context is excited to be back with our fourth video! For those just hearing from us, we make videos for 80,000 Hours, telling stories about transformative AI...



I generally agree that the formal thesis for the debate week set a high bar that is difficult to defend and I think that this is a good statement of the case for that. Even if you think that AI welfare is important (which I do!), the field doesn't have the existing talent pipelines or clear strategy to absorb $50 million in new funding each year. Putting that much in over the next few years could easily make things worse. It is also possible that AI welfare has the potential for non-EA money and it should aim for that rather than try to take money that would otherwise go to EA cause areas.
That said, there are other points that I disagree with:
I think that this is wrong. The fact that something might have a huge scale and we might be able to do something about it is enough for it to be taken seriously and provides prima facie evidence that it should be a priority. I think it is vastly preferrable to preempt problems before they occur rather than try to fix them once they have. For one, AI welfare is a very complicated topic that will take years or decades to sort out. AI persons (or things that look like AI persons) could easily be here in the next decade. If we don't start thinking about it soon, then we may be years behind when it happens.
AI people (of some form or other) are not exactly a purely hypothetical technology, and the epistemic case for them doesn't seem fundamentally different from the case for thinking that AI safety will be an existential issue in the future, that the average intensively farmed animal leads a net-negative life, or that any given global health intervention won't have significant unanticipated negative side effects. We're dealing with deep uncertainties no matter what we do.
Additionally, it might be much harder to try to lobby for changes once things have gone wrong. I wish some groups were actively lobbying against intensified animal agriculture in the 1930s (or the 1880s). It may not have been tractable. It may not have been clear, but it may have been possible to outlaw some terrible practices before they were adopted. We might have that opportunity now with AI welfare. Perhaps this means that we only need a small core group, but I do think some people should make it a priority.
I feel like you are talking past the critique. For an intervention to be a longtermist priority, there needs to be some kind of story for how it improves the long-term future. Sure, AI welfare may be a large-scaled problem which takes decades to sort out (if tackled by unaided humans), but that alone does not mean it should be worked on presently. Your points here do not engage with the argument, made by @Zach Stein-Perlman early on in the week, that we can just punt solving AI welfare to the future (i.e., to the long reflection / to once we have aligned superintelligent advisors), and in the meantime continue focusing our resources on AI safety (i.e., on raising the probability that we make it to a long reflection).
(There is an argument going in the opposite direction that a long reflection might not happen following alignment success, and so doing AI welfare work now might indeed make a difference to what gets locked in for the long-term. I am somewhat sympathetic to this argument, as I wrote here, but I still don’t think it delivers a knockdown case for making AI welfare work a priority.)
Likewise, for an intervention to be a neartermist priority, there has to be some kind of quantitative estimate demonstrating that it is competitive—or will soon be competitive, if nothing is done—in terms of suffering prevented per dollar spent, or similar, with the current neartermist priorities. Factory farming seems like the obvious thing to compare AI welfare against. I’ve been surprised by how nobody has tried coming up with such an estimate this week, however rough. (Note: I’m not sure if you are trying to argue that AI welfare should be both a neartermist and longtermist priority, as some have.)
(Note also: I’m unsure how much of our disagreement is simply because of the “should be a priority” wording. I agree with JWS’s current “It is not good enough…” statement, but would think it wrong if the “should” were replaced with “could.” Similarly, I agree with you as far as: “The fact that something might have a huge scale and we might be able to do something about it is enough for it to be taken seriously.”)
[ETA: On a second read, this comment of mine seems a bit more combative than I intended—sorry about that.]
I disagree with this. With existential risk from unaligned AI, I don't think anyone has ever told a very clear story about how AI will actually get misaligned, get loose, and kill everyone. People have speculated about components of the story, but generally not in a super concrete way, and it isn't clear how standard AI safety research would address a very specific disaster scenario. I don't think this is a problem: we shouldn't expect to know all the details of how things go wrong in advance, and it is worthwhile to do a lot of preparatory research that might be helpful so that we're not fumbling through basic things during a critical period. I think the same applies to digital minds.
I think this viewpoint is overly optimistic about the probability of locking in / the relevance of superintelligent advisors. I discuss some of the issues of locking in in a contribution to the debate week. In brief, I think that it is possible that digital minds will be sufficiently integrated in the next few decades that they will have power in social relationships that will be extremely difficult to disentangle. I also think that AGI may be useful in drawing inferences from our assumptions, but won't be particularly helpful at setting the right assumptions.
This should be evidence against AI x-risk![1] Even in the atmospheric ignition case in Trinity, they had more concrete models to use. If we can't build a concrete model here, then it implies we don't have a concrete/convincing case for why it should be prioritised at all, imo. It's similar to the point in my footnotes that you need to argue for both p and p->q, not just the latter. This is what I would expect to see if the case for p was unconvincing/incorrect.
Yeah I agree with this. But the uncertainty and cluelessness in the future should decrease one's confidence that they're working on the most important thing in the history of humanity, one would think.
I'm all in favour of research, but how much should that research get funded? Can it be justified above other potential uses of money and general resource? Should it be an EA priority as defined by the AWDW framing? These we (almost) entirely unargued for.
Not dispositive evidence perhaps, but a consideration
When I read the passage you quoted I thought of e.g. Critch's description of RAAPs and Christiano's what failure looks like, both of which seem pretty detailed to me without necessarily fitting the "AI gets misaligned, gets loose and kills everyone" meme; both Critch and Christiano seem to me to be explicitly pushing back against consideration of only that meme, and Critch in particular thinks work in this area is ~neglected (as of 2021, I haven't kept up with goings-on). I suppose Gwern's writeup comes closest to your description, and I can't imagine it being more concrete; curious to hear if you have a different reaction.
To add to the intensive animal agriculture analogy: this time, people are designing them, which provides a lot of reason to believe early intervention can affect AI welfare compared to animal agriculture.
Thanks for extensive reply Derek :)
Yep completely agree here, and as Siebe pointed out I did got to the extreme end of 'make the changes right now'. It could be structured in more gradual way, and potential from more external funding.
I agree in principle on the huge scale point, but much less so the 'might be able to do something'. I think we need a lot more than that, we need something tractable to get going, especially for something to be considered a priority. I think the general form of argument I've seen this week is that AI Welfare could have a huge scale, therefore it should be an EA priority without much to flesh out the 'do something' part.
I think I disagree empirically here. Counterfeit "people" might be here soon, but I am not moved much by arguments that digital 'life' with full agency, self-awareness, autopoiesis, moral values, moral patienhood etc will be here in the next decade. Especially not easily here. I definitely think that case hasn't been made, and I think (contra Chris in the other thread) that claims of this sort should have been made much more strongly during AWDW.
Some small people should, I agree. Funding Jeff Sebo and Rob Long? Sounds great. Giving them 438 research assistants and $49M in funding taken from other EA causes? Hell to the naw. We weren't discussing whether AI Welfare should be a priority for some EAs, we were discussing specific terms set out in the week's statement, and I feel like I'm the only person during this week who paid any attention to them.
Secondly, the 'we might have that opportunity' is very unconving to me. It's the same convingness to me of saying in 2008 that '"If CERN is turned on, it make create a black hole that destroys the world. Nobody else is listening. We might only have the opportunity to act now!" It's just not enough to be action-guiding in my opinion.
I'm pretty aware the above is unfair to strong advocates of AI Safety and AI Welfare, but at the moment that's where the quality of arguments this week have roughly stood from my viewpoint.