Comments
Now this is a study I love. Thanks for publishing!
Now this is a study I love. Thanks for publishing!
Disclaimer: This post was cross-posted with the author's permission, under his account. He may not notice comments. It was originally posted on June 30. You can find the audio version here.

I've argued that the development of advanced AI could make this the most important century for humanity. A common reaction to this idea is one laid out by Tyler Cowen here: "how good were past thinkers at predicting the future? Don’t just select on those who are famous because they got some big things right."
This is a common reason people give for being skeptical about the most important century - and, often, for skepticism about pretty much any attempt at futurism (trying to predict key events in the world a long time from now) or steering (trying to help the world navigate such key future events).
The idea is something like: "Even if we can't identify a particular weakness in arguments about key future events, perhaps we should be skeptical of our own ability to say anything meaningful at all about the long-run future. Hence, perhaps we should forget about theories of the future and focus on reducing suffering today, generally increasing humanity's capabilities, etc."
But are people generally bad at predicting future events? Including thoughtful people who are trying reasonably hard to be right? If we look back at prominent futurists' predictions, what's the actual track record? How bad is the situation?
I've looked pretty far and wide for systematic answers to this question, and Open Philanthropy's[1] Luke Muehlhauser has put a fair amount of effort into researching it; I discuss what we've found in an appendix. So far, we haven't turned up a whole lot - the main observation is that it's hard to judge the track record of futurists. (Luke discusses the difficulties here.)
Recently, I worked with Gavin Leech and Misha Yagudin at Arb Research to take another crack at this. I tried to keep things simpler than with past attempts - to look at a few past futurists who (a) had predicted things "kind of like" advances in AI (rather than e.g. predicting trends in world population); (b) probably were reasonably thoughtful about it; but (c) are very clearly not "just selected on those who are famous because they got things right." So, I asked Arb to look at predictions made by the "Big Three" science fiction writers of the mid-20th century: Isaac Asimov, Arthur C. Clarke, and Robert Heinlein.
These are people who thought a lot about science and the future, and made lots of predictions about future technologies - but they're famous for how entertaining their fiction was at the time, not how good their nonfiction predictions look in hindsight. I selected them by vaguely remembering that "the Big Three of science fiction" is a thing people say sometimes, googling it, and going with who came up - no hunting around for lots of sci-fi authors and picking the best or worst.[2]
So I think their track record should give us a decent sense for "what to expect from people who are not professional, specialized or notably lucky forecasters but are just giving it a reasonably thoughtful try." As I'll discuss below, I think this is many ways "unfair" as a comparison to today's forecasts about AI: I think these predictions are much less serious, less carefully considered and involve less work (especially work weighing different people and arguments against each other).
But my takeaway is that their track record looks ... fine! They made lots of pretty detailed, nonobvious-seeming predictions about the long-run future (30+, often 50+ years out); results ranged from "very impressive" (Asimov got about half of his right, with very nonobvious-seeming predictions) to "bad" (Heinlein was closer to 35%, and his hits don't seem very good) to "somewhere in between" (Clarke had a similar hit rate to Asimov, but his correct predictions don't seem as impressive). There are a number of seemingly impressive predictions and seemingly embarrassing ones.
(How do we determine what level of accuracy would be "fine" vs. "bad?" Unfortunately there's no clear quantitative benchmark - I think we just have to look at the predictions ourselves, how hard they seemed / how similar to today's predictions about AI, and make a judgment call. I could easily imagine others having a different interpretation than mine, which is why I give examples and link to the full prediction sets. I talk about this a bit more below.)
They weren't infallible oracles, but they weren't blindly casting about either. (Well, maybe Heinlein was.) Collectively, I think you could call them "mediocre," but you can't call them "hopeless" or "clueless" or "a warning sign to all who dare predict the long-run future." Overall, I think they did about as well as you might naively[3] guess a reasonably thoughtful person would do at some random thing they tried to do?
Below, I'll:
For this investigation, Arb very quickly (in about 8 weeks) dug through many old sources, used pattern-matching and manual effort to find predictions, and worked with contractors to score the hundreds of predictions they found. Big thanks to them! Their full report is here. Note this bit: "If you spot something off, we’ll pay $5 per cell we update as a result. We’ll add all criticisms – where we agree and update or reject it – to this document for transparency."
