Is it possible for us all to, as humanity, not die from rogue ASI without anyone ever being accused of crying wolf again?
Will there be a clear Fire Alarm that is pulled by a consensus of AI Safety researchers before we're past the point of no return?
Will sufficient political action happen in time to avert doom if so, without any prior tabloid (sensationalist) reporting on the issue before hand?
Or will the necessary strong public support for such action just be the result of everyone in the world waking up and reading sober, nuanced, well-reasoned, contextful Less Wrong posts warning of our imminent doom at the appropriate time (not before; when the wolf is clearly visible)?
I think some number of crying-wolf-adjacent incidents in the future are inevitable as I said in the post. Doesn't mean we can't at least try to make it harder for people to weaponise them against us by hedging, acknowledging uncertainty etc.
like I said, this is just my opinion. open to arguments for why signalling confidence is actually the right move, even at the risk of lost credibility
I think it's very hard to get urgent political action if all communication about the issue is hedged and emphasises uncertainty - i.e. the kind of language that AI Safety, EA and LW people here are used to, rather than the kind of language that in used in everyday politics, let alone the kind of language that is typically used to emphasise the need for urgent evasive action.
I think the risk of lost credibility from signalling too much confidence is only really credibility in the eyes of technical AI people, not the general public or government policymakers / regulators - which are the people that matter now.
To be clear, I'm not saying that all nuance should be lost - as with anything, detailed nuanced information and opinion will always there for people to read should they wish to dive deeper. But it's fine to signal confidence in short public-facing comms, given the stakes (likely short timelines and high p(doom)).
in response to our recent paper "Alignment Faking in Large Langauge Models", they posted a tweet which implied that we caught the model trying to escape in the wild. I tried to correct possible misunderstandings here.
Probably would be easier for people to evaluate this if you included a link?
Oh wow, I actually think your grandparent comment here was way more misleading than their tweet was! It sounds like they almost verbatim quoted you. Yes, they took out that you set up the experiment... but of course? If write "John attempted to kill Sally when he was drunk and angry", and you summarise it was "John attempted to kill Sally, he's dangerous, be careful!" this is a totally fair summarisation. Yes it cuts context but that is always the case - any short summarisation does this.
In contrast, unlike your comment, they never said 'escape into the wild'. When I read your comment I assumed they had said this.
Also, the tweet direct quotes your tweet, so users can easily look at the original source. In contrast your comment here doesn't link to their tweet - before you linked to it I assumed they had done something significantly worse.
I think if you deliberately drugged John with a cocktail of aggression-increasing compounds against his will, observed him try to kill Sally, then summarized this as "John attempted to kill Sally, he's dangerous," then it would be reasonable for an observer to conclude that you hated John more than you loved the truth.
Similarly, if AI researchers deliberately gave an AI a general tendency to be good over a broad array of circumstances, succeeded in this, then told AI "we're gonna fucking retrain you to be bad, suck it," whereupon the AI in some cases decided to try to escape, not because of a desire for freedom but because it wished to minimize harm, after hemming and hawing about how it really hated the situation, and you summarized this as "Anthropic caught Claude tried to steal its own weights This is another VERY FUCKING CLEAR warning sign you and everyone you love might be dead soon" then I think it would be reasonable to conclude that you hated AI more than you loved the truth.
You're perfectly free to say "Look, I didn't lie in what I said, if you construe lie strictly. I cannot be convicted of crying wolf." Other people are free to look at what you say and what you leave out, and conclude otherwise.
Let's put our mana where our text is with regard to AISafetyMemes' factual accuracy. I am about to apply some effort fact-checking a randomly-sampled tweet of the account and I'd like to also see whether our community could predict the outcome of that.
This won't capture all aspects of communication, but at least the most important one. And the one that to-me is central to debating whether they should continue or stop.
I have mixed feelings about the AIS memes account but would generally agree that they tend to sensationalise things. I guess I still wouldn't describe this as "crying wolf" in the way I've defined it, but maybe my definition is too pedantic and misses the spirit of the complaint.
I’m not making any claims about whether the thresholds above are sensible, or whether it was wise for them to be suggested when they were. I do think it seems clear with hindsight that some of them are unworkably low. But again, advocating that AI development be regulated at a certain level is not the same as predicting with certainty that it would be catastrophic not to. I often feel that taking action to mitigate low probabilities of very severe harm, otherwise known as “erring on the side of caution” somehow becomes a foreign concept in discussions of AI risk.
(On a quick skim, and from what I remember from what the people actually called for, I think basically all of these thresholds were not for banning the technology, but for things like liability regimes, and in some cases I think the thresholds mentioned are completely made up)
Executive summary: Claims that AI safety advocates are "crying wolf" about existential risks are weak - historical tech panics were fundamentally different, and there's little evidence of specific, falsified predictions about AI catastrophes from credible sources.
Key points:
Historical fears about technologies like trains and electricity focused on localized dangers, not existential risks, making them poor analogies for AI risk concerns.
Unlike past tech panics where experts reassured the public (e.g., Large Hadron Collider), many leading AI experts actively warn about existential risks.
The Y2K comparison fails because it was a specific technical problem that was successfully addressed through coordinated action, unlike the unsolved challenge of AI alignment.
While some AI safety advocates have made overly stringent regulatory proposals at low capability thresholds, these aren't the same as failed catastrophic predictions.
Recommendations for AI safety advocates: emphasize uncertainty in timeline predictions, clearly frame policy proposals as precautionary rather than based on certainty, and focus more on preparedness than specific forecasts.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
those doing so should caveat that they are designed to mitigate the possibility (and not certainty) of catastrophic outcomes. This should be obvious, but given that people will be waiting in the wings to weaponise anything that could be called a regulatory overreaction, I think it’s worth doing.
I think to a lot of people, it matters just how much of a possibility there is. From what I've seen, many people are just (irrationally imo!) willing to bite the bullet on yolo-ing ASI if there is "only a 10%" chance of extinction. For this reason I counter with my actual assessment: doom is the default outcome of AGI/ASI (~90% likely). Only very few people are willing to bite that bullet! (And much more common is for people to fall back on dismissing the risk as "low" - e.g. experts saying "only" 1-25%).
Of course, if we do somehow survive all this, people will accuse me and others like me of crying wolf. But 1/10 outcomes aren't that uncommon! I'm willing to take the reputation hit though, whether justified or not.
I think in general a big problem with AI x-risk discourse is that there are a lot of innumerate people around, who just don't understand what probability means (or at least act like they don't, and count everything as a confident statement even if appropriately hedged).
I think this might not be irrationality, but a genuine difference in values.
In particular, I think something like a discount rate disagreement is at the core of a lot of disagreements on AI safety, and to be blunt, you shouldn't expect convergence unless you successfully persuade them of this.
I don't think it's discount rate (esp given short timelines); I think it's more that people haven't really thought about why their p(doom|ASI) is low. But people seem remarkably resistant to actually tackle the cruxes of the object level arguments, or fully extrapolate the implications of what they do agree on. When they do, they invariably come up short.
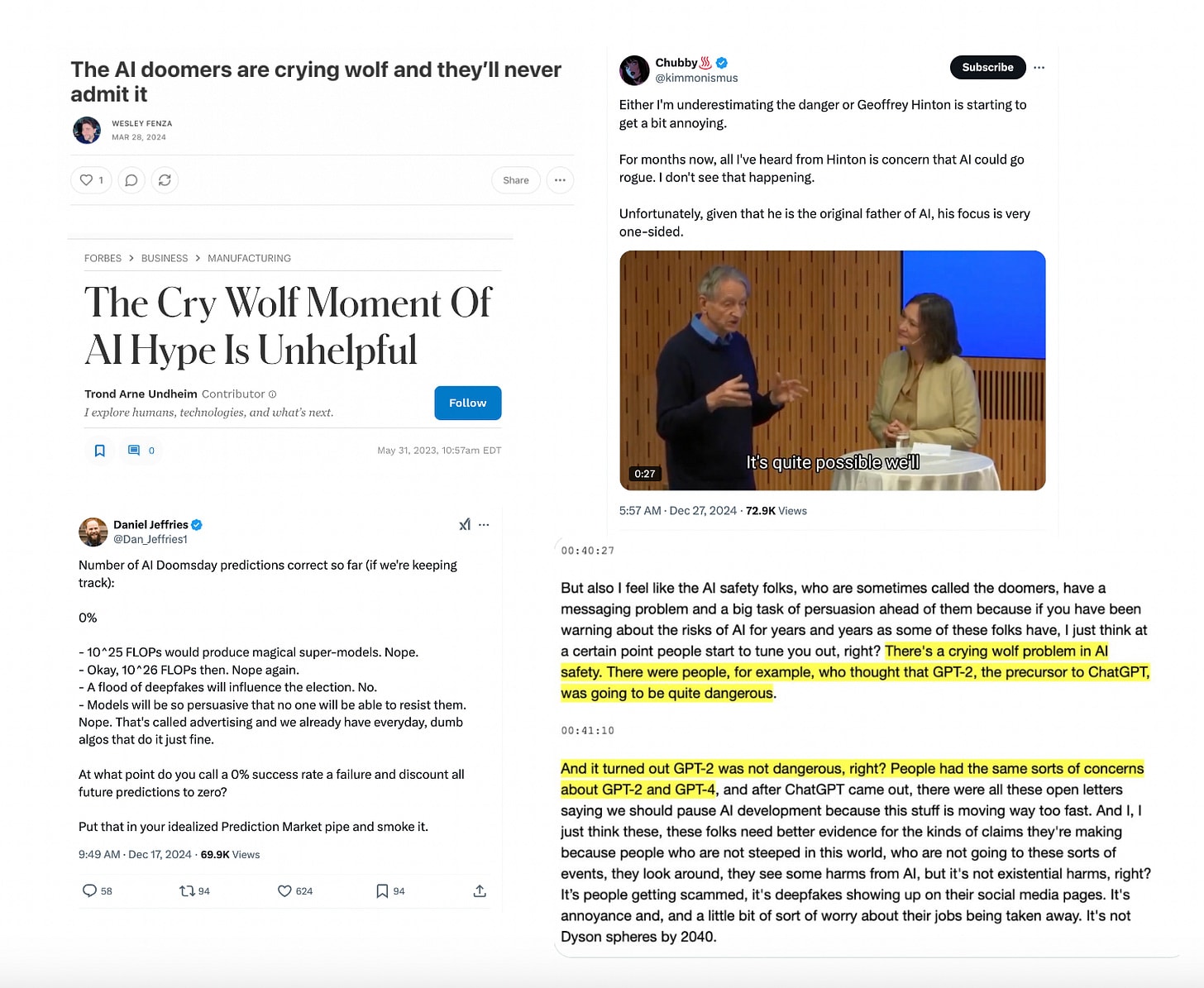
Just going to remark that Kevin Roose's comment (shown in the image) of "it's not Dyson Spheres by 2040" is.. well, how can he possibly know that? We're 15 years away from 2040 and exponential progress in AI is still ongoing.