Arb collected "digital copies of as much of their [Asimov's, Clarke's, Heinlein's] nonfiction as possible (books, essays, interviews). The resulting intake is 475 files covering ~33% of their nonfiction corpuses."
Arb then used pattern-matching and manual inspection to pull out all of the predictions it could find, and scored these predictions by:
Importantly, fiction was never used as a source of predictions, so this exercise is explicitly scoring people on what they were not famous for. This is more like an assessment of "whether people who like thinking about the future make good predictions" than an assessment of "whether professional or specialized forecasters make good predictions."
For reasons I touch on in an appendix below, I didn't ask Arb to try to identify how confident the Big Three were about their predictions. I'm more interested in whether their predictions were nonobvious and sometimes correct than in whether they were self-aware about their own uncertainty; I see these as different issues, and I suspect that past norms discouraged the latter more than today's norms do (at least within communities interested in Bayesian mindset and the science of forecasting).
More detail in Arb's report.
The tables below summarize the numbers I think give the best high-level picture. See the full report and detailed files for the raw predictions and a number of other cuts; there are a lot of ways you can slice the data, but I don't think it changes the picture from what I give below.
Below, I present each predictor's track record on:
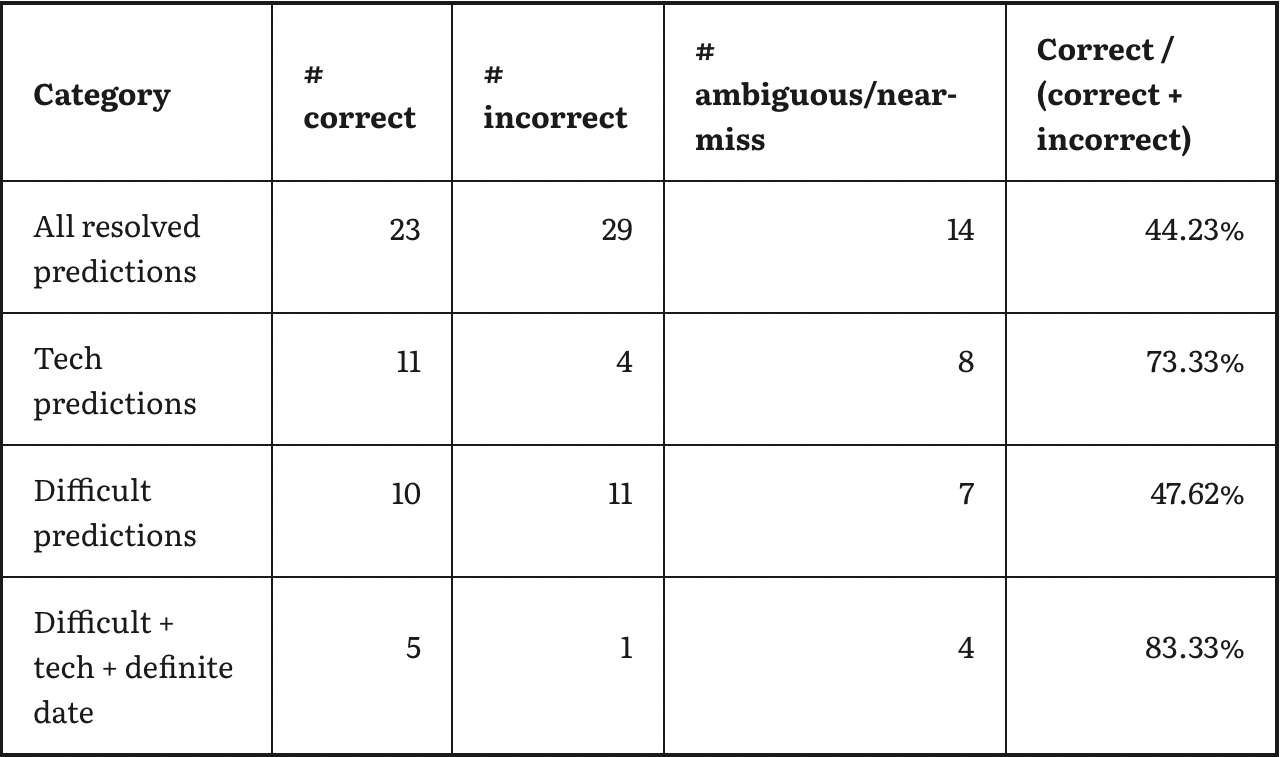
You can see the full set of predictions here, but to give a flavor, here are two "correct" and two "incorrect" predictions from the strictest category.[6] All of these are predictions Asimov made in 1964, about the year 2014 (unless otherwise indicated).