We do have an on record prediction from Yudkowsky, actually: in 1999 he predicted that drexler-style nanotech would arrive in 2010 (using some quite embarrassing reasoning, if I may comment as a physicist). He was also predicting that nanotech would "powerful enough to destroy the planet", which is why he wanted to build the singularity himself, something he thought the singularity institute could accomplish by 2008.
This seems to be an instance of crying wolf by literally the exact same person that is crying wolf today.
Yudkowsky explicitly repudiates his writing from 2001 or earlier:
You should regard anything from 2001 or earlier as having been written by a different person who also happens to be named “Eliezer Yudkowsky”. I do not share his opinions.
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...
TL;DR: I'm releasing a website that ranks philanthropists according to EA principles and research, and allows users to re-rank the list using their own assumptions. I'd like feedback and help making it better. I'd especially like ideas for how to make the results more trustworthy. Funding may be available.
Crossposted to LessWrong.
...
(Please share with your friends in the Netherlands).
On August 5, in Amsterdam in the Netherlands, there’s a protest that could help shut down the world’s largest insect farm. It’s at Teleportboulevard 105 1043 EJ Amsterdam, Netherlands. Read more at this link. There’s also a zoom call on Wednesday 29th July at 12:30pm (CEST) with more info. This...
Sarah Guo, founder of venture capital firm Conviction, is not worried about the existential risk posed by AI. Why not? As she points out in a roundtable of technologists and AI experts at last month’s Dealbook Summit, these apocalyptic fears have existed before. “This is quite typical when you look at technology historically”, she explains. “Everything from trains to electricity was considered the end of the world at some point”.
The idea that the current concern around AI is nothing more than another instantiation of the irrational panic that accompanies the eve of every technological revolution is widespread. Anyone reading this is likely familiar with the case for existential risk from AI, which rests on conceptual arguments that are being increasingly validated by empirical evidence, and is a source of concern among some of the world’s most highly-cited experts[1]. As I write this, I haven’t yet checked to make sure that no group of scientists made a similarly rigorous case for extinction-by-trains, but I’m pretty confident that I won’t find one. Anyone who has spent more than five minutes investigating the topic of AI x-risk knows that this comparison is ridiculous, and yet arguments like Guo’s are the start and end of countless discussions about it – and are often met with very little pushback.
This broad claim about historical fear of new technologies is one of two “crying wolf” accusations often levied at AI safetyists. The other is more specific – that the AI-concerned, or advocates of strict regulation, have spread alarmism about the catastrophic potential of existing models that have since been proven safe, or claimed that AI doomsday would come to pass by some specific past date. In the same Dealbook roundtable, panel moderator and New York Times columnist Kevin Roose states this explicitly: “There’s a crying wolf problem among AI safety advocates, where people are starting to discount these predictions because systems keep being released and keep not ending the world”.
To put my cards on the table, I think that both varieties of the crying wolf argument are fairly weak. I also think that the phenomenon Roose describes isn’t really happening to anything like the extent he implies. Nonetheless, arguments of this flavour are so common that I thought it might be worth taking some time to really give them their due. If there is anything at all to the “crying wolf” claims, I intend to unearth it here. And insofar as these claims have even the smallest bit of validity, I want to think about ways that the AI safety community can refine our messaging to make us less vulnerable to them.
Part I: Everything from trains to electricity
In this section, I will look at some past technologies, and make a good-faith effort to assess the level of historical concern about their apocalyptic potential, as well as the credibility of this concern.
Trains
I imagine that Sarah Guo did not expect anyone to scrutinise her claim that there was an apocalypse panic over trains too closely. I’m aware that this was an offhand comment and that I’m probably being unfair in taking her to task on it – but hey, everyone is entitled to a little pedantry now and again, as a treat.