A general challenge with assessing prediction track records is that we don't know what to compare someone's track record to. Is getting about half your predictions right "good," or is it no more impressive than writing down a bunch of things that might happen and flipping a coin on each?
I think this comes down to how difficult the predictions are, which is hard to assess systematically. A nice thing about this study is that there are enough predictions to get a decent sample size, but the whole thing is contained enough that you can get a good qualitative feel for the predictions themselves. (This is why I give examples; you can also view all predictions for a given person by clicking on their name above the table.) In this case, I think Asimov tends to make nonobvious, detailed predictions, such that I consider it impressive to have gotten ~half of them to be right.
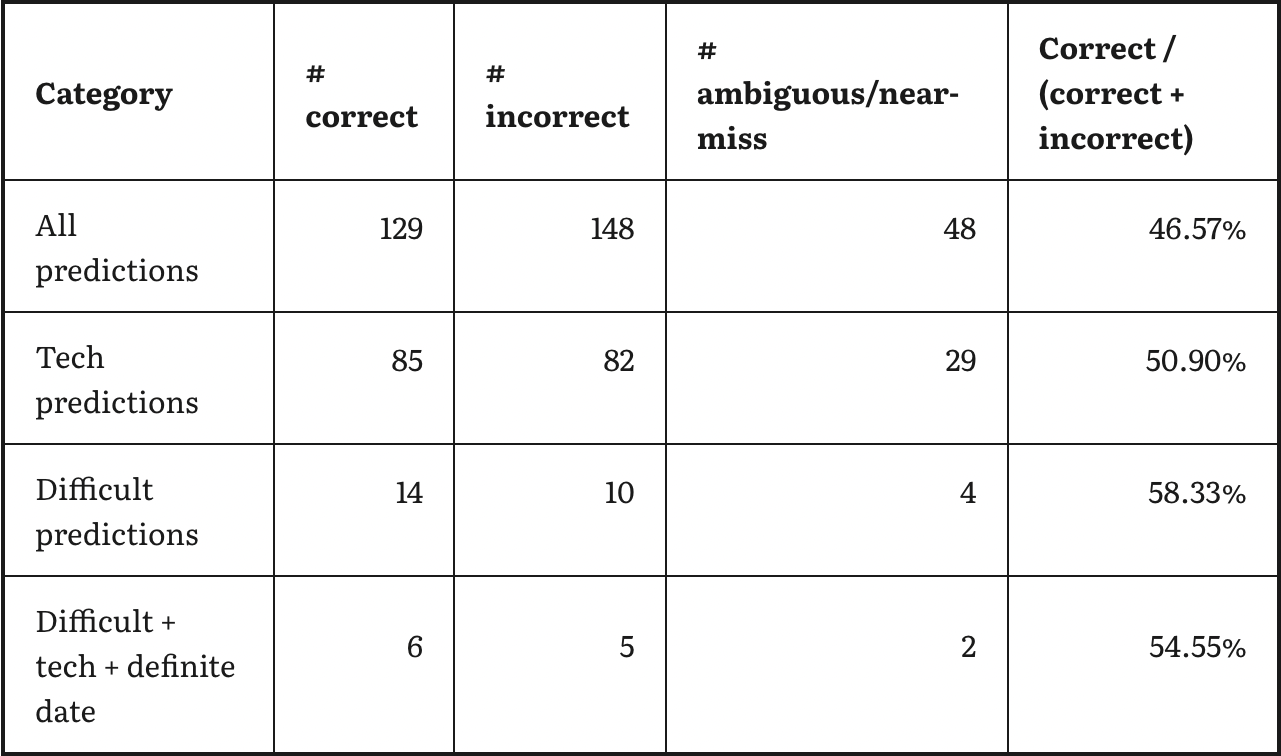
Examples (as above):[7]
I generally found this data set less satisfying/educational than Asimov's: a lot of the predictions were pretty deep in the weeds of how rocketry might work or something, and a lot of them seemed pretty hard to interpret/score. I thought the bad predictions were pretty bad, and the good predictions were sometimes good but generally less impressive than Asimov's.