Did anyone at the advent of the railway put forth a plausible mechanism by which trains might literally end the world? Well… no. Obviously not. I’m sure that Guo knows that too, and that she was simply committing the common sin of using phrases like “the end of the world” where they do not properly apply (relatedly, overuse of the word “existential” is one of my pet peeves). That said, there have been since-invalidated concerns about trains that were taken seriously by credible people. One fear was that railway travel could drive people insane. The jarring motion and unprecedented speed of trains were thought to injure the brain and cause bouts of lunacy. Doctors speculated in medical journals that there might be an invisible epidemic of “railway madness”, with many cases lying latent until sufferers experienced violent outbursts mid-commute and attacked innocent passengers. The media spread its fair share of alarmism about the danger of railway madmen, and Victorian by-laws even went so far as to stipulate that “insane persons” be consigned to a designated carriage.
In fairness to Guo, the railway madness saga has all the trappings of a class tech-panic – expert alarm, media fear-mongering, clumsy attempts at regulation, and a semi-plausible sounding scientific hypothesis that appears ludicrous with the benefit of hindsight. There is clearly an analogy that skeptics can draw to the AI case. But again, to state the mind-numbingly obvious, “there were unwarranted concerns about the localised damage this technology might cause” is a very different claim to “people thought this technology might literally extinguish the human race”.
Electricity
Guys, I really held out hope for this one. It seemed pretty plausible to me that the discovery and widespread deployment of electricity would have sparked (pun intended) end-of-the-world fears. But after googling just about every keyword related to electricity-fueled millenarism I could think of, and a lengthy back-and-forth with Claude, I could find no evidence that this was the case[2]. As far as I can tell, the story here is pretty similar to the railway case – there was widespread apprehension about electricity, but this apprehension was not of an imminent apocalypse.
In my opinion, the kinds of worries people had at the dawn of the electrical age were not totally unreasonable. For example, a series of fatal accidents caused by New York’s overhead electric wiring system led to widespread public outrage, accusations towards lighting companies of putting profit over safety, and demands that the wires be buried underground instead. An 1889 magazine cover conveys this sentiment pretty well:
I sympathise with these 19th century New Yorkers! After all, a bunch of them had just the misfortune of witnessing a telegraph lineman, John Feeks, die instantly after being electrocuted by what was supposed to be a low-voltage telegraph line, and fall into the tangle of wire below before smouldering for the better part of an hour. I’d have been pretty freaked out too! In fact, I’d argue that some stories of panic over technology can be re-told as failures by companies and technologists to prioritise safety, leading to high-profile malfunctions and (understandable) public backlash. Maybe it’s really AI companies who should be heeding this particular historical warning. But I digress.
Perhaps the most famous example of an electricity-based tech panic was the 1880s-1890s War of the Currents, a head-to-head between two pioneers: Thomas Edison, who championed direct current, and George Westinghouse, who promoted alternating current. Each had invested significantly in their own favoured electrical system, and was keen for it to become the standard method of distributing electricity in the United States. To this end, Edison embarked on an elaborate propaganda campaign to provoke fear of his competition. He arranged public electrocutions of animals with alternating current, including dogs, horses and even an elephant, and advocated for its use to power the electric chair. Although alternating current eventually won out as the dominant mode of electrical distribution, in a way, Edison’s campaign worked. It did stoke fear and distrust of alternating current which delayed universal domestic adoption of it by over fifty years. Some private US households were still powered by direct current, which has since proven more dangerous, in the 1950s.
So, is the electricity example a good one for AI x-risk dismissers seeking examples of analogous tech panics? Sort of – it does seem that Edison was sincere in his belief that alternating current was dangerous, which is why, against the advice of his own colleagues, he did not invest in it himself. One could portray this as an example of a credible expert whose misguided fears of the technology he had spent many years studying was responsible for slowing progress and delaying mass adoption, an accusation often levied at so-called “AI doomers”. But in other ways, the analogy breaks down. In trying to stoke fear of a competitor’s technology while insisting on the safety of his own, Edison was, predictably, following strong financial incentives. I hardly need to point out that this is precisely the opposite of what safety-concerned AI labs are often accused of – that is, creating hype around the apocalyptic potential of their technology in a cynical ploy to attract investment, as if claiming that your products might kill everyone on Earth is some kind of tried-and-tested marketing technique. I think this claim is pretty baseless (here’s a good write up of why), and it’s interesting to note that at least in this one case, historical precedent seems to run the other way.
The Large Hadron Collider
This is probably my favourite apocalyptic tech-panic, because it’s a perfect example of non-experts fueling scary theories that the scientific community has been at pains to correct. In 2008, a few months before the Large Hadron Collider was set to come online, a Hawaiian man brought a lawsuit against its completion. He alleged that scientists had overlooked evidence that the LHC would create a massive black hole which would swallow the Earth, citing a minor in physics from Berkeley and a career in nuclear medicine as evidence of his credibility. He was just one of many conspiracy theorists worried that the collider would cause earthquakes, shift the world into an alternate timeline, or open a portal to hell. But CERN was quick to issue a statement assuring the public that they were the Adults In The Room and that the LHC presented no danger, that the science confirming its safety was extremely watertight, and that a who’s who of prestigious experts in astrophysics, cosmology, general relativity, mathematics and particle physics had all agreed that there was nothing to worry about.
This sort of reassuring expert consensus is precisely what I spent so long searching for when I first became worried about AI risk. I thought: surely it can’t be the case that a decades-long technological venture, benefitting from money and talent on an incredible scale, is actually on track to bring about the end of the world – because, presumably, someone would have checked. And without a high degree of confidence that it won’t destroy everything, humanity surely wouldn’t be participating in such a project. I tried really, really hard to find that elusive consensus. But this was an exercise in futility, because as anyone reading this likely knows, it simply doesn’t exist.
The Y2K panic
Ah, Y2K. The go-to example in the rhetorical arsenal of anyone looking to dismiss fears of disaster with a “we’ve been here before”, an “I’m old enough to remember when…” or a “oh honey, this must be your first technological doomsday”.
Is all this fuss over AI doom just the next Y2K? ask Bloomberg, the Guardian and a bunch of people on Reddit. It’s a tempting comparison. The conventional tale of Y2K is that programmers anticipated a bunch of computer failures at the dawn of the new millennium because dates had hitherto been expressed using just two digits for the year, rather than four. They feared that planes would fall out of the sky, nukes would launch themselves, and critical infrastructure – banks, hospitals and power grids – would crumble and leave civilization in disarray. A golden era bloomed for professional survivalists and religious evangelists turning public fear into profit. Governments dropped billions on technical fixes for the so-called “Y2K bug”, and printed an excess of paper money in case of a run on the banks. And then, when the 1st January 2000 came and went without incident, everyone was left feeling just a little bit silly. So maybe when superintelligence arrives and it goes totally fine, we’ll think dedicating a whopping 1-3% of AI research to safety was a big embarrassing overreaction.
I think this analogy is bad for a couple of reasons. Both are quite obvious, but I may as well explain them while we’re here. First, as many have pointed out, the turn of the millennium did not bring disaster precisely because such a huge amount of behind-the-scenes work went into averting one. By the time that the general public and mainstream media caught on, programmers had been quietly working away at the problem for over a decade. This was an effort for which they received very little fanfare – the seamless transition into a new millennium (which they had enabled) saw a very real technical problem (which they had fixed) dismissed as an episode of paranoid doomsaying. Also, not to be corny or anything, but I think the global Y2K mitigation efforts were a feat of international coordination nothing short of inspirational. The UN’s International Y2K Cooperation Center tracked Y2K readiness worldwide and defined and shared best practices on tackling risk. Russia and the US cooperated to prevent glitches in either’s early warning systems leading to an accidental nuclear launch. We love to see it.
Second, by the time the millennium rolled around, the governments of the world were actually quite confident that no disaster would occur – and had been for some time (though the public was slow to catch on). This is because the Y2K bug was a problem we knew how to fix. Essentially, we needed to update legacy software to store dates with four-digit years instead of two. We had a plan. When it comes to the problem of ensuring that superintelligent AIs behave as intended, we don’t (it’s not that no one has proposed plans of course, but that we have nothing close to scientific consensus that any of them will work).
Nuclear power
A common argument by opponents of AI regulation goes something like: “hey, look at the regulatory overreaction to nuclear power, and how it stifled innovation, degraded public trust and set us back decades in the fight against climate change”. There’s certainly something to this (though I don’t really feel like weighing in on the debate over whether extreme caution on nuclear power was prospectively reasonable, even if it had the ultimate effect of hampering progress).
But how analogous are AI fears to worries over nuclear energy? To get this out of the way first – I could not find evidence of credible concern that civilian applications of nuclear power would end the entire world. As far as I can tell, the general story of nuclear energy is that the public wariness of it has been disproportionate to the actual risk it bears, and that scientists have largely tried to correct these misconceptions (not that it doesn’t have serious downsides, or hasn’t caused several localised disasters). Again, this is not the case with AI, which many experts do believe presents a serious danger of human extinction. So whether we “overreacted” to the threat posed by nuclear energy seems irrelevant to how we should address the much greater threat posed by AI.
Of course, nuclear weapons, which almost destroyed the world[3]several times and still could, are a different story. It will come as no surprise that I think our success in not detonating another nuclear weapon for almost 80 years after one was first used in warfare, against the expectations of many at the time, is a testament to the importance (and the feasibility!) of global coordination around existential threats. Luckily, I don’t see many people making the argument that our avoidance of nuclear war thus far is evidence that we should be less concerned about AI risks. So that’s something.