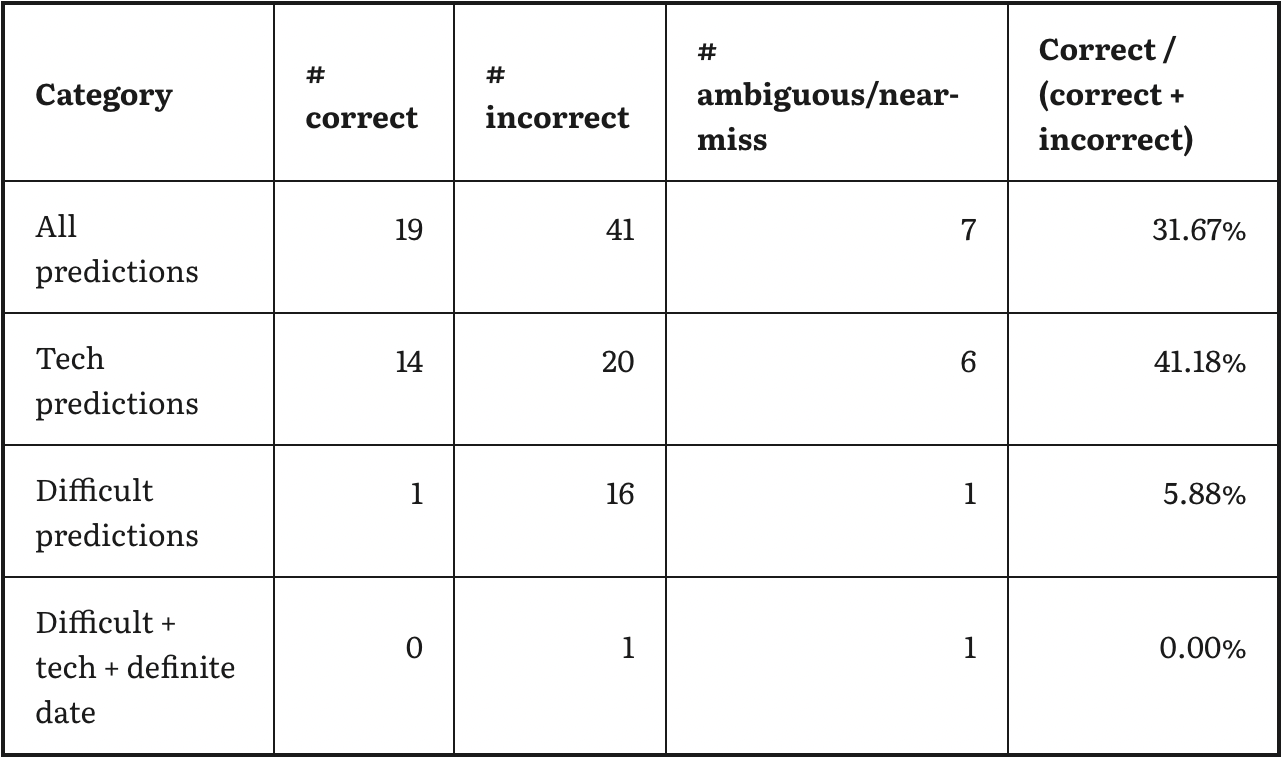
This seems really bad, especially adjusted for difficulty: many of the "correct" ones seem either hard-to-interpret or just very obvious (e.g., no time travel). I was impressed by his prediction that "we probably will still be after a cure for the common cold" until I saw a prediction in a separate source saying "Cancer, the common cold, and tooth decay will all be conquered." Overall it seems like he did a lot of predicting outlandish stuff about space travel, and then anti-predicting things that are probably just impossible (e.g., no time travel).