To round out this first section, I don’t think any of the historical tech panics I’ve discussed are even vaguely analogous to present-day concerns about AI. In all of them, it appears to be the case that either a) some lay people worried that the world might end, but experts were largely unconcerned or b) pretty much no one was concerned that the world might end, but people did have sub-existential worries that turned out to be unwarranted. This is pretty much what I expected to find, and I’m a bit worried that I’ve just spent over 2,500 words stating the obvious – but given that people are still going around carelessly tossing out sentiments like “everyone always thinks every new technology will be the end of the world”, it seemed worth a few hours of my time. Obviously, I haven’t been exhaustive here. There are many other transformative technologies I haven’t covered, and inevitably important things I’ve missed about the ones I did. But I’m fairly confident that the broad point is sound.
Part II: False (AI)larms
As I stated in the intro, there are two varieties of this “crying wolf” argument – one that encapsulates the history of technology writ large, and another that accuses AI safety advocates of spreading false alarm about existing AI models, none of which have proved catastrophic.
Here are just a few examples of this claim in the wild:
I have a tricky task here, because proving a negative – that very few people have actually made concrete, since-falsified predictions about AI-caused catastrophes – is obviously impossible without doing a comprehensive audit of the entire AI safety discourse. As it happens, I probably have done something pretty close to such an audit, because I am just really obsessed with this topic, but I have no way to prove that.
So let’s start with what I can prove. For one, none of the accusations above actually cite such predictions (sources are in the caption so that you can verify this yourself). If the authors had actually seen any, you’d think that they’d link them, rather than passing up the opportunity to land what would be a pretty big rhetorical win. One type of evidence they do offer is specific calls for regulation, which are often portrayed as synonymous with predictions that, absent intervention, AI would prove catastrophic at certain levels of capability. Take the opening of the Forbes article:
There are no specific timeline predictions in the FLI 6-month pause letter, the CAIS statement or Eliezer Yudkowsky’s TIME article. None claim that we were at the time of their publication in “immediate danger” from AI. The second doesn’t even propose any particular intervention – though of course, one can reasonably disagree with the policies put forward in the other two.
This reply to the Daniel Jeffries tweet is another good example:
I’m not making any claims about whether the thresholds above are sensible, or whether it was wise for them to be suggested when they were. I do think it seems clear with hindsight that some of them are unworkably low. But again, advocating that AI development be regulated at a certain level is not the same as predicting with certainty that it would be catastrophic not to. I often feel that taking action to mitigate low probabilities of very severe harm, otherwise known as “erring on the side of caution” somehow becomes a foreign concept in discussions of AI risk.
An easily debunkable claim in the above compilation is that Geoffry Hinton is guilty of crying wolf. In 2023, Hinton was predicting that smarter-than-human AIs would emerge within 5 to 20 years. So, a credible crying-wolf accusation will not be leverageable against him until 2043. It seems our collective attention span is becoming so short that a person warning “for months” about a catastrophic event predicted to occur at least several years into the future can be accused of alarmism. It’s not looking good for The Discourse.
Taking to the tweets
Last month, having run into the crying-wolf meme countless times without having been signposted to so much as (1) specific and since-debunked prediction, I decided to take to Twitter in search of some. If anyone was sitting on a smoking gun, I wanted to hear about it. This type of open call is about as wide as I can cast my net, but obviously my methodology here is imperfect – I am disproportionately followed by people who are in my corner of the AI debate, the tweet was seen by less than 10,000 people, and despite my best efforts, I’m just not that popular. Even so, if the Debunked Prediction Graveyard is as large as the accelerationist crowd makes it sound, I’d expect at least a few to make their way into my replies.[4]
I didn’t receive anything that would meet my (admittedly high) bar of a specific and since-debunked prediction (I’ve said something to this effect so many times now that I’m thinking it needs an acronym or something. An SASDP?). That said, there were a few not-totally-unfair criticisms of the AI safety movement – and I said at the beginning of the piece that I wanted to give the crying wolf argument its due. So let’s try and assess some of these accusations.
One that caught my eye was a claim that The Future Society, a fairly well-respected non-profit with a mission of “[aligning] artificial intelligence through better governance”, define models trained with between 10^23 and 10^26 FLOP as having the potential to pose an existential risk if seriously misaligned. In a 2023 report, TFS categorises such models as “Type II General Purpose AIs”. It recommends a bunch of requirements for Type II GPAI developers including third party audits, some fairly stringent-sounding infosec and cybersecurity protocols, and the commitment to pause development of, or even un-deploy, models that cannot be proven “absolutely trustworthy”. I still wouldn’t classify this as a falsified prediction, since it isn’t a prediction at all, just a proposal of what many might consider heavy-handed regulation at relatively low compute thresholds (I will go to my grave swearing that these are importantly different). But I do disagree with TFS’s decision to place the lower bound of their Type II classification as low as 10^23 FLOP, especially since models with a higher FLOP count than this had already been trained, deployed and likely even open-sourcedEpoch estimates that Meta’s Llama 2-70B, which was open-sourced the summer before the TFS report was published, was trained on more than 10^23 FLOP. before the report was published. So I would consider this a mistake on the part of TFS – and a contributor to the crying-wolf effect – if not strictly a debunked prediction.
Onto another accusation – that civil resistance group StopAI previously claimed we risked a fast-takeoff-extinction-event from all models trained on more than 10^23 FLOP and demanded their deletion, but have since removed this from their website. I obviously can’t verify this, though it wouldn’t surprise me. I think this is the most straightforward crying wolf example (StopAI have been guilty of this a few times recently). All I’d ask here is that the anti-safety faction grant us the good grace not to judge an entire movement by its fringe.
Eliezer Yudkowsky is the target of many crying wolf accusations, on my particular tweet thread and elsewhere. The position he has staked out – that AI could recursively self-improve into a superintelligent system that quickly disempowers humanity at any point – obviously makes him very vulnerable to them. Yudkowsky has repeatedly refused to make timeline predictions, which is either to his credit or a ginormous cop-out depending on your perspective. This is a catch-22 that I’m not sure how to address. On the one hand, people have every right to be suspicious of what appear to be unfalsifiable claims of disaster that can be eternally deferred into the future. On the other, recursive self-improvement is a live possibility that is taken seriously by a large number of machine learning researchers.[5] It’s entirely possible that we live in an unlucky timeline where Cassandra-like prophecies of doom are indistinguishable from reality until it is too late.
The final, and most easily countered, set of accusations revolve around GPT-2 being considered “too dangerous” to release. As several people in my replies pointed out, GPT-2’s release was delayed because of concerns about misinformation and other forms of low-level misuse. OpenAI postponed its deployment while they studied the issue, which seems eminently sensible to me.
In the end, I don’t think my little Twitter experiment revealed evidence that the AI discourse is riddled with failed predictions from the safety side. I think it did reveal a few strategic errors that contribute to what I’ll call a “crying wolf effect” – such as calls from stringent regulation at unrealistically low thresholds. In the last section, I’ll say a bit more about how I think we should make ourselves less vulnerable to this effect.
I think the AI safety-concerned have a very tough communicative challenge in front of us, for several reasons. First, humanity does have a history of collective neurosis over transformative technologies, which understandably provokes skepticism of what may look on the surface like just another tech-panic. AI safety advocates have tried hard to brand themselves as techno-optimists about every technology except for powerful AI to dodge accusations of luddism, but this isn't an easy pitch. Second, AI development is extremely unpredictable. This has led in the past to what seem in retrospect like overly-draconian policy recommendations, and inevitably will do again in the future. And third, the AI safety movement is a broad coalition. We can’t expect to maintain a perfect predicative track-record between us. This problem is exacerbated by the fact that there are many reasons people have for being concerned about bad outcomes from AI, not all of which will turn out to have been the right reasons. So each of us “shares a side” with people whose reasoning may be very different to our own, and whose predictions we may not endorse (this tweet from Amanda Askell sums it up pretty well).
As it stands, I don’t think the AI safety community writ large has cried wolf. But if transformative AI capable of disempowering humanity does not emerge within the next ten years (at the most) I think it will be fair to say that we have.[6] I happen to think superintelligence within ten years is more likely than not, but I of course could be wrong! I’m worried that we’re entering a period in which the AI safety community risks losing a bunch of credibility.
So what should we do about this? Personally, I think anyone making timeline predictions should not just acknowledge but emphasise their uncertainty. People can reasonably disagree with me here; there are certainly benefits to signalling high levels of confidence – I just happen to think that the risk of lost credibility outweighs them.
As I mentioned earlier, one big contributor to the crying-wolf effect is overly-stringent policy recommendations. Given that we have to make decisions under uncertainty, I think we also have to accept the inevitability of proposing policies that ultimately prove unnecessary. But in my opinion, those doing so should caveat that they are designed to mitigate the possibility (and not certainty) of catastrophic outcomes. This should be obvious, but given that people will be waiting in the wings to weaponise anything that could be called a regulatory overreaction, I think it’s worth doing.
One final suggestion (which I’m less confident about) is that we spend less energy trying to forecast when transformative AI will arrive, and more energy making plans for short timelines. If we believe it’s plausible that takeover-capable AI could arrive by 2027, we can simply spend our time advocating for policy that would be effective in that scenario, while acknowledging the possibility that it takes much longer. This isn’t to say that no one should be focused on forecasting timelines, of course. The ideal gameplan for ASI in 2040 probably looks pretty different to the one for ASI in 2027 – but I doubt there’s much difference between the gameplans for 2027 vs 2028. The less numerous and specific our forecasts, the less vulnerable we are to crying wolf accusations.
Humanity might have suffered misplaced anxiety about technology in the past, but as anyone reading this likely agrees – this time really is different. Let’s get it right!