He did have some decent ones, though, such as: "By 2000 A.D. we will know a great deal about how the brain functions ... whereas in 1900 what little we knew was wrong. I do not predict that the basic mystery of psychology--how mass arranged in certain complex patterns becomes aware of itself--will be solved by 2000 A.D. I hope so but do not expect it." He also predicted no human extinction and no end to war - I'd guess a lot of people disagreed with these at the time.
Looks like, of the "big three," we have:
The above collect casual predictions - no probabilities given, little-to-no reasoning given, no apparent attempt to collect evidence and weigh arguments - by professional fiction writers.
Contrast this situation with my summary of the different lines of reasoning forecasting transformative AI. The latter includes:
There's plenty of room for debate on how much these measures should be expected to improve our foresight, compared to what the "Big Three" were doing. My guess is that we should take forecasts about transformative AI a lot more seriously, partly because I think there's a big difference between putting in "extremely little effort" (basically guessing off the cuff without serious time examining arguments and counter-arguments, which is my impression of what the Big Three were mostly doing) and "putting in moderate effort" (considering expert opinion, surveying arguments and counter-arguments, explicitly thinking about one's degree of uncertainty).
But the "extremely little effort" version doesn't really look that bad.
If you look at forecasts about transformative AI and think "Maybe these are Asimov-ish predictions that have about a 50% hit rate on hard questions; maybe these are Heinlein-ish predictions that are basically crap," that still seems good enough to take the "most important century" hypothesis seriously.
A 2013 project assessed Ray Kurzweil's 1999 predictions about 2009, and a 2020 followup assessed his 1999 predictions about 2019. Kurzweil is known for being interesting at the time rather than being right with hindsight, and a large number of predictions were found and scored, so I consider this study to have similar advantages to the above study.
Kurzweil is notorious for his very bold and contrarian predictions, and I'm overall inclined to call his track record something between "mediocre" and "fine" - too aggressive overall, but with some notable hits. (I think if the most important century hypothesis ends up true, he'll broadly look pretty prescient, just on the early side; if it doesn't, he'll broadly look quite off base. But that's TBD.)
A 2002 paper, summarized by Luke Muehlhauser here, assessed the track record of The Year 2000 by Herman Kahn and Anthony Wiener, "one of the most famous and respected products of professional futurism."
Luke's 2019 survey on the track record of futurism identifies two other relevant papers (here and here); I haven't read these beyond the abstracts, but their overall accuracy rates were 76% and 37%, respectively. It's difficult to interpret those numbers without having a feel for how challenging the predictions were.
A 2021 EA Forum post looks at the aggregate track record of forecasters on PredictionBook and Metaculus, including specific analysis of forecasts 5+ years out, though I don't find it easy to draw conclusions about whether the performance was "good" or "bad" (or how similar the questions were to the ones I care about).
Disclosure: I'm co-CEO of Open Philanthropy. ↩
I also briefly Googled for their predictions to get a preliminary sense of whether they were the kinds of predictions that seemed relevant. I found a couple of articles listing a few examples of good and bad predictions, but nothing systematic. I claim I haven't done a similar exercise with anyone else and thrown it out.
That is, if we didn't have a lot of memes in the background about how hard it is to predict the future.
(1) was already generally known,
(2) was expert consensus,
(3) speculative but on trend,
(4) above trend, or oddly detailed
(5) prescient, no trend to go off
Very few predictions in the data set are for less than 30 years, and I just ignored them.
Asimov actually only had one incorrect prediction in this category, so for the 2nd incorrect prediction I used one with difficulty "3" instead of "4."
The first prediction in this list qualified for the strictest criteria when I first drafted this post, but it's now been rescored to difficulty=3/5, which I disagree with (I think it is an impressive prediction, more so than any of the remaining ones that qualify as difficulty=4/5).
Also see this report on calibration for Open Philanthropy grant investigators (though this is a different set of people from the people who researched transformative AI timelines).


This was posted to lesswrong 4 days ago; consider checking out the comments to the lesswrong version. There are 18 comments at the time I'm writing this.