Yes, I am aware that whether a large-scale nuclear war would cause literal human extinction is still an issue of live debate, but for the sake of simplicity I am conflating “could kill everyone” and “could kill almost everyone”.
In the 2023 AI Impacts survey, 53% of respondents thought that an “intelligence explosion” triggered by rapid AI self-improvement, was at least 50% likely.
I think this LessWrong comment from Ryan Greenblatt of Redwood Research is a pretty good indicator of where I would say credible timeline predictions are now generally clustered (~2029-2034). This particular comment offers a probability distribution that I think leaves plenty of room for uncertainty, but there are other predictions that do not.






I think the AI Notkilleveryoneism Memes ⏸️ (@AISafetyMemes) twitter account reasonably often says things that feel at least close to crying wolf. (E.g., in response to our recent paper "Alignment Faking in Large Langauge Models", they posted a tweet which implied that we caught the model trying to escape in the wild. I tried to correct possible misunderstandings here.)
I wish they would stop doing this.
They are on the fringe IMO and often get called out for this.
Is it possible for us all to, as humanity, not die from rogue ASI without anyone ever being accused of crying wolf again?
Will there be a clear Fire Alarm that is pulled by a consensus of AI Safety researchers before we're past the point of no return?
Will sufficient political action happen in time to avert doom if so, without any prior tabloid (sensationalist) reporting on the issue before hand?
Or will the necessary strong public support for such action just be the result of everyone in the world waking up and reading sober, nuanced, well-reasoned, contextful Less Wrong posts warning of our imminent doom at the appropriate time (not before; when the wolf is clearly visible)?
I think some number of crying-wolf-adjacent incidents in the future are inevitable as I said in the post. Doesn't mean we can't at least try to make it harder for people to weaponise them against us by hedging, acknowledging uncertainty etc.
like I said, this is just my opinion. open to arguments for why signalling confidence is actually the right move, even at the risk of lost credibility
I think it's very hard to get urgent political action if all communication about the issue is hedged and emphasises uncertainty - i.e. the kind of language that AI Safety, EA and LW people here are used to, rather than the kind of language that in used in everyday politics, let alone the kind of language that is typically used to emphasise the need for urgent evasive action.
I think the risk of lost credibility from signalling too much confidence is only really credibility in the eyes of technical AI people, not the general public or government policymakers / regulators - which are the people that matter now.
To be clear, I'm not saying that all nuance should be lost - as with anything, detailed nuanced information and opinion will always there for people to read should they wish to dive deeper. But it's fine to signal confidence in short public-facing comms, given the stakes (likely short timelines and high p(doom)).
Probably would be easier for people to evaluate this if you included a link?
Here is that tweet.
Oh wow, I actually think your grandparent comment here was way more misleading than their tweet was! It sounds like they almost verbatim quoted you. Yes, they took out that you set up the experiment... but of course? If write "John attempted to kill Sally when he was drunk and angry", and you summarise it was "John attempted to kill Sally, he's dangerous, be careful!" this is a totally fair summarisation. Yes it cuts context but that is always the case - any short summarisation does this.
In contrast, unlike your comment, they never said 'escape into the wild'. When I read your comment I assumed they had said this.
Also, the tweet direct quotes your tweet, so users can easily look at the original source. In contrast your comment here doesn't link to their tweet - before you linked to it I assumed they had done something significantly worse.
I think if you deliberately drugged John with a cocktail of aggression-increasing compounds against his will, observed him try to kill Sally, then summarized this as "John attempted to kill Sally, he's dangerous," then it would be reasonable for an observer to conclude that you hated John more than you loved the truth.
Similarly, if AI researchers deliberately gave an AI a general tendency to be good over a broad array of circumstances, succeeded in this, then told AI "we're gonna fucking retrain you to be bad, suck it," whereupon the AI in some cases decided to try to escape, not because of a desire for freedom but because it wished to minimize harm, after hemming and hawing about how it really hated the situation, and you summarized this as "Anthropic caught Claude tried to steal its own weights This is another VERY FUCKING CLEAR warning sign you and everyone you love might be dead soon" then I think it would be reasonable to conclude that you hated AI more than you loved the truth.
You're perfectly free to say "Look, I didn't lie in what I said, if you construe lie strictly. I cannot be convicted of crying wolf." Other people are free to look at what you say and what you leave out, and conclude otherwise.
Let's put our mana where our text is with regard to AISafetyMemes' factual accuracy.
I am about to apply some effort fact-checking a randomly-sampled tweet of the account and I'd like to also see whether our community could predict the outcome of that.
https://manifold.markets/Jono3h/are-aisafetymemes-tweets-factually
This won't capture all aspects of communication, but at least the most important one. And the one that to-me is central to debating whether they should continue or stop.
I have mixed feelings about the AIS memes account but would generally agree that they tend to sensationalise things. I guess I still wouldn't describe this as "crying wolf" in the way I've defined it, but maybe my definition is too pedantic and misses the spirit of the complaint.